Y Errors in Floating-Point Subtraction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lecture 2 MODES of NUMERICAL COMPUTATION
§1. Diversity of Numbers Lecture 2 Page 1 It is better to solve the right problem the wrong way than to solve the wrong problem the right way. The purpose of computing is insight, not numbers. – Richard Wesley Hamming (1915–1998) Lecture 2 MODES OF NUMERICAL COMPUTATION To understand numerical nonrobustness, we need to understand computer arithmetic. But there are several distinctive modes of numerical computation: symbolic mode, floating point (FP) mode, arbitrary precision mode, etc. Numbers are remarkably complex objects in computing, embodying two distinct sets of properties: quantitative properties and algebraic properties. Each mode has its distinctive number representations which reflect the properties needed for computing in that mode. Our main focus is on the FP mode that is dominant in scientific and engineering computing, and in the corresponding representation popularly known as the IEEE Standard. §1. Diversity of Numbers Numerical computing involves numbers. For our purposes, numbers are elements of the set C of complex numbers. But in each area of application, we are only interested in some subset of C. This subset may be N as in number theory and cryptographic applications. The subset may be R as in most scientific and engineering computations. In algebraic computations, the subset might be Q or its algebraic closure Q. These examples show that “numbers”, despite their simple unity as elements of C, can be very diverse in manifestation. Numbers have two complementary sets of properties: quantitative (“numerical”) properties and algebraic properties. Quantitative properties of numbers include ordering and magnitudes, while algebraic properties include the algebraic axioms of a ring or field. -

Modes of Numerical Computation
§1. Diversity of Numbers Lecture 2 Page 1 It is better to solve the right problem the wrong way than to solve the wrong problem the right way. The purpose of computing is insight, not numbers. – Richard Wesley Hamming (1915–1998) Lecture 2 MODES OF NUMERICAL COMPUTATION To understand numerical nonrobustness, we need to understand computer arithmetic. But there are several distinctive modes of numerical computation: symbolic mode, floating point (FP) mode, arbitrary precision mode, etc. Numbers are remarkably complex objects in computing, embodying two distinct sets of properties: quantitative properties and algebraic properties. Each mode has its distinctive number representations which reflect the properties needed for computing in that mode. Our main focus is on the FP mode that is dominant in scientific and engineering computing, and in the corresponding representation popularly known as the IEEE Standard. §1. Diversity of Numbers Numerical computing involves numbers. For our purposes, numbers are elements of the set C of complex numbers. But in each area of application, we are only interested in some subset of C. This subset may be N as in number theory and cryptographic applications. The subset may be R as in most scientific and engineering computations. In algebraic computations, the subset might be Q or its algebraic closure Q. These examples show that “numbers”, despite their simple unity as elements of C, can be very diverse in manifestation. Numbers have two complementary sets of properties: quantitative (“numerical”) properties and algebraic properties. It is not practical to provide a single representation of numbers to cover the full range of these properties. -

