A Model Driven Regression Testing Pattern for Enhancing Agile Release Management
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Security Testing
ISSN 1866-5705 www.testingexperience.com free digital version print version 8,00 € printed in Germany 6 The Magazine for Professional Testers The MagazineforProfessional Security Testing © iStockphoto/alexandru_lamba June, 2009 © iStockphoto/Manu1174 ISTQB® Certified Tester Foundation Level for only 499,- € plus VAT ONLINE TRAINING English & German www.testingexperience.learntesting.com Certified Tester Advanced Level coming soon Editorial Dear readers, One of my professors at the university said once to all of us: Computer scientists are at some point criminals. What he meant was that we or some of us – computer scientists – at some point like to try things that are not that “legal”. The most of us are “clean”, but some of us are “free time hackers”! Nowadays the hackers are almost away from the 17 years old guy, trying to pen- etrate in some website and so on. They are now adults, with families, cars, pets, holidays and a job. They are professionals earning money for acting as such. Application Security is not only important and essential for the companies and their businesses, technology and employees. Application Security is a macroeco- nomic aspect for the countries. There are a lot of secret services or governments agencies working on getting technology or information by advance hacking the server and databases of top companies or governments worldwide. When we hear that some countries could be behind the penetration of the USA electricity net- work, you can imagine what is going on outside. Are we testers prepared for that job? I’m not! Last year we had the first tutorial by Manu Cohen about Application Security Testing. -

Agile Automated Software Testing Into Automotive V-Model Process
Agile automated software testing into automotive V-Model process: A practical case Xavier Martin Artal Software QA Manager [email protected] es.linkedin.com/pub/xavier-martin/6/a89/723/ Agenda • Introduction • Automotive Trends: Car Connectivity • Car Telematics project Challenges • Use Case Solution: From V-Model to Agile Testing • Results and Conclusions Introduction What is this presentation about? • Expose a practical case of adoption of Agile techniques in automotive testing • Converge Spice automotive V-Model to Agile Spice V-Model Agile • Present Technical Solution adopted: Automation Test Framework • Discuss results and Agile adequacy to Automotive industry Automotive Trends: Vehicle Connectivity Car Telematics • Car Manufacturers start to add 3G/4G capabilities • Connectivity opens new opportunities to develop services for both clients and manufacturers Connectivity Services – Emergency Call – Fleet Management – Car Sharing – Remote Car Diagnostics – Stolen Vehicle Tracking (SVT) – WOTA Update – Dealer Services – User Premium Services Car telematics: eCall • Emergency Call Service for Europe • U.E Council proposes eCall obligatory in European Cars for end 2017 • Automatic call in case of accident or emergency will force car manufacturers to add IVTU to every new car for European Service • Similar regulations for Russia, USA, BRA and PRC Car Telematics Project Challenges What is an iVTU? iVTU = in Vehicle Telematics Unit - Electronic Unit in charge of granting 2G/3G/LTE connectivity to vehicles - Two Main processors architecture: -

Agile Testing: Your Key to Better Software
Agile Testing: Your Key to Better Software What’s in the Way of Testing at the Speed Of practitioners say testing is of Agile? 63% the biggest 1 Testing at the speed of agile drives quality at speed. But the bottleneck question is, “When do you think the testing process should begin?” If you answered something like “after the code is written”, or “once developers hand it off to QA”, you are not thinking Continuous Testing. To truly achieve continuous testing, you need shift left-all the way left. The challenge is to enable requirements design, test automation and development that fits into the same sprint, while allowing stakeholders—from business analysts to testers Of testing is still manual to developers—to stay in alignment and remain flexible. This is 70% a tall order that requires replacing the typically slow, manual and error-prone testing process with a powerful, model-based approach to agile testing. An Agile Testing approach addresses the key challenges that business analysts, testers and developers face when they Of critical dependencies attempt to create better software, faster. These pain points span across the testing lifecycle and include: 56% unavailable • Ambiguous requirements • Poor test case design and limited coverage • Waiting for test data • Unavailability of system components • No automation Of time spent looking Let’s take a look at each of these problem areas and see how for test data CA Agile Requirements Designer, a solution from CA 50% Technologies for agile testing using a model-based approach, can help. 1 DevOps Review 2017 2 Ambiguous Requirements More often than not, software challenges are introduced at There is a better way— automatically model requirements the very beginning of a project, during the requirements phase. -

