The Applicability of TESTAR on Accessibility Evaluation and The
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Overview Work Experience Skills Contact Education
OVERVIEW Have over 6 years experience in development E-Learning Tool, 1 year experience in development Search Engine website; 1 year in defect tracking tool, 6 months experience in development Task Management tool; 4 years experience in development Enterprise Social Network. Skill in C/C++, VC++, Java Springframework, C#, ASP.Net, Linq, WPF, WCF, JavaScript., .Net Framework 1.x, Net Framework 2.0, 3.5, 4.0, REST API. Good knowledge in Object Oriented Programming. Have years experience in C++, VC++, C#.Net, Java, Javascript and 6 years experience in Cross Platforms Programming, System Events Hook technique, Application Programming Interface Hook technique, Java Access Bridge, Microsoft Active Accessibility, and IHTML, Java, Spring MVC. CONTACT WORK EXPERIENCE 03 Apr, 1981 Senior Software Engineer January, 2014- Now Ho Chi Minh City PROJECT: ZILLABLE Project Description: Enterprise Social Network EDUCATION Industry: Social Network Project Team Size: 15+ Bachelor – Information Technology, Role(s): Developer, Component owner University of Sciences and Natural, Skill Set Utilized: Ho Chi Minh City, VietNam Languages: Java, AngularJS Middleware: MongoDB, Elasticsearch SKILLS Others: REST API, Integration: Google APIs, OneDrive API, DropBox, Interested in and researching: Box Auth2 AI Responsibilities: Programming Crypto, Smart Contract Number of People Managed: 0 FinTech Assignment Duration Algorithms High level programming: Senior Software Engineer January, 2013 - 2014 define data models and basic PROJECT: INTEGRIS relationships for code generation -

Database Client Installation Guide
Oracle® Database Database Client Installation Guide 18c for HP-UX Itanium E83741-01 November 2018 Oracle Database Database Client Installation Guide, 18c for HP-UX Itanium E83741-01 Copyright © 2015, 2018, Oracle and/or its affiliates. All rights reserved. Primary Author: Prakash Jashnani Contributing Authors: Douglas Williams Contributors: Mark Bauer, David Austin, Neha Avasthy, Prasad Bagal, Subhranshu Banerjee, Mark Bauer, Tammy Bednar, Eric Belden, Gavin Bowe, Robert Chang, Darcy Christensen, Kiran Chamala, Jonathan Creighton, Benoit Dageville, Sudip Datta, Jim Erickson, Marcus Fallen, Joseph Francis, Mark Fuller, Allan Graves, Barbara Glover, Asad Hasan, Thirumaleshwara Hasandka, Prasad Kuruvadi Nagaraj, Clara Jaeckel, Aneesh Khandelwal, Joel Kallman, Eugene Karichkin, Jai Krishnani, Sangeeth Kumar, Ranjith Kundapur, Kevin Jernigan, Christopher Jones, Simon Law, Bryn Llewellyn, Saar Maoz, Sreejith Minnanghat, Gopal Mulagund, Sue Lee, Rich Long, Barb Lundhild, Rolly Lv, Rudregowda Mallegowda, Padmanabhan Manavazhi, Mughees Minhas, Krishna Mohan, Matthew McKerley, John McHugh, Gurudas Pai, Satish Panchumarthy , Rajesh Prasad, Rajendra Pingte, Apparsamy Perumal, Srinivas Poovala, Mohammed Shahnawaz Quadri, Hanlin Qian, Gurumurthy Ramamurthy, Hema Ramamurthy, Sunil Ravindrachar, Mark Richwine, Dipak Saggi, Trivikrama Samudrala, Shachi Sanklecha, David Schreiner, Ara Shakian, Mohit Singhal, Dharma Sirnapalli, Akshay Shah, James Spiller, Roy Swonger, Binoy Sukumaran, Kamal Tbeileh, Ravi Thammaiah, Shekhar Vaggu, Parvathi Subramanian, Ajesh Viswambharan, Peter Wahl, Terri Winters, Sergiusz Wolicki, Sivakumar Yarlagadda, Zakia Zerhouni This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. -

