Structural Classification and Properties of Ketoacyl Synthases and Biotin-Dependent Carboxylases Yingfei Chen Iowa State University
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Thesis, Dissertation
THE COENZYME M BIOSYNTHETIC PATHWAY IN PROTEOBACTERIUM XANTHOBACTER AUTOTROPHICUS PY2 by Sarah Eve Partovi A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Biochemistry MONTANA STATE UNIVERSITY Bozeman, Montana January 2018 ©COPYRIGHT by Sarah Eve Partovi 2018 All Rights Reserved ii DEDICATION I dedicate this dissertation to my family, without whom none of this would have been possible. My husband Ky has been a part of the graduate school experience since day one, and I am forever grateful for his support. My wonderful family; Iraj, Homa, Cameron, Shireen, Kevin, Lin, Felix, Toby, Molly, Noise, Dooda, and Baby have all been constant sources of encouragement. iii ACKNOWLEDGEMENTS First, I would like to acknowledge Dr. John Peters for his mentorship, scientific insight, and for helping me gain confidence as a scientist even during the most challenging aspects of this work. I also thank Dr. Jennifer DuBois for her insightful discussions and excellent scientific advice, and my other committee members Dr. Brian Bothner and Dr. Matthew Fields for their intellectual contributions throughout the course of the project. Drs. George Gauss and Florence Mus have contributed greatly to my laboratory technique and growth as a scientist, and have always been wonderful resources during my time in the lab. Members of the Peters Lab past and present have all played an important role during my time, including Dr. Oleg Zadvornyy, Dr. Jacob Artz, and future Drs. Gregory Prussia, Natasha Pence, and Alex Alleman. Undergraduate researchers/REU students including Hunter Martinez, Andrew Gutknecht and Leah Connor have worked under my guidance, and I thank them for their dedication to performing laboratory assistance. -

Transcriptional Regulation of the Acetone Carboxylase Operon Via Two-Component Signal Transduction in Helicobacter Pylori
W&M ScholarWorks Undergraduate Honors Theses Theses, Dissertations, & Master Projects 7-2012 Transcriptional Regulation of the Acetone Carboxylase Operon via Two-Component Signal Transduction in Helicobacter pylori Samuel Emerson Harvey College of William and Mary Follow this and additional works at: https://scholarworks.wm.edu/honorstheses Part of the Biology Commons Recommended Citation Harvey, Samuel Emerson, "Transcriptional Regulation of the Acetone Carboxylase Operon via Two- Component Signal Transduction in Helicobacter pylori" (2012). Undergraduate Honors Theses. Paper 471. https://scholarworks.wm.edu/honorstheses/471 This Honors Thesis is brought to you for free and open access by the Theses, Dissertations, & Master Projects at W&M ScholarWorks. It has been accepted for inclusion in Undergraduate Honors Theses by an authorized administrator of W&M ScholarWorks. For more information, please contact [email protected]. Transcriptional Regulation of the Acetone Carboxylase Operon via Two- Component Signal Transduction in Helicobacter pylori A thesis submitted in partial fulfillment of the requirement for the degree of Bachelor of Science in Biology from The College of William & Mary By Samuel Emerson Harvey Accepted for ____________________________ (Honors) _______________________________________ Dr. Mark Forsyth, Chair _______________________________________ Dr. Oliver Kerscher _______________________________________ Dr. Kurt Williamson _______________________________________ Dr. Randolph Coleman Williamsburg, VA April 30, 2012 Abstract Helicobacter pylori is a gram negative gastric pathogen that infects the mucosal lining of the human stomach and is present is nearly half of the human population. H. pylori is the etiologic agent of peptic ulcer disease, and infection is highly associated with the development of gastric cancer. The H. pylori genome encodes three complete two- component signal transduction systems (TCSTs): ArsRS, CrdRS, and FlgRS. -