Testing in a Devops Era: Perceptions of Testers in Norwegian Organisations
Testing in a DevOps Era: Perceptions of Testers in Norwegian Organisations Daniela Soares Cruzes1, Kristin Melsnes2, Sabrina Marczak3 1 SINTEF - Norway 2 Bouvet – Norway 3 PUCRS - Brazil [email protected], [email protected], [email protected] Abstract. To better understand the challenges encountered by testers in DevOps development, we have performed an empirical investigation of what are the trends and challenges for the testers in the DevOps environ- ment. We have discussed the quality assurance in the difference focus areas of DevOps: Social Aspects, automation, leanness, sharing, measurement. The results were then themed in five different topics of concern to testers: collaboration, roles and responsibilities, types of tests, automation and monitoring and infrastructure. In Testing, there has been a change on the roles and responsibilities of testers, where there is much more focus on the responsibilities for testing across the teams, instead of a sole responsibility of the tester. Testers are also forced to collaborate more with other stake- holders as operations and business. Testing is brought to another level of automation in DevOps but there is still need for manual tests, that have to be much more risk-based than before. And finally, testing transparency is a must in this process and should involve not only development team but also operations and customers. This paper contributes to the body of knowledge on what are the areas we need to focus for improvement in test- ing for the DevOps environment. This paper also contributes to practition- ers to improve their testing focusing on specific areas that needs attention. -

Software Test Automation Practices in Agile Development Environment: an Industry Experience Report
Software Test Automation Practices in Agile Development Environment: An Industry Experience Report Eliane Figueiredo Collins Vicente Ferreira de Lucena Jr. Nokia Institute of Technology Federal University of Amazonas Manaus, AM, Brazil Manaus, AM, Brazil [email protected] [email protected] Abstract— The increased importance of Test Automation the customer rather than following rigid plans and contract in software engineering is very evident considering the number negotiations. The Scrum, as agile methods, is an important of companies investing in automated testing tools nowadays, practice in software development, with characteristics of with the main aim of preventing defects during the relatively flexible organizational system, timely and development process. Test Automation is considered an interactive feedback, objective-oriented flat management and essential activity for agile methodologies being the key to speed effective participation of members [4]. It can solve the up the quality assurance process. This paper presents difficulties faced by traditional open methods, some to a empirical observations and the challenges of a test team new to large extent and it can also be used to manage and control agile practices and Test Automation using open source testing software and product development. tools integrated in software projects that use the Scrum Agile processes are iterative, so the test activities have to methodology. The results obtained showed some important issues to be discussed and the Test Automation practices follow the iterations which need to be executed fast and collected based on the experiences and lessons learned. efficiently leading to the use of automated testing tools, quick responses to the requirement changes and interact with Keywords-test automation; agile testing; testing tools; the development team [5]. -

Jorgensen's Chapter 11: Life Cycle-Based Testing
Chapter 11 Life Cycle-Based Testing Software Testing: A Craftsman’s Approach, 4th Edition Chapter 11 Life Cycle-Based Testing Levels and Life Cycle Models • Levels of testing depend primarily on the software life cycle used. • BUT, most forms of testing levels are derived from the V-Model version of the good, old Waterfall Model. • Iterative models introduce the need for regression testing. • System testing is greatly enhanced when an executable specification is used. Software Testing: A Craftsman’s Approach, 4th Edition Chapter 11 Life Cycle-Based Testing The Waterfall Lifecycle Requirements Specification what how Preliminary Design what how Detailed Design what how Coding Unit Testing Integration Testing System Testing Software Testing: A Craftsman’s Approach, 4th Edition Chapter 11 Life Cycle-Based Testing High Level Design Requirements specification DetailedDesign Coding Unit, Integration, and System Testing Maintenance Software Testing: A Craftsman’s Approach, 4th Edition Chapter 11 Life Cycle-Based Testing The Waterfall Lifecycle Model • Earliest lifecycle model – NATO conference in 1968 – probably “in use” before that • Very sequential—output of one phase expresses “what” must be done in the next phase • Strong emphasis/importance of design • What-How cycles are natural points for software technical inspections • Basis for unit, integration, and system levels of testing (see V-Model) • Basis for many spinoff lifecycle models Software Testing: A Craftsman’s Approach, 4th Edition Chapter 11 Life Cycle-Based Testing The V-Model Requirements -