Migrating to the Cloud: Oracle Client-Server Modernization
Migrating to the Cloud > This page intentionally left blank Migrating to the Cloud Oracle Client/Server Modernization Tom Laszewski Prakash Nauduri Technical Editor Ward Spangenberg AMSTERDAM • BOSTON • HEIDELBERG • LONDON NEW YORK • OXFORD • PARIS • SAN DIEGO SAN FRANCISCO • SINGAPORE • SYDNEY • TOKYO Syngress is an imprint of Elsevier Acquiring Editor: Chris Katsaropoulos Development Editor: Matt Cater Project Manager: Jessica Vaughan Designer: Alisa Andreola Syngress is an imprint of Elsevier 225 Wyman Street, Waltham, MA 02451, USA Ó 2012 Elsevier Inc. All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or any information storage and retrieval system, without permission in writing from the publisher. Details on how to seek permission, further information about the Publisher’s permissions policies and our arrangements with organizations such as the Copyright Clearance Center and the Copyright Licensing Agency, can be found at our website: www.elsevier.com/permissions. This book and the individual contributions contained in it are protected under copyright by the Publisher (other than as may be noted herein). Notices Knowledge and best practice in this field are constantly changing. As new research and experience broaden our understanding, changes in research methods or professional practices may become necessary. Practitioners and researchers must always rely on their own experience and knowledge in evaluating and using any information or methods described herein. In using such information or methods they should be mindful of their own safety and the safety of others, including parties for whom they have a professional responsibility. -

Kofax RPA Installation Guide Version: 11.0.0
Kofax RPA Installation Guide Version: 11.0.0 Date: 2019-12-18 © 2015–2020 Kofax. All rights reserved. Kofax is a trademark of Kofax, Inc., registered in the U.S. and/or other countries. All other trademarks are the property of their respective owners. No part of this publication may be reproduced, stored, or transmitted in any form without the prior written permission of Kofax. Table of Contents Preface.......................................................................................................................................................... 4 Related Documentation...................................................................................................................... 4 Offline Documentation............................................................................................................. 6 Training............................................................................................................................................. 10 Getting help with Kofax products.....................................................................................................10 Chapter 1: Dependencies and Prerequisites......................................................................................... 11 Chapter 2: Install Kofax RPA................................................................................................................... 19 Install on Windows........................................................................................................................... 20 Install -

Azul Zulu Builds of Openjdk April 20, 2021 Update Release
Azul Zulu builds of OpenJDK April 20, 2021 Update Release Azul Zulu 11.48 (CA) for Arm 64-bit Document Version: 1.0 Updated: Apr 21, 2021 Table of Contents What’s New . 2 April 20, 2021 PSU Release. 2 IANA time zone data version . 2 New Features and Enhancements. 2 Fixed Issues . 3 JDK Common Vulnerabilities and Exposure (CVE) Fixes. 3 Non-CVE Security Fixes . 6 OpenJDK Bug Fixes . 6 About This Build . 19 Supported Platforms . 19 Supported Functionality . 19 HotSpot Compilers . 19 Getting Started with Azul Zulu . 21 Legal Notice . 22 Revision History Revision Date Description 0.1 April 20, 2021 Initial version of the document. 1.0 April 20, 2021 Added information about CVEs fixed in this release. 1 What’s New April 20, 2021 PSU Release This section describes new features and changes in behavior introduced in April 20, 2021 Azul Zulu PSU Update Release. Azul Zulu Version: 11.48 (11.0.11+9) Release Date: April 20, 2021 Based on Azul Zulu Version: 11.47 (11.0.10.0.101+1) A CPU (Critical Patch Update) release incorporates critical bug fixes and security vulnerability fixes. Azul Zulu CPU releases are based on the prior PSU release and are available commercially. A PSU (Patch Set Updates) release is based on the current CPU release, i.e. it includes all bug fixes that have been fixed in the CPU release, and a number of non-security bug fixes. IANA time zone data version This release of Azul Zulu comes with IANA time zone data version 2021a. For more details, see https://data.iana.org/time-zones/tzdb-2021a/NEWS. -

1. Why POCS.Key
Symptoms of Complexity Prof. George Candea School of Computer & Communication Sciences Building Bridges A RTlClES A COMPUTER SCIENCE PERSPECTIVE OF BRIDGE DESIGN What kinds of lessonsdoes a classical engineering discipline like bridge design have for an emerging engineering discipline like computer systems Observation design?Case-study editors Alfred Spector and David Gifford consider the • insight and experienceof bridge designer Gerard Fox to find out how strong the parallels are. • bridges are normally on-time, on-budget, and don’t fall ALFRED SPECTORand DAVID GIFFORD • software projects rarely ship on-time, are often over- AS Gerry, let’s begin with an overview of THE DESIGN PROCESS bridges. AS What is the procedure for designing and con- GF In the United States, most highway bridges are budget, and rarely work exactly as specified structing a bridge? mandated by a government agency. The great major- GF It breaks down into three phases: the prelimi- ity are small bridges (with spans of less than 150 nay design phase, the main design phase, and the feet) and are part of the public highway system. construction phase. For larger bridges, several alter- There are fewer large bridges, having spans of 600 native designs are usually considered during the Blueprints for bridges must be approved... feet or more, that carry roads over bodies of water, preliminary design phase, whereas simple calcula- • gorges, or other large obstacles. There are also a tions or experience usually suffices in determining small number of superlarge bridges with spans ap- the appropriate design for small bridges. There are a proaching a mile, like the Verrazzano Narrows lot more factors to take into account with a large Bridge in New Yor:k. -

