Influence Functions and Efficiencies of the Canonical Correlation and Vector
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

San Models; *Research Methodology; *Structural Equation
DOCUMENT RESUME ED 383 760 TM 023 293 AUTHOR Fan, Xitao TITLE Structural Equation Modeling and Canonical Correlation Analysis: What Do They Have in Common? PUB DATE Apr 95 NOTE 28p.; Paper presented at the Annual Meeting of the American Educational Research Association (San Francisco, CA, April 18-22, 1995). PUB TYPE Reports Evaluative/Feasibility (142) Speeches /Conference Papers (150) EDRS PRICE MF01/PCO2 Plus Postage. DESCRIPTORS Comparative Analysis; *Correlation; Mathematical Models; *Research Methodology; *Structural Equation Models ABSTRACT This paper, in a fashion easy to follow, illustrates the interesting relationship between structural equation modeling and canonical correlation analysis. Although computationally somewhat inconvenient, representing canonical correlation as a structural equation model may provide some information which is not available from conventional canonical correlation analysis. Hierarchically, with regard to the degree of generality of the techniques, it is suggested that structural equation modeling stands to be a more general approach. For researchers interested in these techniques, understanding the interrelationship among them is meaningful, since our judicious choice of these analytic techniques for our research depends on such understanding. Three tables and two figures present the data. (Contains 25 references.) (Author) *********************************************************************** Reproductions supplied by EDRS are the best that can be made from the original document. * *********************************************************************** -

In the Term Multivariate Analysis Has Been Defined Variously by Different Authors and Has No Single Definition
Newsom Psy 522/622 Multiple Regression and Multivariate Quantitative Methods, Winter 2021 1 Multivariate Analyses The term "multivariate" in the term multivariate analysis has been defined variously by different authors and has no single definition. Most statistics books on multivariate statistics define multivariate statistics as tests that involve multiple dependent (or response) variables together (Pituch & Stevens, 2105; Tabachnick & Fidell, 2013; Tatsuoka, 1988). But common usage by some researchers and authors also include analysis with multiple independent variables, such as multiple regression, in their definition of multivariate statistics (e.g., Huberty, 1994). Some analyses, such as principal components analysis or canonical correlation, really have no independent or dependent variable as such, but could be conceived of as analyses of multiple responses. A more strict statistical definition would define multivariate analysis in terms of two or more random variables and their multivariate distributions (e.g., Timm, 2002), in which joint distributions must be considered to understand the statistical tests. I suspect the statistical definition is what underlies the selection of analyses that are included in most multivariate statistics books. Multivariate statistics texts nearly always focus on continuous dependent variables, but continuous variables would not be required to consider an analysis multivariate. Huberty (1994) describes the goals of multivariate statistical tests as including prediction (of continuous outcomes or -

Multimodal Representation Learning Using Deep Multiset Canonical
MULTIMODAL REPRESENTATION LEARNING USING DEEP MULTISET CANONICAL CORRELATION ANALYSIS Krishna Somandepalli, Naveen Kumar, Ruchir Travadi, Shrikanth Narayanan Signal Analysis and Interpretation Laboratory, University of Southern California April 4, 2019 ABSTRACT We propose Deep Multiset Canonical Correlation Analysis (dMCCA) as an extension to represen- tation learning using CCA when the underlying signal is observed across multiple (more than two) modalities. We use deep learning framework to learn non-linear transformations from different modalities to a shared subspace such that the representations maximize the ratio of between- and within-modality covariance of the observations. Unlike linear discriminant analysis, we do not need class information to learn these representations, and we show that this model can be trained for com- plex data using mini-batches. Using synthetic data experiments, we show that dMCCA can effectively recover the common signal across the different modalities corrupted by multiplicative and additive noise. We also analyze the sensitivity of our model to recover the correlated components with respect to mini-batch size and dimension of the embeddings. Performance evaluation on noisy handwritten datasets shows that our model outperforms other CCA-based approaches and is comparable to deep neural network models trained end-to-end on this dataset. 1 Introduction and Background In many signal processing applications, we often observe the underlying phenomenon through different modes of signal measurement, or views or modalities. For example, the act of running can be measured by electrodermal activity, heart rate monitoring and respiratory rate. We refer to these measurements as modalities. These observations are often corrupted by sensor noise, as well as the variability of the signal across people, influenced by interactions with other physiological processes. -