Intro to Software Testing
Introduction to Software Testing CS 3250 Software Testing [Ammann and Offutt, “Introduction to Software Testing,” Ch. 1, Ch. 2.1] Fall 2021 – University of Virginia © Praphamontripong 1 Bug? “ ‘Bug’ – as such little faults and difficulties are called – show themselves, and months of anxious watching, study, and labor are requisite before commercial success – or failure – is certainly reached.” [Thomas Edison, 1878] [Ref: Did You Know? Edison Coined the Term “Bug”, http://theinstitute.ieee.org/tech-history/technology-history/did- you-know-edison-coined-the-term-bug, IEEE 2013] “A software bug is an error, flaw, failure or fault in a computer program or system that causes it to produce an incorrect or unexpected result, or to behave in unintended ways.” [Ref: https://en.wikipedia.org/wiki/Software_bug] • “Bug” is used informally. BUG • Fault? Error? Or failure? • This course will try to use words that have precise, defined, and unambiguous meaning – and avoid using the term “bug” Fall 2021 – University of Virginia © Praphamontripong 2 Fault, Error, and Failure • Fault: a static defect in the software’s source code Cause of a problem – “fault location” • Error: An incorrect internal state that is the manifestation of some fault Erroneous program state caused by execution of the defect • Failure: External, incorrect behavior with respect to the requirements or other descriptions of the expected behavior Propagation of erroneous state to the program outputs Fall 2021 – University of Virginia © Praphamontripong 3 First Example (Testing) -

Agile Capabilities
Business Value of Agile Methods Using ROI & Real Options Dr. David F. Rico, PMP, CSEP, ACP, CSM, SAFe Twitter : @dr_david_f_rico Website: http://www.davidfrico.com LinkedIn : http://www.linkedin.com/in/davidfrico Agile Capabilities : http://davidfrico.com/rico-capability-agile.pdf Agile Resources : http://www.davidfrico.com/daves-agile-resources.htm Agile Cheat Sheet : http://davidfrico.com/key-agile-theories-ideas-and-principles.pdf Author Background Gov’t contractor with 32+ years of IT experience B.S. Comp . Sci ., M.S. Soft . Eng ., & D.M. Info . Sys . Large gov’t projects in U.S., Far/Mid-East, & Europe Career systems & software engineering methodologist Lean-Agile, Six Sigma, CMMI, ISO 9001, DoD 5000 NASA, USAF, Navy, Army, DISA, & DARPA projects Published seven books & numerous journal articles Intn’l keynote speaker, 130+ talks to 12,000 people Specializes in metrics, models, & cost engineering Cloud Computing, SOA, Web Services, FOSS, etc. Adjunct at five Washington, DC-area universities 2 Today’s Whirlwind Environment Global Reduced Competition IT Budgets Work Life Obsolete Imbalance Technology & Skills Demanding 81 Month Customers Cycle Times •Overruns •Inefficiency Vague •Attrition •High O&M Overburdening Requirements •Escalation •Lower DoQ Legacy Systems •Runaways •Vulnerable •Cancellation •N-M Breach Organization Redundant Downsizing Data Centers Technology Poor Change System Lack of IT Security Complexity Interoperability Pine, B. J. (1993). Mass customization : The new frontier in business competition . Boston, MA: Harvard Business School Press. Pontius, R. W. (2012). Acquisition of IT: Improving efficiency and effectiveness in IT acquisition in the DoD. Second Annual AFEI/NDIA Conference on Agile in DoD, Springfield, VA, USA . 3 Traditional Projects Big projects result in poor quality and scope changes Productivity declines with long queues /wait times Large projects are unsuccessful or canceled Size vs. -