Anti-Inflammatory Role of Curcumin in LPS Treated A549 Cells at Global Proteome Level and on Mycobacterial Infection
Anti-inflammatory Role of Curcumin in LPS Treated A549 cells at Global Proteome level and on Mycobacterial infection. Suchita Singh1,+, Rakesh Arya2,3,+, Rhishikesh R Bargaje1, Mrinal Kumar Das2,4, Subia Akram2, Hossain Md. Faruquee2,5, Rajendra Kumar Behera3, Ranjan Kumar Nanda2,*, Anurag Agrawal1 1Center of Excellence for Translational Research in Asthma and Lung Disease, CSIR- Institute of Genomics and Integrative Biology, New Delhi, 110025, India. 2Translational Health Group, International Centre for Genetic Engineering and Biotechnology, New Delhi, 110067, India. 3School of Life Sciences, Sambalpur University, Jyoti Vihar, Sambalpur, Orissa, 768019, India. 4Department of Respiratory Sciences, #211, Maurice Shock Building, University of Leicester, LE1 9HN 5Department of Biotechnology and Genetic Engineering, Islamic University, Kushtia- 7003, Bangladesh. +Contributed equally for this work. S-1 70 G1 S 60 G2/M 50 40 30 % of cells 20 10 0 CURI LPSI LPSCUR Figure S1: Effect of curcumin and/or LPS treatment on A549 cell viability A549 cells were treated with curcumin (10 µM) and/or LPS or 1 µg/ml for the indicated times and after fixation were stained with propidium iodide and Annexin V-FITC. The DNA contents were determined by flow cytometry to calculate percentage of cells present in each phase of the cell cycle (G1, S and G2/M) using Flowing analysis software. S-2 Figure S2: Total proteins identified in all the three experiments and their distribution betwee curcumin and/or LPS treated conditions. The proteins showing differential expressions (log2 fold change≥2) in these experiments were presented in the venn diagram and certain number of proteins are common in all three experiments. -

Supplemental Methods
Supplemental Methods: Sample Collection Duplicate surface samples were collected from the Amazon River plume aboard the R/V Knorr in June 2010 (4 52.71’N, 51 21.59’W) during a period of high river discharge. The collection site (Station 10, 4° 52.71’N, 51° 21.59’W; S = 21.0; T = 29.6°C), located ~ 500 Km to the north of the Amazon River mouth, was characterized by the presence of coastal diatoms in the top 8 m of the water column. Sampling was conducted between 0700 and 0900 local time by gently impeller pumping (modified Rule 1800 submersible sump pump) surface water through 10 m of tygon tubing (3 cm) to the ship's deck where it then flowed through a 156 µm mesh into 20 L carboys. In the lab, cells were partitioned into two size fractions by sequential filtration (using a Masterflex peristaltic pump) of the pre-filtered seawater through a 2.0 µm pore-size, 142 mm diameter polycarbonate (PCTE) membrane filter (Sterlitech Corporation, Kent, CWA) and a 0.22 µm pore-size, 142 mm diameter Supor membrane filter (Pall, Port Washington, NY). Metagenomic and non-selective metatranscriptomic analyses were conducted on both pore-size filters; poly(A)-selected (eukaryote-dominated) metatranscriptomic analyses were conducted only on the larger pore-size filter (2.0 µm pore-size). All filters were immediately submerged in RNAlater (Applied Biosystems, Austin, TX) in sterile 50 mL conical tubes, incubated at room temperature overnight and then stored at -80oC until extraction. Filtration and stabilization of each sample was completed within 30 min of water collection. -

Purification and Characterization of Acetone Carboxylase from Xanthobacter Strain Py2
Proc. Natl. Acad. Sci. USA Vol. 94, pp. 8456–8461, August 1997 Biochemistry Purification and characterization of acetone carboxylase from Xanthobacter strain Py2 MIRIAM K. SLUIS AND SCOTT A. ENSIGN* Department of Chemistry and Biochemistry, Utah State University, Logan, UT 84322-0300 Communicated by R. H. Burris, University of Wisconsin, Madison, WI, June 9, 1997 (received for review March 24, 1997) ABSTRACT Acetone metabolism in the aerobic bacte- aerobic, Gram-negative bacterium (14). The metabolism of rium Xanthobacter strain Py2 proceeds by a carboxylation acetone by Xanthobacter Py2 was recently shown to proceed by reaction forming acetoacetate as the first detectable product. aCO2-dependent pathway analogous to that discussed above In this study, acetone carboxylase, the enzyme catalyzing this (3). The carboxylation of acetone to form acetoacetate was reaction, has been purified to homogeneity and characterized. reconstituted in cell extracts with the addition of ATP (3). This Acetone carboxylase was comprised of three polypeptides with study provided the first direct evidence for the involvement of molecular weights of 85,300, 78,300, and 19,600 arranged in an an ATP-dependent carboxylase in bacterial acetone metabo- a2b2g2 quaternary structure. The carboxylation of acetone lism. In this study, acetone carboxylase has been purified to was coupled to the hydrolysis of ATP and formation of 1 mol homogeneity. The molecular properties of acetone carboxylase AMP and 2 mol inorganic phosphate per mol acetoacetate are described, and evidence for a novel mechanism of acetone formed. ADP was also formed during the course of acetone carboxylation coupled to ATP hydrolysis and AMP and inor- consumption, but only accumulated at low, substoichiometric ganic phosphate formation is presented. -

