Aspect Impact Analysis
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Smart Execution of Distributed Application by Balancing Resources in Mobile Devices
ALMA MATER STUDIORUM - UNIVERSITÀ DI BOLOGNA SCUOLA DI INGEGNERIA E ARCHITETTURA DISI INGEGNERIA INFORMATICA TESI DI LAUREA in Reti di Calcolatori M Smart execution of distributed application by balancing resources in mobile devices and cloud-based avatars CANDIDATO: RELATORE: Giacomo Gezzi Chiar.mo Prof. Ing. Antonio Corradi CORRELATORE: Chiar.mo Prof. Cristian Borcea Anno Accademico 2014/2015 Sessione III 2 Abstract L’obiettivo del progetto di tesi svolto e` quello di realizzare un servizio di livello middleware dedicato ai dispositivi mobili che sia in grado di fornire il supporto per l’offloading di codice verso una infrastruttura cloud. In particolare il progetto si concentra sulla migrazione di codice verso macchine virtuali dedicate al singolo utente. Il sistema operativo delle VMs e` lo stesso utilizzato dal device mobile. Come i precedenti lavori sul computation offloading, il progetto di tesi deve garantire migliori per- formance in termini di tempo di esecuzione e utilizzo della batteria del dispositivo. In particolare l’obiettivo piu` ampio e` quello di adattare il principio di computation offloading a un contesto di sistemi distribuiti mobili, miglio- rando non solo le performance del singolo device, ma l’esecuzione stessa dell’applicazione distribuita. Questo viene fatto tramite una gestione di- namica delle decisioni di offloading basata, non solo, sullo stato del de- vice, ma anche sulla volonta` e/o sullo stato degli altri utenti appartenenti allo stesso gruppo. Per esempio, un primo utente potrebbe influenzare le decisioni degli altri membri del gruppo specificando una determinata richiesta, come alta qualita` delle informazioni, risposta rapida o basata su altre informazioni di alto livello. -

Build an Eclipse Development Environment for Perl, Python, and PHP Use the Dynamic Languages Toolkit (DLTK) to Create Your Own IDE
Build an Eclipse development environment for Perl, Python, and PHP Use the Dynamic Languages Toolkit (DLTK) to create your own IDE Skill Level: Intermediate Matthew Scarpino ([email protected]) Java Developer Eclipse Engineering, LLC 03 Feb 2009 Eclipse presents a wealth of capabilities for building tools for compiled languages like C and the Java™ programming language, but provides little support for scripting languages like Perl, Python, and PHP. For these and similar languages, the Eclipse Dynamic Languages Toolkit (DLTK) comes to the rescue. Walk through the process of building a DLTK-based IDE and discover sample code for each step. Section 1. Before you start About this tutorial This tutorial shows how Eclipse's DLTK makes it possible to build development tools for scripting languages. In particular, it explains how to implement syntax coloring, user preferences, and interpreter integration in a plug-in-based project. Objectives This tutorial explains — one step at a time — how to build a DLTK-based Build an Eclipse development environment for Perl, Python, and PHP © Copyright IBM Corporation 2008. All rights reserved. Page 1 of 33 developerWorks® ibm.com/developerWorks development environment. The discussion presents the DLTK by focusing on a practical plug-in project based on the Octave numerical computation language. Topics covered include: Frequently used acronyms • DLTK: Dynamic Languages Toolkit • GPL: GNU Public License • IDE: Integrated Development Environment • JRE: Java Runtime Environment • MVC: Model-View-Controller • SWT: Standard Widget Toolkit • UI: User Interface • Creating a plug-in project. • Configuring the editor and the DLTK text tools. • Adding classes to control syntax coloring in the text editor. -

Customizing Eclipse RCP Applications Techniques to Use with SWT and Jface
Customizing Eclipse RCP applications Techniques to use with SWT and JFace Skill Level: Intermediate Scott Delap ([email protected]) Desktop/Enterprise Java Consultant Annas Andy Maleh ([email protected]) Consultant 27 Feb 2007 Most developers think that an Eclipse Rich Client Platform (RCP) application must look similar in nature to the Eclipse integrated development environment (IDE). This isn't the case, however. This tutorial will explain a number of simple techniques you can use with the Standard Widget Toolkit (SWT) and JFace to create applications that have much more personality than the Eclipse IDE. Section 1. Before you start About this tutorial This tutorial will explain a number of UI elements that can be changed in Eclipse RCP, JFace, and SWT. Along the way, you will learn about basic changes you can make, such as fonts and colors. You will also learn advanced techniques, including how to create custom wizards and section headers. Using these in conjunction should provide you the ability to go from a typical-looking Eclipse RCP application to a distinctive but visually appealing one. Prerequisites Customizing Eclipse RCP applications © Copyright IBM Corporation 1994, 2008. All rights reserved. Page 1 of 40 developerWorks® ibm.com/developerWorks You should have a basic familiarity with SWT, JFace, and Eclipse RCP. System requirements To run the examples, you need a computer capable of adequately running Eclipse V3.2 and 50 MB of free disk space. Section 2. Heavyweight and lightweight widgets Before diving into techniques that can be used to modify SWT, JFace, and Eclipse RCP in general, it's important to cover the fundamental characteristics of SWT and how they apply to the appearance of the widget set. -

