M´Emoire De Stage De Master M2
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Product Plan SAP Analytics Cloud and Digital Boardroom Q4 2020
Product Plan SAP Analytics Cloud and Digital Boardroom Q4 2020 PUBLIC Quarterly Release Schedule Updates to the Timeline Since launching in 2015, SAP Analytics Cloud received updates approximately every two weeks. As of version 2018.19, we moved from a bi-weekly release schedule to a Quarterly Release schedule to align with SAP’s global strategy for cloud application releases. This means you can expect a new version once every quarter. The Product Plan timeline shown below will now reflect the current plan based on this Quarterly Release Schedule. Q4/2020 Q1/2021 Future Direction If you are on the Fast-Track subscription (updates every two weeks), please note that features may be available to you earlier than what is listed in the Quarterly Release Schedule timeline. More information can be found here. *The upcoming Q4 2020 release of SAP Analytics Cloud is a dedicated quality and performance release. © 2020 SAP SE or an SAP affiliate company. All rights reserved. ǀ PUBLIC 2 Table of contents ▪ Data integration ▪ Modeling ▪ Data visualization ▪ Reporting ▪ Planning ▪ Smart Assist ▪ Smart Predict / Predictive Planning ▪ Analytics Designer ▪ APIs and Extensions for Developers ▪ Intelligent Enterprise ▪ Mobile ▪ Platform Services ▪ Administration and infrastructure ▪ SAP Digital Boardroom ▪ SAP Analytics Content Network ▪ SAP Microsoft Office Add-ins ▪ Product Plan summary © 2020 SAP SE or an SAP affiliate company. All rights reserved. ǀ PUBLIC 3 Product Description SAP Analytics Cloud ACT WITH CONFIDENCE Business Augmented Enterprise Intelligence -

Expert Analytics User Guide Content
PUBLIC SAP BusinessObjects Predictive Analytics 3.1 2016-11-22 Expert Analytics User Guide Content 1 About Expert Analytics........................................................6 1.1 Expert Analytics Overview.......................................................6 1.2 New in Expert Analytics 3.1......................................................6 1.3 Document History............................................................ 6 1.4 Documentation Resources...................................................... 7 1.5 What this Guide Contains.......................................................8 1.6 Target Audience..............................................................9 2 Getting Started with Expert Analytics........................................... 10 2.1 Basics of Expert Analytics......................................................10 2.2 Understanding Online and Agnostic Modes ..........................................11 2.3 Launching Expert Analytics.....................................................12 2.4 Installing R and the Required Packages.............................................12 2.5 Configuring R...............................................................14 2.6 Understanding Expert Analytics..................................................15 Designer View............................................................15 Results View.............................................................16 2.7 Using Expert Analytics from Start to Finish..........................................16 2.8 Configuring Advanced -
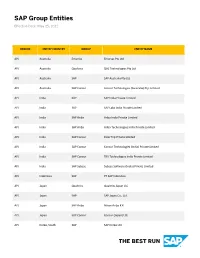
SAP Group Entities Effective Date: May 25, 2021
SAP Group Entities Effective Date: May 25, 2021 REGION ENTITY COUNTRY GROUP ENTITY NAME APJ Australia Emarsys Emarsys Pty Ltd APJ Australia Qualtrics QAL Technologies Pty Ltd APJ Australia SAP SAP Australia Pty Ltd APJ Australia SAP Concur Concur Technologies (Australia) Pty. Limited APJ India SAP SAP India Private Limited APJ India SAP SAP Labs India Private Limited APJ India SAP Ariba Ariba India Private Limited APJ India SAP Ariba Ariba Technologies India Private Limited APJ India SAP Concur ClearTrip Private Limited APJ India SAP Concur Concur Technologies (India) Private Limited APJ India SAP Concur TRX Technologies India Private Limited APJ India SAP Sybase Sybase Software (India) Private Limited APJ Indonesia SAP PT SAP Indonesia APJ Japan Qualtrics Qualtrics Japan LLC APJ Japan SAP SAP Japan Co., Ltd. APJ Japan SAP Ariba Nihon Ariba K.K. APJ Japan SAP Concur Concur (Japan) Ltd. APJ Korea, South SAP SAP Korea Ltd. REGION ENTITY COUNTRY GROUP ENTITY NAME APJ Korea, South SAP SAP Labs Korea, Inc. APJ Malaysia SAP SAP Malaysia Sdn. Bhd. APJ Malaysia SAP Concur CNQR Operations Mexico S. de. R.L. de. C.V. APJ Myanmar SAP SAP System Application and Products Asia Myanmar Limited APJ New Zealand SAP SAP New Zealand Limited APJ Philippines SAP SAP Philippines, Inc. APJ Philippines SAP SuccessFactors SuccessFactors (Philippines), Inc. APJ Singapore Emarsys Emarsys Pte Ltd APJ Singapore Qualtrics QSL Technologies Pte. Ltd. APJ Singapore SAP SAP Asia Pte Ltd APJ Singapore SAP Ariba Ariba International Singapore Pte Ltd APJ Singapore SAP Concur Concur Technologies (Singapore) Pte Ltd APJ Taiwan, China SAP SAP Taiwan Co., Ltd. -

