Cross-Correlation of Beat-Synchronous Representations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

STAR Digio 100 チャンネル:476 REGGAE 放送日:2009/6/8~6/14 「番組案内(6時間サイクル)」 開始時間:4:00~10:00~16:00~22:00~
STAR digio 100 チャンネル:476 REGGAE 放送日:2009/6/8~6/14 「番組案内(6時間サイクル)」 開始時間:4:00~10:00~16:00~22:00~ 楽曲タイトル 演奏者名 REGGAE VIBRATION RASTA SHOULD BE DEEPER JUNIOR KELLY DICK TRACY DEAN FRASER FAMILY AFFAIR SHINEHEAD Zungguzungguguzungguzeng YELLOWMAN CB 200 DILLINGER JAVA AUGUSTUS PABLO REGGAE MAKOSSA Byron Lee & The Dragonaires CUMBOLO CULTURE IT A GO ROUGH Johnny Clarke Got To Be There TOOTS & THE MAYTALS AIN'T THAT LOVING YOU STEELY & CLEVIE featuring BERES HAMMOND (featuring U-ROY) Can I Change My Mind HORACE ANDY Ghetto-Ology SUGAR MINOTT RED RED WINE UB40 BUJU BANTON (1) RASTAFARI BUJU BANTON UNTOLD STORIES BUJU BANTON MAMA AFRICA BUJU BANTON MAYBE WE ARE BUJU BANTON PULL IT UP BERES HAMMOND & BUJU BANTON Hills And Valleys BUJU BANTON 54 / 46 BUJU BANTON featuring TOOTS HIBBERT A LITTLE BIT OF SORRY BUJU BANTON FEELING GROOVY BUJU BANTON Better Must come BUJU BANTON MIRROR BUJU BANTON WHY BUJU LOVE YOU BUJU BANTON We'll Be Alright BUJU BANTON feat. Luciano COVER REGGAE With A Little Help From My Friends Easy Star All-Stars feat. Luciano YOU WON'T SEE ME ERNIE SMITH COME TOGETHER THE ISRAELITES WATCH THIS SOUND THE UNIQUES Holly Holy UB40 BAND OF GOLD SUSAN CADOGAN COUNTRY LIVING (ADAPTED) The mighty diamonds MIDNIGHT TRAIN TO GEORGIA TEDDY BROWN TOUCH ME IN THE MORNING JOHN HOLT Something On My Mind HORACE ANDY ENDLESS LOVE JACKIE EDWARDS & HORTNESE ELLIS CAN'T HURRY LOVE~恋はあせらず~ J.C. LODGE SOMEONE LOVES YOU HONEY STEELY & CLEVIE featuring JC LODGE THERE'S NO ME WITHOUT YOU Fiona ALL THAT SHE WANTS PAM HALL & GENERAL DEGREE JUST THE TWO -