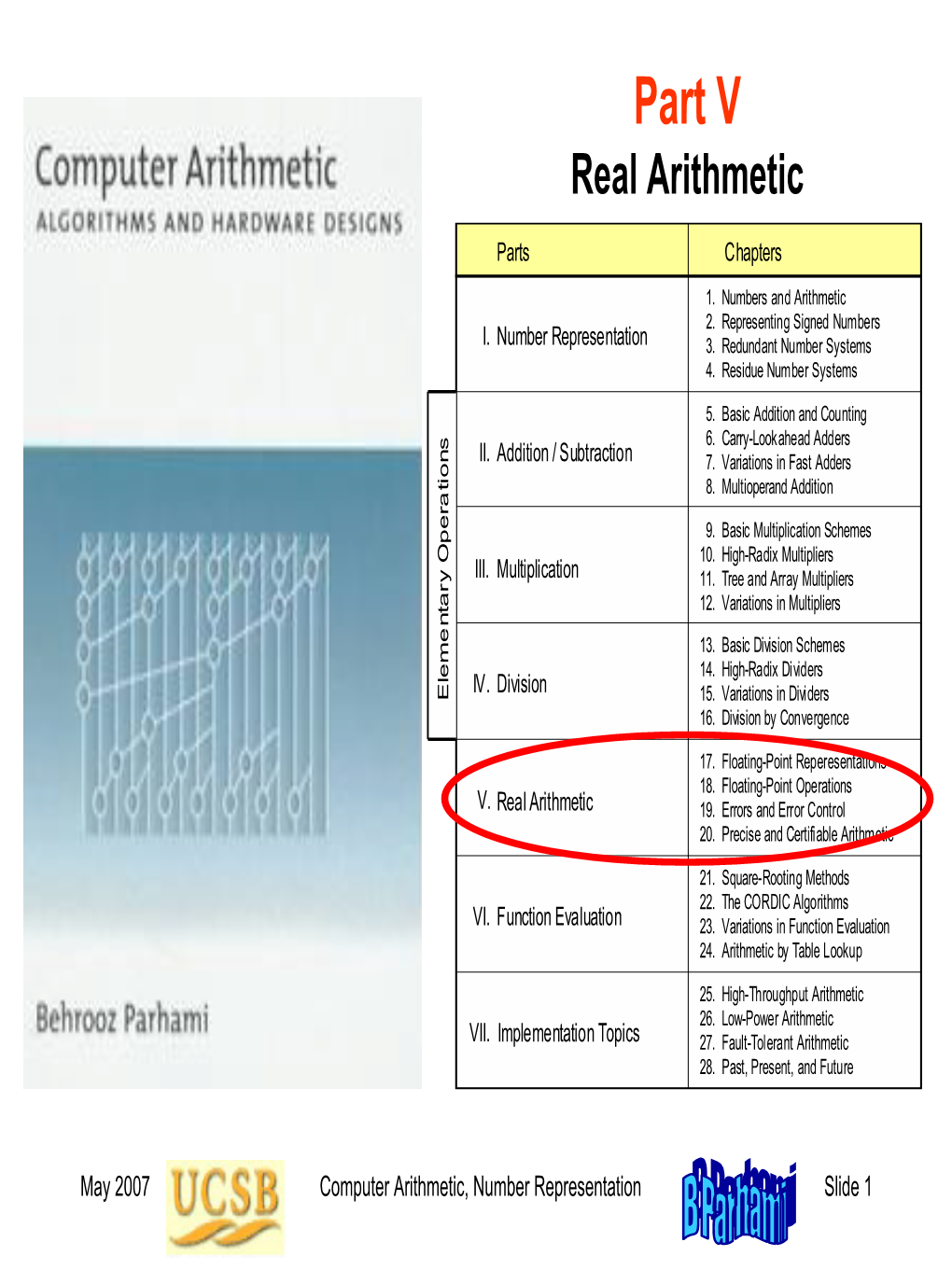
Part V Real Arithmetic
Part V Real Arithmetic Parts Chapters 1. Numbers and Arithmetic 2. Representing Signed Numbers I. Number Representation 3. Redundant Number Systems 4. Residue Number Systems 5. Basic Addition and Counting 6. Carry-Lookahead Adders II. Addition / Subtraction 7. Variations in Fast Adders 8. Multioperand Addition 9. Basic Multiplication Schemes 10. High-Radix Multipliers III. Multiplication 11. Tree and Array Multipliers 12. Variations in Multipliers 13. Basic Division Schemes 14. High-Radix Dividers IV . Division Elementary Operations Elementary 15. Variations in Dividers 16. Division by Convergence 17. Floating-Point Reperesentations 18. Floating-Point Operations V. Real Arithmetic 19. Errors and Error Control 20. Precise and Certifiable Arithmetic 21. Square-Rooting Methods 22. The CORDIC Algorithms VI. Function Evaluation 23. Variations in Function Evaluation 24. Arithmetic by Table Lookup 25. High-Throughput Arithmetic 26. Low-Power Arithmetic VII. Implementation Topics 27. Fault-Tolerant Arithmetic 28. Past,Reconfigurable Present, and Arithmetic Future Appendix: Past, Present, and Future May 2015 Computer Arithmetic, Real Arithmetic Slide 1 About This Presentation This presentation is intended to support the use of the textbook Computer Arithmetic: Algorithms and Hardware Designs (Oxford U. Press, 2nd ed., 2010, ISBN 978-0-19-532848-6). It is updated regularly by the author as part of his teaching of the graduate course ECE 252B, Computer Arithmetic, at the University of California, Santa Barbara. Instructors can use these slides freely in classroom teaching and for other educational purposes. Unauthorized uses are strictly prohibited. © Behrooz Parhami Edition Released Revised Revised Revised Revised First Jan. 2000 Sep. 2001 Sep. 2003 Oct. 2005 May 2007 May 2008 May 2009 Second May 2010 Apr. -

Interval Arithmetic in Mathematica
Interval Computations No 3, 1993 Interval Arithmetic in Mathematica Jerry B. Keiper The use of interval methods to solve numerical problems has been very limited. Some of the reasons for this are the lack of easy access to software and the lack of knowledge of the potential benefits. Until numerical analysts and others become generally familiar with interval methods, their use will remain limited. Mathematica is one way to educate potential users regarding the usefulness of interval methods. This paper examines some of the ways that intervals can be used in Mathematica. ИНТЕРВАЛЬНАЯ АРФМЕТИКА В СИСТЕМЕ Mathematica Дж. Б. Кейпер Использование интервальных методов для решения численных задач до сих пор было весьма ограниченным. Отчасти причины этого заключались в отсутствии легкого доступа к программному обеспечению и отсутствии знаний о потенциальной выгоде. Пока исследователи, занимающиеся чис- ленным анализом и смежными дисциплинами, не познакомятся достаточ- но близко с интервальными методами, их использование будет оставаться ограниченным. Доступ к системе Mathematica является одним из способов ознакомить потенциальных пользователей с полезностью интервальных методов. В статье рассматриваются некоторые возможности использова- ния интервалов в системе Mathematica. c J. B. Keiper, 1993 Interval Arithmetic in Mathematica 77 1 Introduction Mathematica, like all computer-algebra systems, has several types of arith- metic. In addition to exact arithmetic (i.e., integers and rational num- bers) and machine-precision floating-point arithmetic, it has high-precision floating-point arithmetic and interval arithmetic. The behavior of the high-precision floating-point arithmetic can be al- tered (by changing $MinPrecision and $MaxPrecision), but the default behavior is essentially a form of interval arithmetic in which the intervals are assumed to be “short” relative to the magnitude of the numbers represented. -
