XML Tutorial: Overview
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2004/WD-xml-media-types-20041102 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP (formerly of Oracle) Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list and in the section C Change Log [p.11] . A diff-marked version against the previous version of this document is available. -

An Arbitration System for Student Evaluation Based on XML Signature
2nd EUROPEAN COMPUTING CONFERENCE (ECC’08) Malta, September 11-13, 2008 An Arbitration System for Student Evaluation based on XML Signature ROBERT ANDREI BUCHMANN, SERGIU JECAN Business Information Systems Dpt. Faculty of Economic Sciences and Business Administration Babes Bolyai University Cluj Napoca Str. Th. Mihali 58-60, ROMANIA [email protected], [email protected] Abstract: This paper promotes an e-learning application model for student evaluation, based on AJAX frameworks in order to provide improved user experience and asynchronous data exchange and the XML Signature standard in order to impose message authentications for the test papers. The motivation of this research is the need to arbitrate contestation for e-learning evaluation by providing an authentication and non-repudiation mechanism for both the students’ answers and the teachers’ evaluation criteria and rating, especially in open answer tests. Keywords: - e-learning, digital signature, AJAX 1 Introduction arose the issue of arbitration in contestation processes, especially in tests based on open E-learning already provides a mature model for questions, but also in multiple choice tests with educational processes. However, the separation no immediate answer validation. The proposed of parties in time and space is bound to solution is an extension to traditional e-learning communication gaps causing situations where an application models, regarding the evaluation arbitration system should provide trust module, based on XML-based digital signature mechanisms between the student and the and improved usability through AJAX teacher. The proposed application model is an frameworks. evolutionary step of the XML-driven e- commerce application previously implemented 3 Problem Solution for Flash 2004 with XML support and currently migrated under an AJAX framework and within 3.1 Instrumentation an e-learning context based on trust managed through XML Signatures. -
XML Specifications Growth of the Web
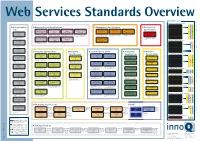
Web Services Standards Overview Dependencies Messaging Specifications SOAP 1.1 SOAP 1.2 Interoperability Business Process Specifications Management Specifications Presentation SOAP Message Transmission Optimization Mechanism WS-Notification the trademarks of their respective owners. of their respective the trademarks Management Using Web Management Of WS-BaseNotification Issues Business Process Execution WS-Choreography Model Web Service Choreography Web Service Choreography WS-Management Specifications Services (WSDM-MUWS) Web Services (WSDM-MOWS) Language for Web Services 1.1 Overview Interface Description Language AMD, Dell, Intel, Microsoft and Sun WS-Topics (BPEL4WS) · 1.1 · BEA Systems, IBM, (WSCI) · 1.0 · W3C 1.0 1.0 1.0 · W3C (CDL4WS) · 1.0 · W3C Microsystems Microsoft, SAP, Sun Microsystems, SAP, BEA Systems WS-BrokeredNotification Working Draft Candidate Recommendation OASIS OASIS Published Specification Web Services for Remote Security Resource Basic Profile Siebel Systems · OASIS-Standard and Intalio · Note OASIS-Standard OASIS-Standard Metadata Portlets (WSRP) WS-Addressing – Core 1.1 ̆ ̆ ̆ ̆ ̆ ̆ ̆ 2.0 WS-I Business Process Execution Language for Web Services WS-Choreography Model Overview defines the format Web Service Choreography Interface (WSCI) describes Web Service Choreography Description Language Web Service Distributed Management: Management Using Web Service Distributed Management: Management Of WS-Management describes a general SOAP-based WS-Addressing – WSDL Binding 1.1(BPEL4WS) provides a language for the formal -