Making Sense of Tourists' Photographs Using Canonical Variate
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Cronfa at Swansea University Making sense of tourists’ photographs using canonical variate analysis Nika Balomenou University of Hertfordshire Brian Garrod* Aberystwyth University Andri Georgiadou University of Hertfordshire * Corresponding author Professor of Tourism Management, School of Management and Business, Aberystwyth University, Rheidol Building, Llanbadarn Campus, Aberystwyth, Ceredigion, Wales, UK, SY23 3AL. Tel. 01970 621638. Email: [email protected] 1 Abstract (150 words): Tourists’ photographs can be a rich database for researchers wishing to study tourists’ perceptions and attitudes towards destinations. Such data can also be useful in examining how tourists behave, where, when, with whom and why. Many researchers favour the qualitative analysis of such data, which requires the use either of relatively small numbers of photographs or a considerable expense of researcher time and effort to undertake. Much of this process is speculative, in that it involves working with variables which may or may not prove to be significant in addressing the hypotheses set for the research. This research note recommends the use of a preliminary phase of research in which a quantitative approach is used to reduce the number of variables needing to be coded. Canonical variate analysis is suggested as an appropriate tool for achieving this. Case study results are presented to demonstrate the utility of this approach. Keywords: Tourists, Photographs; Canonical -

Canonical Correlation Analysis As the General Linear Model
DOCUMENT RESUME ED 408 308 TM 026 521 AUTHOR Vidal, Sherry TITLE Canonical Correlation Analysis as the General Linear Model. PUB DATE Jan 97 NOTE 35p.; Paper presented at the Annual Meeting of the Southwest Educational Research Association (Austin, TX, January 1997). PUB TYPE Reports Evaluative (142) Speeches/Meeting Papers (150) EDRS PRICE MF01/PCO2 Plus Postage. DESCRIPTORS *Correlation; Heuristics; *Multivariate Analysis; *Regression (Statistics); Satisfaction; Synthesis IDENTIFIERS *F Test; *General Linear Model ABSTRACT The concept of the general linear model (GLM) is illustrated and how canonical correlation analysis is the GLM is explained, using a heuristic data set to demonstrate how canonical correlation analysis subsumes various multivariate and univariate methods. The paper shows how each of these analyses produces a synthetic variable, like the Yhat variable in regression. Ultimately these synthetic variables are actually analyzed in all statistics, a fact that is important to researchers who want to understand the substance of their statistical analysis. The illustrative (fictitious) example involves the relationship between a set of marital happiness characteristics, including a marital satisfaction score and a frequency of sex score, and a set of personal characteristics, which includes IQ scores and overall religiosity. The latent constructs, marital happiness and personal characteristics, are the sets of variables that are examined. A brief summary of the canonical correlation analysis is presented, and how canonical correlation subsumes regression, factorial analysis of variance, and T-tests is discussed. The discussion makes it clear that the "F" statistic is not the sole statistic of interest to researchers. The use of canonical correlation as GLM can help students and researchers comprehend the similarities between models as well as the different statistics that are important in all analyses, such as synthetic variables. -

