Methods for Presenting Statistical Information: the Box Plot
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
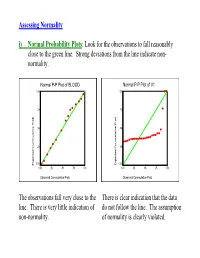
Assessing Normality I) Normal Probability Plots : Look for The
Assessing Normality i) Normal Probability Plots: Look for the observations to fall reasonably close to the green line. Strong deviations from the line indicate non- normality. Normal P-P Plot of BLOOD Normal P-P Plot of V1 1.00 1.00 .75 .75 .50 .50 .25 .25 0.00 0.00 Expected Cummulative Prob Expected Cummulative Expected Cummulative Prob Expected Cummulative 0.00 .25 .50 .75 1.00 0.00 .25 .50 .75 1.00 Observed Cummulative Prob Observed Cummulative Prob The observations fall very close to the There is clear indication that the data line. There is very little indication of do not follow the line. The assumption non-normality. of normality is clearly violated. ii) Histogram: Look for a “bell-shape”. Severe skewness and/or outliers are indications of non-normality. 5 16 14 4 12 10 3 8 2 6 4 1 Std. Dev = 60.29 Std. Dev = 992.11 2 Mean = 274.3 Mean = 573.1 0 N = 20.00 0 N = 25.00 150.0 200.0 250.0 300.0 350.0 0.0 1000.0 2000.0 3000.0 4000.0 175.0 225.0 275.0 325.0 375.0 500.0 1500.0 2500.0 3500.0 4500.0 BLOOD V1 Although the histogram is not perfectly There is a clear indication that the data symmetric and bell-shaped, there is no are right-skewed with some strong clear violation of normality. outliers. The assumption of normality is clearly violated. Caution: Histograms are not useful for small sample sizes as it is difficult to get a clear picture of the distribution. -

Summarize — Summary Statistics
Title stata.com summarize — Summary statistics Description Quick start Menu Syntax Options Remarks and examples Stored results Methods and formulas References Also see Description summarize calculates and displays a variety of univariate summary statistics. If no varlist is specified, summary statistics are calculated for all the variables in the dataset. Quick start Basic summary statistics for continuous variable v1 summarize v1 Same as above, and include v2 and v3 summarize v1-v3 Same as above, and provide additional detail about the distribution summarize v1-v3, detail Summary statistics reported separately for each level of catvar by catvar: summarize v1 With frequency weight wvar summarize v1 [fweight=wvar] Menu Statistics > Summaries, tables, and tests > Summary and descriptive statistics > Summary statistics 1 2 summarize — Summary statistics Syntax summarize varlist if in weight , options options Description Main detail display additional statistics meanonly suppress the display; calculate only the mean; programmer’s option format use variable’s display format separator(#) draw separator line after every # variables; default is separator(5) display options control spacing, line width, and base and empty cells varlist may contain factor variables; see [U] 11.4.3 Factor variables. varlist may contain time-series operators; see [U] 11.4.4 Time-series varlists. by, collect, rolling, and statsby are allowed; see [U] 11.1.10 Prefix commands. aweights, fweights, and iweights are allowed. However, iweights may not be used with the detail option; see [U] 11.1.6 weight. Options Main £ £detail produces additional statistics, including skewness, kurtosis, the four smallest and four largest values, and various percentiles. meanonly, which is allowed only when detail is not specified, suppresses the display of results and calculation of the variance. -

U3 Introduction to Summary Statistics
Presentation Name Course Name Unit # – Lesson #.# – Lesson Name Statistics • The collection, evaluation, and interpretation of data Introduction to Summary Statistics • Statistical analysis of measurements can help verify the quality of a design or process Summary Statistics Mean Central Tendency Central Tendency • The mean is the sum of the values of a set • “Center” of a distribution of data divided by the number of values in – Mean, median, mode that data set. Variation • Spread of values around the center – Range, standard deviation, interquartile range x μ = i Distribution N • Summary of the frequency of values – Frequency tables, histograms, normal distribution Project Lead The Way, Inc. Copyright 2010 1 Presentation Name Course Name Unit # – Lesson #.# – Lesson Name Mean Central Tendency Mean Central Tendency x • Data Set μ = i 3 7 12 17 21 21 23 27 32 36 44 N • Sum of the values = 243 • Number of values = 11 μ = mean value x 243 x = individual data value Mean = μ = i = = 22.09 i N 11 xi = summation of all data values N = # of data values in the data set A Note about Rounding in Statistics Mean – Rounding • General Rule: Don’t round until the final • Data Set answer 3 7 12 17 21 21 23 27 32 36 44 – If you are writing intermediate results you may • Sum of the values = 243 round values, but keep unrounded number in memory • Number of values = 11 • Mean – round to one more decimal place xi 243 Mean = μ = = = 22.09 than the original data N 11 • Standard Deviation: Round to one more decimal place than the original data • Reported: Mean = 22.1 Project Lead The Way, Inc. -