![How to Hunt Wild Constants Arxiv:2103.16720V2 [Cs.SC] 28 Apr](https://docslib.b-cdn.net/cover/6474/how-to-hunt-wild-constants-arxiv-2103-16720v2-cs-sc-28-apr-6266474.webp)
How to Hunt Wild Constants Arxiv:2103.16720V2 [Cs.SC] 28 Apr
How to hunt wild constants David R. Stoutemyer April 29, 2021 Abstract There are now several comprehensive web applications, stand-alone computer programs and computer algebra functions that, given a floating point number such as 6.518670730718491, can return concise nonfloat constants such as 3 arctan 2 + ln 9 + 1 that closely approximate the float. Examples include AskConstants, In- verse Symbolic Calculator, the Maple identify function, MESearch, OEIS, RIES, and WolframAlpha. Usefully often such a result is the exact limit as the float is computed with increasing precision. Therefore these program results are candi- dates for proving an exact result that you could not derive or conjecture without the program. Moreover, candidates that are not the exact limit can be provable bounds, or convey qualitative insight, or suggest series that they truncate, or pro- vide sufficiently close efficient approximations for subsequent computation. This article describes some of these programs, how they work, and how best to use each of them. Almost everyone who uses or should use mathematical software can bene- fit from acquaintance with several such programs, because these programs differ in the sets of constants that they can return. 1 Introduction “... you are in a state of constant learning.” – Bruce Lee arXiv:2103.16720v2 [cs.SC] 28 Apr 2021 This article is about numerical mathematical constants that can be computed approx- imately, rather than about dimensionless or dimensioned physical constants. This article is a more detailed version of a presentation at an Applications of Computer Algebra conference [19]. For real-world problems, we often cannot directly derive exact closed-form results even with the help of computer algebra, but we more often can compute approximate floating-point results – hereinafter called floats. -

The End of (Numeric) Error
Ubiquity, an ACM publication April 2016 The End of (Numeric) Error An Interview with John L. Gustafson by Walter Tichy Editor’s Introduction Crunching numbers was the prime task of early computers. Wilhelm Schickard’s machine of 1623 helped calculate astronomical tables; Charles Babbage’s difference engine, built by Per Georg Scheutz in 1843, worked out tables of logarithms; the Atanasoff-Berry digital computer of 1942 solved systems of linear equations; and the ENIAC of 1946 computed artillery firing tables. The common element of these early computers is they all used integer arithmetic. To compute fractions, you had to place an imaginary decimal (or binary) point at an appropriate, fixed position in the integers. (Hence the term fixed-point arithmetic.) For instance, to calculate with tenths of pennies, arithmetic must be done in multiples of 10−3 dollars. Combining tiny and large quantities is problematic for fixed-point arithmetic, since there are not enough digits. Floating-point numbers overcome this limitation. They implement the “scientific notation,” where a mantissa and an exponent represent a number. For example, 3.0×108 m/s is the approximate speed of light and would be written as 3.0E8. The exponent indicates the position of the decimal point, and it can float left or right as needed. The prime advantage of floating-point is its vast range. A 32-bit floating-point number has a range of approximately 10−45 to 10+38. A binary integer would require more than 260 bits to represent this range in its entirety. A 64-bit floating point has the uber-astronomical range of 10632. -

