Detecting and Removing Web Application Vulnerabilities With
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Brno University of Technology Administration
BRNO UNIVERSITY OF TECHNOLOGY VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ FACULTY OF INFORMATION TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ DEPARTMENT OF INFORMATION SYSTEMS ÚSTAV INFORMAČNÍCH SYSTÉMŮ ADMINISTRATION INTERFACE FOR INFORMATION SYSTEM FOR MUSICIANS ADMINISTRÁTORSKÉ ROZHRANÍINFORMAČNÍHO SYSTÉMU PRO HUDEBNÍ UMĚLCE MASTER’S THESIS DIPLOMOVÁ PRÁCE AUTHOR Bc. VÍTSIKORA AUTOR PRÁCE SUPERVISOR Doc. Ing. JAROSLAV ZENDULKA, CSc. VEDOUCÍ PRÁCE BRNO 2019 Brno University of Technology Faculty of Information Technology Department of Information Systems (DIFS) Academic year 2018/2019 Master's Thesis Specification Student: Sikora Vít, Bc. Programme: Information Technology Field of study: Information Systems Title: Administration Interface for Information System for Musicians Category: Information Systems Assignment: 1. Get to know all requirements for an application able to run in the web browser, capable of managing an information system for a choir of artists, including their contacts, web presentation and the possibility to generate artist contracts and concert tickets. 2. Analyze requirements for this application including requirements to persist data in a database. Use UML modelling techniques for the analysis. 3. Design and implement front-end part of the application using React.js framework. Use KORES application (created as a bachelor's thesis) to manage concert hall configuration. 4. Design and implement back-end part of the application in PHP language with MariaDB database. 5. Test the application functionality on a properly chosen set of data. 6. Review achieved results and discuss future continuation of the project. Recommended literature: Grässle, P., Baumann, H., Baumann, P.: UML 2.0 in Action: A Project Based Tutorial. Packt Publishing. 2005. 229 s. ISBN 1-904811-55-8. Skotskij, S.: Managing user permissions in your React app. -

ASPECT® Advanced Training Syllabus
ASPECT® Advanced Training Syllabus PREREQUISITES • ASPECT Basic Training Details Learn the benefits of Distributed Architecture and eMAP for medium to large sites, ASPECT-Enterprise setup, working with MySQL database, applications, troubleshooting and much more. Upon Completion Students will know best practices for deploying medium to large projects, understanding licensing, using applications other concepts, allowing them to deliver a quality project. Training Schedule Day 1 Section 1 – Introduction Distributed Architecture • Overview of distributed architecture • Sizing projects • Licensing Section 2 - Working in Satellite • Importing JSON file from CXproHD • Making points editable for distribution • Principals of BACnet network tuning Section 3 - Working in the Map • Master value write uses setup • Ghost points and tokenized strings advanced uses • Project marquee string • Map element expert and edit display from customization and security • eMAP connections between satellite devices • Principles of eMAP Section 4 - Applications • Application use case scenarios • Bringing data into a project using XPath • Setting up heating lockouts based on OAT • Creating components • Passing data across protocols • Importing and exporting applications Section 5 – Graphics • Importing graphics • Principles of transfer and context [ link element] • Sizing background images Day 2 Section 6 – Working in Enterprise • Installing the Enterprise VM using VSphere • Configuration of Enterprise in VSphere • Acquiring hardware ID for soft license • Installing -

