A Data Analysis of the World Happiness Index and Its Relation to the North-South Divide
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
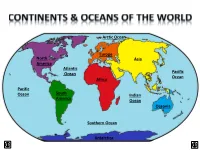
North America Other Continents
Arctic Ocean Europe North Asia America Atlantic Ocean Pacific Ocean Africa Pacific Ocean South Indian America Ocean Oceania Southern Ocean Antarctica LAND & WATER • The surface of the Earth is covered by approximately 71% water and 29% land. • It contains 7 continents and 5 oceans. Land Water EARTH’S HEMISPHERES • The planet Earth can be divided into four different sections or hemispheres. The Equator is an imaginary horizontal line (latitude) that divides the earth into the Northern and Southern hemispheres, while the Prime Meridian is the imaginary vertical line (longitude) that divides the earth into the Eastern and Western hemispheres. • North America, Earth’s 3rd largest continent, includes 23 countries. It contains Bermuda, Canada, Mexico, the United States of America, all Caribbean and Central America countries, as well as Greenland, which is the world’s largest island. North West East LOCATION South • The continent of North America is located in both the Northern and Western hemispheres. It is surrounded by the Arctic Ocean in the north, by the Atlantic Ocean in the east, and by the Pacific Ocean in the west. • It measures 24,256,000 sq. km and takes up a little more than 16% of the land on Earth. North America 16% Other Continents 84% • North America has an approximate population of almost 529 million people, which is about 8% of the World’s total population. 92% 8% North America Other Continents • The Atlantic Ocean is the second largest of Earth’s Oceans. It covers about 15% of the Earth’s total surface area and approximately 21% of its water surface area. -

John F. Helliwell, Richard Layard and Jeffrey D. Sachs
2018 World Happiness Report John F. Helliwell, Richard Layard and Jeffrey D. Sachs Table of Contents World Happiness Report 2018 Editors: John F. Helliwell, Richard Layard, and Jeffrey D. Sachs Associate Editors: Jan-Emmanuel De Neve, Haifang Huang and Shun Wang 1 Happiness and Migration: An Overview . 3 John F. Helliwell, Richard Layard and Jeffrey D. Sachs 2 International Migration and World Happiness . 13 John F. Helliwell, Haifang Huang, Shun Wang and Hugh Shiplett 3 Do International Migrants Increase Their Happiness and That of Their Families by Migrating? . 45 Martijn Hendriks, Martijn J. Burger, Julie Ray and Neli Esipova 4 Rural-Urban Migration and Happiness in China . 67 John Knight and Ramani Gunatilaka 5 Happiness and International Migration in Latin America . 89 Carol Graham and Milena Nikolova 6 Happiness in Latin America Has Social Foundations . 115 Mariano Rojas 7 America’s Health Crisis and the Easterlin Paradox . 146 Jeffrey D. Sachs Annex: Migrant Acceptance Index: Do Migrants Have Better Lives in Countries That Accept Them? . 160 Neli Esipova, Julie Ray, John Fleming and Anita Pugliese The World Happiness Report was written by a group of independent experts acting in their personal capacities. Any views expressed in this report do not necessarily reflect the views of any organization, agency or programme of the United Nations. 2 Chapter 1 3 Happiness and Migration: An Overview John F. Helliwell, Vancouver School of Economics at the University of British Columbia, and Canadian Institute for Advanced Research Richard Layard, Wellbeing Programme, Centre for Economic Performance, at the London School of Economics and Political Science Jeffrey D. -

The Social Progress Index Background and US Implementation
Ideas + Action for a Better City learn more at SPUR.org tweet about this event: @SPUR_Urbanist #SocialProgress The Social Progress Index Background and US Implementation www.socialprogress.org We need a new model “Economic growth alone is not sufficient to advance societies and improve the quality of life of citizens. True success, and Michael E. Porter Harvard Business growth that is inclusive, School and Social requires achieving Progress Imperative both economic and Advisory Board Chair social progress.” 2 Social Progress Index design principles As a complement to economic measures like GDP, SPI answers universally important questions about the success of society that measures of economic progress cannot alone address. 4 2019 Social Progress Index aggregates 50+ social and environmental outcome indicators from 149 countries 5 GDP is not destiny Across the spectrum, we see how some countries are much better at turning their economic growth into social progress than 2019 Social Progress Index Score Index Progress Social 2019 others. GDP PPP per capita (in USD) 6 6 From Index to Action to Impact Delivering local data and insight that is meaningful, relevant and actionable London Borough of Barking & Dagenham ward-level SPI holds US city-level SPIs empower government accountable to ensure mayors, business and civic leaders no one is left behind left behind with new insight to prioritize policies and investments European Union regional SPI provides a roadmap for policymakers to guide €350 billion+ in EU Cohesion Policy spending state and -