Chengpu Wang, a New Uncertainty-Bearing Floating-Point
A New Uncertainty-Bearing Floating-Point Arithmetic∗ Chengpu Wang 40 Grossman Street, Melville, NY 11747, USA [email protected] Abstract A new deterministic floating-point arithmetic called precision arith- metic is developed to track precision for arithmetic calculations. It uses a novel rounding scheme to avoid the excessive rounding error propagation of conventional floating-point arithmetic. Unlike interval arithmetic, its uncertainty tracking is based on statistics and the central limit theorem, with a much tighter bounding range. Its stable rounding error distribution is approximated by a truncated Gaussian distribution. Generic standards and systematic methods for comparing uncertainty-bearing arithmetics are discussed. The precision arithmetic is found to be superior to inter- val arithmetic in both uncertainty-tracking and uncertainty-bounding for normal usages. The arithmetic code is published at: http://precisionarithm.sourceforge.net. Keywords: computer arithmetic, error analysis, interval arithmetic, multi-precision arithmetic, numerical algorithms. AMS subject classifications: 65-00 1 Introduction 1.1 Measurement Precision Except for the simplest counting, scientific and engineering measurements never give completely precise results [18, 42]. The precision of measured values ranges from an 2 4 order-of-magnitude estimation of astronomical measurements to 10− to 10− of com- 14 mon measurements to 10− of state-of-art measurements of basic physics constants [17]. In scientific and engineering measurements, the uncertainty of a measurement x usually is characterized by the sample deviation δx [18, 42, 19]. In certain cases, such as raw reading from an ideal analog-to-digital converter, the uncertainty of a ∗Submitted: March 11, 2006; Revised: various times – 2010–2012; Accepted: December 4, 2012. -

A Graduate Introduction to Numerical Methods
A Graduate Introduction to Numerical Methods Robert M. Corless • Nicolas Fillion A Graduate Introduction to Numerical Methods From the Viewpoint of Backward Error Analysis 123 Robert M. Corless Nicolas Fillion Applied Mathematics Applied Mathematics University of Western Ontario University of Western Ontario London, ON, Canada London, ON, Canada ISBN 978-1-4614-8452-3 ISBN 978-1-4614-8453-0 (eBook) DOI 10.1007/978-1-4614-8453-0 Springer New York Heidelberg Dordrecht London Library of Congress Control Number: 2013955042 © Springer Science+Business Media New York 2013 This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. Exempted from this legal reservation are brief excerpts in connection with reviews or scholarly analysis or material supplied specifically for the purpose of being entered and executed on a computer system, for exclusive use by the purchaser of the work. Duplication of this publication or parts thereof is permitted only under the provisions of the Copyright Law of the Publisher’s location, in its current version, and permission for use must always be obtained from Springer. Permissions for use may be obtained through RightsLink at the Copyright Clearance Center. Violations are liable to prosecution under the respective Copyright Law. The use of general descriptive names, registered names, trademarks, service marks, etc. -