Toward the Discovery and Extraction of Money Laundering Evidence from Arbitrary Data Formats Using Combinatory Reductions
Toward the Discovery and Extraction of Money Laundering Evidence from Arbitrary Data Formats using Combinatory Reductions Alonza Mumford, Duminda Wijesekera George Mason University [email protected], [email protected] Abstract—The evidence of money laundering schemes exist undetected in the electronic files of banks and insurance firms scattered around the world. Intelligence and law enforcement analysts, impelled by the duty to discover connections to drug cartels and other participants in these criminal activities, require the information to be searchable and extractable from all types of data formats. In this overview paper, we articulate an approach — a capability that uses a data description language called Data Format Description Language (DFDL) extended with higher- order functions as a host language to XML Linking (XLink) and XML Pointer (XPointer) languages in order to link, discover and extract financial data fragments from raw-data stores not co- located with each other —see figure 1. The strength of the ap- Fig. 1. An illustration of an anti-money laundering application that connects proach is grounded in the specification of a declarative compiler to multiple data storage sites. In this case, the native data format at each site for our concrete language using a higher-order rewriting system differs, and a data description language extended with higher-order functions with binders called Combinatory Reduction Systems Extended and linking/pointing abstractions are used to extract data fragments based on (CRSX). By leveraging CRSX, we anticipate formal operational their ontological meaning. semantics of our language and significant optimization of the compiler. Index Terms—Semantic Web, Data models, Functional pro- II. -

O'reilly Xpath and Xpointer.Pdf
XPath and XPointer John E. Simpson Publisher: O'Reilly First Edition August 2002 ISBN: 0-596-00291-2, 224 pages Referring to specific information inside an XML document is a little like finding a needle in a haystack. XPath and XPointer are two closely related Table of Contents languages that play a key role in XML processing by allowing developers Index to find these needles and manipulate embedded information. By the time Full Description you've finished XPath and XPointer, you'll know how to construct a full Reviews XPointer (one that uses an XPath location path to address document Reader reviews content) and completely understand both the XPath and XPointer features it Errata uses. 1 Table of Content Table of Content ............................................................................................................. 2 Preface............................................................................................................................. 4 Who Should Read This Book?.................................................................................... 4 Who Should Not Read This Book?............................................................................. 4 Organization of the Book............................................................................................ 5 Conventions Used in This Book ................................................................................. 5 Comments and Questions ........................................................................................... 6 Acknowledgments...................................................................................................... -

On the Integrity and Trustworthiness of Web Produced Data
CORE Metadata, citation and similar papers at core.ac.uk Provided by Open Repository of the University of Porto On the Integrity and Trustworthiness of web produced data Luís A. Maia Mestrado Integrado em Engenharia de Redes e Sistemas Informáticos Departamento de Ciência de Computadores 2013 Orientador Professor Doutor Manuel Eduardo Carvalho Duarte Correia, Professor Auxiliar do Departamento de Computadores, Faculdade de Ciências da Universidade do Porto Todas as correções determinadas pelo júri, e só essas, foram efetuadas. O Presidente do Júri, Porto, ______/______/_________ Acknowledgments I would like to express my appreciation for the help of my supervisor in researching and bringing different perspectives and to thank my family, for their support and dedication. 3 Abstract Information Systems have been a key tool for the overall performance improvement of administrative tasks in academic institutions. While most systems intend to deliver a paperless environment to each institution it is recurrent that document integrity and accountability is still relying on traditional methods such as producing physical documents for signing and archiving. While this method delivers a non-efficient work- flow and has an effective monetary cost, it is still the common method to provide a degree of integrity and accountability on the data contained in the databases of the information systems. The evaluation of a document signature is not a straight forward process, it requires the recipient to have a copy of the signers signature for comparison and training beyond the scope of any office employee training, this leads to a serious compromise on the trustability of each document integrity and makes the verification based entirely on the trust of information origin which is not enough to provide non-repudiation to the institutions. -

XML Signature/Encryption — the Basis of Web Services Security
Special Issue on Security for Network Society Falsification Prevention and Protection Technologies and Products XML Signature/Encryption — the Basis of Web Services Security By Koji MIYAUCHI* XML is spreading quickly as a format for electronic documents and messages. As a consequence, ABSTRACT greater importance is being placed on the XML security technology. Against this background research and development efforts into XML security are being energetically pursued. This paper discusses the W3C XML Signature and XML Encryption specifications, which represent the fundamental technology of XML security, as well as other related technologies originally developed by NEC. KEYWORDS XML security, XML signature, XML encryption, Distributed signature, Web services security 1. INTRODUCTION 2. XML SIGNATURE XML is an extendible markup language, the speci- 2.1 Overview fication of which has been established by the W3C XML Signature is an electronic signature technol- (WWW Consortium). It is spreading quickly because ogy that is optimized for XML data. The practical of its flexibility and its platform-independent technol- benefits of this technology include Partial Signature, ogy, which freely allows authors to decide on docu- which allows an electronic signature to be written on ment structures. Various XML-based standard for- specific tags contained in XML data, and Multiple mats have been developed including: ebXML and Signature, which enables multiple electronic signa- RosettaNet, which are standard specifications for e- tures to be written. The use of XML Signature can commerce transactions, TravelXML, which is an EDI solve security problems, including falsification, spoof- (Electronic Data Interchange) standard for travel ing, and repudiation. agencies, and NewsML, which is a standard specifica- tion for new distribution formats. -