The Human Development Index: Measuring the Quality of Life
Student Resource XIV The Human Development Index: Measuring the Quality of Life The ‘Human Development Index (HDI) is a summary measure of average achievement in key dimensions of human development’ (UNDP). It is a measure closely related to quality of life, and is used to compare two or more countries. The United Nations developed the HDI based on three main dimensions: long and healthy life, knowledge, and a decent standard of living (see Image below). Figure 1: Indicators of HDI Source: http://hdr.undp.org/en/content/human-development-index-hdi In 2015, the United States ranked 8th among all countries in Human Development, ranking behind countries like Norway, Australia, Switzerland, Denmark, Netherlands, Germany and Ireland (UNDP, 2015). The closer a country is to 1.0 on the HDI index, the better its standing in regards to human development. Maps of HDI ranking reveal regional patterns, such as the low HDI in Sub-Saharan Africa (Figure 2). Figure 2. The United Nations Human Development Index (HDI) rankings for 2014 17 Use Student Resource XIII, Measuring Quality of Life Country Statistics to answer the following questions: 1. Categorize the countries into three groups based on their GNI PPP (US$), which relates to their income. List them here. High Income: Medium Income: Low Income: 2. Is there a relationship between income and any of the other statistics listed in the table, such as access to electricity, undernourishment, or access to physicians (or others)? Describe at least two patterns here. 3. There are several factors we can look at to measure a country's quality of life. -

1 Executive Summary Mauritius Is an Upper Middle-Income Island Nation
Executive Summary Mauritius is an upper middle-income island nation of 1.2 million people and one of the most competitive, stable, and successful economies in Africa, with a Gross Domestic Product (GDP) of USD 11.9 billion and per capita GDP of over USD 9,000. Mauritius’ small land area of only 2,040 square kilometers understates its importance to the Indian Ocean region as it controls an Exclusive Economic Zone of more than 2 million square kilometers, one of the largest in the world. Emerging from the British colonial period in 1968 with a monoculture economy based on sugar production, Mauritius has since successfully diversified its economy into manufacturing and services, with a vibrant export sector focused on textiles, apparel, and jewelry as well as a growing, modern, and well-regulated offshore financial sector. Recently, the government of Mauritius has focused its attention on opportunities in three areas: serving as a platform for investment into Africa, moving the country towards renewable sources of energy, and developing economic activity related to the country’s vast oceanic resources. Mauritius actively seeks investment and seeks to service investment in the region, having signed more than forty Double Taxation Avoidance Agreements and maintaining a legal and regulatory framework that keeps Mauritius highly-ranked on “ease of doing business” and good governance indices. 1. Openness To, and Restrictions Upon, Foreign Investment Attitude Toward FDI Mauritius actively seeks and prides itself on being open to foreign investment. According to the World Bank report “Investing Across Borders,” Mauritius has one of the world’s most open economies to foreign ownership and is one of the highest recipients of FDI per capita. -

Countries and Continents of the World: a Visual Model
Countries and Continents of the World http://geology.com/world/world-map-clickable.gif By STF Members at The Crossroads School Africa Second largest continent on earth (30,065,000 Sq. Km) Most countries of any other continent Home to The Sahara, the largest desert in the world and The Nile, the longest river in the world The Sahara: covers 4,619,260 km2 The Nile: 6695 kilometers long There are over 1000 languages spoken in Africa http://www.ecdc-cari.org/countries/Africa_Map.gif North America Third largest continent on earth (24,256,000 Sq. Km) Composed of 23 countries Most North Americans speak French, Spanish, and English Only continent that has every kind of climate http://www.freeusandworldmaps.com/html/WorldRegions/WorldRegions.html Asia Largest continent in size and population (44,579,000 Sq. Km) Contains 47 countries Contains the world’s largest country, Russia, and the most populous country, China The Great Wall of China is the only man made structure that can be seen from space Home to Mt. Everest (on the border of Tibet and Nepal), the highest point on earth Mt. Everest is 29,028 ft. (8,848 m) tall http://craigwsmall.wordpress.com/2008/11/10/asia/ Europe Second smallest continent in the world (9,938,000 Sq. Km) Home to the smallest country (Vatican City State) There are no deserts in Europe Contains mineral resources: coal, petroleum, natural gas, copper, lead, and tin http://www.knowledgerush.com/wiki_image/b/bf/Europe-large.png Oceania/Australia Smallest continent on earth (7,687,000 Sq. -