Status=Not/Inst/Cfg-Files/Unpacked
Desired=Unknown/Install/Remove/Purge/Hold |Status=Not/Inst/Cfgfiles/Unpacked/Failedcfg/Halfinst/trigaWait/Trigpend |/Err?=(none)/Reinstrequired(Status,Err:uppercase=bad) ||/NameVersion Description +++=========================================================================== =============================================================================== ================================================================================ ===== ii0trace1.0bt4 0traceisatraceroutetoolthatcanberunwithinanexisting,open TCPconnectionthereforebypassingsometypesofstatefulpacketfilterswith ease. ii3proxy0.6.1bt2 3APA3A3proxytinyproxyserver iiace1.10bt2 ACE(AutomatedCorporateEnumerator)isasimpleyetpowerfulVoIPCo rporateDirectoryenumerationtoolthatmimicsthebehaviorofanIPPhoneinor dert iiadduser3.112ubuntu1 addandremoveusersandgroups iiadmsnmp0.1bt3 SNMPauditscanner. iiafflib3.6.10bt1 AnopensourceimplementationofAFFwritteninC. iiair2.0.0bt2 AIRisaGUIfrontendtodd/dc3dddesignedforeasilycreatingforen sicimages. iiaircrackng1.1bt9 Aircrackngwirelessexploitationandenumerationsuite iialacarte0.13.10ubuntu1 easyGNOMEmenueditingtool iialsabase1.0.22.1+dfsg0ubuntu3 ALSAdriverconfigurationfiles iialsatools1.0.220ubuntu1 ConsolebasedALSAutilitiesforspecifichardware iialsautils1.0.220ubuntu5 ALSAutilities iiamap5.2bt4 Amapisanextgenerationtoolforassistingnetworkpenetrationtesti ng.Itperformsfastandreliableapplicationprotocoldetection,independanton the iiapache22.2.145ubuntu8.4 ApacheHTTPServermetapackage iiapache2mpmprefork2.2.145ubuntu8.4 ApacheHTTPServertraditionalnonthreadedmodel -
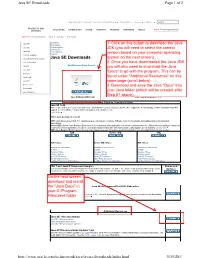
Java SE Downloads Page 1 of 2
Java SE Downloads Page 1 of 2 Sign In/Register for Account Help Select Country/Region Communities I am a... I want to... Search PRODUCTS AND SOLUTIONS DOWNLOADS STORE SUPPORT TRAINING PARTNERS ABOUT Oracle Technology Network SERVICES Oracle Technology Network Java Java SE Downloads Overview Java SE Downloads Java EE Documentation Community Java ME Technologies Training Java SE Support Java SE Advanced & Suite Java SE Downloads Java Embedded JavaFX Next Releases (Early Access) Embedded Use Previous Releases Java DB Web Tier Java Card Java TV New to Java Community Java Magazine Java Platform (JDK) 7u40 JDK 7u40 & NetBeans 7.3.1 Java Platform, Standard Edition Java SE 7u40 This release includes several new features like Java Mission Control, Deployment Rule Set, support for Retina display on Mac, and Hard Float ABI support on Linux ARM v7. It also includes bug fixes and enhancements. Learn more Which Java package do I need? JDK: (Java Development Kit). For Java Developers. Includes a complete JRE plus tools for developing, debugging, and monitoring Java applications. Server JRE: (Server Java Runtime Environment) For deploying Java applications on servers. Includes tools for JVM monitoring and tools commonly required for server applications, but does not include browser integration (the Java plug-in), auto-update, nor an installer. Learn more JRE: (Java Runtime Environment). Covers most end-users needs. Contains everything required to run Java applications on your system. JDK Server JRE JRE JDK 7 Docs Server JRE 7 Docs JRE 7 Docs Installation Instructions Installation Instructions Installation Instructions ReadMe ReadMe ReadMe Release Notes Release Notes Release Notes Oracle License Oracle License Oracle License Java SE Products Java SE Products Java SE Products Third Party Licenses Third Party Licenses Third Party Licenses Certified System Configurations Certified System Configurations Certified System Configurations JDK 7 and JavaFX Demos and Samples Demos and Demos and samples of common tasks and new functionality available on JDK 7. -