Rdfa in XHTML: Syntax and Processing Rdfa in XHTML: Syntax and Processing
RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing A collection of attributes and processing rules for extending XHTML to support RDF W3C Recommendation 14 October 2008 This version: http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014 Latest version: http://www.w3.org/TR/rdfa-syntax Previous version: http://www.w3.org/TR/2008/PR-rdfa-syntax-20080904 Diff from previous version: rdfa-syntax-diff.html Editors: Ben Adida, Creative Commons [email protected] Mark Birbeck, webBackplane [email protected] Shane McCarron, Applied Testing and Technology, Inc. [email protected] Steven Pemberton, CWI Please refer to the errata for this document, which may include some normative corrections. This document is also available in these non-normative formats: PostScript version, PDF version, ZIP archive, and Gzip’d TAR archive. The English version of this specification is the only normative version. Non-normative translations may also be available. Copyright © 2007-2008 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. Abstract The current Web is primarily made up of an enormous number of documents that have been created using HTML. These documents contain significant amounts of structured data, which is largely unavailable to tools and applications. When publishers can express this data more completely, and when tools can read it, a new world of user functionality becomes available, letting users transfer structured data between applications and web sites, and allowing browsing applications to improve the user experience: an event on a web page can be directly imported - 1 - How to Read this Document RDFa in XHTML: Syntax and Processing into a user’s desktop calendar; a license on a document can be detected so that users can be informed of their rights automatically; a photo’s creator, camera setting information, resolution, location and topic can be published as easily as the original photo itself, enabling structured search and sharing. -

Sams Teach Yourself XML in 21 Days
Steven Holzner Teach Yourself XML in 21 Days THIRD EDITION 800 East 96th Street, Indianapolis, Indiana, 46240 USA Sams Teach Yourself XML in 21 Days, ASSOCIATE PUBLISHER Michael Stephens Third Edition ACQUISITIONS EDITOR Copyright © 2004 by Sams Publishing Todd Green All rights reserved. No part of this book shall be reproduced, stored in a retrieval DEVELOPMENT EDITOR system, or transmitted by any means, electronic, mechanical, photocopying, record- Songlin Qiu ing, or otherwise, without written permission from the publisher. No patent liability MANAGING EDITOR is assumed with respect to the use of the information contained herein. Although every precaution has been taken in the preparation of this book, the publisher and Charlotte Clapp author assume no responsibility for errors or omissions. Nor is any liability assumed PROJECT EDITOR for damages resulting from the use of the information contained herein. Matthew Purcell International Standard Book Number: 0-672-32576-4 INDEXER Library of Congress Catalog Card Number: 2003110401 Mandie Frank PROOFREADER Printed in the United States of America Paula Lowell First Printing: October 2003 TECHNICAL EDITOR 06050403 4321 Chris Kenyeres Trademarks TEAM COORDINATOR Cindy Teeters All terms mentioned in this book that are known to be trademarks or service marks have been appropriately capitalized. Sams Publishing cannot attest to the accuracy INTERIOR DESIGNER of this information. Use of a term in this book should not be regarded as affecting Gary Adair the validity of any trademark or service mark. COVER DESIGNER Warning and Disclaimer Gary Adair PAGE LAYOUT Every effort has been made to make this book as complete and as accurate as possi- ble, but no warranty or fitness is implied. -