White Paper Agile Software Testing Ten Tips for Launching and Testing High Quality Apps in an Agile Environment
Agile Software Testing Ten Tips for Launching and Testing High Quality Apps in an Agile Environment White Paper June 2011 White Paper: Agile Software Testing White Paper Agile Software Testing Ten Tips for Launching and Testing High Quality Apps in an Agile Environment Table of Contents • Agile Overview……………………………..……….. 3 - The Agile Manifesto…………………………….…. 3 - The Problem With Waterfall………………...…… 3 - The Emergence of Agile………...……………….. 4 - It’s Okay To Use Waterfall………...…………….. 4 “Simplicity is the ultimate • Ten Tips of Agile Testing…………………………. 5 sophistication.” 1. Understand the True Role of Testing……... 5 2. Unify SRS and Test Plans…………………. 5 3. Define Your Testing Matrix………………… 6 - Leonardo da Vinci 4. Tell a Story – Not a Use Case…………….. 7 5. Capture Meaningful Data……….………….. 8 6. Fix Broken Windows………………………… 9 7. Make Testing Your Feedback Loop…..…… 9 8. Timing is Everything……………………….... 10 9. Run Frequent Load Tests……………….….. 10 10. Stick to Your Scrums………………………… 11 • About uTest………………………………………….. 12 2 White Paper: Agile Software Testing Introduction Agile Overview A Google search for “agile development” returned 2.7 million results at the time this was written. It’s safe to say the word is getting out. But although the basic concepts have been actively discussed in books, blogs and everything in between, we’re going to first review them anyway. We promise to be quick. If you’ve heard this story before, feel free to skip ahead to the next section: Tips for Agile Testing. The Agile Manifesto Though ‘Agile’ is a relatively new term, the shift towards more iterative development methodologies began years ago. Eventually, in 2001, a small group of CTOs, academics and thought leaders published the well-known Agile Manifesto. -