Developing Integration Projects with Oracle Data Integrator
Oracle® Fusion Middleware Developing Integration Projects with Oracle Data Integrator 12c (12.2.1.4.0) E95627-02 July 2021 Oracle Fusion Middleware Developing Integration Projects with Oracle Data Integrator, 12c (12.2.1.4.0) E95627-02 Copyright © 2010, 2021, Oracle and/or its affiliates. Primary Author: Oracle Corporation This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer -

Oracle Developer Suite 10G (9.0.4) Installation Guide for Windows and UNIX
Oracle® Developer Suite Installation Guide 10g (9.0.4) for Windows and UNIX Part No. B10579-01 November 2003 Oracle Developer Suite Installation Guide 10g (9.0.4) for Windows and UNIX Part No. B10579-01 Copyright © 2002, 2003 Oracle Corporation. All rights reserved. Primary Author: Joe Malin Contributing Author: Poh Lee Tan Contributors: Steven Anderson, Carolyn Bruse, Orlando Cordero, Craig DeNamur, Avrom Faderman, Kerstin Goldsmith, Jay Hauser, Kurt Heiss, Yuki Hirano, Christine Jacobs, Madhavi Jain, Derek Jones, Thomas Jose, Lypp-tek Khoo-Ellis, Shaun Lin, Robin Merrin, Mike Moon, Kathyrn Munn, Kavita Nayer, Andy Page, Santosh Poonen, Mercy Polson, Rajesh Ramachandran, Frank Rovitto, Theresa Robertson, Bill Ruppel, Yvette Salmon, Julia Stein, Jeremy Williams, Paul Wright The Programs (which include both the software and documentation) contain proprietary information of Oracle Corporation; they are provided under a license agreement containing restrictions on use and disclosure and are also protected by copyright, patent and other intellectual and industrial property laws. Reverse engineering, disassembly or decompilation of the Programs, except to the extent required to obtain interoperability with other independently created software or as specified by law, is prohibited. The information contained in this document is subject to change without notice. If you find any problems in the documentation, please report them to us in writing. Oracle Corporation does not warrant that this document is error-free. Except as may be expressly permitted in your license agreement for these Programs, no part of these Programs may be reproduced or transmitted in any form or by any means, electronic or mechanical, for any purpose, without the express written permission of Oracle Corporation. -
Oracle Fusion Middleware Installation Guide for Oracle Service Bus, 11G Release 1 (11.1.1.3) E15017-01
Oracle® Fusion Middleware Installation Guide for Oracle Service Bus 11g Release 1 (11.1.1.3) E15017-01 April 2010 Oracle Fusion Middleware Installation Guide for Oracle Service Bus, 11g Release 1 (11.1.1.3) E15017-01 Copyright © 2001, 2010, Oracle and/or its affiliates. All rights reserved. Primary Author: Gururaj B.S. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this software or related documentation is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms set forth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). -

Veritas Infoscale™ Third-Party Software License Agreements
Veritas InfoScale™ Third-Party Software License Agreements Windows 7.0 June 2015 Symantec Storage Foundation™ and High Availability Solutions Third-Party Software License Agreements The software described in this book is furnished under a license agreement and may be used only in accordance with the terms of the agreement. Product version: 7.0 Document version: 7.0 Rev 0 Legal Notice Copyright © 2015 Symantec Corporation. All rights reserved. Symantec, the Symantec Logo, the Checkmark Logo, Veritas, the Veritas Logo, CommandCentral, NetBackup, Enterprise Vault, and LiveUpdate are trademarks or registered trademarks of Symantec Corporation or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. This Symantec product may contain third party software for which Symantec is required to provide attribution to the third party (“Third Party Programs”). Some of the Third Party Programs are available under open source or free software licenses. The License Agreement accompanying the Software does not alter any rights or obligations you may have under those open source or free software licenses. See the Third-party Legal Notices document for this product, which is available online or included in the base release media. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Symantec Corporation and its licensors, if any. THE DOCUMENTATION IS PROVIDED "AS IS" AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID.