Performance Guarantees in Sample-Starved Space-Time Adaptive Processing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Error Control for the Detection of Rare and Weak Signatures in Massive Data Céline Meillier, Florent Chatelain, Olivier Michel, H Ayasso
Error control for the detection of rare and weak signatures in massive data Céline Meillier, Florent Chatelain, Olivier Michel, H Ayasso To cite this version: Céline Meillier, Florent Chatelain, Olivier Michel, H Ayasso. Error control for the detection of rare and weak signatures in massive data. EUSIPCO 2015 - 23th European Signal Processing Conference, Aug 2015, Nice, France. hal-01198717 HAL Id: hal-01198717 https://hal.archives-ouvertes.fr/hal-01198717 Submitted on 14 Sep 2015 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. ERROR CONTROL FOR THE DETECTION OF RARE AND WEAK SIGNATURES IN MASSIVE DATA Celine´ Meillier, Florent Chatelain, Olivier Michel, Hacheme Ayasso GIPSA-lab, Grenoble Alpes University, France n ABSTRACT a R the intensity vector. A few coefficients ai of a are 2 In this paper, we address the general issue of detecting rare expected to be non zero, and correspond to the intensities of and weak signatures in very noisy data. Multiple hypothe- the few sources that are observed. ses testing approaches can be used to extract a list of com- Model selection procedures are widely used to tackle this ponents of the data that are likely to be contaminated by a detection problem. -

A Frequency-Domain Adaptive Matched Filter for Active Sonar Detection
sensors Article A Frequency-Domain Adaptive Matched Filter for Active Sonar Detection Zhishan Zhao 1,2, Anbang Zhao 1,2,*, Juan Hui 1,2,*, Baochun Hou 3, Reza Sotudeh 3 and Fang Niu 1,2 1 Acoustic Science and Technology Laboratory, Harbin Engineering University, Harbin 150001, China; [email protected] (Z.Z.); [email protected] (F.N.) 2 College of Underwater Acoustic Engineering, Harbin Engineering University, Harbin 150001, China 3 School of Engineering and Technology, University of Hertfordshire, Hatfield AL10 9AB, UK; [email protected] (B.H.); [email protected] (R.S.) * Correspondence: [email protected] (A.Z.); [email protected] (J.H.); Tel.: +86-138-4511-7603 (A.Z.); +86-136-3364-1082 (J.H.) Received: 1 May 2017; Accepted: 29 June 2017; Published: 4 July 2017 Abstract: The most classical detector of active sonar and radar is the matched filter (MF), which is the optimal processor under ideal conditions. Aiming at the problem of active sonar detection, we propose a frequency-domain adaptive matched filter (FDAMF) with the use of a frequency-domain adaptive line enhancer (ALE). The FDAMF is an improved MF. In the simulations in this paper, the signal to noise ratio (SNR) gain of the FDAMF is about 18.6 dB higher than that of the classical MF when the input SNR is −10 dB. In order to improve the performance of the FDAMF with a low input SNR, we propose a pre-processing method, which is called frequency-domain time reversal convolution and interference suppression (TRC-IS). -

Anomaly Detection Based on Wavelet Domain GARCH Random Field Modeling Amir Noiboar and Israel Cohen, Senior Member, IEEE
IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING, VOL. 45, NO. 5, MAY 2007 1361 Anomaly Detection Based on Wavelet Domain GARCH Random Field Modeling Amir Noiboar and Israel Cohen, Senior Member, IEEE Abstract—One-dimensional Generalized Autoregressive Con- Markov noise. It is also claimed that objects in imagery create a ditional Heteroscedasticity (GARCH) model is widely used for response over several scales in a multiresolution representation modeling financial time series. Extending the GARCH model to of an image, and therefore, the wavelet transform can serve as multiple dimensions yields a novel clutter model which is capable of taking into account important characteristics of a wavelet-based a means for computing a feature set for input to a detector. In multiscale feature space, namely heavy-tailed distributions and [17], a multiscale wavelet representation is utilized to capture innovations clustering as well as spatial and scale correlations. We periodical patterns of various period lengths, which often ap- show that the multidimensional GARCH model generalizes the pear in natural clutter images. In [12], the orientation and scale casual Gauss Markov random field (GMRF) model, and we de- selectivity of the wavelet transform are related to the biological velop a multiscale matched subspace detector (MSD) for detecting anomalies in GARCH clutter. Experimental results demonstrate mechanisms of the human visual system and are utilized to that by using a multiscale MSD under GARCH clutter modeling, enhance mammographic features. rather than GMRF clutter modeling, a reduced false-alarm rate Statistical models for clutter and anomalies are usually can be achieved without compromising the detection rate. related to the Gaussian distribution due to its mathematical Index Terms—Anomaly detection, Gaussian Markov tractability. -