Business Objects SA Securities Litigation 04-CV-02401-Consolidated Complaint for Violations of Federal Securities Laws
Case 3:04-cv-02401-MJJ Document 25-1 Filed 01/07/2005 Page 1 of 42 1 LERACH COUGHLIN STOIA GELLER RUDMAN & ROBBINS LLP 2 WILLIAM S. LERACH (68581) JONAH H. GOLDSTEIN (193777) 3 DAVID W. MITCHELL (199706) 401 B Street, Suite 1600 4 San Diego, CA 92101 Telephone: 619/231-1058 5 619/231-7423 (fax) 6 Lead Counsel for Plaintiffs 7 UNITED STATES DISTRICT COURT 8 NORTHERN DISTRICT OF CALIFORNIA 9 10 In re BUSINESS OBJECTS S.A SECURITIES ) Master File No. C-04-2401-MJJ LITIGATION ) 11 ) CLASS ACTION ) 12 This Document Relates To: ) CONSOLIDATED COMPLAINT FOR ) VIOLATIONS OF THE FEDERAL 13 ALL ACTIONS. ) SECURITIES LAWS ) 14 DEMAND FOR JURY TRIAL 15 16 17 18 19 20 21 22 23 24 25 26 27 28 Case 3:04-cv-02401-MJJ Document 25-1 Filed 01/07/2005 Page 2 of 42 1 JURISDICTION AND VENUE 2 1. Jurisdiction is conferred by §27 of the Securities Exchange Act of 1934 (“1934 Act”). 3 The claims asserted arise under §§10(b) and 20(a) of the 1934 Act. 4 2. Venue is proper in this District pursuant to §27 of the 1934 Act. Defendants maintain 5 corporate headquarters and conduct business at 3030 Orchard Parkway, San Jose, California, 95134, 6 and the wrongful conduct took place in this District. 7 NATURE AND SUMMARY OF THE ACTION 8 3. This is a securities class action on behalf of purchasers of Business Objects S.A. 9 (“Business Objects” or the “Company”) publicly traded securities during the period from April 23, 10 2003 to April 29, 2004 (the “Class Period”). -

Participating Addendum Contract #0000000000000000000028963
PARTICIPATING ADDENDUM CONTRACT #0000000000000000000028963 NASPO ValuePoint Software Value Added Reseller (SVAR) Administrated by the State of Arizona (hereinafter “Lead State”) MASTER AGREEMENT SHI International Corporation Master Agreement No: ADSPO16-130651 (hereinafter “Contractor”) And The State of Indiana acting by and through the Indiana State Police (“ISP”) (hereinafter “Participating State/Entity”) 1. Scope: This addendum covers the Software Value Added Reseller contract led by the State of Arizona for use by state agencies and other entities located in the Participating State authorized by that state’s statutes to utilize State contracts with the prior approval of the state’s chief procurement official. 2. Participation: Use of specific NASPO ValuePoint cooperative contracts by agencies, political subdivisions and other entities (including cooperatives) authorized by an individual state’s statutes to use State contracts are subject to the prior approval of the respective State Chief Procurement Official. Issues of interpretation and eligibility for participation are solely within the authority of the State Chief Procurement Official. 3. Participating State Modifications or Additions to Master Agreement: (These modifications or additions apply only to actions and relationships within the Participating Entity.) Participating State/Entity must check one of the boxes below. [__] No changes to the terms and conditions of the Master Agreement are required. [ X ] The following changes are modifying or supplementing the Master Agreement terms and conditions. Exhibit A, hereby attached and incorporated by reference, is the Supplement covering compliance with State laws. The Supplement is incorporated into and made a part of the Master Agreement Number ADSPO16-130651 (Exhibit B) and applies to all transactions under this Participating Addendum. -