Bibliography of Erik Wilde
dretbiblio dretbiblio Erik Wilde's Bibliography References [1] AFIPS Fall Joint Computer Conference, San Francisco, California, December 1968. [2] Seventeenth IEEE Conference on Computer Communication Networks, Washington, D.C., 1978. [3] ACM SIGACT-SIGMOD Symposium on Principles of Database Systems, Los Angeles, Cal- ifornia, March 1982. ACM Press. [4] First Conference on Computer-Supported Cooperative Work, 1986. [5] 1987 ACM Conference on Hypertext, Chapel Hill, North Carolina, November 1987. ACM Press. [6] 18th IEEE International Symposium on Fault-Tolerant Computing, Tokyo, Japan, 1988. IEEE Computer Society Press. [7] Conference on Computer-Supported Cooperative Work, Portland, Oregon, 1988. ACM Press. [8] Conference on Office Information Systems, Palo Alto, California, March 1988. [9] 1989 ACM Conference on Hypertext, Pittsburgh, Pennsylvania, November 1989. ACM Press. [10] UNIX | The Legend Evolves. Summer 1990 UKUUG Conference, Buntingford, UK, 1990. UKUUG. [11] Fourth ACM Symposium on User Interface Software and Technology, Hilton Head, South Carolina, November 1991. [12] GLOBECOM'91 Conference, Phoenix, Arizona, 1991. IEEE Computer Society Press. [13] IEEE INFOCOM '91 Conference on Computer Communications, Bal Harbour, Florida, 1991. IEEE Computer Society Press. [14] IEEE International Conference on Communications, Denver, Colorado, June 1991. [15] International Workshop on CSCW, Berlin, Germany, April 1991. [16] Third ACM Conference on Hypertext, San Antonio, Texas, December 1991. ACM Press. [17] 11th Symposium on Reliable Distributed Systems, Houston, Texas, 1992. IEEE Computer Society Press. [18] 3rd Joint European Networking Conference, Innsbruck, Austria, May 1992. [19] Fourth ACM Conference on Hypertext, Milano, Italy, November 1992. ACM Press. [20] GLOBECOM'92 Conference, Orlando, Florida, December 1992. IEEE Computer Society Press. http://github.com/dret/biblio (August 29, 2018) 1 dretbiblio [21] IEEE INFOCOM '92 Conference on Computer Communications, Florence, Italy, 1992. -

EAN.UCC XML Architectural Guide Version 1.0 July 2001
EAN·UCC System The Global Language of Business ® EAN.UCC XML Architectural Guide Version 1.0 July 2001 COPYRIGHT 2001, EAN INTERNATIONAL™ AND UNIFORM CODE COUNCIL, INC.Ô EAN.UCC Architectural Guide EAN·UCC System The Global Language of Business ® Table of Contents Document History........................................................................................................................ 4 1. Introduction............................................................................................................................ 5 1.1 Overview......................................................................................................................................................................... 5 1.1.1 Extensions in UML............................................................................................................................................... 5 1.1.1.1 Common Core Components ....................................................................................................................... 6 1.2 In A Nutshell: A Business Process Document......................................................................................................... 6 1.3 Other Related Documents ............................................................................................................................................ 7 2. Implementation Guidelines ..................................................................................................... 8 2.1 Schema Language ........................................................................................................................................................ -

Ontology Matching • Semantic Social Networks and Peer-To-Peer Systems
The web: from XML to OWL Rough Outline 1. Foundations of XML (Pierre Genevès & Nabil Layaïda) • Core XML • Programming with XML Development of the future web • Foundations of XML types (tree grammars, tree automata) • Tree logics (FO, MSO, µ-calculus) • Expressing information ! Languages • A taste of research: introduction to some grand challenges • Manipulating it ! Algorithms 2. Semantics of knowledge representation on the web (Jérôme Euzenat & • in the most correct, efficient and ! Logic Marie-Christine Rousset) meaningful way ! Semantics • Semantic web languages (URI, RDF, RDFS and OWL) • Querying RDF and RDFS (SPARQL) • Querying data though ontologies (DL-Lite) • Ontology matching • Semantic social networks and peer-to-peer systems 1 / 8 2 / 8 Foundations of XML Semantic web We will talk about languages, algorithms, and semantics for efficiently and meaningfully manipulating formalised knowledge. We will talk about languages, algorithms, and programming techniques for efficiently and safely manipulating XML data. You will learn about: You will learn about: • Expressing formalised knowledge on the semantic web (RDF) • Tree structured data (XML) ! Syntax and semantics ! Tree grammars & validation You will not learn about: • Expressing ontologies on the semantic • XML programming (XPath, XSLT...) You will not learn about: web (RDFS, OWL, DL-Lite) • Tagging pictures ! Queries & transformations ! Syntax and semantics • Hacking CGI scripts ! Reasoning • Sharing MP3 • Foundational theory & tools • HTML • Creating facebook ! Regular expressions