Massive Model Visualization: an Investigation Into Spatial Partitioning Jeremy S
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Efficient Evaluation of Radial Queries Using the Target Tree
Efficient Evaluation of Radial Queries using the Target Tree Michael D. Morse Jignesh M. Patel William I. Grosky Department of Electrical Engineering and Computer Science Dept. of Computer Science University of Michigan, University of Michigan-Dearborn {mmorse, jignesh}@eecs.umich.edu [email protected] Abstract from a number of chosen points on the surface of the brain and end in the tumor. In this paper, we propose a novel indexing structure, We use this problem to motivate the efficient called the target tree, which is designed to efficiently evaluation of a new type of spatial query, which we call a answer a new type of spatial query, called a radial query. radial query, which will allow for the efficient evaluation A radial query seeks to find all objects in the spatial data of surgical trajectories in brain surgeries. The radial set that intersect with line segments emanating from a query is represented by a line in multi-dimensional space. single, designated target point. Many existing and The results of the query are all objects in the data set that emerging biomedical applications use radial queries, intersect the line. An example of such a query is shown in including surgical planning in neurosurgery. Traditional Figure 1. The data set contains four spatial objects, A, B, spatial indexing structures such as the R*-tree and C, and D. The radial query is the line emanating from the quadtree perform poorly on such radial queries. A target origin (the target point), and the result of this query is the tree uses a regular hierarchical decomposition of space set that contains the objects A and B. -

Opengl Shaders and Programming Models That Provide Object Persistence
OpenGL shaders and programming models that provide object persistence COSC342 Lecture 22 19 May 2016 OpenGL shaders É We discussed forms of local illumination in the ray tracing lectures. É We also saw that there were reasons you might want to modify these: e.g. procedural textures for bump maps. É Ideally the illumination calculations would be entirely programmable. É OpenGL shaders facilitate high performance programmability. É They have been available as extensions since OpenGL 1.5 (2003), but core within OpenGL 2.0 (2004). É We will focus on vertex and fragment shaders, but there are other types: e.g. geometry shaders, and more recent shaders for tessellation and general computing. COSC342 OpenGL shaders and programming models that provide object persistence 2 GL Shading Language|GLSL É C-like syntax. (No surprises given the OpenGL lineage . ) É However, compared to `real' use of C, GLSL programmers are further away from the actual hardware. É Usually the GLSL code will be passed as a string into the OpenGL library you are using. É Only supports limited number of data types: e.g. float, double,... É Adds some special types of its own: e.g. vector types vec2, vec4. É Unlike most software, GLSL is typically compiled every time you load your functions|there isn't (yet...) a standardised GL machine code. COSC342 OpenGL shaders and programming models that provide object persistence 3 GLSL on the hardware É The GLSL syntax just provides a standard way to specify functions. É Different vendors may use vastly different hardware implementations. É (Or indeed the CPU may be doing the GLSL work, e.g. -

Lecture 08: Hierarchical Modeling with Scene Graphs
Lecture 08: Hierarchical Modeling with Scene Graphs CSE 40166 Computer Graphics Peter Bui University of Notre Dame, IN, USA November 2, 2010 Symbols and Instances Objects as Symbols Model world as a collection of object symbols. Instance Transformation Place instances of each symbol in model using M = TRS. 1 glTranslatef (dx, dy, dz); 2 g l R o t a t e f (angle, rx, ry, rz); 3 g l S c a l e f (sx, sy, sz); 4 gluCylinder (quadric, base, top, height, slices, stacks); Problem: No Relationship Among Objects Symbols and instances modeling technique contains no information about relationships among objects. I Cannot separate movement of Wall-E from individual parts. I Hard to take advantage of the re-usable objects. Solution: Use Graph to Model Objects Represent the visual and abstract relationships among the parts of the models with a graph. I Graph consists of a set of nodes and a set of edges. I In directed graph, edges have a particular direction. Example: Robot Arm 1 display () 2 { 3 g l R o t a t e f (theta, 0.0, 1.0, 0.0); 4 base (); 5 glTranslatef (0.0, h1, 0.0); 6 g l R o t a t e f (phi, 0.0, 0.0, 1.0); 7 lower_arm(); 8 glTranslatef (0.0, h2, 0.0); 9 g l R o t a t e f (psi, 0.0, 0.0, 1.0); 10 upper_arm(); 11 } Example: Robot Arm (Graph) 1 ConstructRobotArm(Root) 2 { 3 Create Base; 4 Create LowerArm; 5 Create UpperArm; 6 7 Connect Base to Root; 8 Connect LowerArm to Base; 9 Connect UpperArm to LowerArm; 10 } 11 12 RenderNode(Node) 13 { 14 Store Environment; 15 16 Node.Render(); 17 18 For Each child in Node.children: 19 RenderNode(child); 20 21 Restore Environment; 22 } Scene Graph: Node Node in a scene graph requires the following components: I Render: A pointer to a function that draws the object represented by the node. -

