Essnet Big Data II
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

List of Participants
List of participants Conference of European Statisticians 69th Plenary Session, hybrid Wednesday, June 23 – Friday 25 June 2021 Registered participants Governments Albania Ms. Elsa DHULI Director General Institute of Statistics Ms. Vjollca SIMONI Head of International Cooperation and European Integration Sector Institute of Statistics Albania Argentina Sr. Joaquin MARCONI Advisor in International Relations, INDEC Mr. Nicolás PETRESKY International Relations Coordinator National Institute of Statistics and Censuses (INDEC) Elena HASAPOV ARAGONÉS National Institute of Statistics and Censuses (INDEC) Armenia Mr. Stepan MNATSAKANYAN President Statistical Committee of the Republic of Armenia Ms. Anahit SAFYAN Member of the State Council on Statistics Statistical Committee of RA Australia Mr. David GRUEN Australian Statistician Australian Bureau of Statistics 1 Ms. Teresa DICKINSON Deputy Australian Statistician Australian Bureau of Statistics Ms. Helen WILSON Deputy Australian Statistician Australian Bureau of Statistics Austria Mr. Tobias THOMAS Director General Statistics Austria Ms. Brigitte GRANDITS Head International Relation Statistics Austria Azerbaijan Mr. Farhad ALIYEV Deputy Head of Department State Statistical Committee Mr. Yusif YUSIFOV Deputy Chairman The State Statistical Committee Belarus Ms. Inna MEDVEDEVA Chairperson National Statistical Committee of the Republic of Belarus Ms. Irina MAZAISKAYA Head of International Cooperation and Statistical Information Dissemination Department National Statistical Committee of the Republic of Belarus Ms. Elena KUKHAREVICH First Deputy Chairperson National Statistical Committee of the Republic of Belarus Belgium Mr. Roeland BEERTEN Flanders Statistics Authority Mr. Olivier GODDEERIS Head of international Strategy and coordination Statistics Belgium 2 Bosnia and Herzegovina Ms. Vesna ĆUŽIĆ Director Agency for Statistics Brazil Mr. Eduardo RIOS NETO President Instituto Brasileiro de Geografia e Estatística - IBGE Sra. -

UNWTO/DG GROW Workshop Measuring the Economic Impact Of
UNWTO/DG GROW Workshop Measuring the economic impact of tourism in Europe: the Tourism Satellite Account (TSA) Breydel building – Brey Auditorium Avenue d'Auderghem 45, B-1040 Brussels, Belgium 29-30 November 2017 LIST OF PARTICIPANTS Title First name Last name Institution Position Country EU 28 + COSME COUNTRIES State Tourism Committee of the First Vice Chairman of the State Tourism Mr Mekhak Apresyan Armenia Republic of Armenia Committee of the Republic of Armenia Trade Representative of the RA to the Mr Varos Simonyan Trade Representative of the RA to the EU Armenia EU Head of balance of payments and Ms Kristine Poghosyan National Statistical Service of RA Armenia foreign trade statistics division Mr Gagik Aghajanyan Central Bank of the Republic of Armenia Head of Statistics Department Armenia Mr Holger Sicking Austrian National Tourist Office Head of Market Research Austria Federal Ministry of Science, Research Ms Angelika Liedler Head of International Tourism Affairs Austria and Economy Department of Tourism, Ministry of Consultant of Planning and Organization Ms Liya Stoma Sports and Tourism of the Republic of Belarus of Tourism Activities Division Belarus Ms Irina Chigireva National Statistical Committee Head of Service and Domestic Trade Belarus Attachée - Observatoire du Tourisme Ms COSSE Véronique Commissariat général au Tourisme Belgium wallon Mr François VERDIN Commissariat général au Tourisme Veille touristique et études de marché Belgium 1 Title First name Last name Institution Position Country Agency for statistics of Bosnia -