Geography Notes.Pdf
THE GLOBE What is a globe? a small model of the Earth Parts of a globe: equator - the line on the globe halfway between the North Pole and the South Pole poles - the northern-most and southern-most points on the Earth 1. North Pole 2. South Pole hemispheres - half of the earth, divided by the equator (North & South) and the prime meridian (East and West) 1. Northern Hemisphere 2. Southern Hemisphere 3. Eastern Hemisphere 4. Western Hemisphere continents - the largest land areas on Earth 1. North America 2. South America 3. Europe 4. Asia 5. Africa 6. Australia 7. Antarctica oceans - the largest water areas on Earth 1. Atlantic Ocean 2. Pacific Ocean 3. Indian Ocean 4. Arctic Ocean 5. Antarctic Ocean WORLD MAP ** NOTE: Our textbooks call the “Southern Ocean” the “Antarctic Ocean” ** North America The three major countries of North America are: 1. Canada 2. United States 3. Mexico Where Do We Live? We live in the Western & Northern Hemispheres. We live on the continent of North America. The other 2 large countries on this continent are Canada and Mexico. The name of our country is the United States. There are 50 states in it, but when it first became a country, there were only 13 states. The name of our state is New York. Its capital city is Albany. GEOGRAPHY STUDY GUIDE You will need to know: VOCABULARY: equator globe hemisphere continent ocean compass WORLD MAP - be able to label 7 continents and 5 oceans 3 Large Countries of North America 1. United States 2. Canada 3. -

ICS South Africa
Integrated Country Strategy South Africa FOR PUBLIC RELEASE FOR PUBLIC RELEASE Table of Contents 1. Chief of Mission Priorities ................................................................................................................ 2 2. Mission Strategic Framework .......................................................................................................... 4 3. Mission Goals and Objectives .......................................................................................................... 6 4. Management Objectives ................................................................................................................ 12 FOR PUBLIC RELEASE Approved: August 22, 2018 1 FOR PUBLIC RELEASE 1. Chief of Mission Priorities There are tremendous opportunities to broaden U.S. engagement in South Africa which stand to benefit both countries. Over 600 U.S. companies already operate in South Africa, some for over 100 years; furthermore, many of them use South Africa as a platform for operations and a springboard for expansion into the rest of Africa. South Africa is therefore the single most critical market hub to a population expecting to double to two billion people in the next 30 years. While some resentment of the United States continues from the apartheid era, there is also recognition of American activism that helped end apartheid. In polls, the United States is seen very favorably by every day South Africans, who respond positively to American politics, culture, and goods. South Africa’s economy is the most -

An Information Visualization Application Case to Understand the World Happiness Report
An information visualization application case to understand the World Happiness Report Nychol Bazurto-Gomez1[0000−0003−0881−6736], Carlos Torres J.1[0000−0002−5814−6278], Raul Gutierrez1[0000−0003−1375−8753], Mario Chamorro3[0000−0002−7247−8236], Claire Bulger4[0000−0002−3031−2908], Tiberio Hernandez1[0000−0002−5035−4363], and John A. Guerra-Gomez1;2[0000−0001−7943−0000] 1 Imagine group, Universidad de los Andes, Bogota, Colombia fn.bazurto,cf.torres,ra.gutierrez,jhernand,[email protected] 2 UC Berkeley, California, Berkeley, United States 3 Make it happy, San Francisco, United States [email protected] 4 World Happiness Report, San Francisco, United States [email protected] Abstract. Happiness is one of the most important components in life, however, qualifying happiness is not such a happy task. For this purpose, the World Happiness Report was created: An annual survey that mea- sures happiness around the globe. It uses six different metrics: (i) healthy life expectancy, (ii) social support, (iii) freedom to make life choices, (iv) perceptions of corruption, (v) GDP per capita, and (vi) generosity. Those metrics combined in an index rank countries by their happiness. This in- dex has been published by means of a static report that attempts to explain it, however, given the complexity of the index, the creators have felt that the index hasn't been explained properly to the community. In order to propose a more intuitive way to explore the metrics that compose the index, this paper presents an interactive approach. Thanks to our information visualization, we were able to discover insights such as the many changes in the happiness levels of South Africa in 2013, a year with statistics like highest crime rate and country with most pub- lic protests in the world. -