Using Graph-Based Data Structures to Organize and Manage Scene
d07wals.x.g2db Page 1 of 7 Thursday, April 4, 2002 8:47:50 AM HEAD: Understanding Scene Graphs DEK Using graph-based Bio data structures to Aaron is chairman of Mantis Development, and teaches computer graphics and In- organize and manage ternet/Web application development at Boston College. He can be contacted at scene contents [email protected]. Byline NOTE TO AUTHORS: PLEASE CHECK ALL URLs AND SPELLINGS OF NAMES CAREFULLY. Aaron E. Walsh THANK YOU. Pullquotes Before scene-graph programming Scene-graph models, we usually nodes represent represented scene objects in a scene data and behavior procedurally d07wals.x.g2db Page 2 of 7 Thursday, April 4, 2002 8:47:50 AM 2.1 cene graphs are data structures used 2.68 At the scene level, you concern your- – to organize and manage the contents – self with what’s in the scene and any as- – of hierarchically oriented scene data. – sociated behavior or interaction among – Traditionally considered a high-level – objects therein. Underlying implementa- 2.5 S – data management facility for 3D content, tion and rendering details are abstracted – scene graphs are becoming popular as – out of the scene-graph programming mod- – general-purpose mechanisms for manag- – el. In this case, you can assume that your – ing a variety of media types. MPEG-4, for 2.75 VRML browser plug-in handles low-level – instance, uses the Virtual Reality Model- – concerns. 2.10 ing Language (VRML) scene-graph pro- – – gramming model for multimedia scene – Nodes and Arcs – composition, regardless of whether 3D – As Figure 2 depicts, scene graphs consist – data is part of such content. -
Transformations Rotation and Scaling
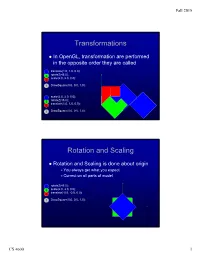
Fall 2015 Transformations In OpenGL, transformation are performed in the opposite order they are called 4 translate(1.0, 1.0, 0.0); 3 rotateZ(45.0); 2 scale(2.0, 2.0, 0.0); 1 DrawSquare(0.0, 0.0, 1.0); 4 scale(2.0, 2.0, 0.0); 3 rotateZ(45.0); translate(1.0, 1.0, 0.0); 2 1 DrawSquare(0.0, 0.0, 1.0); Rotation and Scaling Rotation and Scaling is done about origin You always get what you expect Correct on all parts of model 4 rotateZ(45.0); 3 scale(2.0, 2.0, 0.0); 2 translate(-0.5, -0.5, 0.0); 1 DrawSquare(0.0, 0.0, 1.0); CS 4600 1 Fall 2015 Load and Mult Matrices in MV.js Mat4(m) Mat4(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16) Sets the sixteen values of the current matrix to those specified by m. CTM = mult(CTM, xformMatrix); Multiplies the matrix,CTM, by xformMatrix and stores the result as the current matrix, CTM. OpenGL uses column instead of row vectors However, MV.js treats things in row-major order Flatten does the transpose Matrices are defined like this (use float m[16]); CS 4600 2 Fall 2015 Object Coordinate System Used to place objects in scene Draw at origin of WCS Scale and Rotate Translate to final position Use the MODELVIEW matrix as the CTM scale(x, y, z) rotate[XYZ](angle) translate(x, y, z) lookAt(eyeX, eyeY, eyeZ, atX, atY, atZ, upX, upY, upZ) lookAt LookAt(eye, at, up) Angel and Shreiner: Interactive Computer Graphics 7E © Addison-Wesley 2015 CS 4600 3 Fall 2015 The lookAt Function The GLU library contained the function gluLookAt to form the required modelview matrix through a simple interface Note -