Canonical Correlation Analysis
Canonical Correlation Analysis LEARNING OBJECTIVES Upon completing this chapter, you should be able to do the following: State the similarities and differences between multiple regression, factor analysis, discriminant analysis, and canonical correlation. Summarize the conditions that must be met for application of canonical correlation analysis. State what the canonical root measures and point out its limitations. State how many independent canonical functions can be defined between the two sets of original variables. Compare the advantages and disadvantages of the three methods for interpreting the nature of canonical functions. Define redundancy and compare it with multiple regression’s R2. CHAPTER PREVIEW Until recent years, canonical correlation analysis was a relatively unknown statistical technique. As with almost all of the multivariate techniques, the availability of computer programs has facilitated its increased application to research problems. It is particularly useful in situations in which multiple output measures such as satisfaction, purchase, or sales volume are available. If the independent variables were only categorical, multivariate analysis of variance could be used. But what if the independent variables are metric? Canonical correlation is the answer, allowing for the assessment of the relationship between metric independent variables and multiple dependent measures. Canonical correlation is considered to be the general model on which many other multivariate techniques are based because it can use both metric and nonmetric data for either the dependent or independent variables. We express the general form of canonical analysis as Y1 + Y2 + Y3 + ... + Yn = X1 + X2+ X3 + ... + Xn (metric, nonmetric) (metric, nonmetric) This chapter introduces the researcher to the multivariate statistical technique of canonical correlation analysis. -
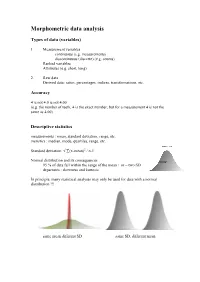
Morphometric Data Analysis
Morphometric data analysis Types of data (variables) 1. Measurement variables continuous (e.g. measurements) discontinuous (discrete) (e.g. counts) Ranked variables Attributes (e.g. short, long) 2. Raw data Derived data: ratios, percentages, indices, transformations, etc. Accuracy 4 is not 4.0 is not 4.00 (e.g. the number of teeth, 4 is the exact number; but for a measurement 4 is not the same as 4.00) Descriptive statistics measurements : mean, standard deviation, range, etc. meristics : median, mode, quartiles, range, etc. Standard deviation: (x-mean)2 / n-1 Normal distribution and its consequences 95 % of data fall within the range of the mean + or – two SD departures : skewness and kurtosis In principle, many statistical analyses may only be used for data with a normal distribution !!! same mean different SD same SD, different mean Anova : assumptions random sampling (choice of specimens) independence = random error (measuring) normal distribution homogeneity of variances (homoscedasticity) Manova = similar but in a multidimensional space Correlation and regression Two variates are related correlation: the intensity of the relationship regression: expresses the form of the relationship (predictive) Allometry Y=bX log Y = log b + log X (log b = intercept; =slope) Non-parametric tests (univariate) Kruskal-Wallis, Mann-Whitney U, Wilcoxon, Kolmogorov-Smirnov, Wald-Wolfowitz, etc. Used as a substitute for parametric tests (t-test, F-test etc, anova). They are also called distribution-free tests. Data do not have to be normally distributed. -

Principal Component Analysis, Second Edition
Principal Component Analysis, Second Edition I.T. Jolliffe Springer Preface to the Second Edition Since the first edition of the book was published, a great deal of new ma- terial on principal component analysis (PCA) and related topics has been published, and the time is now ripe for a new edition. Although the size of the book has nearly doubled, there are only two additional chapters. All the chapters in the first edition have been preserved, although two have been renumbered. All have been updated, some extensively. In this updat- ing process I have endeavoured to be as comprehensive as possible. This is reflected in the number of new references, which substantially exceeds those in the first edition. Given the range of areas in which PCA is used, it is certain that I have missed some topics, and my coverage of others will be too brief for the taste of some readers. The choice of which new topics to emphasize is inevitably a personal one, reflecting my own interests and biases. In particular, atmospheric science is a rich source of both applica- tions and methodological developments, but its large contribution to the new material is partly due to my long-standing links with the area, and not because of a lack of interesting developments and examples in other fields. For example, there are large literatures in psychometrics, chemometrics and computer science that are only partially represented. Due to consid- erations of space, not everything could be included. The main changes are now described. Chapters 1 to 4 describing the basic theory and providing a set of exam- ples are the least changed. -

Regularized Consensus PCA ∑
Regularized Consensus PCA Michel Tenenhaus (1), Arthur Tenenhaus (2), Patrick J. F. Groenen (3) (1) HEC Paris, Jouy-en-Josas, France, [email protected] (2) CentraleSupélec-L2S, UMR CNRS 8506, Gif-sur-Yvette, France and Bioinformatics- Biostatistics Platform IHU-A-ICM, Paris, France, [email protected] (3) Econometric Institute, Erasmus School of Economics, Erasmus University, Rotterdam, [email protected] Abstract A new framework for many multiblock component methods (including consensus and hierarchical PCA) is proposed. It is based on the consensus PCA model: a scheme connecting each block of variables to a superblock obtained by concatenation of all blocks. Regularized consensus PCA is obtained by applying regularized generalized canonical correlation analysis to this scheme for the function gx() xm where m 1. A gradient algorithm is proposed. At convergence, a solution of the stationary equation related to the optimization problem is obtained. For m = 1, 2 or 4 and shrinkage constants equal to 0 or 1, many multiblock component methods are recovered. Keywords: Consensus PCA, hierarchical PCA, multiblock component methods, regularized generalized canonical correlation analysis. 1. Introduction In this paper, we consider several data matrices XXX1,...,bB ,..., . Each nJ b data matrix Xb is called a block and represents a set of Jb variables observed on n individuals. The number and the nature of the variables usually differ from one block to another but the individuals must be the same across blocks. We assume that all variables are centered. Generalized canonical correlation analysis (Carroll, 1968a), consensus PCA (Westerhuis, Kourti, and MacGregor, 1998) and hierarchical PCA (Smilde, Westerhuis, and de Jong, 2003) can be considered as methods extending PCA of variables to PCA of blocks of variables. -