Recoder with Eclipse
School of Mathematics and Systems Engineering Reports from MSI - Rapporter från MSI Recoder with Eclipse Saúl Díaz González Álvaro Pariente Alonso June MSI Report 09031 2009 Växjö University ISSN 1650-2647 SE-351 95 VÄXJÖ ISRN VXU/MSI/DA/E/--09031/--SE Abstract RECODER is a Java framework aimed at source code analysis and metaprogramming. It works on several layers to offer a set of semi-automatic transformations and tools, ranging from a source code parser and unparser, offering a highly detailed syntactical model, analysis tools which are able to infer types of expressions, evaluate compile-time constants and keep cross-reference information, to transformations of the very Java sources, containing a library of common transformations and incremental analysis capabilities. These make up an useful set of tools which can be extended to provide the basis for more advanced refactoring and metacompiler applications, in very different fields, from code beautification and simple preprocessors, stepping to software visualization and design problem detection tools to adaptive programming environments and invasive software composition. The core system development of RECODER started in the academic field and as such, it was confined into a small platform of users. Although a powerful tool, RECODER framework lacks usability and requires extensive and careful configuration to work properly. In order to overcome such limitations, we have taken advantage of the Eclipse Integrated Development Environment (Eclipse IDE) developed by IBM, specifically its Plugin Framework Architecture to build a tool and a vehicle where to integrate RECODER functionalities into a wide-used, well-known platform to provide a semi- automated and user-friendly interface. -

Eclipse (Software) 1 Eclipse (Software)
Eclipse (software) 1 Eclipse (software) Eclipse Screenshot of Eclipse 3.6 Developer(s) Free and open source software community Stable release 3.6.2 Helios / 25 February 2011 Preview release 3.7M6 / 10 March 2011 Development status Active Written in Java Operating system Cross-platform: Linux, Mac OS X, Solaris, Windows Platform Java SE, Standard Widget Toolkit Available in Multilingual Type Software development License Eclipse Public License Website [1] Eclipse is a multi-language software development environment comprising an integrated development environment (IDE) and an extensible plug-in system. It is written mostly in Java and can be used to develop applications in Java and, by means of various plug-ins, other programming languages including Ada, C, C++, COBOL, Perl, PHP, Python, Ruby (including Ruby on Rails framework), Scala, Clojure, and Scheme. The IDE is often called Eclipse ADT for Ada, Eclipse CDT for C/C++, Eclipse JDT for Java, and Eclipse PDT for PHP. The initial codebase originated from VisualAge.[2] In its default form it is meant for Java developers, consisting of the Java Development Tools (JDT). Users can extend its abilities by installing plug-ins written for the Eclipse software framework, such as development toolkits for other programming languages, and can write and contribute their own plug-in modules. Released under the terms of the Eclipse Public License, Eclipse is free and open source software. It was one of the first IDEs to run under GNU Classpath and it runs without issues under IcedTea. Eclipse (software) 2 Architecture Eclipse employs plug-ins in order to provide all of its functionality on top of (and including) the runtime system, in contrast to some other applications where functionality is typically hard coded. -

Design Pattern Implementation in Java and Aspectj
Design Pattern Implementation in Java and AspectJ Jan Hannemann Gregor Kiczales University of British Columbia University of British Columbia 201-2366 Main Mall 201-2366 Main Mall Vancouver B.C. V6T 1Z4 Vancouver B.C. V6T 1Z4 jan [at] cs.ubc.ca gregor [at] cs.ubc.ca ABSTRACT successor in the chain. The event handling mechanism crosscuts the Handlers. AspectJ implementations of the GoF design patterns show modularity improvements in 17 of 23 cases. These improvements When the GoF patterns were first identified, the sample are manifested in terms of better code locality, reusability, implementations were geared to the current state of the art in composability, and (un)pluggability. object-oriented languages. Other work [19, 22] has shown that implementation language affects pattern implementation, so it seems The degree of improvement in implementation modularity varies, natural to explore the effect of aspect-oriented programming with the greatest improvement coming when the pattern solution techniques [11] on the implementation of the GoF patterns. structure involves crosscutting of some form, including one object As an initial experiment we chose to develop and compare Java playing multiple roles, many objects playing one role, or an object [27] and AspectJ [25] implementations of the 23 GoF patterns. playing roles in multiple pattern instances. AspectJ is a seamless aspect-oriented extension to Java, which means that programming in AspectJ is effectively programming in Categories and Subject Descriptors Java plus aspects. D.2.11 [Software Engineering]: Software Architectures – By focusing on the GoF patterns, we are keeping the purpose, patterns, information hiding, and languages; D.3.3 intent, and applicability of 23 well-known patterns, and only allowing [Programming Languages]: Language Constructs and Features – the solution structure and solution implementation to change. -