Annie Lennox Waiting in Vain Mp3, Flac, Wma
Annie Lennox Waiting In Vain mp3, flac, wma DOWNLOAD LINKS (Clickable) Genre: Electronic / Pop Album: Waiting In Vain Country: Europe Released: 1995 Style: House, Downtempo MP3 version RAR size: 1954 mb FLAC version RAR size: 1931 mb WMA version RAR size: 1945 mb Rating: 4.3 Votes: 756 Other Formats: FLAC ADX DTS VOC WMA MIDI MP4 Tracklist Hide Credits Waiting In Vain (Single Mix) 1 4:05 Written-By – Bob Marley Train In Vain 2 4:42 Written-By – Strummer*, Jones* No More "I Love You's" (Junior Vasquez Mix) 3 Engineer [Additional] – Dennis MitchellRemix – Junior VasquezWritten-By – D. Freeman*, J. 7:31 Hughes* Credits Engineer – Heff Moraes Producer – Stephen Lipson Notes Made in the EC. Released in slimline jewel case. Barcode and Other Identifiers Barcode: 743213175423 Mastering SID Code: IFPI L030 Mould SID Code: IFPI 0719 Matrix / Runout: SONOPRESS M-1847/4321317542 A Rights Society: BIEM/GEMA Label Code: LC 0316 Other (Distribution code): PM 620 Other versions Category Artist Title (Format) Label Category Country Year Annie Waiting In Vain 74321316132 BMG, RCA 74321316132 UK 1995 Lennox (CD, Single, Ltd) Waiting In Vain Annie BMG VAIN 1 (CDr, Single, VAIN 1 UK 1995 Lennox Records Promo) Annie Waiting In Vain BMG 74321328212 74321328212 Australasia 1995 Lennox (CD, Maxi) Records Train In Vain / 74321 316121, Annie Waiting In Vain / No 74321 316121, RCA, RCA UK 1995 74321316121 Lennox More "I Love You's" 74321316121 (2x12") Annie Waiting In Vain 74321317522 BMG 74321317522 Europe 1995 Lennox (CD, Single) Related Music albums to Waiting In Vain by Annie Lennox Annie Lennox - Little Bird EP Jody Watley - Waiting In Vain Annie Lennox - Why Annie Lennox - Greatest Music Gallery Annie Lennox - Train In Vain Bob marley - waiting in vain/special four track mix up Annie Lennox - Love Song For A Vampire (From "Bram Stoker's Dracula") Leroy Smart - Waiting In Vain Annie Lennox - Medusa Annie Lennox - Precious. -
View Song List
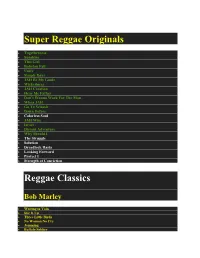
Super Reggae Originals Togetherness Sunshine This Girl Babylon Fall Unify Simple Days JAH Be My Guide Wickedness JAH Creation Hear Me Father Don’t Wanna Work For The Man Whoa JAH Go To Selassie Down Before Colorless Soul JAH Wise Israel Distant Adventure Why Should I The Struggle Solution Dreadlock Rasta Looking Forward Protect I Strength of Conviction Reggae Classics Bob Marley Waiting in Vain Stir It Up Three Little Birds No Woman No Cry Jamming Buffalo Soldier I Shot the Sherriff Mellow Mood Forever Loving JAH Lively Up Yourself Burning and Looting Hammer JAH Live Gregory Issacs Number One Tune In Night Nurse Sunday Morning Soon Forward Cool Down the Pace Dennis Brown Love and Hate Need a Little Loving Milk and Honey Run Too Tuff Revolution Midnite Ras to the Bone Jubilees of Zion Lonely Nights Rootsman Zion Pavilion Peter Tosh Legalize It Reggaemylitis Ketchie Shuby Downpressor Man Third World 96 Degrees in the Shade Roots with Quality Reggae Ambassador Riddim Haffe Rule Sugar Minott Never Give JAH Up Vanity Rough Ole Life Rub a Dub Don Carlos People Unite Credential Prophecy Civilized Burning Spear Postman Columbus Burning Reggae Culture Two Sevens Clash See Dem a Come Slice of Mt Zion Israel Vibration Same Song Rudeboy Shuffle Cool and Calm Garnet Silk Zion in a Vision It’s Growing Passing Judgment Yellowman Operation Eradication Yellow Like Cheese Alton Ellis Just A Guy Breaking Up is Hard to Do Misty in Roots Follow Fashion Poor and Needy -