The Skip Quadtree: a Simple Dynamic Data Structure for Multidimensional Data
The Skip Quadtree: A Simple Dynamic Data Structure for Multidimensional Data David Eppstein† Michael T. Goodrich† Jonathan Z. Sun† Abstract We present a new multi-dimensional data structure, which we call the skip quadtree (for point data in R2) or the skip octree (for point data in Rd , with constant d > 2). Our data structure combines the best features of two well-known data structures, in that it has the well-defined “box”-shaped regions of region quadtrees and the logarithmic-height search and update hierarchical structure of skip lists. Indeed, the bottom level of our structure is exactly a region quadtree (or octree for higher dimensional data). We describe efficient algorithms for inserting and deleting points in a skip quadtree, as well as fast methods for performing point location and approximate range queries. 1 Introduction Data structures for multidimensional point data are of significant interest in the computational geometry, computer graphics, and scientific data visualization literatures. They allow point data to be stored and searched efficiently, for example to perform range queries to report (possibly approximately) the points that are contained in a given query region. We are interested in this paper in data structures for multidimensional point sets that are dynamic, in that they allow for fast point insertion and deletion, as well as efficient, in that they use linear space and allow for fast query times. Related Previous Work. Linear-space multidimensional data structures typically are defined by hierar- chical subdivisions of space, which give rise to tree-based search structures. That is, a hierarchy is defined by associating with each node v in a tree T a region R(v) in Rd such that the children of v are associated with subregions of R(v) defined by some kind of “cutting” action on R(v). -

Principles of Computer Game Design and Implementation
Principles of Computer Game Design and Implementation Lecture 14 We already knew • Collision detection – high-level view – Uniform grid 2 Outline for today • Collision detection – high level view – Other data structures 3 Non-Uniform Grids • Locating objects becomes harder • Cannot use coordinates to identify cells Idea: choose the cell size • Use trees and navigate depending on what is put them to locate the cell. there • Ideal for static objects 4 Quad- and Octrees Quadtree: 2D space partitioning • Divide the 2D plane into 4 (equal size) quadrants – Recursively subdivide the quadrants – Until a termination condition is met 5 Quad- and Octrees Octree: 3D space partitioning • Divide the 3D volume into 8 (equal size) parts – Recursively subdivide the parts – Until a termination condition is met 6 Termination Conditions • Max level reached • Cell size is small enough • Number of objects in any sell is small 7 k-d Trees k-dimensional trees • 2-dimentional k-d tree – Divide the 2D volume into 2 2 parts vertically • Divide each half into 2 parts 3 horizontally – Divide each half into 2 parts 1 vertically » Divide each half into 2 parts 1 horizontally • Divide each half …. 2 3 8 k-d Trees vs (Quad-) Octrees • For collision detection k-d trees can be used where (quad-) octrees are used • k-d Trees give more flexibility • k-d Trees support other functions – Location of points – Closest neighbour • k-d Trees require more computational resources 9 Grid vs Trees • Grid is faster • Trees are more accurate • Combinations can be used Cell to tree Grid to tree 10 Binary Space Partitioning • BSP tree: recursively partition tree w.r.t. -