Celebrating the Establishment, Development and Evolution of Statistical Offices Worldwide: a Tribute to John Koren
Statistical Journal of the IAOS 33 (2017) 337–372 337 DOI 10.3233/SJI-161028 IOS Press Celebrating the establishment, development and evolution of statistical offices worldwide: A tribute to John Koren Catherine Michalopouloua,∗ and Angelos Mimisb aDepartment of Social Policy, Panteion University of Social and Political Sciences, Athens, Greece bDepartment of Economic and Regional Development, Panteion University of Social and Political Sciences, Athens, Greece Abstract. This paper describes the establishment, development and evolution of national statistical offices worldwide. It is written to commemorate John Koren and other writers who more than a century ago published national statistical histories. We distinguish four broad periods: the establishment of the first statistical offices (1800–1914); the development after World War I and including World War II (1918–1944); the development after World War II including the extraordinary work of the United Nations Statistical Commission (1945–1974); and, finally, the development since 1975. Also, we report on what has been called a “dark side of numbers”, i.e. “how data and data systems have been used to assist in planning and carrying out a wide range of serious human rights abuses throughout the world”. Keywords: National Statistical Offices, United Nations Statistical Commission, United Nations Statistics Division, organizational structure, human rights 1. Introduction limitations to this power. The limitations in question are not constitutional ones, but constraints that now Westergaard [57] labeled the period from 1830 to seemed to exist independently of any formal arrange- 1849 as the “era of enthusiasm” in statistics to indi- ments of government.... The ‘era of enthusiasm’ in cate the increasing scale of their collection. -
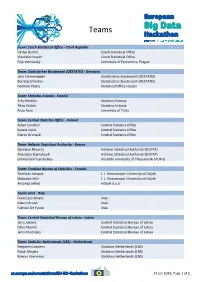
European Big Data Hackathon
Teams Team: Czech Statistical Office - Czech Republic Václav Bartoš Czech Statistical Office Vlastislav Novák Czech Statistical Office Filip Vencovský University of Economics, Prague Team: Statistisches Bundesamt (DESTATIS) - Germany Jana Emmenegger Statistisches Bundesamt (DESTATIS) Bernhard Fischer Statistisches Bundesamt (DESTATIS) Normen Peters Statistical Office Hessen Team: Statistics Estonia - Estonia Arko Kesküla Statistics Estonia Tõnu Raitviir Statistics Estonia Anto Aasa University of Tartu Team: Central Statistics Office - Ireland Aidan Condron Central Statistics Office Sanela Jojkic Central Statistics Office Marco Grimaldi Central Statistics Office Team: Hellenic Statistical Authority - Greece Georgios Ntouros Hellenic Statistical Authority (ELSTAT) Anastasia Stamatoudi Hellenic Statistical Authority (ELSTAT) Emmanouil Tsardoulias Aristotle University of Thessaloniki (AUTH) Team: Croatian Bureau of Statistics - Croatia Tomislav Jakopec J. J. Strossmayer University of Osijek Slobodan Jelić J. J. Strossmayer University of Osijek Antonija Jelinić mStart d.o.o Team: Istat - Italy Francesco Amato Istat Mauro Bruno Istat Fabrizio De Fausti Istat Team: Central Statistical Bureau of Latvia - Latvia Janis Jukams Central Statistical Bureau of Latvia Dāvis Kļaviņš Central Statistical Bureau of Latvia Jānis Muižnieks Central Statistical Bureau of Latvia Team: Statistics Netherlands (CBS) - Netherlands Benjamin Laevens Statistics Netherlands (CBS) Ralph Meijers Statistics Netherlands (CBS) Rowan Voermans Statistics Netherlands (CBS) 31 -