MIKE DENA “A Singer‐Songwriter with an Old Soul”
MIKE DENA “a singer‐songwriter with an old soul” Mike Dena is a singer‐songwriter, recording artist and performer with influences ranging from The Band, Van Morrison, Ray Charles, Ray LaMontagne, Jim Croce & Ben Harper.. SAMPLE VIDEO REPRESENTATION: KIRSCHNER CREATIVE ARTISTS (562) 429-3732 | [email protected] Song Catalog / Mike Dena Rock-Blues-Soul- Songs (electric and acoustic) • The Joker-Steve Miller • Ill Back You up-Dave Matthews • In The Wintertime-Steve Miller • Diamonds On The Inside-Ben Harper • Cocaine-Eric Clapton • Steal My Kisses-Ben Harper • Willie and the Hand Jive-Eric Clapton • Waiting On An Angel-Ben Harper • Knocking on Heavens Door-Bob Dylan • Walk Away-Ben Harper • Like A Rolling Stone-Bob Dylan • Operater-Jim Croce • Cant Always Get What You Want-Rolling • Flake-Jack Johnson Stones • Traffic In The Sky-Jack Johnson • Sympathy for the Devil-Rolling Stones • Free Bird-Lynard Skynard • Wild Horses-Rolling Stones • Try Me-James Brown • Mustang Sally-Otis Redding • Thrill is Gone-BB King Reggae • Hey Joe-Jimi Hendrix • Voodoo Chile-Jimi Hendrix • 1. Stir It Up-Bob Marley • Red House-Jimi Hendrix • 2. Jamming-Bob Marley • Up From The Skies-Jimi Hendrix • 3. Shes Gone-BobMarley • All Along The Watchtower-Jimi Hendrix • 4. Waiting In Vain-Bob Marley • Foxy Lady-Jimi Hendrix • 5. Jah Live-Bob Marley • Cisco Kid-War • 6. I Shot The Sherrif • Pride and Joy-Stevie Ray Vaughn • 7. Burning And Looting • Life by the Drop-Stevie Ray Vaughn • 8. Thank You Lord-Bob Marley • Steam Roller-James Taylor • 9. Lively Up Yourself-Bob -

Vince Rivers
Song List This list represents the styles and variety of music included in performances. This list, however, is not all inclusive as new material is added on a regular basis. Requested music is always welcomed! Top 40 & Pop Shape of You- Ed Sheeran 24K Magic- Bruno Mars Sugar- Maroon 5 Can’t Stop this Feeling- Justin Timberlake All of Me- John Legend Wake Me Up- Avicii & Aloe Blacc Stay With Me- Sam Smith Sunday Morning- Maroon 5 Suit & Tie- Justin Timberlake Free Fallin'- Tom Petty Come Together- The Beattles Get Lucky- Daft Punk Sitting, Waiting, Wishing- Jack Johnson I Need You Tonight- INXS Steal My Kisses- Ben Harper Brown Eyed Girl- Van Morrison Blurred Lines- Robin Thicke I Can't Help It- Michael Jackson You are the Best Thing- Ray Lamontague If You Want Me to Stay- Sly Stone Crazy- Gnarls Barkley Kiss- Prince Thank You- Sly Stone Happy- Pharrell Williams Banana Pancakes- Jack Johnson Pumped Up Kicks- Foster the People Hard To Handle- Black Crows Tupelo Honey- Van Morrison Billie Jean- Michcael Jackson Way You Make Me Feel- Michael Jackson Moon Dance- Van Morrison You Send Me- Sam Cooke Are You Gonna Be My Girl- Jet Sharp Dressed Man- ZZ Top Return of the Mack- Mark Morrison Boogie Shoes- KC & the Sunshine Band This Is How We do It- Montell Jordan I'm Yours- Jason Mraz World to Change- John Mayer Word Up- Cameo My Perogative- Bobby Brown She Drives Me Crazy- Fine Young Cannibals It Ain't Over- Lenny Kravitz No Such Thing- John Mayer Dynamite_ Taio Cruz Human Nature- Michael Jackson Little Miss Magic- Jimmy Buffet Better Together- -