(12) United States Patent (10) Patent No.: US 9,334,531 B2 Li Et Al
USOO933.4531B2 (12) United States Patent (10) Patent No.: US 9,334,531 B2 Li et al. (45) Date of Patent: *May 10, 2016 (54) NUCLECACIDAMPLIFICATION (56) References Cited U.S. PATENT DOCUMENTS (71) Applicant: LIFE TECHNOLOGIES 5,223,414 A 6/1993 Zarling et al. CORPORATION, Carlsbad, CA (US) 5,616,478 A 4/1997 Chetverin et al. 5,670,325 A 9/1997 Lapidus et al. (72) Inventors: Chieh-Yuan Li, El Cerrito, CA (US); 5,928,870 A 7/1999 Lapidus et al. David Ruff, San Francisco, CA (US); 5,958,698 A 9, 1999 Chetverinet al. Shiaw-Min Chen, Fremont, CA (US); 6,001,568 A 12/1999 Chetverinet al. 6,033,881 A 3/2000 Himmler et al. Jennifer O'Neil, Wakefield, MA (US); 6,074,853. A 6/2000 Pati et al. Rachel Kasinskas, Amesbury, MA (US); 6,306,590 B1 10/2001 Mehta et al. Jonathan Rothberg, Guilford, CT (US); 6.432,360 B1 8, 2002 Church Bin Li, Palo Alto, CA (US); Kai Qin 6,440,706 B1 8/2002 Vogelstein et al. Lao, Pleasanton, CA (US) 6,511,803 B1 1/2003 Church et al. 6,929,915 B2 8, 2005 Benkovic et al. (73) Assignee: Life Technologies Corporation, 7,270,981 B2 9, 2007 Armes et al. 7,282,337 B1 10/2007 Harris Carlsbad, CA (US) 7,399,590 B2 7/2008 Piepenburg et al. 7.432,055 B2 * 10/2008 Pemov et al. ................ 435/6.11 (*) Notice: Subject to any disclaimer, the term of this 7,435,561 B2 10/2008 Piepenburg et al. -

Complete Thesis
University of Groningen Omega transaminases: discovery, characterization and engineering Palacio, Cyntia Marcela IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document version below. Document Version Publisher's PDF, also known as Version of record Publication date: 2019 Link to publication in University of Groningen/UMCG research database Citation for published version (APA): Palacio, C. M. (2019). Omega transaminases: discovery, characterization and engineering. Rijksuniversiteit Groningen. Copyright Other than for strictly personal use, it is not permitted to download or to forward/distribute the text or part of it without the consent of the author(s) and/or copyright holder(s), unless the work is under an open content license (like Creative Commons). The publication may also be distributed here under the terms of Article 25fa of the Dutch Copyright Act, indicated by the “Taverne” license. More information can be found on the University of Groningen website: https://www.rug.nl/library/open-access/self-archiving-pure/taverne- amendment. Take-down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. Downloaded from the University of Groningen/UMCG research database (Pure): http://www.rug.nl/research/portal. For technical reasons the number of authors shown on this cover page is limited to 10 maximum. Download date: 01-10-2021 Omega transaminases: discovery, characterization and engineering Cyntia Marcela Palacio 2019 Cover design by Cyntia Palacio and Joris Goudsmits, adapted from a decorative mosaic artwork on the railway underpass on Moesstraat, Groningen. -

Stabilization of Fatty Acid Synthesis Enzyme Acetyl-Coa Carboxylase 1 Suppresses Acute Myeloid Leukemia Development
Stabilization of fatty acid synthesis enzyme acetyl-CoA carboxylase 1 suppresses acute myeloid leukemia development Hidenori Ito, … , Jun-ya Kato, Noriko Yoneda-Kato J Clin Invest. 2021;131(12):e141529. https://doi.org/10.1172/JCI141529. Research Article Oncology Graphical abstract Find the latest version: https://jci.me/141529/pdf The Journal of Clinical Investigation RESEARCH ARTICLE Stabilization of fatty acid synthesis enzyme acetyl-CoA carboxylase 1 suppresses acute myeloid leukemia development Hidenori Ito, Ikuko Nakamae, Jun-ya Kato, and Noriko Yoneda-Kato Laboratory of Tumor Cell Biology, Division of Biological Science, Graduate School of Science and Technology, Nara Institute of Science and Technology, Nara, Japan. Cancer cells reprogram lipid metabolism during their malignant progression, but limited information is currently available on the involvement of alterations in fatty acid synthesis in cancer development. We herein demonstrate that acetyl- CoA carboxylase 1 (ACC1), a rate-limiting enzyme for fatty acid synthesis, plays a critical role in regulating the growth and differentiation of leukemia-initiating cells. The Trib1-COP1 complex is an E3 ubiquitin ligase that targets C/EBPA, a transcription factor regulating myeloid differentiation, for degradation, and its overexpression specifically induces acute myeloid leukemia (AML). We identified ACC1 as a target of the Trib1-COP1 complex and found that an ACC1 mutant resistant to degradation because of the lack of a Trib1-binding site attenuated complex-driven leukemogenesis. Stable ACC1 protein expression suppressed the growth-promoting activity and increased ROS levels with the consumption of NADPH in a primary bone marrow culture, and delayed the onset of AML with increases in mature myeloid cells in mouse models. -

Verrucomicrobial Methanotrophs Grow on Diverse C3 Compounds and Use
www.nature.com/ismej ARTICLE OPEN Verrucomicrobial methanotrophs grow on diverse C3 compounds and use a homolog of particulate methane monooxygenase to oxidize acetone 1 1 1 2 3 fi 4 Samuel Imisi Awala , Joo-Han Gwak , Yong-Man Kim ✉, So-Jeong Kim , Andrea Strazzulli , Peter F. Dun eld , Hyeokjun Yoon5, Geun-Joong Kim6 and Sung-Keun Rhee 1 © The Author(s) 2021 Short-chain alkanes (SCA; C2-C4) emitted from geological sources contribute to photochemical pollution and ozone production in the atmosphere. Microorganisms that oxidize SCA and thereby mitigate their release from geothermal environments have rarely been studied. In this study, propane-oxidizing cultures could not be grown from acidic geothermal samples by enrichment on propane alone, but instead required methane addition, indicating that propane was co-oxidized by methanotrophs. “Methylacidiphilum” isolates from these enrichments did not grow on propane as a sole energy source but unexpectedly did grow on C3 compounds such as 2-propanol, acetone, and acetol. A gene cluster encoding the pathway of 2-propanol oxidation to pyruvate via acetol was upregulated during growth on 2-propanol. Surprisingly, this cluster included one of three genomic operons (pmoCAB3) encoding particulate methane monooxygenase (PMO), and several physiological tests indicated that the encoded PMO3 enzyme mediates the oxidation of acetone to acetol. Acetone-grown resting cells oxidized acetone and butanone but not methane or propane, implicating a strict substrate specificity of PMO3 to ketones instead of alkanes. Another PMO-encoding operon, pmoCAB2, was induced only in methane-grown cells, and the encoded PMO2 could be responsible for co-metabolic oxidation of propane to 2-propanol. -

Physiology and Biochemistry of Aromatic Hydrocarbon-Degrading Bacteria That Use Chlorate And/Or Nitrate As Electron Acceptor
Invitation for the public defense of my thesis Physiology and biochemistry of aromatic hydrocarbon-degrading of aromatic and biochemistry Physiology bacteria that use chlorate and/or nitrate as electron acceptor as electron nitrate and/or use chlorate that bacteria Physiology and biochemistry Physiology and biochemistry of aromatic hydrocarbon-degrading of aromatic hydrocarbon- degrading bacteria that bacteria that use chlorate and/or nitrate as electron acceptor use chlorate and/or nitrate as electron acceptor The public defense of my thesis will take place in the Aula of Wageningen University (Generall Faulkesweg 1, Wageningen) on December 18 2013 at 4:00 pm. This defense is followed by a reception in Café Carré (Vijzelstraat 2, Wageningen). Margreet J. Oosterkamp J. Margreet Paranimphs Ton van Gelder ([email protected]) Aura Widjaja Margreet J. Oosterkamp ([email protected]) Marjet Oosterkamp (911 W Springfield Ave Apt 19, Urbana, IL 61801, USA; [email protected]) Omslag met flap_MJOosterkamp.indd 1 25-11-2013 5:58:31 Physiology and biochemistry of aromatic hydrocarbon-degrading bacteria that use chlorate and/or nitrate as electron acceptor Margreet J. Oosterkamp Thesis-MJOosterkamp.indd 1 25-11-2013 6:42:09 Thesis committee Thesis supervisor Prof. dr. ir. A. J. M. Stams Personal Chair at the Laboratory of Microbiology Wageningen University Thesis co-supervisors Dr. C. M. Plugge Assistant Professor at the Laboratory of Microbiology Wageningen University Dr. P. J. Schaap Assistant Professor at the Laboratory of Systems and Synthetic Biology Wageningen University Other members Prof. dr. L. Dijkhuizen, University of Groningen Prof. dr. H. J. Laanbroek, University of Utrecht Prof. -

A Diverse Superfamily of Enzymes with ATP-Dependent Carboxylate-Amine/Thiol Ligase Activity
Prorein Science (1997). 6:2639-2643. Cambridge University Press. Printed in the USA. Copyright 0 1997 The Protein Society FOR THE RECORD A diverse superfamily of enzymes with ATP-dependent carboxylate-amine/thiol ligase activity MICHAEL Y. GALPERIN AND EUGENE V. KOONIN National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Bethesda, Maryland 20894 (RECEIVEDJune 12, 1997; ACCEFTEDSeptember 8, 1997) Abstract: The recently developed PSI-BLAST method for se- et al., 1997). All these enzymes catalyze a reaction that involves an quence database search and methods for motif analysis were used ATP-dependent ligation of a carboxyl group carbon of one sub- to define and expand a superfamily of enzymes with an unusual strate with an amino or imino group nitrogen of the second one and nucleotide-binding fold, referred to as palmate, or ATP-grasp fold. includes, in each case, the formation of acylphosphate intermedi- In addition to D-alanine-D-alanine ligase, glutathione synthetase, ates (Gushima et al., 1983; Ogita& Knowles, 1988; Meister, 1989; biotin carboxylase, and carbamoyl phosphate synthetase, enzymes Fan et al., 1994). Structural alignment of DD-ligase, GSHase, and with known three-dimensional structures, the ATP-grasp domain is BCase revealed threeconserved motifs, corresponding to the predicted in the ribosomal protein S6 modification enzyme (RimK), phosphate-binding loop and the Mg2+-binding site of the ATP- urea amidolyase, tubulin-tyrosine ligase, and three enzymes of binding domain (Artymiuk et al., 1996). In each of these enzymes, purine biosynthesis. All these enzymes possess ATP-dependent ATP binds in a cleft formed by two structural elements, each carboxylate-amine ligase activity, and their catalytic mechanisms containing two antiparallel P-strands and a loop (Hibi etal., 1996). -
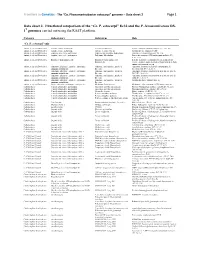
Ca. P. Ectocarpi” Ec32 and the P
Frontiers in Genetics - The “Ca. Phaeomarinobacter ectocarpi” genome – Data sheet 2 Page 1 Data sheet 2. Functional comparison of the “Ca. P. ectocarpi” Ec32 and the P. lavamentivorans DS- 1T genomes carried out using the RAST platform. Category Subcategory Subsystem Role “Ca. P. ectocarpi” only Amino Acids and Derivatives Alanine, serine, and glycine Alanine biosynthesis Valine--pyruvate aminotransferase (EC 2.6.1.66) Amino Acids and Derivatives Alanine, serine, and glycine Glycine cleavage system Sodium/glycine symporter GlyP Amino Acids and Derivatives Arginine; urea cycle, polyamines Arginine and Ornithine Degradation Ornithine cyclodeaminase (EC 4.3.1.12) Amino Acids and Derivatives Arginine; urea cycle, polyamines Polyamine Metabolism Putrescine transport ATP-binding protein PotA (TC 3.A.1.11.1) Amino Acids and Derivatives Branched-chain amino acids Branched-Chain Amino Acid Leucine-responsive regulatory protein, regulator for Biosynthesis leucine (or lrp) regulon and high-affinity branched-chain amino acid transport system Amino Acids and Derivatives Glutamine, glutamate, aspartate, asparagine; Glutamate and Aspartate uptake in Glutamate Aspartate periplasmic binding protein ammonia assimilation Bacteria precursor GltI (TC 3.A.1.3.4) Amino Acids and Derivatives Glutamine, glutamate, aspartate, asparagine; Glutamate and Aspartate uptake in Glutamate Aspartate transport system permease protein ammonia assimilation Bacteria GltJ (TC 3.A.1.3.4) Amino Acids and Derivatives Glutamine, glutamate, aspartate, asparagine; Glutamate and Aspartate