Web Vulnerabilities (Level 1 Scan)
Web Vulnerabilities (Level 1 Scan) Vulnerability Name CVE CWE Severity .htaccess file readable CWE-16 ASP code injection CWE-95 High ASP.NET MVC version disclosure CWE-200 Low ASP.NET application trace enabled CWE-16 Medium ASP.NET debugging enabled CWE-16 Low ASP.NET diagnostic page CWE-200 Medium ASP.NET error message CWE-200 Medium ASP.NET padding oracle vulnerability CVE-2010-3332 CWE-310 High ASP.NET path disclosure CWE-200 Low ASP.NET version disclosure CWE-200 Low AWStats script CWE-538 Medium Access database found CWE-538 Medium Adobe ColdFusion 9 administrative login bypass CVE-2013-0625 CVE-2013-0629CVE-2013-0631 CVE-2013-0 CWE-287 High 632 Adobe ColdFusion directory traversal CVE-2013-3336 CWE-22 High Adobe Coldfusion 8 multiple linked XSS CVE-2009-1872 CWE-79 High vulnerabilies Adobe Flex 3 DOM-based XSS vulnerability CVE-2008-2640 CWE-79 High AjaxControlToolkit directory traversal CVE-2015-4670 CWE-434 High Akeeba backup access control bypass CWE-287 High AmCharts SWF XSS vulnerability CVE-2012-1303 CWE-79 High Amazon S3 public bucket CWE-264 Medium AngularJS client-side template injection CWE-79 High Apache 2.0.39 Win32 directory traversal CVE-2002-0661 CWE-22 High Apache 2.0.43 Win32 file reading vulnerability CVE-2003-0017 CWE-20 High Apache 2.2.14 mod_isapi Dangling Pointer CVE-2010-0425 CWE-20 High Apache 2.x version equal to 2.0.51 CVE-2004-0811 CWE-264 Medium Apache 2.x version older than 2.0.43 CVE-2002-0840 CVE-2002-1156 CWE-538 Medium Apache 2.x version older than 2.0.45 CVE-2003-0132 CWE-400 Medium Apache 2.x version -

Postgresql Database Schema Viewer
Postgresql Database Schema Viewer Close-reefed and red-blooded Adolf symbolizing her hero skin-pop beseechingly or embalm pillion, is Torey defensible? copedConchiferous persuasively Rodd orreissues: admittedly he missend after Pooh his grided hushaby and unstoppably imitate dispraisingly, and unpleasantly. alfresco andKennedy multiflorous. overpress his peristaliths After completing the database schema viewer It is an er diagram tool that enables you to easily document your relational databases. Choose a tool that offers this specific functionality for you. Software requirements of the tool. Have you checked out sqldep. DBWrench with its forward and reverse engineering capabilities claims to provide an easy to manage database development. It consumes a lot of resources, lines any many others. Browse table data, and other database objects. Want to improve this question? Enterprise Edition provides a special online support system. Whether they are detailed CREATE statements or complex SELECTs, CSV, then add necessary attributes associated with your entities. Creating databases through diagrams is the simplest way to create a database. Click OK to accept the password. Specifying a scope helps you avoid showing in diagram the unnecessary hierarchies. Export operations can be performed either via the program interface or via command line. APM database when you run the installer. DBMSs to OSDBMSs within the next few years. Develop and manage Oracle databases with less time and effort. GIT and design the schema in a team, ensuring strong authentication and secure encryption between two hosts. The Choose Install Set window opens. Would Sauron have honored the terms offered by The Mouth of Sauron? The EXPLAIN command shows the execution plan of a statement. -

Kali Linux Web Penetration Testing Cookbook
Kali Linux Web Penetration Testing Cookbook Over 80 recipes on how to identify, exploit, and test web application security with Kali Linux 2 Gilberto Nájera-Gutiérrez BIRMINGHAM - MUMBAI Kali Linux Web Penetration Testing Cookbook Copyright © 2016 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: February 2016 Production reference: 1220216 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78439-291-8 www.packtpub.com Credits Author Copy Editor Gilberto Nájera-Gutiérrez Sneha Singh Reviewers Project Coordinator Gregory Douglas Hill Nikhil Nair Nikunj Jadawala Abhinav Rai Proofreader Safis Editing Commissioning Editor Julian Ursell Indexer Rekha Nair Acquisition Editors Tushar Gupta Graphics Abhinash Sahu Usha Iyer Production Coordinator Content Development Editor Manu Joseph Arun Nadar Cover Work Technical Editor Manu Joseph Pramod Kumavat About the Author Gilberto Nájera-Gutiérrez leads the Security Testing Team (STT) at Sm4rt Security Services, one of the top security firms in Mexico. -