Coherent Detection
Coherent Detection Reading: • Ch. 4 in Kay-II. • (Part of) Ch. III.B in Poor. EE 527, Detection and Estimation Theory, # 5b 1 Coherent Detection (of A Known Deterministic Signal) in Independent, Identically Distributed (I.I.D.) Noise whose Pdf/Pmf is Exactly Known H0 : x[n] = w[n], n = 1, 2,...,N versus H1 : x[n] = s[n] + w[n], n = 1, 2,...,N where • s[n] is a known deterministic signal and • w[n] is i.i.d. noise with exactly known probability density or mass function (pdf/pmf). The scenario where the signal s[n], n = 1, 2,...,N is exactly known to the designer is sometimes referred to as the coherent- detection scenario. The likelihood ratio for this problem is QN p (x[n] − s[n]) Λ(x) = n=1 w QN n=1 pw(x[n]) EE 527, Detection and Estimation Theory, # 5b 2 and its logarithm is N−1 X hpw(x[n] − s[n])i log Λ(x) = log p (x[n]) n=0 w which needs to be compared with a threshold γ (say). Here is a schematic of our coherent detector: EE 527, Detection and Estimation Theory, # 5b 3 Example: Coherent Detection in AWGN (Ch. 4 in Kay-II) If the noise w[n] i.i.d.∼ N (0, σ2) (i.e. additive white Gaussian noise, AWGN) and noise variance σ2 is known, the likelihood- ratio test reduces to (upon taking log and scaling by σ2): N H 2 X 2 1 σ log Λ(x) = (x[n]s[n]−s [n]/2) ≷ γ (a threshold) (1) n=1 and is known as the correlator detector or simply correlator. -

Matched Filter
Matched Filter Documentation for explaining UAVRT-SDR’s current matched filter Flagstaff, AZ June 24, 2017 Edited by Michael Finley Northern Arizona University Dynamic and Active Systems Laboratory CONTENTS Matched Filter: Project Manual Contents 1 Project Description 3 2 Matched Filter Explanation 4 3 Methods/Procedures 11 4 MATLAB Processing 11 5 Recommendations 13 Page 2 of 13 Matched Filter: Project Manual 1 Project Description The aim of this project is to construct an unmanned aerial system that integrates a radio telemetry re- ceiver and data processing system for efficient detection and localization of tiny wildlife radio telemetry tags. Current methods of locating and tracking small tagged animals are hampered by the inaccessibility of their habitats. The high costs, risk to human safety, and small sample sizes resulting from current radio telemetry methods limit our understanding of the movement and behaviors of many species. UAV-based technologies promise to revolutionize a range of ecological field study paradigms due to the ability of a sensing platform to fly in close proximity to rough terrain at very low cost. The new UAV-based (UAV-RT) system will dramatically improve wildlife tracking capability while using inexpensive, commercially available radio tags. The system design will reflect the unique needs of wildlife tracking applications, including easy assembly and repair in the field and reduction of fire risk. Our effort will focus on the development, analysis, real-time implementation, and test of software-defined signal processing algorithms for RF signal detection and localization using unmanned aerial platforms. It combines (1) aspects of both wireless communication and radar signal processing, as well as modern statis- tical methods for model+data inference of RF source locations, and (2) fusion-based inference that draws on RF data from both mobile UAV-based receivers and ground-based systems operated by expert humans. -

MATCHED FILTERS •The Matched Filter Is the Optimal Linear Filter for Maximizing the Signal to Noise Ratio (SNR) in the Presence of Additive Stochastic Noise
MATCHED FILTERS •The matched filter is the optimal linear filter for maximizing the signal to noise ratio (SNR) in the presence of additive stochastic noise. •Matched filters are commonly used in radar, in which a signal is sent out, and we measure the reflected signals, looking for something similar to what was sent out. •Two-dimensional matched filters are commonly used in image processing, e.g., to improve SNR for X-ray pictures 1 • A general representation for a matched filter is illustrated in Figure 3-1 FIGURE 3-1 Matched filter 2 • The filter input x(t) consists of a pulse signal g(t) corrupted by additive channel noise w(t), as shown by (3.0) • where T is an arbitrary observation interval. The pulse signal g(t) may represent a binary symbol I or 0 in a digital communication system. • The w(t) is the sample function of a white noise process of zero mean and power spectral density No/2. • The source of uncertainty lies in the noise w(t). • The function of the receiver is to detect the pulse signal g(t) in an optimum manner, given the received signal x(t). • To satisfy this requirement, we have to optimize the design of the filter so as to minimize the effects of noise at the filter output in some statistical sense, and thereby enhance the detection of the pulse signal g(t). 3 • Since the filter is linear, the resulting output y(t) may be expressed as • (3.1) • where go(t) and n(t) are produced by the signal and noise components of the input x(t), respectively. -

