How and Why Standardized Tests Systematically Underestimate
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Review of Standardized Testing Practices and Perceptions in Maine
A Review of Standardized Testing Practices and Perceptions in Maine Janet Fairman, Ph.D. Amy Johnson, Ph.D. Ian Mette, Ph.D Garry Wickerd, Ph.D. Sharon LaBrie, M.S. April 2018 Maine Education Policy Research Institute Maine Education Policy Research Institute McLellan House, 140 School Street 5766 Shibles Hall, Room 314 Gorham, ME 04038 Orono, ME 04469-5766 207.780.5044 or 1.888.800.5044 207.581.2475 Published by the Maine Education Policy Research Institute in the Center for Education Policy, Applied Research, and Evaluation (CEPARE) in the School of Education and Human Development, University of Southern Maine, and the Maine Education Policy Research Institute in the School of Education and Human Development at the University of Maine at Orono. The Maine Education Policy Research Institute (MEPRI), is jointly funded by the Maine State Legislature and the University of Maine System. This institute was established to conduct studies on Maine education policy and the Maine public education system for the Maine Legislature. Statements and opinions by the authors do not necessarily reflect a position or policy of the Maine Education Policy Research Institute, nor any of its members, and no official endorsement by them should be inferred. The University of Maine System does not discriminate on the basis of race, color, religion, sex, sexual orientation, national origin or citizenship status, age, disability, or veteran's status and shall comply with Section 504, Title IX, and the A.D.A in employment, education, and in all other areas of the University. The University provides reasonable accommodations to qualified individuals with disabilities upon request. -

Nine Facts About the SAT That Might Surprise You
Nine Facts About the SAT That Might Surprise You By Lynn Letukas COLLEGE BOARD RESEARCH Statistical Report RESEARCH Executive Summary The purpose of this document is to identify and dispel rumors that are frequently cited about the SAT. The following is a compilation of nine popular rumors organized into three areas: Student Demographics, Test Preparation/Test Prediction, and Test Utilization. Student Demographics Student demographics claims are those that primarily center around a specific demographic group that is said to over-/underperform on the SAT. Presumably, it is reasoned, if the SAT were a fair test, no student demographic characteristics would matter, as average scores would be similar across groups. Therefore, some people assume that any difference in SAT performance by demographics must indicate test bias for/against a demographic group. Rumor 1: The SAT Is a Wealth Test. According to Peter Sacks, author of Standardized Minds, “one can make a good guess about a child’s standardized test scores simply by looking at how many degrees her parents have and what kind of car they drive.”1 This comment is illustrative of frequent criticism that the SAT is merely a “wealth test” because there is a correlation between student scores and socioeconomic status (i.e., parental income and educational attainment). Proponents of this claim often support their arguments by stating that the SAT only covers content that is learned by wealthy students, rather than material covered in high school.2 Fact: Rigorous Course Taking in High School Better Explains Why Students Do Well (or Not) on the SAT. While SAT scores may be correlated with socioeconomic status (parental income and education), correlation does not mean two phenomena are causally related (e.g., parental income causes students to do well on the SAT). -

Public School Admissions and the Myth of Meritocracy: How and Why Screened Public School Admissions Promote Segregation
BUERY_FIN.DOCX(DO NOT DELETE) 4/14/20 8:46 PM PUBLIC SCHOOL ADMISSIONS AND THE MYTH OF MERITOCRACY: HOW AND WHY SCREENED PUBLIC SCHOOL ADMISSIONS PROMOTE SEGREGATION RICHARD R. BUERY, JR.* Public schools in America remain deeply segregated by race, with devastating effects for Black and Latinx students. While residential segregation is a critical driver of school segregation, the prevalence of screened admissions practices can also play a devastating role in driving racial segregation in public schools. New York City, one of the most segregated school systems in America, is unique in its extensive reliance on screened admissions practices, including the use of standardized tests, to assign students to sought-after public schools. These screens persist despite their segregative impact in part because they appeal to America’s embrace of the idea of meritocracy. This Article argues that Americans embrace three conceptions of merit which shield these screens from proper scrutiny. The first is individual merit—the idea that students with greater ability or achievement deserve access to better schools. The second is systems merit—the idea that poor student performance on an assessment is a failure of the system that prepared the student for the assessment. The third is group merit—the idea that members of some groups simply possess less ability. Each of these ideas has a pernicious impact on perpetuating racial inequality in public education. INTRODUCTION ................................................................................. 102 I. THE APPEAL OF THREE DIMENSIONS OF MERIT .................... 104 A. Merit of the Individual .................................................... 104 B. Merit of the System ......................................................... 107 C. Merit of the Group .......................................................... 109 II. THE MYTH OF MERITOCRACY IN K12 ADMISSIONS ............. -

Rethinking School Accountability: Opportunities for Massachusetts
RETHINKING SCHOOL ACCOUNTABILITY OPPORTUNITIES FOR MASSACHUSETTS UNDER THE EVERY STUDENT SUCCEEDS ACT Senator Patricia D. Jehlen, Chair Senate Sub-committee to the Joint Committee on Education May 2018 The special Senate Subcommittee to the Joint Committee on Education was established per order of the Massachusetts State Senate in February, 2017: Ms. Chang-Díaz presented the following order, to wit: Ordered, That there shall be a special Senate sub-committee to the Joint Committee on Education, to consist of five members from the current Senate membership on the Joint Committee on Education, chaired by the Senate vice chair of the Joint Committee on Education, for the purpose of making an investigation and study of the Commonwealth’s alignment with and opportunities presented by the Every Student Succeeds (ESSA) Act, Public Law 114-95. The subcommittee shall submit its report and related legislation, if any, to the joint committee on Education once its report is completed. Senate Sub-committee chair and report author Senator Patricia D. Jehlen, with gratitude to those who contributed ideas, data, and comments Senate Sub-committee Members: Senator Michael J. Barrett Senator Jason M. Lewis Senator Barbara A. L'Italien Senator Patrick M. O'Connor Staff: Victoria Halal, Matthew Hartman, Emily Wilson, Kat Cline, Dennis Burke, Erin Riley, Sam Anderson, Daria Afshar Sponsored Events: (6/13/17) Panel Discussion: Life & Learning in MA Turnaround Schools https://www.youtube.com/watch?v=KbErK6rLQAY&t=2s (12/12/17) Mildred Avenue School Site Visit -

Sat-Act-Study-Report.Pdf
Executive Summary For many years, high school grade-point average (HSGPA) and standardized test scores (i.e. SAT/ACT) have served as the two most important and relied upon college admissions criteria. However, there is constant debate about whether HSGPA and SAT/ACT are fair measures of college preparation and valid predictors of college success, and whether SAT/ACT should remain as a requirement for college admissions. Supporters of standardized tests argue that SAT/ACT evaluates college-preparedness on an equal standing despite inconsistent grading systems throughout the nation’s high schools. While HSGPA compares a student to the rest of his/her school, SAT/ACT scores compare the student to the rest of the country. Opponents of standardized tests argue that SAT/ACT is biased towards white, upper middle class students from high performing schools. Focusing on HSGPA in college admissions may help foster racial and socioeconomic diversity in the college student population. Previous research generally treats standardized test results as measures of college preparation. The literature surrounding the predictive validity of standardized test scores on student success is mixed. Many studies found a statistically significant association between SAT/ACT scores and college outcomes including first-year college GPA, first-year retention, four-year graduation, and graduation GPA. On the other hand, research also shows that demographic predictors weakened the ability of SAT/ACT scores to be effective predictors of college success. In light of previous research, this report presents the results of separate studies on the relationship among HSGPA, standardized tests, and demographics, and explanatory power of test scores for college success based on UC’s application and enrollment data. -

Getting High School Students Ready for College: a Quantitative Study of Standards- Based Grading Practices
Getting High School Students Ready for College: A Quantitative Study of Standards- Based Grading Practices Matt Townsley, [email protected], University of West Georgia Matt Varga, [email protected], University of West Georgia Some high schools are moving towards standards-based grading in an attempt to produce consistent grading practices; however, the change’s impact on college readiness is not clear. The purpose of this study was to explore the effect of high school’s grading practices as it relates to ACT scores and grade point averages (GPAs). Existing data were collected from two comparable high schools using different grading practices in a Midwestern state as determined by state department of education-provided demographics: enrollment, socioeconomic status (as defined by percentage of students receiving free or reduced lunch), and ethnicity. Stepwise multiple linear regressions were used to determine if GPA and the method of high school grading practices, standards-based grading or traditional grading, used predict ACT scores. The findings revealed GPAs remain unchanged and ACT scores may be negatively impacted when high schools utilize standards-based grading practices. In addition, traditional grading practices were a small factor combined with GPA in predicting ACT scores. Keywords: grading, standards-based grading, college admissions exams, high school Journal of Research in Education, Volume 28, Issue 1 93 / Townsley & Varga Educational scholars agree grading is a highly subjective aspect of public schooling and has been for over 100 years (Allen, 2005; Brimi, 2011; Cureton, 1971; Schinske & Tanner, 2014; Schneider & Hutt, 2013; Starch & Elliott, 1912). Jeffrey Erickson (2010) calls grading the “third rail” of education due to the long held beliefs permeating classrooms across the country. -

Chapter 1: a Review of the Nature of Standardized Tests
01-Kennedy.qxd 04-02-03 2:37 PM Page 1 1 A Review of the Nature of Standardized Tests his chapter presents an overview of standardized tests T and their applications in education. The first section pre- sents a brief historical review of standardized testing in schools. This is followed by a discussion of the nature of these tests and their uses in education. Several technical terms (e.g., reliability) are introduced and discussed. ABRIEF HISTORY OF STANDARDIZED TESTING IN AMERICA Large-scale standardized testing in the United States can be traced to the First World War. At the beginning of U.S. involvement in the war, the military was overwhelmed with volunteers. At the time, much of the country, including the 1 01-Kennedy.qxd 04-02-03 2:37 PM Page 2 2 Raising Test Scores for All Students military, was deeply immersed in the efficiency movement. The idea, borrowed from the industrial workplace, was to use input, including human capital, in such a manner as to maxi- mize output and minimize waste. Subscribing to this idea, the U.S. military was committed to finding scientific ways to max- imize the efficiency with which it used human capital for its war machine. A solution was offered by leaders of the American Psychological Association (APA). Headed by Robert Yerkes, the APA proposed developing an objective and scientific way for planners to allocate men to positions in the military hierarchy. Yerkes and his colleagues proposed and developed two tests designed to measure the mental ages of recruits and volunteers. -
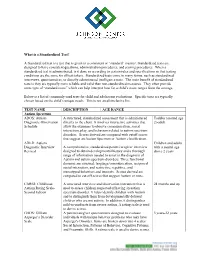
What Is a Standardized Test?
What is a Standardized Test? A Standardized test is a test that is given in a consistent or “standard” manner. Standardized tests are designed to have consistent questions, administration procedures, and scoring procedures. When a standardized test is administrated, is it done so according to certain rules and specifications so that testing conditions are the same for all test takers. Standardized tests come in many forms, such as standardized interviews, questionnaires, or directly administered intelligence tests. The main benefit of standardized tests is they are typically more reliable and valid than non-standardized measures. They often provide some type of “standard score” which can help interpret how far a child’s score ranges from the average. Below is a list of commonly used tests for child and adolescent evaluations. Specific tests are typically chosen based on the child’s unique needs. This is not an all-inclusive list. TEST NAME DESCRIPTION AGE RANGE Autism Spectrum ADOS: Autism A structured, standardized assessment that is administered Toddler (around age Diagnostic Observation directly to the client. It involves interactive activities that 2)-adult Schedule allow the examiner to observe communication, social interaction, play, and behaviors related to autism spectrum disorders. Scores derived are compared with cutoff scores that suggest an Autism Spectrum or Autism classification. ADI-R: Autism Children and adults Diagnostic Interview A comprehensive, standardized parent/caregiver interview with a mental age Revised designed to obtain developmental history and a thorough above 2 years range of information needed to assist in the diagnosis of Autism and autism spectrum disorders. Three functional domains are assessed: language/communication, reciprocal social interaction, and restrictive, repetitive, and stereotyped behaviors and interests. -

The Roles of Standardized Reading Tests in Schools
LITERACY LEADERSHIP BRIEF The Roles of Standardized Reading Tests in Schools International Literacy Association | 2017 tandardized tests have a long history of being the go-to measure of student reading achievement, teacher ac- complishment, and school accountability. Given this habit of history, it is predictable that a single stan- Sdardized reading test score is often considered the indicator of student reading growth and achievement. Yet standardized reading tests come with a host of conse- quences. Test scores are used to deem particular schools ex- emplary or substandard. From these designations, there may follow an exodus of students to for-profit charter schools or a reconstitution of the teaching corps of an entire school. Real es- tate prices rise and fall in relation to the neighborhood school’s testing profile, as test scores are used as a proxy for school quality. Test scores teach students that they are “above aver- age,” “average,” or “below average.” In contrast to this power and these consequences, standard- Standardized reading tests ized reading tests are limited in their ability to describe stu- are limited in their ability to dents’ reading needs and to inform reading instruction. describe students’ reading needs and to inform reading Roles and Uses of Standardized Tests instruction. The roles, or uses, of standardized tests can be described with- out endorsing them. These include assessing student achieve- ment, comparing students, evaluating programs, creating educational policy, and determining accountability. Assessing Student Achievement We expect that students will further develop as literate individ- uals as a result of schooling. Standardized tests provide annual before (near the beginning of a school year) and after (near the end of the school year) appraisals of this student development. -

The Effect of Standardized Testing on Historical Literacy and Educational Reform in the U.S
The Effect of Standardized Testing on Historical Literacy and Educational Reform in the U.S. Julie Hisey Maranto Fort Hays State University Masters of Liberal Arts Student Humanities Public education in America has an impressive history of success in equipping students with literacy that extends back to the earliest days of our nation. Education was a high priority for the original settlers in America who, motivated by their religious convictions, eagerly sought mastery and dissemination of literacy skills throughout the population. For most of the Protestant settlers, their beliefs derived from the doctrines of the Reformation and they considered the ability to read as a fundamental necessity for grounding citizens in the tenets of their faith as well as their government. The first law in the colonies pertaining to education was passed by the Massachusetts General Court to instill literacy, religion, and civic responsibility in students. The law, passed in 1642, instructed that children must be able to “read and understand the principles of religion and the capital laws of the country” and, in addition, addressed the negligence and lack of concern they felt many parents showed toward the education of their children (Good, 1962, p. 29). Local officials, known as selectmen, were assigned the duty of seeing that the law was obeyed. In the event that they came upon a child not being taught adequately, the selectmen had the authority to establish an apprenticeship for the child with someone who would assume that responsibility (Good, 1962). Many of those in leadership, including George Washington, Thomas Jefferson, Benjamin Rush, and Noah Webster, considered education, particularly in preparation for “civic duty,” as essential to the maintenance of the newly formed republic. -

Standards-Based Assessment and High Stakes Testing
STANDARDS-BASED ASSESSMENT AND HIGH STAKES TESTING: ACCURACY OF STANDARDS-BASED GRADING by Amity C. Hardegree Liberty University A Dissertation Presented in Partial Fulfillment Of the Requirements for the Degree Doctor of Education Liberty University July, 2012 ii STANDARDS-BASED ASSESSMENT AND HIGH STAKES TESTING: ACCURACY OF STANDARDS-BASED GRADING by Amity Christa Hardegree A Dissertation Presented in Partial Fulfillment Of the Requirements for the Degree Doctor of Education Liberty University, Lynchburg, VA July, 2012 APPROVED BY: Kenneth Gossett, Ph.D., Committee Chair April Howard, Ed.D., Committee Member Rebecca Harrison, Ed.D., Committee Member Scott B. Watson, Ph.D., Associate Dean, Advanced Programs iii ABSTRACT Amity C. Hardegree. STANDARDS-BASED ASSESSMENT AND HIGH STAKES TESTING: ACCURACY OF STANDARDS-BASED GRADING. (Under the direction of Dr. Kenneth Gossett) School of Education, Liberty University, Summer, 2012. This quantitative study examines whether standards-based grade reporting accurately informs student academic achievement on standardized criterion-referenced tests for all students. The participants for this study were all fifth graders enrolled in eight elementary schools in a rural system in north Georgia from 2009-2010. Approximately 550 students’ standards-based report cards (SBRC) and Criterion Referenced Competency Tests (CRCT) provide the data to determine whether grades on standards-based report cards provide accurate information for all students, regardless of gender, ELL status, or socioeconomic status by comparing mean scores on Georgia’s CRCT in the areas of math and reading, based on SBRC indicators. The findings of this study provide strong implications for school systems considering a standards-based grading reporting system in response to the recent movement towards standards-based curriculums. -

Glossary of Testing, Measurement, and Statistical Terms
hmhco.com HMH ASSESSMENTS Glossary of Testing, Measurement, and Statistical Terms Resource: Joint Committee on the Standards for Educational and Psychological Testing of the AERA, APA, and NCME. (2014). Standards for educational and psychological testing. Washington, DC: American Educational Research Association. Glossary of Testing, Measurement, and Statistical Terms Ability – A characteristic indicating the level of an individual on a particular trait or competence in a particular area. Often this term is used interchangeably with aptitude, although aptitude actually refers to one’s potential to learn or to develop a proficiency in a particular area. For comparison see Aptitude. Ability/Achievement Discrepancy – Ability/Achievement discrepancy models are procedures for comparing an individual’s current academic performance to others of the same age or grade with the same ability score. The ability score could be based on predicted achievement, the general intellectual ability score, IQ score, or other ability score. Scores for each academic area are compared to the corresponding cognitive ability score in one of these areas to see if the individual is achieving at the level one would expect based on their ability level. See also: Predicted Achievement, Achievement Test, and Ability Testing. Ability Profile – see Profile. Ability Testing – The use of standardized tests to evaluate the current performance of a person in some defined domain of cognitive, psychomotor, or physical functioning. Accommodation – A testing accommodation, refers to a change in the standard procedures for administering the assessment. Accommodations do not change the kind of achievement being measured. If chosen appropriately, an accommodation will neither provide too much or too little help to the student who receives it.