Perspectives of Agile Software Testing
EBOOK PERSPECTIVES ON AGILE SOFTWARE TESTING An anthology of essays on testing approaches, tools and culture by testers for testers. Share this ebook. Contents A Timeline: The Evolution of Testing Tools 4 Is Selenium Finely Aged Wine? - Anand Bagmar 9 Testing in an Agile Environment - Daniel Amorim 15 Testing for Mobile - Fabio Maia and Alabe Duarte 20 BDD Style of Testing in Mobile Applications - Prateek Baheti and Vishnu Karthik 24 Continuous Delivery for Mobile Applications - Gayathri Mohan 28 Challenges in Mobile Testing - Vikrant Chauhan and Sushant Choudhary 37 Three Misconceptions about BDD - Nicholas Pufal and Juraci Vieira 43 Hiring Selenium QA People - Paul Hammant 48 Recap: Five Takeaways for the Modern Tester 54 © 2014 Share this ebook: 2 What’s this It’s been 10 years since Selenium was born. The industry has e-book about? changed tremendously since then. We want to recap the big developments of the last decade and introduce this anthology about testing methods and tools - some new pieces, and some from our greatest hits. © 2014 Share this ebook: 3 A TIMELINE: THE EVOLUTION OF TESTING TOOLS © 2014 Share this ebook: 4 Technology OATS LoadRunner QTP Rational Created 1999 2000 2001 2002 Open Source Commercial Support Web Mobile Selenium Ecosystem © 2014 Share this ebook: 5 Technology SilkTest Watir WaitN Created 2005 2004 2005 2006 2008 Open Source Commercial Support Web Mobile Selenium Ecosystem © 2014 Share this ebook: 6 Selenium 2 Technology CodedUI Watij (Webdriver) Created 2010 2011 Open Source Commercial Support Web Mobile Selenium Ecosystem © 2014 Share this ebook: 7 Technology Created 2012 2013 2014 Open Source Commercial Support Web Mobile Selenium Ecosystem © 2014 Share this ebook: 8 IS SELENIUM Anand Bagmar SOFTWARE QUALITY EVANGELIST — Anand FINELY AGED Bagmar is a hands-on and result-oriented Software Quality Evangelist with 17+ years in the IT field of which 14+ years in the software test WINE? field. -
Trainings Test and Debug
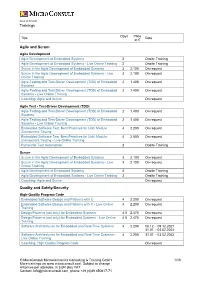
As of 28.09.2021 Trainings Days Price Title Date in € Agile and Scrum Agile Development Agile Development of Embedded Systems 2 Onsite Training Agile Development of Embedded Systems - Live Online Training 2 Onsite Training Scrum in the Agile Development of Embedded Systems 3 2.100 On request Scrum in the Agile Development of Embedded Systems - Live 3 2.100 On request Online Training Agile Testing and Test-Driven Development (TDD) of Embedded 2 1.400 On request Systems Agile Testing and Test-Driven Development (TDD) of Embedded 2 1.400 On request Systems - Live Online Training Coaching: Agile and Scrum On request Agile Test - Test-Driven Development (TDD) Agile Testing and Test-Driven Development (TDD) of Embedded 2 1.400 On request Systems Agile Testing and Test-Driven Development (TDD) of Embedded 2 1.400 On request Systems - Live Online Training Embedded Software Test: Best Practices for Unit/ Module 4 2.200 On request /Component Testing Embedded Software Test: Best Practices for Unit/ Module 4 2.000 On request /Component Testing - Live Online Training Python for Test Automation 3 Onsite Training Scrum Scrum in the Agile Development of Embedded Systems 3 2.100 On request Scrum in the Agile Development of Embedded Systems - Live 3 2.100 On request Online Training Agile Development of Embedded Systems 2 Onsite Training Agile Development of Embedded Systems - Live Online Training 2 Onsite Training Coaching: Agile and Scrum On request Quality and Safety/Security High-Quality Program Code Embedded Software Design and Patterns with C 4 2.200 On request Embedded Software Design and Patterns with C - Live Online 4 2.200 On request Training Design Patterns (not only) for Embedded Systems 4.5 2.475 On request Design Patterns (not only) for Embedded Systems - Live Online 4.5 2.475 On request Training Software Architectures for Embedded and Real-Time Systems 4 2.200 06.12. -

Agile Software Development and Testing: Approach and Challenges in Advanced Distributed Systems by P
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Global Journal of Computer Science and Technology (GJCST) Global Journal of Computer Science and Technology: B Cloud and Distributed Volume 14 Issue 1 Version 1.0 Year 2014 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals Inc. (USA) Online ISSN: 0975-4172 & Print ISSN: 0975-4350 Agile Software Development and Testing: Approach and Challenges in Advanced Distributed Systems By P. Rajasekhar & Dr. R. Mahammad Shafi Jawaharlal Nehru Technological University, India Abstract- More and more companies are adopting Agile methods as a flexible way to introduce new software products. An important part of any software project is testing. Agile testing may have similar aims as traditional software testing, but the structure of the team is different, testers need to support quality infusion through entire team. Test automation and selection of test tool can help project teams deliver more effectively, and in shorter timescales. The challenges in testing of cloud are visible also in the tools for automatic test case execution. This paper addresses some of these challenges and also highlights every aspect of software testing process in Agile development. Keywords: agile methods, unit testing, cloud testing. GJCST-B Classification: K.6.3 AgileSoftwareDevelopmentandTestingApproachandChallengesinAdvancedDistributedSystems Strictly as per the compliance and regulations of: © 2014. P. Rajasekhar & Dr. R. Mahammad Shafi. This is a research/review paper, distributed under the terms of the Creative Commons Attribution-Noncommercial 3.0 Unported License http://creativecommons.org/licenses/by-nc/3.0/), permitting all non- commercial use, distribution, and reproduction inany medium, provided the original work is properly cited.