Matched-Filter Ultrasonic Sensing: Theory and Implementation Zhaohong Zhang
White Paper SLAA814–December 2017 Matched-Filter Ultrasonic Sensing: Theory and Implementation Zhaohong Zhang ........................................................................................................... MSP Systems This document provides a detailed discussion on the operating theory of the matched-filter based ultrasonic sensing technology and the single-chip implementation platform using the Texas Instruments (TI) MSP430FR6047 microcontroller (MCU). Contents 1 Introduction ................................................................................................................... 2 2 Theory of Matched Filtering ................................................................................................ 2 3 MSP430FR6047 for Ultrasonic Sensing .................................................................................. 5 4 MSP430FR6047 USS Subsystem......................................................................................... 6 5 MSP430FR6047 Low Energy Accelerator (LEA) ........................................................................ 8 6 References ................................................................................................................... 9 List of Figures 1 Sonar in Target Range Measurement .................................................................................... 2 2 Concept of Pulse Compression............................................................................................ 2 3 Time-Domain Waveform and Autocorrelation of FM Chirp............................................................ -

Necessary Conditions for a Maximum Likelihood Estimate to Become Asymptotically Unbiased and Attain the Cramer–Rao Lower Bound
Necessary conditions for a maximum likelihood estimate to become asymptotically unbiased and attain the Cramer–Rao Lower Bound. Part I. General approach with an application to time-delay and Doppler shift estimation Eran Naftali and Nicholas C. Makris Massachusetts Institute of Technology, Room 5-222, 77 Massachusetts Avenue, Cambridge, Massachusetts 02139 ͑Received 17 October 2000; revised 20 April 2001; accepted 29 May 2001͒ Analytic expressions for the first order bias and second order covariance of a general maximum likelihood estimate ͑MLE͒ are presented. These expressions are used to determine general analytic conditions on sample size, or signal-to-noise ratio ͑SNR͒, that are necessary for a MLE to become asymptotically unbiased and attain minimum variance as expressed by the Cramer–Rao lower bound ͑CRLB͒. The expressions are then evaluated for multivariate Gaussian data. The results can be used to determine asymptotic biases, variances, and conditions for estimator optimality in a wide range of inverse problems encountered in ocean acoustics and many other disciplines. The results are then applied to rigorously determine conditions on SNR necessary for the MLE to become unbiased and attain minimum variance in the classical active sonar and radar time-delay and Doppler-shift estimation problems. The time-delay MLE is the time lag at the peak value of a matched filter output. It is shown that the matched filter estimate attains the CRLB for the signal’s position when the SNR is much larger than the kurtosis of the expected signal’s energy spectrum. The Doppler-shift MLE exhibits dual behavior for narrow band analytic signals. -

Matched Filtering As a Separation Tool – Review Example in Any Map
Matched Filtering as a Separation Tool – review example In any map of total magnetic intensity, various sources contribute components spread across the spatial frequency spectrum. A matched filter seeks to deconvolve the signal from one such source using parameters determined from the observations. In this example, we want to find an optimum filter which separates shallow and deep source layers. Matched filtering is a Fourier transform filtering method which uses model parameters determined from the natural log of the power spectrum in designing the appropriate filters. Assumptions: 1. A statistical model consisting of an ensemble of vertical sided prisms (i.e. Spector and Grant, 1970; Geophysics, v. 35, p. 293- 302). 2. The depth term exp(-2dk) is the dominate factor in the power spectrum: size and thickness terms for this example are ignored but they can have large impacts on the power spectrum. Depth estimates must be taken as qualitative. For a simple example, consider a magnetic data set, with two convolved components, in the spatial frequency (wavenumber) domain: ΔT = T(r) + T(s) where T(r) = regional component = C*exp(-k*D) T(s) = shallow component = c*exp(-k*d) D = depth to deep component d = depth to shallow component k = radial wavenumbers (2*pi/wavelength) c, C = constants including magnetization, unit conversions, field and magnetic directions. Substitute from above, and ΔT =C*exp(-k*D)+ c*exp(-k*d) factor out the deep term, and c ΔT = C*exp(-k*D)*(1+ *exp(k*(D-d))). C We now have the expression for the total field anomaly in the spatial frequency domain as: c ΔT = C*exp(-k*D) * [1+ *exp(k*(D-d))] C Note the term in brackets '[]'. -