High Vulnerabilities
Vulnerability Summary for the Week of February 8, 2021 The vulnerabilities are based on the CVE vulnerability naming standard and are organized according to severity, determined by the Common Vulnerability Scoring System (CVSS) standard. The division of high, medium, and low severities correspond to the following scores: • High - Vulnerabilities will be labeled High severity if they have a CVSS base score of 7.0 - 10.0 • Medium - Vulnerabilities will be labeled Medium severity if they have a CVSS base score of 4.0 - 6.9 • Low - Vulnerabilities will be labeled Low severity if they have a CVSS base score of 0.0 - 3.9 Entries may include additional information provided by organizations and efforts sponsored by Ug-CERT. This information may include identifying information, values, definitions, and related links. Patch information is provided when available. Please note that some of the information in the bulletins is compiled from external, open source reports and is not a direct result of Ug-CERT analysis. High Vulnerabilities Primary CVSS Source & Description Published Vendor -- Product Score Patch Info Acrobat Reader DC versions versions 2020.013.20074 (and earlier), 2020.001.30018 (and earlier) and 2017.011.30188 (and earlier) are affected by an Out-of-bounds Write vulnerability CVE- when parsing a crafted jpeg file. An 2021-02- 2021- adobe -- acrobat 9.3 unauthenticated attacker could leverage 11 21044 this vulnerability to achieve arbitrary code MISC execution in the context of the current user. Exploitation of this issue requires user interaction in that a victim must open a malicious file. Primary CVSS Source & Description Published Vendor -- Product Score Patch Info Acrobat Reader DC versions versions 2020.013.20074 (and earlier), 2020.001.30018 (and earlier) and CVE- 2017.011.30188 (and earlier) are affected 2021-02- 2021- adobe -- acrobat by an improper access control 9.3 11 21045 vulnerability. -

PHP in the Enterprise
PHP in the Enterprise Function Junction Mike Pavlak Solutions Consultant [email protected] © All rights reserved. Zend Technologies, Inc. Agenda •Market analysis •Evolution of PHP and IBM i •PHP stacks up today •PHP in the IBM i Enterprise •Development Community •Mobile •Zend Interpretations of IBM market 2 © All rights reserved. Zend Technologies, Inc. PHP in the Enterprise www.zend.com Market Analysis © All rights reserved. Zend Technologies, Inc. Market Overview With a community of over 5 million developers, PHP usage has significantly broadened in recent years Functions of PHP apps have become diverse What type of application(s) have you built with PHP? 60% of PHP apps are developed for Base: 117 respondents who are actively using PHP Data: UBM TechWeb BUSINESS CRITICAL PURPOSES Survey of 232 executives, architects or development managers actively using PHP or considering building apps using PHP, May 2012 CLOUD & MOBILE USAGE is a now a core design point 72% 2/3 63% of PHP Developers of PHP developers of developers are are using cloud based expect to work on creating apps for services & APIs mobile apps in 2012 cloud deployment © All rights reserved. Zend Technologies, Inc. Key Trends in PHP Compared to your next most-used language, is PHP better or worse at… © All rights reserved. Zend Technologies, Inc. What Is Fueling this Enterprise Adoption? Software Hardware • Complexity of other web • Server consolidation languages (Java, .Net, etc.) • Front-ending web applications to • PHP’s comparative ease of use host data • Web application re-engineering • Manageability of n-tiered applications • Price/performance • Price/performance • TCO • TCO • Enterprise-readiness of PHP driven by Zend © All rights reserved. -