Canonical Correlation Analysis (CCA)
C Canonical Correlation Analysis Canonical The latent variables (one per data variates table) computed in CCA (also called canonical variables, Hervé Abdi1, Vincent Guillemot2, Aida Eslami3 canonical variable scores, or and Derek Beaton4 canonical factor scores). The 1School of Behavioral and Brain Sciences, The canonical variates have maximal University of Texas at Dallas, Richardson, TX, correlation. USA Canonical The set of coefficients of the linear 2Bioinformatics and Biostatistics Hub, Institut vectors combinations used to compute the Pasteur (IP), C3BI, USR 3756 CNRS, Paris, canonical variates, also called France canonical weights. Canonical 3Centre for Heart Lung Innovation, University of vectors are also sometimes called British Columbia, Vancouver, BC, Canada canonical loadings. 4Rotman Research Institute, Baycrest Health Latent A linear combination of the Sciences, Toronto, ON, Canada variable variables of one data table. In general, a latent variable is Synonyms computed to satisfy some predefined criterion. Canonical analysis; Canonical variate analysis; Definition External factor analysis. Canonical correlation analysis (CCA) is a statisti- Glossary cal method whose goal is to extract the informa- tion common to two data tables that measure quantitative variables on a same set of observa- Canonical Correlation between two canonical tions. To do so, CCA creates pairs of linear com- correlation variates of the same pair. This is the binations of the variables (one per table) that have criterion optimized by CCA. maximal correlation. Canonical Correlation between the original loadings variables and the canonical variates. Sometimes used as a synonym for canonical vectors (because these quantities differ only by their normalization). # Springer Science+Business Media LLC 2018 R. Alhajj, J. -

Tilburg University the Use of Canonical Analysis Kuylen, A.A.A
Tilburg University The use of canonical analysis Kuylen, A.A.A.; Verhallen, T.M.M. Published in: Journal of Economic Psychology Publication date: 1981 Link to publication in Tilburg University Research Portal Citation for published version (APA): Kuylen, A. A. A., & Verhallen, T. M. M. (1981). The use of canonical analysis. Journal of Economic Psychology, 1, 217-237. General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. Download date: 28. sep. 2021 7 21 Journal f Economio , c Psycholog (19811 y ) 217-237 North-Holland Publishing Company THE USE OF CANONICAL ANALYSIS Anton A.A. KUYLE Thed Nan o M.M. VERHALLEN* Tilburg University, NetherlandsThe Received August 25, 1980; accepted April 20, 1981 e firsTh t par f thio t s non-technical revie f canonicawo l analysi concernes si d wit principlee hth e ,th data requirements interpretatione th , evaluatioe , th applicatioe th d nan consumen ni r researcf ho canonical analysis. -

Functional Linear Regression Via Canonical Analysis
Bernoulli 16(3), 2010, 705–729 DOI: 10.3150/09-BEJ228 Functional linear regression via canonical analysis GUOZHONG HE1, HANS-GEORG MULLER¨ 2,*, JANE-LING WANG2,** and WENJING YANG2,† 1University of California, San Francisco, Institute for Health and Aging and California Diabetes Program, California Department of Public Health P.O. Box 997377, MS 7211, Sacramento, CA 95899-7377, USA. E-mail: [email protected] 2Department of Statistics, University of California, One Shields Avenue, Davis, CA 95616, USA. E-mail: *[email protected]; **[email protected]; †[email protected] We study regression models for the situation where both dependent and independent variables are square-integrable stochastic processes. Questions concerning the definition and existence of the corresponding functional linear regression models and some basic properties are explored for this situation. We derive a representation of the regression parameter function in terms of the canonical components of the processes involved. This representation establishes a connec- tion between functional regression and functional canonical analysis and suggests alternative approaches for the implementation of functional linear regression analysis. A specific procedure for the estimation of the regression parameter function using canonical expansions is proposed and compared with an established functional principal component regression approach. As an example of an application, we present an analysis of mortality data for cohorts of medflies, obtained in experimental studies of aging and longevity. Keywords: canonical components; covariance operator; functional data analysis; functional linear model; longitudinal data; parameter function; stochastic process 1. Introduction With the advancement of modern technology, data sets which contain repeated measure- arXiv:1102.5212v1 [math.ST] 25 Feb 2011 ments obtained on a dense grid are becoming ubiquitous.