A Simultaneous Maximum Likelihood Estimator Based on a Generalized Matched Filter
A simultaneous maximum likelihood estimator based on a generalized matched filter Gustavsson, Jan-Olof; Börjesson, Per Ola Published in: [Host publication title missing] DOI: 10.1109/ICASSP.1994.389775 1994 Link to publication Citation for published version (APA): Gustavsson, J-O., & Börjesson, P. O. (1994). A simultaneous maximum likelihood estimator based on a generalized matched filter. In [Host publication title missing] (pp. 481-484) https://doi.org/10.1109/ICASSP.1994.389775 Total number of authors: 2 General rights Unless other specific re-use rights are stated the following general rights apply: Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal Read more about Creative commons licenses: https://creativecommons.org/licenses/ Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. LUND UNIVERSITY PO Box 117 221 00 Lund +46 46-222 00 00 Download date: 25. Sep. 2021 A -

Matched Filters
Introduction to matched filters Introduction to matched filters John C. Bancroft ABSTRACT Matched filters are a basic tool in electrical engineering for extracting known wavelets from a signal that has been contaminated by noise. This is accomplished by cross- correlating the signal with the wavelet. The cross-correlation of the vibroseis sweep (a wavelet) with a recorded seismic signal is one geophysical application. Another geophysical application is found in Kirchhoff migrations, where the summing of energy in diffraction patterns is equivalent to a two-dimensional cross-correlation. The basic concepts of matched filters are presented with figures illustrating the applications in one and two dimensions. INTRODUCTION 1D model for matched filtering Matched filtering is a process for detecting a known piece of signal or wavelet that is embedded in noise. The filter will maximize the signal to noise ratio (SNR) of the signal being detected with respect to the noise. Consider the model in Figure 1 where the input signal is s(t) and the noise, n(t). The objective is to design a filter, h(t), that maximizes the SNR of the output, y(t). Signal s(t) Filter h(t) y(t) = sh(t) +nh(t) Noise n(t) FIG. 1: Basic filter If the input signal, s(t), is a wavelet, w(t), and n(t) is white noise, then matched filter theory states the maximum SNR at the output will occur when the filter has an impulse response that is the time-reverse of the input wavelet. Note that the convolution of the time-reversed wavelet is identical to cross-correlation of the wavelet with the wavelet (autocorrelation) in the input signal. -
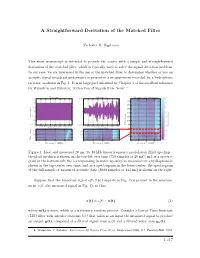
A Straightforward Derivation of the Matched Filter
A Straightforward Derivation of the Matched Filter Nicholas R: Rypkema This short manuscript is intended to provide the reader with a simple and straightforward derivation of the matched filter, which is typically used to solve the signal detection problem. In our case, we are interested in the use of the matched filter to determine whether or not an acoustic signal broadcast underwater is present in a measurement recorded by a hydrophone receiver, as shown in Fig. 1. It is in large part informed by Chapter 3 of the excellent reference by Wainstein and Zubakov, `Extraction of Signals from Noise' 1. Template Measured Measured Spectrogram 1.5 0.05 200 1 180 0.5 160 0 0 140 -0.5 Amplitude 120 -1 100 -1.5 -0.05 Time (ms) 80 0 100 200 300 400 500 600 700 0 100 200 300 400 500 600 700 Samples (n) Samples (n) 60 15 15 40 10 10 20 5 5 Time (ms) 05 10 15 05 10 15 05 10 15 Frequency (kHz) Frequency (kHz) Frequency (kHz) Figure 1: Ideal and measured 20 ms, 16{18 kHz linear frequency modulation (lfm) up-chirp { the ideal up-chirp is shown on the top-left over time (750 samples or 20 ms), and as a spectro- gram in the bottom-left; the corresponding in-water up-chirp as measured by a hydrophone is shown in the top-center over time, and as a spectrogram in the lower-center; the spectrogram of the full sample of measured acoustic data (8000 samples or 213 ms) is shown on the right.