Annex 3: Sources, Methods and Technical Notes
Annex 3 EAG 2007 Education at a Glance OECD Indicators 2007 Annex 3: Sources 1 Annex 3 EAG 2007 SOURCES IN UOE DATA COLLECTION 2006 UNESCO/OECD/EUROSTAT (UOE) data collection on education statistics. National sources are: Australia: - Department of Education, Science and Training, Higher Education Group, Canberra; - Australian Bureau of Statistics (data on Finance; data on class size from a survey on Public and Private institutions from all states and territories). Austria: - Statistics Austria, Vienna; - Federal Ministry for Education, Science and Culture, Vienna (data on Graduates); (As from 03/2007: Federal Ministry for Education, the Arts and Culture; Federal Ministry for Science and Research) - The Austrian Federal Economic Chamber, Vienna (data on Graduates). Belgium: - Flemish Community: Flemish Ministry of Education and Training, Brussels; - French Community: Ministry of the French Community, Education, Research and Training Department, Brussels; - German-speaking Community: Ministry of the German-speaking Community, Eupen. Brazil: - Ministry of Education (MEC) - Brazilian Institute of Geography and Statistics (IBGE) Canada: - Statistics Canada, Ottawa. Chile: - Ministry of Education, Santiago. Czech Republic: - Institute for Information on Education, Prague; - Czech Statistical Office Denmark: - Ministry of Education, Budget Division, Copenhagen; - Statistics Denmark, Copenhagen. 2 Annex 3 EAG 2007 Estonia - Statistics office, Tallinn. Finland: - Statistics Finland, Helsinki; - National Board of Education, Helsinki (data on Finance). France: - Ministry of National Education, Higher Education and Research, Directorate of Evaluation and Planning, Paris. Germany: - Federal Statistical Office, Wiesbaden. Greece: - Ministry of National Education and Religious Affairs, Directorate of Investment Planning and Operational Research, Athens. Hungary: - Ministry of Education, Budapest; - Ministry of Finance, Budapest (data on Finance); Iceland: - Statistics Iceland, Reykjavik. -
Facts About Tallinn 2019
FACTS 2019 ABOUT TALLINN TALLINN – Estonia’s Economic Centre 1 TABLE OF CONTENTS HISTORY: 1 TALLINN TALLINN 800 4 COMPETITIVENESS 5 BUSINESS 13 INFORMATION AND COMMUNICATIONS TECHNOLOGY The year 2019 marks a milestone in Tallinn’s history: on June 15, the city th 17 TOURISM celebrates its 800 anniversary, commemorating its first recorded mention in the Livonian Chronicle of Henry in 1219, in which Henry of Latvia (Henricus de 23 ECONOMY Lettis) describes the battle of Lindanise Castle (today’s Toompea Hill) between 25 FOREIGN TRADE King Valdemar II of Denmark and the Estonian forces. 27 RESIDENTIAL HOUSING AND COMMERCIAL REAL ESTATE As all good things come in pairs, and the city’s first mention in the chronicles is 32 POPULATION AND JOB MARKET not the only reason to celebrate: we share our great anniversary with the Danish 34 TRANSPORT state flag, the Dannebrog. According to a popular legend, the red-and-white 38 EDUCATION cross fell from the sky as a sign of support from God during the battle in Tallinn 41 ENVIRONMENT and secured a difficult victory for the Danes. 44 HEALTH CARE On 15 May 1248, Erik IV, the King of Denmark, granted Tallinn town rights under 46 SPORT the Lübeck Law, thereby joining Tallinn to the common legal space of German 50 CULTURE trading towns. 53 ADMINISTRATION AND BUDGET Tallinn, the famous Hanseatic town, received its town rights in 1248. Published by: Tallinn City Enterprise Department Tallinn is the best-preserved medieval town in Northern Europe. Design: Disainikorp Tallinn Old Town is included on the UNESCO World Heritage List. -

4Th Edition of the Handbook of Statistical Organization
4th Edition of the Handbook of Statistical Organization Beta version 2.1 18 February 2021 1 | Page Table of Content Table of Content ....................................................................................................................... 2 Chapter 1. Introduction ...................................................................................................... 8 1.1 General context .................................................................................................................... 8 1.2 Purpose, users and uses of the Handbook .......................................................................... 11 1.3 Main topics, key concepts, and terminologies ................................................................... 12 1.4 Features and outline of the Handbook ............................................................................... 15 Chapter 2. Overview of the Handbook ............................................................................ 20 2.1 Official statistics ................................................................................................................ 20 2.2 The international dimension .............................................................................................. 20 2.3 Basis of official statistics ................................................................................................... 21 2.4 National statistical offices and national statistical systems ............................................... 21 2.5 The role of the chief statistician -