XM Premieres Never-Released Bob Marley Song and New CDS from UB40 and Jazz Legend Paul Hardcastle
NEWS RELEASE XM Premieres Never-Released Bob Marley Song and New CDS from UB40 and Jazz Legend Paul Hardcastle 3/6/2002 XM TO AIR SHOWS BY HEARTS OF SPACE, GRAMMY-WINNING DUO DEEP DISH AND COUNTRY MUSIC LEGEND BILL ANDERSON Washington D.C., March 06, 2002 -- XM Satellite Radio, America's leading national satellite radio service, will premiere a never-released song from the late reggae icon Bob Marley and CDs from reggae star UB40 and Jazz legend Paul Hardcastle among its revolutionary programming in early March. XM will also air shows from the acclaimed "Hearts of Space" series and by Grammy Award-winning duo Deep Dish and country music legend Bill Anderson. Never-Heard Bob Marley Song Air Exclusively on The Joint Marley's track, "Jump it in a Babylon," was recorded shortly before his death in 1981 and stays true to Marley's humanitarian message to focus on your inner strength and not allow others to detour you from your path. "Jump it in a Babylon" was written and recorded at the home of Marley's mother, Cedella, in his native Jamaica. "The Joint is honored and excited to have the exclusive release of one of the most important and influential artists in history playing on our channel," said Wayne Jobson, Program Director of The Joint (Channel 101), XM's commercial-free reggae channel. Marley was one of the first Jamaican artists to achieve international stardom, introducing reggae music to the world. Songs such as "Jamming," "Waiting in Vain," and "One Love/People Get Ready," gave voice to the day-to-day struggles of the Jamaican experience. -

Tropical Blend Song List
Tropical Breeze Steel Drum/Vocal Ain't No Sunshine ALL NIGHT LONG - Lionel Richie Badfish -Sublime Banana Pancakes -Jack Johnson Better Together -Jack Johnson Black Magic Woman -Santana BROWN EYED GIRL -Van Morrison Can Call Me Al -Paul Simon Could You Be Loved -Bob Marley Diamonds On The Soles Of Her Shoes -Paul Simon Dock Of The Bay Hotel California -Eagles How Sweet It Is -James Taylor I'm Yours -Jason Mraz Iron Lion Zion -Bob Marley Is This Love -Bob Marley Island Song -Zack Brown It's Five O'Clock Somewhere -Jimmy Buffett The Joker -Steve Miller Band Kingston Town -UB40 Knee Deep -Zack Brown La Bamba Late In The Evening -Paul Simon Look Who's Dancing -Ziggy Marley LOVE SONG -311 Mary Jane's Last Dance- Tom Petty Natural Mystic -Bob Marley New Light -John Mayer Night Nurse -Gregory Isaacs OYE COMO VA -Santana Red Red Wine -UB40 Santeria -Sublime Smooth -Santana Stir It Up -Bob Marley Three Little Birds -Bob Marley Toes -Zack Brown Upside Down -Jack Johnson Waiting In Vain Bob Marley THE WAY YOU DO THE THINGS YOU DO -UB40 When The Sun Goes Down -Kenny Chesney Where The Boat Leaves From -Zack Brown Wild World -Maxi Priest 50 Ways To Leave Your Lover - Paul Simon BANANA BOAT Don’t worry be happy Everywhere calypso guantanamera THE HAMMER I Can see clearly now I shot the sheriff jamacan farewell Jump the line Linstead market Lion sleeps tonight Margaritiville Maryann MATILDA Pass the Dutchie Red red wine spanish harlem st thomas Tobago Jam UNDER THE SEA Volcano WAVE yellowbird . -

XM Celebrates Bob Marley's Birthday with Marathon of Exclusive Programming
NEWS RELEASE XM Celebrates Bob Marley's Birthday with Marathon of Exclusive Programming 2/5/2002 TRIBUTE HOSTED BY FORMER WAILERS LEAD GUITARIST JUNIOR MARVIN ON XM'S THE JOINT Washington D.C., February 05, 2002 -- XM Satellite Radio will broadcast a marathon tribute Wednesday, Feb. 6, celebrating the life and music of reggae legend Bob Marley on what would have been his 57th birthday. Junior Marvin, Marley's former lead guitarist and a member of XM's artists family, will host the 12-hour special on XM's commercial-free reggae channel, The Joint (XM Channel 101). The tribute, which will run from 8 am to 8pm February 6, will include exclusive, never-aired stories and tapes. XM will also feature recordings of Marley's live concerts at the BBC and The Rainbow in London, and original interviews with Marley's mother, Cedella, and son Ziggy Marley. Marley was one of the first Jamaican artists to achieve international stardom, introducing reggae music to the world. Songs such as "Jamming," "Waiting in Vain," and "One Love/People Get Ready," gave voice to the day-to-day struggles of the Jamaican experience. "Bob Marley is an icon not only in reggae history but in music history and we are proud to celebrate his contributions on XM," said Lee Abrams XM Chief Programming Officer. The Marley tribute is part of a broad array of original programming XM is bringing in February, including a comprehensive celebration of Black History Month, a live broadcast of the celebrated "Down from the Mountain" tour, and exclusive live coverage of NASCAR's Daytona 500. -