Computation of Potentially Visible Set for Occluded Three-Dimensional Environments
Computation of Potentially Visible Set for Occluded Three-Dimensional Environments Derek Carr Advisor: Prof. William Ames Boston College Computer Science Department May 2004 Page 1 Abstract This thesis deals with the problem of visibility culling in interactive three- dimensional environments. Included in this thesis is a discussion surrounding the issues involved in both constructing and rendering three-dimensional environments. A renderer must sort the objects in a three-dimensional scene in order to draw the scene correctly. The Binary Space Partitioning (BSP) algorithm can sort objects in three- dimensional space using a tree based data structure. This thesis introduces the BSP algorithm in its original context before discussing its other uses in three-dimensional rendering algorithms. Constructive Solid Geometry (CSG) is an efficient interactive modeling technique that enables an artist to create complex three-dimensional environments by performing Boolean set operations on convex volumes. After providing a general overview of CSG, this thesis describes an efficient algorithm for computing CSG exp ression trees via the use of a BSP tree. When rendering a three-dimensional environment, only a subset of objects in the environment is visible to the user. We refer to this subset of objects as the Potentially Visible Set (PVS). This thesis presents an algorithm that divides an environment into a network of convex cellular volumes connected by invisible portal regions. A renderer can then utilize this network of cells and portals to compute a PVS via a depth first traversal of the scene graph in real-time. Finally, this thesis discusses how a simulation engine might exploit this data structure to provide dynamic collision detection against the scene graph. -

Open Scene Graph ODE - Open Dynamics Engine
Universidade do Vale do Rio dos Sinos Virtual Reality Tools OSG - Open Scene Graph ODE - Open Dynamics Engine M.Sc . Milton Roberto Heinen - Unisinos / UFRGS E-mail: [email protected] Dr. Fernando S. Osório - Unisinos E-mail: [email protected] Artificial Intelligence Group - GIA Virtual Reality Tools OSG (Open Scene Graph) + ODE (Open Dynamics Engine) Open Scene Graph Programa de Pós-Graduação em Computação Aplicada PIPCA Grupo de Inteligência Artificial - GIA 1 Virtual Reality Tools OSG (Open Scene Graph) + ODE (Open Dynamics Engine) Open Scene Graph - OSG http://www.openscenegraph.org/ • OSG: Open and Free Software Object Oriented (C++) Software Library (API) • The OSG Library is an abstraction layer over the OpenGL, allowing to easily create complex visual scenes • With OSG you do not need to use other APIs like MFC, GTK or Glut (windows and device libs) • With OSG you can read/show several 3D file formats as for example VRML, OBJ, DirectX (.X), OSG using textures, lights, particles and other visual effects • OSG works in Windows and Linux Environments creating portable graphical applications Programa de Pós-Graduação em Computação Aplicada PIPCA Grupo de Inteligência Artificial - GIA Virtual Reality Tools OSG (Open Scene Graph) + ODE (Open Dynamics Engine) OSG – Primitive Objects Programa de Pós-Graduação em Computação Aplicada PIPCA Grupo de Inteligência Artificial - GIA 2 Virtual Reality Tools OSG (Open Scene Graph) + ODE (Open Dynamics Engine) OSG – Textures Programa de Pós-Graduação em Computação Aplicada PIPCA Grupo de Inteligência -

Introduction to Computer Graphics Farhana Bandukwala, Phd Lecture 17: Hidden Surface Removal – Object Space Algorithms Outline
Introduction to Computer Graphics Farhana Bandukwala, PhD Lecture 17: Hidden surface removal – Object Space Algorithms Outline • BSP Trees • Octrees BSP Trees · Binary space partitioning trees · Steps: 1. Group scene objects into clusters (clusters of polygons) 2. Find plane, if possible that wholly separates clusters 3. Clusters on same side of plane as viewpoint can obscure clusters on other side 4. Each cluster can be recursively subdivided P1 P1 back A front D P2 P2 3 1 front back front back P2 B D C A B C 3,1,2 3,2,1 1,2,3 2,1,3 2 BSP Trees,contd · Suppose the tree was built with polygons: 1. Pick 1 polygon (arbitrary) as root 2. Its plane is used to partition space into front/back 3. All intersecting polygons are split into two 4. Recursively pick polygons from sub-spaces to partition space further 5. Algorithm terminates when each node has 1 polygon only P1 P1 back P6 front P3 P2 back front back P5 P2 P4 P3 P4 P6 P5 BSP Trees,contd · Traverse tree in order: 1. Start from root node 2. If view point in front: a) Draw polygons in back branch b) Then root polygon c) Then polygons in front branch 3. If view point in back: a) Draw polygons in front branch b) Then root polygon c) Then polygons in back branch 4. Recursively perform front/back test and traverse child nodes P1 P1 back P6 front P3 P2 back front back P5 P2 P4 P3 P4 P6 P5 Octrees · Consider splitting volume into 8 octants · Build tree containing polygons in each octant · If an octant has more than minimum number of polygons, split again 4 5 4 5 4 5 1 0 5 0 0 1 5 5 0 1 1 1 7 0 1 0 2 3 5 7 7 3 3 2 3 2 3 Octrees, contd · Best suited for orthographic projection · Display polygons in octant farthest from viewer first · Then those nodes that share a border with this octant · Recursively display neighboring octant · Last display closest octant Octree, example y 2 4 Viewpoint 8 11 6 12 114 12 14 9 6 10 13 1 5 3 5 x z Octants labeled in the order drawn given the viewpoint shown here. -