Web-Sites of National Statistical Offices
Web-sites of National Statistical Offices Afghanistan Central Statistics Organization Albania Statistical Institute Argentina National Institute for Statistics and Census Armenia National Statistical Service of the Republic of Armenia Aruba Central Bureau of Statistics Australia Australian Bureau of Statistics Austria National Statistical Office of Austria Azerbaijan State Statistical Committee of Azerbaijan Republic Belarus Ministry of Statistics and Analysis Belgium National Institute of Statistics Belize Statistical Institute Benin National Statistics Institute Bolivia National Statistics Institute Botswana Central Statistics Office Brazil Brazilian Institute of Statistics and Geography Bulgaria National Statistical Institute Burkina Faso National Statistical Institute Cambodia National Institute of Statistics Cameroon National Institute of Statistics Canada Statistics Canada Cape Verde National Statistical Office Central African Republic General Directorate of Statistics and Economic and Social Studies Chile National Statistical Institute of Chile China National Bureau of Statistics Colombia National Administrative Department for Statistics Cook Islands Statistics Office Costa Rica National Statistical Institute Côte d'Ivoire National Statistical Institute Croatia Croatian Bureau of Statistics Cuba National statistical institute Cyprus Statistical Service of Cyprus Czech Republic Czech Statistical Office Denmark Statistics Denmark Dominican Republic National Statistical Office Ecuador National Institute for Statistics and Census Egypt -

Situation Analysis on Evidence-Informed Health
Evidence-informed INFORMEDpolicy-making processes - MAKINGEiee-iore - poi-i proesses Evidence-informed Evidence-informed policy-making processes Health informationpolicy-making system processes e tio sst SITUATION ANALYSIS Het ior e Health research system ON EVIDENCE Health informationHealth information system system sst o 3 eser HEALTH POLICY Het r et Health research system e HealthHealth system research and system Evidence-informed Estonia policy-making context policy-making processes Het sst poi-i ot EVIPNet Europe Series, N et ot Country context Health system and Evidence-informed policy-making context Coutr policy-making processes Health system and Evidence-informed policy-making context policy-making processes Health information system Country context Country context 19/12/2017 12:16 Health information system Health research system Health information system 19/12/2017 12:16 19/12/2017 12:16 Health research system Health system and policy-makingHealth research context system Health system and policy-making context Country context Health system and policy-making context Country context Country context 2844-OMS-EURO-Cover-EvipNet-v4-20171218.indd 1-3 2844-OMS-EURO-Cover-EvipNet-v4-20171218.indd 1-3 2844-OMS-EURO-Cover-EvipNet-v4-20171218.indd 1-3 Situation analysis to improve evidence-informed health policy-making in Estonia Estonia EVIPNet Europe Series, No 3 ABSTRACT The aim of the situation analysis is to provide deeper understanding of the major factors that may facilitate or hinder the evidence-informed health policy in Estonia. It was conducted based on the WHO situation analysis manual and it found that in order to ensure research use among policy-makers in a systematic way, a knowledge translation platform could be created. -