Table of Contents
SAP BusinessObjects Roambi Cloud Cognos Adapter - May 2016 Table of Contents I. Overview Introduction II. Setup Requirements Roambi Requirements Cognos Requirements Roambi ConFiguration Creating API Key Setting up RoambiScript III. How to Use Option 1: Cognos is conFigured to save ALL report outputs to the File system. Installation and Configuration Preparation ConFigure Cognos Report For Bursting Update roambi-integration.conFig Schedule the Cognos Report Log Files Option 2: Cognos is conFigured to save Individual report outputs to the File system. Installation and Configuration Preparation ConFigure Cognos Report For Bursting Update roambi-integration.conFig Schedule the Cognos Report Log Files Appendix A: Troubleshooting and Common Issues 1 SAP BusinessObjects Roambi Cloud Cognos Adapter - May 2016 I. Overview Introduction Cognos allows users to create reports. Reports can be scheduled to run on diFFerent time intervals and the output can be saved in content manager or sent by email to difFerent recipients. Optionally users can burst the report to produce multiple reports based on a key. Cognos oFFers two methods to save report outputs to the File system. You can conFigure Cognos to save All report outputs to the File system, or enable users to save individual reports to a speciFic Folder in the File system. When conFiguring Cognos to save the All report outputs to the File system, you can provide a batch script that will be called every time a report output File is saved to the File system. In that script we can include the logic to launch the integration with SAP BusinessObjects Roambi Cloud. With this option, the integration with Roambi Cloud is basically controlled by Cognos. -

Businessobjects Adapter Guide Version: 6.2.1
Cisco Tidal Enterprise Scheduler BusinessObjects Adapter Guide Version: 6.2.1 May 3, 2016 Americas Headquarters Cisco Systems, Inc. 170 West Tasman Drive San Jose, CA 95134-1706 USA http://www.cisco.com Tel: 408 526-4000 800 553-NETS (6387) Fax: 408 527-0883 THE SPECIFICATIONS AND INFORMATION REGARDING THE PRODUCTS IN THIS MANUAL ARE SUBJECT TO CHANGE WITHOUT NOTICE. ALL STATEMENTS, INFORMATION, AND RECOMMENDATIONS IN THIS MANUAL ARE BELIEVED TO BE ACCURATE BUT ARE PRESENTED WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. USERS MUST TAKE FULL RESPONSIBILITY FOR THEIR APPLICATION OF ANY PRODUCTS. THE SOFTWARE LICENSE AND LIMITED WARRANTY FOR THE ACCOMPANYING PRODUCT ARE SET FORTH IN THE INFORMATION PACKET THAT SHIPPED WITH THE PRODUCT AND ARE INCORPORATED HEREIN BY THIS REFERENCE. IF YOU ARE UNABLE TO LOCATE THE SOFTWARE LICENSE OR LIMITED WARRANTY, CONTACT YOUR CISCO REPRESENTATIVE FOR A COPY. The Cisco implementation of TCP header compression is an adaptation of a program developed by the University of California, Berkeley (UCB) as part of UCB’s public domain version of the UNIX operating system. All rights reserved. Copyright © 1981, Regents of the University of California. NOTWITHSTANDING ANY OTHER WARRANTY HEREIN, ALL DOCUMENT FILES AND SOFTWARE OF THESE SUPPLIERS ARE PROVIDED “AS IS” WITH ALL FAULTS. CISCO AND THE ABOVE-NAMED SUPPLIERS DISCLAIM ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING, WITHOUT LIMITATION, THOSE OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OR ARISING FROM A COURSE OF DEALING, USAGE, OR TRADE PRACTICE. IN NO EVENT SHALL CISCO OR ITS SUPPLIERS BE LIABLE FOR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, OR INCIDENTAL DAMAGES, INCLUDING, WITHOUT LIMITATION, LOST PROFITS OR LOSS OR DAMAGE TO DATA ARISING OUT OF THE USE OR INABILITY TO USE THIS MANUAL, EVEN IF CISCO OR ITS SUPPLIERS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. -