Measuring Well-Being and Progress: Looking Beyond
Measuring well-being and progress Looking beyond GDP SUMMARY Gross domestic product (GDP), a measure of national economic production, has come to be used as a general measure of well-being and progress in society, and as a key indicator in deciding a wide range of public policies. However GDP does not properly take into account non-economic factors such as social issues and the environment. In the aftermath of the economic and financial crisis, the European Union (EU) needs reliable, transparent and convincing measures for evaluating progress. Indicators of social aspects that play a large role in determining citizens' well-being are increasingly being used to supplement economic measures. Health, education and social relationships play a large role in determining citizens' well-being. Subjective evaluations of well-being can also be used as a measure of progress. Moreover, changes in the environment caused by economic activities (in particular depletion of non-renewable resources and increased greenhouse gas emissions) need to be evaluated so as to ensure that today's development is sustainable for future generations. The EU and its Member States, as well as international bodies, have a role in ensuring that we have accurate, useful and credible ways of measuring well-being and assessing progress in our societies. In this briefing: Background Objective social indicators Subjective well-being Environment and sustainability EU and international context Further reading Author: Ron Davies, Members' Research Service European Parliamentary Research Service 140738REV1 http://www.eprs.ep.parl.union.eu — http://epthinktank.eu [email protected] Measuring well-being and progress Background The limits of GDP Gross domestic product (GDP) measures the market value of all final goods and services produced within a country's borders in a given period, such as a year.1 It provides a simple and easily communicated monetary value that can be calculated from current market prices and that can be used to make comparisons between different countries. -

FACTSHEET: Cardiovascular Diseases in South Africa
FACTSHEET: Cardiovascular diseases in South Africa Globally… Cardiovascular diseases (CVDs), commonly referred to as heart disease or stroke, are the number 1 cause of death around the world 1 in 3 deaths globally are as result of CVD, yet the majority of premature heart disease and stroke is preventable1 In 2010 CVD cost US$ 863 billion – this is estimated to rise by 22% to US$ 1,044 billion by 20302 80% of CVD deaths occur in low- to middle-income countries. In South Africa… Non-communicable diseases (NCDs), including CVDs, are estimated to account for 43% of total adult deaths in South Africa CVDs account for almost a fifth (18%) of these deaths Some of the CVD related risks factors in adults in South Africa are outlined below: 18% of the population smoke tobacco 11 litres of pure alcohol consumed per person 1 in 3 South African adults (33.7%) have hypertension which can increase risk of heart attack, heart failure, kidney disease or stroke 31.3% adults in South Africa are obese In South Africa, the proportion of CVD deaths in women aged between 35–59 years is one and a half times more likely than that of women in the United States.3 Obesity in South Africa4 70% of women and a third of men in South Africa are classified as overweight or obese 40% of women in South Africa are obese 1 in 4 girls and 1 in 5 boys between the ages of 2 – 14 years are overweight or obese. Taking action… In February 2016, South Africa became the first African country to announce plans to introduce a new tax on sugar-sweetened drinks5 The ‘sugar tax’ will come into force from April 2017 A 2013 study by the Human Sciences Research Council in Johannesburg suggested a link between sugar and obesity, concluding that one in five South Africans consume an excessive amount of sugar6 In 2013, the South African Government introduced legislation in line with targets set to reduce salt intake to less than 5g a day per person by 2020. -

John F. Helliwell, Richard Layard and Jeffrey D. Sachs
2018 John F. Helliwell, Richard Layard and Jeffrey D. Sachs Table of Contents World Happiness Report 2018 Editors: John F. Helliwell, Richard Layard, and Jeffrey D. Sachs Associate Editors: Jan-Emmanuel De Neve, Haifang Huang and Shun Wang 1 Happiness and Migration: An Overview . 3 John F. Helliwell, Richard Layard and Jeffrey D. Sachs 2 International Migration and World Happiness . 13 John F. Helliwell, Haifang Huang, Shun Wang and Hugh Shiplett 3 Do International Migrants Increase Their Happiness and That of Their Families by Migrating? . 45 Martijn Hendriks, Martijn J. Burger, Julie Ray and Neli Esipova 4 Rural-Urban Migration and Happiness in China . 67 John Knight and Ramani Gunatilaka 5 Happiness and International Migration in Latin America . 89 Carol Graham and Milena Nikolova 6 Happiness in Latin America Has Social Foundations . 115 Mariano Rojas 7 America’s Health Crisis and the Easterlin Paradox . 146 Jeffrey D. Sachs Annex: Migrant Acceptance Index: Do Migrants Have Better Lives in Countries That Accept Them? . 160 Neli Esipova, Julie Ray, John Fleming and Anita Pugliese The World Happiness Report was written by a group of independent experts acting in their personal capacities. Any views expressed in this report do not necessarily reflect the views of any organization, agency or programme of the United Nations. 2 Chapter 1 3 Happiness and Migration: An Overview John F. Helliwell, Vancouver School of Economics at the University of British Columbia, and Canadian Institute for Advanced Research Richard Layard, Wellbeing Programme, Centre for Economic Performance, at the London School of Economics and Political Science Jeffrey D. Sachs, Director, SDSN, and Director, Center for Sustainable Development, Columbia University The authors are grateful to the Ernesto Illy Foundation and the Canadian Institute for Advanced Research for research support, and to Gallup for data access and assistance.