Weaving Eclipse Applications
Weaving Eclipse Applications Fabio Calefato, Filippo Lanubile, Mario Scalas, 1 Dipartimento di Informatica, Università di Bari, Italy {calefato, lanubile, scalas}@uniba.it Abstract. The Eclipse platform fully supports the ideas behind software components: in addition it also adds dynamic behavior allowing components to be added, replaced or removed at runtime without shutting the application down. While layered software architectures may be implemented by assembling components, the way these components are wired together differs. In this paper we present our solution of Dependecy Injection, which allows to build highly decoupled Eclipse applications in order to implement real separation of concerns by systemically applying Aspect Oriented Programming and the Model-View-Presenter pattern, a variant of the classic Model-View-Controller. Keywords: Eclipse, Aspect Oriented Programming, Dependency Injection. 1 Introduction The Dependency Inversion Principle [19] (DIP) states that (both high and low level) software parts should not depend on each other’s concrete implementation but, instead, be based on a common set of shared abstractions: one application of the DIP is the Dependency Injection, also called Inversion of Control (IoC) [11]. From an architectural perspective, DI allows to explicit the dependencies between software components and provides a way to break the normal coupling between a system under test and its dependencies during automated testing [25]. This is possible because the software is composed by aggregating simpler, loosely coupled objects that are more easily unit-testable [32]. Additionally, by separating the clients by their dependencies, we also make their code simpler because there is no need for them to search for their collaborators. -

Static Versus Dynamic Polymorphism When Implementing Variability in C++
Static Versus Dynamic Polymorphism When Implementing Variability in C++ by Samer AL Masri A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science Department of Computing Science University of Alberta c Samer AL Masri, 2018 Abstract Software Product Line Engineering (SPLE) creates configurable platforms that can be used to efficiently produce similar, and yet different, product vari- ants. To implement SPLs, multiple variability implementation mechanisms have been suggested, including polymorphism. In this thesis, we talk about the trade-offs of using static versus dynamic polymorphism through a case study of IBM’s open-source Eclipse OMR project. Eclipse OMR is an open-source C++ framework for building robust lan- guage runtimes. To support the diverse languages and architectures targeted by the framework, OMR’s variability implementation uses a combination of build-system variability and static polymorphism. OMR developers now real- ize that their current static polymorphism implementation has its drawbacks and are considering using dynamic polymorphism instead. In order to study the trade-offs of using different kinds of polymorphism in OMR, it is crucial to collect function information and overload/override statistics about the current code base. Hence, we create OMRStatistics,a static analysis tool that collects such information about OMR’s source code. Using the information provided by OMRStatistics, OMR developers can make better design decisions on which variability extension points should be switched from static polymorphism to dynamic polymorphism. In addition, we report on our first hand experience of changing the poly- morphism used in OMR’s variability implementation mechanism from static to dynamic, the challenges we faced in the process, and how we overcame them. -