Hierarchical Bounding Volumes Grids Octrees BSP Trees Hierarchical
Spatial Data Structures HHiieerraarrcchhiiccaall BBoouunnddiinngg VVoolluummeess GGrriiddss OOccttrreeeess BBSSPP TTrreeeess 11/7/02 Speeding Up Computations • Ray Tracing – Spend a lot of time doing ray object intersection tests • Hidden Surface Removal – painters algorithm – Sorting polygons front to back • Collision between objects – Quickly determine if two objects collide Spatial data-structures n2 computations 3 Speeding Up Computations • Ray Tracing – Spend a lot of time doing ray object intersection tests • Hidden Surface Removal – painters algorithm – Sorting polygons front to back • Collision between objects – Quickly determine if two objects collide Spatial data-structures n2 computations 3 Speeding Up Computations • Ray Tracing – Spend a lot of time doing ray object intersection tests • Hidden Surface Removal – painters algorithm – Sorting polygons front to back • Collision between objects – Quickly determine if two objects collide Spatial data-structures n2 computations 3 Speeding Up Computations • Ray Tracing – Spend a lot of time doing ray object intersection tests • Hidden Surface Removal – painters algorithm – Sorting polygons front to back • Collision between objects – Quickly determine if two objects collide Spatial data-structures n2 computations 3 Speeding Up Computations • Ray Tracing – Spend a lot of time doing ray object intersection tests • Hidden Surface Removal – painters algorithm – Sorting polygons front to back • Collision between objects – Quickly determine if two objects collide Spatial data-structures n2 computations 3 Spatial Data Structures • We’ll look at – Hierarchical bounding volumes – Grids – Octrees – K-d trees and BSP trees • Good data structures can give speed up ray tracing by 10x or 100x 4 Bounding Volumes • Wrap things that are hard to check for intersection in things that are easy to check – Example: wrap a complicated polygonal mesh in a box – Ray can’t hit the real object unless it hits the box – Adds some overhead, but generally pays for itself. -

Hierarchical Modeling and Scene Graphs
Hierarchical Modeling and Scene Graphs Adapted from material prepared by Ed Angel University of Texas at Austin CS354 - Computer Graphics Spring 2009 Don Fussell Objectives Examine the limitations of linear modeling Symbols and instances Introduce hierarchical models Articulated models Robots Introduce Tree and DAG models Examine various traversal strategies Generalize the notion of objects to include lights, cameras, attributes Introduce scene graphs University of Texas at Austin CS354 - Computer Graphics Don Fussell Instance Transformation Start with a prototype object (a symbol) Each appearance of the object in the model is an instance Must scale, orient, position Defines instance transformation University of Texas at Austin CS354 - Computer Graphics Don Fussell Relationships in Car Model Symbol-instance table does not show relationships between parts of model Consider model of car Chassis + 4 identical wheels Two symbols Rate of forward motion determined by rotational speed of wheels University of Texas at Austin CS354 - Computer Graphics Don Fussell Structure Through Function Calls car(speed){ chassis() wheel(right_front); wheel(left_front); wheel(right_rear); wheel(left_rear); } • Fails to show relationships well • Look at problem using a graph University of Texas at Austin CS354 - Computer Graphics Don Fussell Graphs Set of nodes and edges (links) Edge connects a pair of nodes Directed or undirected Cycle: directed path that is a loop loop University of Texas at Austin CS354 - Computer Graphics Don Fussell Tree Graph in which each