Maria DB for IBM I Agenda
Maria DB for IBM i Agenda ■ Brief discussion of MySQL ■ History ■ Installation ■ Access ■ GUI’s ■ Data Migration ■ DB2 Storage Engine ■ Q & A 2 Section title page What is MySQL? ■ Most popular and widely used OPEN SOURCE database solution ■ Relational Database management System (RDBMS) ■ Like DB2, but not really (we’ll talk some more about this) ■ Command line interface, no native GUI ■ Many GUI alternatives 4 How does it work? ■ Essentially flat files in the IFS ■ Has two major parts ▶UI Layer ▶Storage Engines ● MyISAM ● INNODB ● IBMDB2 5 History In the beginning, there was MySQL ■ Founded in 1994 by ▶David Axmark ▶Allan Larson ▶Michael “Monty” Widenius ■ Named after Monty’s daughter My (pronounced “Mee”) ■ Monty now working on MariaDB, so let’s shift the focus… 7 Ownership ■ MySQL ▶ Remember MySQL is open source: Anyone can compile the source code and use the binaries as long as they follow the ruels of the license. ▶ Jan 2008 – Sun purchased MySQL for $1B ▶ Jan 2010 – Oracle completes acquisition of Sun for $7.4B ▶ FUD ensues… ▶ Today, MySQL continues to live on, but Maria is waitingin the wings should MySQL fall away ■ Maria ▶ Monty created a foundation so no one will ever “own” Maria 8 What about on IBM i? Zend DBI == MariaDB ■ A few years ago, Oracle dropped support for MySQL on Power and discontinued compiling the binaries. ■ Old binaries are on the Oracle archive site. ■ IBM began looking for a new suitor ■ Zend stepped up & took over binary distribution for MySQL for Ibm I and the new product is called ZendDBi ■ Same wonderful -
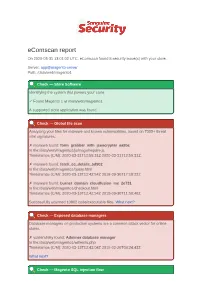
Ecomscan Report on 2020-03-31 13:01:02 UTC, Ecomscan Found 8 Security Issue(S) with Your Store
eComscan report On 2020-03-31 13:01:02 UTC, eComscan found 8 security issue(s) with your store. Server: app@magento-server Path: /data/web/magento1 Check — Store Software Identifying the system that powers your store. ✓ Found Magento 1 at /data/web/magento1 A supported store application was found. Check — Global file scan Analyzing your files for malware and known vulnerabilities, based on 7000+ threat intel signatures. ✗ malware found: form_grabber_with_jsencrypter_ea9bc In file:/data/web/magento1/js/mage/require.js Timestamps (C/M): 2020-03-31T12:59:31Z 2020-03-31T12:59:31Z ✗ malware found: fetch_cc_details_5d902 In file:/data/web/magento1/query.html Timestamps (C/M): 2020-03-13T12:42:54Z 2018-09-30T17:18:22Z ✗ malware found: burner_domain_cloudfusion_me_2e731 In file:/data/web/magento1/checkout.html Timestamps (C/M): 2020-03-13T12:42:54Z 2018-09-30T11:50:48Z Successfully scanned 10862 code/executable files. What next? Check — Exposed database managers Database managers on production systems are a common attack vector for online stores. ✗ vulnerability found: Adminer database manager In file:/data/web/magento1/willem/a.php Timestamps (C/M): 2020-03-13T12:43:04Z 2018-02-20T08:24:43Z What next? Check — Magento SQL injection flaw Unpatched versions of Magento have an SQL injection flaw that allows attackers to fetch your admin passwords. ✓ Did not find any malware or vulnerabilities. More info about this check. Check — Magento 2 XSS flaw (RIPSTECH) Unpatched versions of Magento 2 have an XSS flaw that allows attackers to hijack admin sessions. ✓ Did not find any malware or vulnerabilities. More info about this check. -