Opensap Implementation of SAP Businessobjects Cloud
openSAP Implementation of SAP BusinessObjects Cloud Week 1 Unit 1 00:00:10 Hello, and welcome to the course "The Implementation of SAP BusinessObjects Cloud".My name is Mark Burke, and I am with the Scale, Enablement, and Transformation group of SAP Labs in Palo Alto, California. 00:00:25 I want to welcome you to this course.In this session, which is Week 1 Unit 1, we're going to be introducing you to the course, 00:00:32 and also to the product called SAP BusinessObjects Cloud.Let's cover one naming convention item before we start the course. 00:00:41 SAP BusinessObjects Cloud is the new name for a product that was originally released as SAP Cloud for Analytics.So in this course and going forward, SAP will refer to this as SAP BusinessObjects Cloud. 00:00:54 Be aware that in some of the demonstrations and links that we show you, there may still be references to SAP Cloud for Analytics, but that is the same thing as SAP BusinessObjects Cloud, and that's the name of the product going forward. 00:01:07 I wanted to cover that with you before we start the course.So let's go ahead and get started. 00:01:12 First of all, what can you expect over the next three weeks in this course? First of all, we're going to go through an introduction to the course and also the product. 00:01:21 In Unit 2, we're going to cover where to find help and support, and Units 3 and 4 will be dedicated to model development and maintenance.In Week 2, we'll be covering integration topics. -

Automate the Process of Populating BI Tools with Reporting Objects ___
Angles for Oracle Automate the Process of Populating BI Tools With Reporting Objects ___ Magnitude Angles Generator Automates The Manually-Intensive The Angles Generator Process of Populating Each Reporting Tool With The Reporting Family of Products Objects Necessary For Business Professionals To Develop Reports Includes Support for The Without IT Assistance. Following BI Platforms Angles Generator significantly reduces the tedious effort in implementing BI ✓ Oracle Business Intelligence applications by fully integrating the Magnitude Angles for Oracle platform within the tool’s metadata layer, saving administrators resource costs in supporting a diverse ✓ Tableau reporting environment. ✓ Power BI Together with the operational reporting and packaged analytics capabilities offered within Angles for Oracle, Angles Generator completes the Angles BI solution providing ✓ Microsoft BI organizations with a true end-to-end enterprise reporting solution designed to help maximize the investment in Oracle Applications. ✓ SAP BusinessObjects ✓ IBM Cognos BI ✓ QlikView ✓ Oracle Discoverer ✓ Information Builders WebFOCUS Angles Generator for Oracle Business Intelligence Angles Generator for Tableau Angles BI Generator automatically connects Angles for Oracle Angles Generator automatically connects Angles for with Oracle Business Intelligence (Oracle BI EE Plus and Oracle Views and Angles for Oracle Analytics with Tabueau Oracle BI SE One). It extracts metadata from those sources for fast, cost-effective access to Oracle E-Business Suite and creates the Enterprise Information Model metadata layers, (EBS) application data. Tableau doesn’t have a semantic layer simplifying setup and ad hoc retrieval of database information. that organizes the data users can access. As a result, it can be Angles Generator also automatically creates Angles report difficult for Tableau customers to find the data they want to templates in Oracle BI Answers and Oracle Interactive analyze. -