Island Music Songlist
island music songlist We proudly offer a full menu of song choices that rise to any occasion! In addition to the titles listed below, we maintain an expansive, diverse and ever-expanding library to supplement any songs, artists or styles not represented on this list. Our music designers will make every attempt to incorporate the musical requests specified on these sheets as well as any requests made on the day of the function. INSTRUCTIONS: 1) Print your name / party date below; 2) check off your favorite songs and artists in each category; and 3) include your "must play" songs on the "Top 15" worksheet provided (these selections need NOT be from this song list.) Please return your song list to the office via email ([email protected]), fax (808.982.8340) or post (P.O. Box 2267, Kailua-Kona, HI 96745) at least THREE WEEKS prior to your event date! NAME: EVENT DATE: / / q PELE KANE • MAUNALUA TRADITIONAL HAWAIIAN q PILI MAI NO I KA IHU • AMY HANAIALII GILLIOM q AKAKA FALLS • KEALI'I REICHEL q PILI ME KA'U MANU • ISRAEL "IZ" KAMAKAWIWO'OLE q 'ALIKA • GENOA KEAWE q POHAI KEALOHA • HUI 'OHANA q ALOHA 'OE • KEALOHA KONO q PUPU A' O 'EWA • KEALI'I REICHEL q E ALA E • ISRAEL "IZ" KAMAKAWIWO'OLE q ULILI E • MAKUA ROTHMAN q E APO MAI • NATHAN AWEAU q ULUPALAKUA • HUI 'OHANA q E KU'U MORNING DEW • EDDIE KAMAE & SONS OF HAWAII q WAHINE 'ILIKEA • EDDIE KAMAE & SONS OF HAWAII q E KU'U TUTU • RAIATEA q E O MAI • KEALI'I REICHEL SLACK KEY q E PILI MAI • KEALI'I REICHEL q BACKYARD SLACK • SEAN NA'AUAO q EHUEHU MAI NEI 'O MANOA • AARON J. -

{Dоwnlоаd/Rеаd PDF Bооk} Guitar Chord Songbook
GUITAR CHORD SONGBOOK - BOB MARLEY PDF, EPUB, EBOOK Bob Marley | 106 pages | 05 May 2011 | Hal Leonard Corporation | 9781423495376 | English | Milwaukee, United States Guitar Chord Songbook - Bob Marley PDF Book Lists with This Book. Books by Bob Marley. Add to Wishlist. Bass Play-Along. Delve deep into the blues with celebrated guitarist Kirk Fletcher in this instructional Stir It Up. Smile Jamaica. Thank you for your review! You'll be amazed at how creative you can be with this great book. Kinky Reggae. NOTE: The sample above is just the first page preview of this item. Another Classic Songs specially arranged for beginner guitarists- Following on from the first volume of his bestselling Beginner's Songbook Volume 2 boasts another classic songs from the past and present specially arrange. Paperback , pages. Guitar Chord Songbook. Overview Guitar Chord Songbook. Bob Dylan for Clawhammer Banjo. Bend Down Low. Kristen Yancey rated it really liked it Mar 10, Talkin' Blues. Rizal rated it it was amazing Dec 16, Rivers Of Babylon. Get Up, Stand Up. With so many incredible tunes you'll alwaysbe finding new things to play and wi. Buy this item to display, print, and play the complete music. For a better shopping experience, please upgrade now. The Guitar Play-Along series will help you play your favorite songs quickly and easily! Other editions. Real Situation. Just follow the tab, listen to the audio to hear how the guitar should sound, and then play along using the separate backing tracks. More filters. Time Will Tell. Composed by Various. Rock and classic rock. -