Deltagerliste Sorteret I Landeorden 020517.Xlsx
COUNTRY FIRSTNAME LASTNAME EMAIL ORGANISATION Albania Pranvera Elezi [email protected] Institute of Statistics, INSTAT Austria Katrin Baumgartner [email protected] Statistics Austria Austria Judith Forster [email protected] Statistics Austria Belgium Filip Tanay [email protected] European Commission Bosnia and Herzegovina Svjetlana Kezunovic [email protected] Agency for statistics of Bosnia and Herzegovina Kostova- Bulgaria Tsveta Sevastiyanova [email protected] National statistical institute Cyprus Eleni Christodoulidou [email protected] Statistical Service of Cyprus Denmark Sofie Valentin [email protected] Statistics Denmark Denmark Sven Egmose [email protected] Statistics Denmark Denmark Lisbeth Johansen [email protected] Statistics Denmark Denmark Wendy Takacs Jensen [email protected] Statistics Denmark Denmark Tine Cordes [email protected] Statistics Denmark Denmark Martin Nielsen [email protected] Statistics Denmark Denmark Lars Peter Christensen [email protected] DST Estonia Ülle Pettai [email protected] Statistics Estonia Finland Anna Pärnänen [email protected] Statistics Finland Finland Hanna Sutela [email protected] Statistics Finland France Simon Beck [email protected] Insee France Jonathan Brendler [email protected] INSEE Germany Lisa Guenther [email protected] Federal Statistical Office Hungary Krisztina Mezey [email protected] Hungarian Central Statistical Office Iceland Ólafur Már Sigurðsson [email protected] Statistics Iceland Ireland Edel Flannery [email protected] Central -

Health Expenditure Scenarios in the New Member States Country Report on Estonia
European Network of Economic Policy Research Institutes HEALTH EXPENDITURE SCENARIOS IN THE NEW MEMBER STATES COUNTRY REPORT ON ESTONIA LIIS ROOVÄLI ENEPRI RESEARCH REPORT NO. 45 AHEAD WP9 DECEMBER 2007 ENEPRI Research Reports are designed to make the results of research projects undertaken within the framework of the European Network of Economic Policy Research Institutes (ENEPRI) publicly available. This paper was prepared as part of Work Package 9 of the AHEAD project – Ageing, Health Status and the Determinants of Health Expenditure – which has received financing from the European Commission under the 6th Research Framework Programme (contract no. SP21-CT-2003-502641). Its findings and conclusions are attributable only to the author/s and not to ENEPRI or any of its member institutions. A brief description of the AHEAD project and a list of its partner institutes can be found at the end of this report. ISBN 978-92-9079-762-3 AVAILABLE FOR FREE DOWNLOADING FROM THE ENEPRI WEBSITE (HTTP://WWW.ENEPRI.ORG) AND THE CEPS WEBSITE (WWW.CEPS.EU) © COPYRIGHT 2007, LIIS ROOVÄLI Contents Abbreviations ................................................................................................................................. i Introduction................................................................................................................................... 1 1. Health care expenditure models applied in the country.......................................................... 1 2. Synthetic description of the ILO health budget model -

International Statistics.Docx (X:100.0%, Y:100.0%) Created by Grafikhuset Publi PDF
Microsoft Word − 14 International Statistics.docx (X:100.0%, Y:100.0%) Created by Grafikhuset Publi PDF. International statistics Trends in the world population World economy International statistics since 1898 Microsoft Word − 14 International Statistics.docx (X:100.0%, Y:100.0%) Created by Grafikhuset Publi PDF. International statistics Trends in the World population World population is growing The world’s population almost quadrupled during the 20th century. In 1900, the world population was 1.65 billion and in 2010, the world population is estimated at 7,4 billion in 2016. This trend gained momentum in the 1960s until the 1990s, with a growth rate around 20 per cent every decade. In 2050, the world population is as- sumed to be about 9.7 billion. Figure 1 World population Billion 12 10 8 6 4 2 0 1900 1910 1920 1930 1940 1950 1960 1970 1980 1990 2000 2010 2020 2030 2040 2050 2100 Source: UN (esa.un.org/unpd/wpp/publications/files/key_findings_wpp_2015.pdf) We are also getting older – but major differences among countries Simultaneously with the growing world population, we also live longer. In 1960, the average life expectancy for all new-born children in the world was 50 years. In 2010, average life expectancy increased to more than 69 years. In 2050, average life expec- tancy is assumed to have increased to 76 years. The figures reflect major differences among countries and continents. A child born in Hong Kong is 84, while a child born in Swaziland can only expect to live until the age of 49.