SAP Businessobjects Business Intelligence 4 Innovation and Implementation
SAP BusinessObjects Business Intelligence 4 Innovation and Implementation SAP BUSINESSOBJECTS BUSINESS INTELLIGENCE 4 INNOVATION AND IMPLEMENTATION TABLE OF CONTENTS 1- INTRODUCTION ............................................................................................................................... 4 2- LOGON DETAILS ............................................................................................................................. 5 3- STARTING AND STOPPING THE APPLIANCE .............................................................................. 6 4.1 Remote Desktop Connection - Windows 7 ................................................. Error! Bookmark not defined. 4.2 Remote Desktop Connection - Windows XP .............................................. Error! Bookmark not defined. 2 SAP BUSINESSOBJECTS BUSINESS INTELLIGENCE 4 INNOVATION AND IMPLEMENTATION Disclaimer The information in this presentation is confidential and proprietary to SAP and may not be disclosed without the permission of SAP. This presentation is not subject to your license agreement or any other service or subscription agreement with SAP. SAP has no obligation to pursue any course of business outlined in this document or any related presentation, or to develop or release any functionality mentioned therein. This document, or any related presentation and SAP's strategy and possible future developments, products and or platforms directions and functionality are all subject to change and may be changed by SAP at any time for any reason without -

Esri Maps for IBM Cognos and Esri Maps for SAP Businessobjects Canserina Kurnia Technical Manager – Esri Global Asia Pacific
Esri Maps for IBM Cognos and Esri Maps for SAP BusinessObjects Canserina Kurnia Technical Manager – Esri Global Asia Pacific customer records big data collections social media mobile devices images & video spreadsheets analytics assets people Geo-Enable the Enterprise with Esri’s Open Mapping Platform Location Analytics Mission BI ERP CRM EAM PPT Excel SharePoint Break Down Silos Increase Collaboration Collaboration & Focused Apps BI CRM Productivity • IBM Cognos • Microsoft Dynamics • SharePoint • Business Analyst • MicroStrategy CRM • Office • Community Analyst • SAP Business • SalesForce Objects ArcGIS Platform Esri Location Analytics Apps Office MicroStrategy SharePoint Tablets + Phones IBM Cognos Dynamics CRM Share Maps Across Systems One Map Everywhere Four Imperatives Of Mapping in Business Systems 1. Go beyond basic mapping 2. Enrich your view of the world 3. Use the map for analysis 4. Collaborate with maps Esri Maps for SAP BusinessObjects • Allows you to visualize your SAP BusinessObjects data on a map - Discover visual trends - No custom coding or GIS expertise required • Leverages ArcGIS platform - Geo-enable business data - Enrich maps with data from ArcGIS • Allows you to perform spatial analysis Esri Maps for IBM Cognos • Allows you to visualize IBM Cognos data on a map. - Augment business systems with mapping and analytics - Non-disruptive - Use existing workflows • Leverages the ArcGIS platform - Geo-enable enterprise business systems. - Enrich maps with data from ArcGIS. • Allows you to perform spatial analysis within the context of an IBM Cognos report. Demo Thank you . -

EPM Reclaims Lost Profits
Back to the Future: Forward EPM Reclaims Lost Profits In the information age consumer goods and retail need to catch up in technolo- gy,and management strategies, harnessing the power of data management, in order to truly cross into the 21st century. EPM is a solid step in that direction. Brian Queenin | Xtropian am Walton, founder of Wal-Mart, once said: the data management world is software that is S“There is only one boss – the customer. The cus- designed specifically to sift through mountains of data tomer can fire everybody in the company, from the and provide instant, online, accurate and actionable chairman on down, simply by spending his money data that can spell the difference between lines of black somewhere else.” It’s no secret that the success of any or red ink. That’s what decision makers really need – business depends on performance. In fact, a company the capability of organizing and analyzing financial, will exist only as long as its customers are satisfied with operational and external information to enable them to its performance. understand and act before their competitors do and to Walton, like most visionaries, knew that the key to create a competitive advantage yielding sustainable great performance was information, although the nature shareholder value. and environment in which businesses gather and Companies consider the management of such process information has changed significantly since information critical and challenging. Forrester Research The management of critical information in the consumer packaged goods (cpg) industry, where information is as much a commodity as cereal or soap, is particularly challenging.