Bob Marley – Primary Wave Music
BOB MARLEY facebook.com/BobMarley instagram.com/bobmarley/ twitter.com/bobmarley Imageyoutube.com/bobmarley not found or type unknown bobmarley.com open.spotify.com/user/primarywavemusic/playlist/7nKdMQsvQzxa8MVF3BdD8f Robert Nesta Marley, OM (6 February 1945 – 11 May 1981) Given the image of him as a smiling, joint-smoking peacenik that has proliferated since his death in 1981, it’s easy to forget just how angry Bob Marley was. His music spoke to colonialism (“Small Axe”), poverty (“Them Belly Full [But We Hungry]”), the necessity of achieving political agency (“Get Up, Stand Up”), and the challenge of exercising it (“Burnin’ and Lootin’”) with a righteousness and frustration that made him as much a figurehead to punk rock as to the reggae he helped export to the world. He may have been ambivalent about politics (he once said it was pretty much the same thing as church—a way to keep people ignorant), but it wasn’t because of their underlying possibilities; it was the way the political system had been twisted by the tyranny and greed of people in power that troubled him. And if his music sounded sweet and made you want to dance, it’s because, as his sometime publicist Vivien Goldman once put it, he knew that if he hooked you with the melody, you’d have to listen to what he had to say. Born in 1945 in Nine Mile, a rural village about an hour and a half outside Kingston, Marley formed The Wailers with Peter Tosh and Bunny Wailer in his late teens, thickening from cheerful R&B-based ska to the more rhythmically substantive sound of reggae. -

The Top 200 Greatest Reggae Songs
The top 200 greatest reggae songs 1. No Woman, No Cry - Bob Marley & the Wailers 2. Israelites - Desmond Dekker & the Aces 3. Stir It Up - Bob Marley & the Wailers 4. Pressure Drop - Toots & the Maytals 5. The Harder They Come - Jimmy Cliff 6. One Love - Bob Marley & the Wailers 7. 54-46 That's My Number - Toots & the Maytals 8. Satta Massagana - The Abyssinians 9. Funky Kingston - Toots & the Maytals 10. Montego Bay - Freddie Notes & The Rudies 11. Many Rivers To Cross - Jimmy Cliff 12. Marcus Garvey - Burning Spear 13. Legalize It - Peter Tosh 14. Redemption Song - Bob Marley & the Wailers 15. Here I Come - Dennis Brown 16. Get Up, Stand Up - Bob Marley & the Wailers 17. Rudy Got Soul - Desmond Dekker & The Aces 18. The Tide Is High - The Paragons 19. Three Little Birds - Bob Marley & the Wailers 20. Everything I Own - Ken Boothe 21. Night Nurse - Gregory Isaacs 22. You Don't Care - The Techniques 23. Vietnam - Jimmy Cliff 24. Rivers Of Babylon - The Melodians 25. Police & Thieves - Junior Murvin 26. Buffalo Soldier - Bob Marley & the Wailers 27. Red Red Wine - UB40 28. Cherry Oh Baby - Eric Donaldson 29. (I Am) The Upsetter - Lee "Scratch" Perry 30. Sitting & Watching - Dennis Brown 31. Jammin' - Bob Marley & the Wailers 32. Wear You To The Ball - U-Roy & The Paragons 33. Two Sevens Clash - Culture 34. I Shot The Sheriff - Bob Marley & the Wailers 35. Armagideon Time - Willie Williams 36. 007 Shanty Town - Desmond Dekker & The Aces 37. A Love I Can Feel - John Holt 38. Revolution - Dennis Brown 39. Queen Majesty - The Techniques 40.