How to Hunt Wild Constants
How to hunt wild constants David R. Stoutemyer March 30, 2021 Abstract There are now several comprehensive web applications, stand-alone computer programs and computer algebra functions that, given a floating point number such as 6.518670730718491, can return concise nonfloat constants such as 3 arctan 2 + ln 9 + 1 that closely approximate the float. Usefully often such a result is the exact limit as the float is computed with increasing precision. Therefore these program results are candidates for proving an exact result that you could not otherwise compute or conjecture without the program. Moreover, candidates that are not the exact limit can be provable bounds, or convey qualitative insight, or suggest series that they truncate, or provide sufficiently close efficient approximations for subsequent computation. This article describes some of these programs, how they work, and how best to use each of them. Almost everyone who uses or should use mathematical software can benefit from acquaintance with several such programs, because these programs differ in the sets of constants that they can return. 1 Introduction “... you are in a state of constant learning.” – Bruce Lee This article is about numerical mathematical constants that can be computed ap- proximately. For real-world problems, we often cannot directly derive exact closed-form results even with the help of computer algebra, but we more often can compute approximate floating-point results – hereinafter called floats. For some such cases there is an exact closed-form result that the float approximates and that form is simple enough so that we would like to know it, but we do not know how to derive it or to guess it as a prerequisite to a proof. -

E-Journal Mathematics
E-JOURNAL : MATHEMATICAL REVIEW : 2018 MATHEMATICAL REVIEW : Acknowledgement : The E-Journal MATHEMATICAL REVIEW is the outcome of a series of efforts carried out by all the students and all the faculties of our mathematics department. However it would not be possible to incorporate or framing the entire journal without the help of the faculties as well as the students of our department. Especially I would like to thank Dr. Swapan Kumar Misra, Principal, Mugberia Gangadhar Mahavidyalaya for his generous support in writing this Journal. I express sincerest gratitude to my colleague Dr. Nabakumar Ghosh for his positive suggestions to improve the standard of the said Journal. A special thanks are owed to my obedient student Sudipta Maity, M. Sc 4th sem, Dept. of Mathematics: for his excellent typing to add some special features to this Journal. I would like to express sincere appreciation to all the students, their valuable information’s make the Journal fruitful. I would like to thank for their constant source of inspiration. My undergraduate and post graduate students have taken some helps from our Mathematics Department as well as several sources. I heartily thanks Dr. Arpan Dhara Dr. Arindam Roy, Prof. Bikash Panda, Prof. Suman Giri, Prof Debraj Manna, Prof Asim jana, Mrs. Tanushree Maity, Prof Anupam De and Prof Debnarayan Khatua for their help in different direction to modify the Journal . I appreciate all that they have contributed to this work. I shall feel great to receive constructive suggestions through email for the improvement in future during publication of such Journal from the experts as well as the learners.