Oracle FLEXCUBE Private Banking Release Notes
Product Release Notes Oracle FLEXCUBE Private Banking Release 12.1.0.0.0 [April] [2016] Product Release Notes Table of Contents 1. INTRODUCTION ........................................................................................................................................... 1-1 1.1 PURPOSE ..................................................................................................................................................... 1-1 1.2 BACKGROUND/ENVIRONMENT ................................................................................................................... 1-1 1.3 THIRD PARTY SOFTWARE DETAILS ............................................................................................................ 1-2 1.4 RELEASE CONTENTS ................................................................................................................................... 1-4 1.5 PRODUCT DOCUMENTATION ....................................................................................................................... 1-5 2. COMPONENTS OF THE RELEASE ........................................................................................................... 2-1 2.1 DOCUMENTS ACCOMPANYING THE SOFTWARE ............................................................................................ 2-1 2.2 SOFTWARE COMPONENTS ........................................................................................................................... 2-1 1. Introduction 1.1 Purpose Purpose of this Release Note is to highlight the -
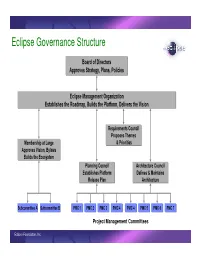
Eclipse Governance Structure
Eclipse Governance Structure Board of Directors A p p rov es S trateg y , P lans, P olicies E clip se M anag em ent O rg aniz ation E stab lish es th e R oadm ap , Bu ilds th e P latform , Deliv ers th e V ision R eq u irem ents C ou ncil P rop oses T h em es M em b ersh ip at L arg e & P riorities A p p rov es V ision, By law s Bu ilds th e E cosy stem P lanning C ou ncil A rch itectu re C ou ncil E stab lish es P latform Defines & M aintains R elease P lan A rch itectu re S u b com m ittee A S u b com m ittee B P M C 1 P M C 2 P M C 3 P M C 4 P M C 4 P M C 5 P M C 6 P M C 7 Project Management Committees Eclipse Foundation, Inc. Eclipse Development Roadmap ° http://www.eclipse.org/org/councils/roadmap.html ° Communicate the direction and timetable of the Eclipse projects ° Solicits for input from key stakeholders ° Create an open predictable environment to enable planning for commercial adoption ° Predictable schedule of new releases ° Understand technology direction ° Eclipse Roadmap consists of: ° Themes and Priorities ° Schedules ° Architecture Plan ° Will be update every 6 months ° First iteration done March 2005 Eclipse Foundation, Inc. Eclipse Roadmap: Development Councils Strategic Members PMC T&P’s Requirements Council Add-in Providers Market research T h P e r m io e ri s & ti s e & e s s e m ti e ri h o T ri P Platform Release Planning Architecture Council Architecture Plan Council P P M M C C P A l r a c n h s Eclipse Foundation, Inc. -

Creating a Modular Aspectj Foundation for Simple and Rapid Extension Implementation By
Creating a Modular AspectJ Foundation for Simple and Rapid Extension Implementation by Hristofor Mirche E!I FM" E#AMI$A"I%$ C%MMI""EE dr& C&M& 'oc(isch prof&dr&ir& M& A(sit )*&*+&,*-. Abstract "he current state of aspect/oriented programming 0A%1) has raised concerns regarding arious limitations that A%1 languages ha e& "he issue is that A%1 languages are not robust enough 3hen the basis program is changed& "here are many ne3 proposals for A%1 languages 3ith ne3 features that attempt to restrict or gi e more expressi eness to the programmer in order to force a ne3 context 3here the problems can be mitigated& Some of those languages are designed as extensions of AspectJ. Existing open AspectJ compilers can be used for implementing such an extension, but this can 5uic(ly become a complicated task of extending the complex processes of lexing4 parsing and 3ea ing4 of 3hich the compilers o6er lo3/le el abstractions& "hus4 there is a need for an easily extensible AspectJ foundation for a simpler and faster de elopment of language extensions& !e ha e de eloped such a foundation and in this thesis 3e describe the design of the implementation. !e pro ide an o er ie3 of a testing process to determine its alidity& Finally4 3e implement one proposal for an AspectJ extension and e aluate the extensibility and ease of use of our foundation in comparison to other existing AspectJ compilers& -& Introduction Moti ation& An easy approach to implement an aspect/oriented language 3ould be to extend an existing A%P compiler& "his is not al3ays the best approach4 -

Developing Java™ Web Applications
ECLIPSE WEB TOOLS PLATFORM the eclipse series SERIES EDITORS Erich Gamma ■ Lee Nackman ■ John Wiegand Eclipse is a universal tool platform, an open extensible integrated development envi- ronment (IDE) for anything and nothing in particular. Eclipse represents one of the most exciting initiatives hatched from the world of application development in a long time, and it has the considerable support of the leading companies and organ- izations in the technology sector. Eclipse is gaining widespread acceptance in both the commercial and academic arenas. The Eclipse Series from Addison-Wesley is the definitive series of books dedicated to the Eclipse platform. Books in the series promise to bring you the key technical information you need to analyze Eclipse, high-quality insight into this powerful technology, and the practical advice you need to build tools to support this evolu- tionary Open Source platform. Leading experts Erich Gamma, Lee Nackman, and John Wiegand are the series editors. Titles in the Eclipse Series John Arthorne and Chris Laffra Official Eclipse 3.0 FAQs 0-321-26838-5 Frank Budinsky, David Steinberg, Ed Merks, Ray Ellersick, and Timothy J. Grose Eclipse Modeling Framework 0-131-42542-0 David Carlson Eclipse Distilled 0-321-28815-7 Eric Clayberg and Dan Rubel Eclipse: Building Commercial-Quality Plug-Ins, Second Edition 0-321-42672-X Adrian Colyer,Andy Clement, George Harley, and Matthew Webster Eclipse AspectJ:Aspect-Oriented Programming with AspectJ and the Eclipse AspectJ Development Tools 0-321-24587-3 Erich Gamma and