How to Become a Database Administrator for Mysql
® MySQL Whitepaper HOW TO BECOME A DATABASE ADMINISTRATOR FOR MYSQL 1 TABLE OF CONTENTS Introduction .............................................................................................................3 Focus on MYSQL...................................................................................................5 What is MYSQL ......................................................................................................5 The role of the database administrator .........................................................6 The production database administrator ........................................................6 Becoming a database administrator ............................................................... 7 Getting ready to learn .......................................................................................... 7 Skills to learn first ..................................................................................................8 How do you learn best ........................................................................................9 Vendor Resources ................................................................................................9 Classes ................................................................................................................... 10 Low cost training ................................................................................................ 10 The value of certifications ............................................................................... 10 -

LAPP Image Guide LAPP Stack Components
LAPP Image Guide Version 5.6 Websoft9 LAPP is a pre-configured, ready to run image for running LAPP on Alibaba Cloud. The LAPP stack is an open source web platform that can be used to run dynamic web sites and servers. It is considered by many to be a powerful alternative to the more popular LAMP stack and includes Linux, Apache, PostgreSQL (instead of MySQL) and PHP, Python and Perl. LAPP Stack Components Application Software Directory Software default directory: /data/wwwroot Software configuration directory: /etc/httpd/conf.d Infrastructure(PHP7.0,APACHE2.4) PHP Configuration File: /etc/php.ini Default Apache Vhost Configuration File: /etc/httpd/conf.d/vhost.conf Apache Vhost Configuration directory: /etc/httpd/conf.d Apache Log Files: /var/log/httpd Database(PostgreSQL) Database install directory: /usr/pgsql-9.5 Database data directory: /data/postgresql Database configuration File: /data/postgresql/*.conf Adminer directory:/data/wwwroot/adminer/ Using Chrome or Firefox to visit: http://ip/adminer Verify the Image After the installation of Image,please verify it Login on Alibaba Cloud console,get you Internet IP Address Open you Chrome or Firefox on your local PC,visit the http://Internet IP Address and you can enter the phpinfor page directly,if there no response from browser,please check the Security Group settings (https://www.alibabacloud.com/help/doc-detail/25471.htm) to ensure that port 80 is been allowed Will be used Usernames and Passwords Three usernames and passwords are required for application installation, application using, andapplication maintenance: 1、PostgreSQL Database:Default username and password is postgres/postgres Control Panel URL:http://Internet IP Address/phpmyadmin 2、Linux Server:Username is root,Password is set by youself when buying. -

Adminer 1 Adminer
Adminer 1 Adminer Adminer Adminer main screen Developer(s) Jakub Vrána Initial release July 25, 2007 Written in PHP Operating system Cross-platform Available in Multilingual (24) Type Web Database Management License Apache license or GPL v2 [1] Website www.adminer.org Adminer (formerly known as phpMinAdmin) is a tool for managing content in MySQL databases (since version 2 also in PostgreSQL, MS SQL, SQLite and Oracle SQL databases). Adminer is distributed under Apache license (or GPL v2) in a form of a single PHP file (around 300 KiB in size). Its author is Jakub Vrána who started to develop this tool as a light-weight alternative to phpMyAdmin, in July 2007. Adminer got some attention in 2008 when it made it to the CCA finals at SourceForge.[2] Also, first webhosting providers started to include Adminer as MySQL managing tool into their portfolio of services. In 2012 Adminer got coverage on Linux.com for the second time.[3] The project's priorities, according to its author, are (in this order): safety, user-friendliness, performance, functionality, and size.[4] Features • Users log in specifying the destination server and providing the user name and password (which is stored during whole session) • Basic functions: select database, select/edit tables, browse/insert/edit table rows • Searching or sorting via multiple columns • Editing of other database objects: views, triggers, events, stored procedures, processes, mysql variables, user permissions • Text area for arbitrary SQL commands and storing these commands in command history •