Descriptive Statistics
Descriptive Statistics Fall 2001 Professor Paul Glasserman B6014: Managerial Statistics 403 Uris Hall Histograms 1. A histogram is a graphical display of data showing the frequency of occurrence of particular values or ranges of values. In a histogram, the horizontal axis is divided into bins, representing possible data values or ranges. The vertical axis represents the number (or proportion) of observations falling in each bin. A bar is drawn in each bin to indicate the number (or proportion) of observations corresponding to that bin. You have probably seen histograms used, e.g., to illustrate the distribution of scores on an exam. 2. All histograms are bar graphs, but not all bar graphs are histograms. For example, we might display average starting salaries by functional area in a bar graph, but such a figure would not be a histogram. Why not? Because the Y-axis values do not represent relative frequencies or proportions, and the X-axis values do not represent value ranges (in particular, the order of the bins is irrelevant). Measures of Central Tendency 1. Let X1,...,Xn be data points, such as the result of n measurements or observations. What one number best characterizes or summarizes these values? The answer depends on the context. Some familiar summary statistics are these: • The mean is given by the arithemetic average X =(X1 + ···+ Xn)/n.(No- tation: We will often write n Xi for X1 + ···+ Xn. i=1 n The symbol i=1 Xi is read “the sum from i equals 1 upto n of Xi.”) 1 • The median is larger than one half of the observations and smaller than the other half. -

Measures of Dispersion for Multidimensional Data
European Journal of Operational Research 251 (2016) 930–937 Contents lists available at ScienceDirect European Journal of Operational Research journal homepage: www.elsevier.com/locate/ejor Computational Intelligence and Information Management Measures of dispersion for multidimensional data Adam Kołacz a, Przemysław Grzegorzewski a,b,∗ a Faculty of Mathematics and Computer Science, Warsaw University of Technology, Koszykowa 75, Warsaw 00–662, Poland b Systems Research Institute, Polish Academy of Sciences, Newelska 6, Warsaw 01–447, Poland article info abstract Article history: We propose an axiomatic definition of a dispersion measure that could be applied for any finite sample of Received 22 February 2015 k-dimensional real observations. Next we introduce a taxonomy of the dispersion measures based on the Accepted 4 January 2016 possible behavior of these measures with respect to new upcoming observations. This way we get two Available online 11 January 2016 classes of unstable and absorptive dispersion measures. We examine their properties and illustrate them Keywords: by examples. We also consider a relationship between multidimensional dispersion measures and mul- Descriptive statistics tidistances. Moreover, we examine new interesting properties of some well-known dispersion measures Dispersion for one-dimensional data like the interquartile range and a sample variance. Interquartile range © 2016 Elsevier B.V. All rights reserved. Multidistance Spread 1. Introduction are intended for use. It is also worth mentioning that several terms are used in the literature as regards dispersion measures like mea- Various summary statistics are always applied wherever deci- sures of variability, scatter, spread or scale. Some authors reserve sions are based on sample data. The main goal of those characteris- the notion of the dispersion measure only to those cases when tics is to deliver a synthetic information on basic features of a data variability is considered relative to a given fixed point (like a sam- set under study. -

Summary Statistics, Distributions of Sums and Means
Summary statistics, distributions of sums and means Joe Felsenstein Department of Genome Sciences and Department of Biology Summary statistics, distributions of sums and means – p.1/18 Quantiles In both empirical distributions and in the underlying distribution, it may help us to know the points where a given fraction of the distribution lies below (or above) that point. In particular: The 2.5% point The 5% point The 25% point (the first quartile) The 50% point (the median) The 75% point (the third quartile) The 95% point (or upper 5% point) The 97.5% point (or upper 2.5% point) Note that if a distribution has a small fraction of very big values far out in one tail (such as the distributions of wealth of individuals or families), the may not be a good “typical” value; the median will do much better. (For a symmetric distribution the median is the mean). Summary statistics, distributions of sums and means – p.2/18 The mean The mean is the average of points. If the distribution is the theoretical one, it is called the expectation, it’s the theoretical mean we would be expected to get if we drew infinitely many points from that distribution. For a sample of points x1, x2,..., x100 the mean is simply their average ¯x = (x1 + x2 + x3 + ... + x100) / 100 For a distribution with possible values 0, 1, 2, 3,... where value k has occurred a fraction fk of the time, the mean weights each of these by the fraction of times it has occurred (then in effect divides by the sum of these fractions, which however is actually 1): ¯x = 0 f0 + 1 f1 + 2 f2 + .. -

2. Graphing Distributions
2. Graphing Distributions A. Qualitative Variables B. Quantitative Variables 1. Stem and Leaf Displays 2. Histograms 3. Frequency Polygons 4. Box Plots 5. Bar Charts 6. Line Graphs 7. Dot Plots C. Exercises Graphing data is the first and often most important step in data analysis. In this day of computers, researchers all too often see only the results of complex computer analyses without ever taking a close look at the data themselves. This is all the more unfortunate because computers can create many types of graphs quickly and easily. This chapter covers some classic types of graphs such bar charts that were invented by William Playfair in the 18th century as well as graphs such as box plots invented by John Tukey in the 20th century. 65 by David M. Lane Prerequisites • Chapter 1: Variables Learning Objectives 1. Create a frequency table 2. Determine when pie charts are valuable and when they are not 3. Create and interpret bar charts 4. Identify common graphical mistakes When Apple Computer introduced the iMac computer in August 1998, the company wanted to learn whether the iMac was expanding Apple’s market share. Was the iMac just attracting previous Macintosh owners? Or was it purchased by newcomers to the computer market and by previous Windows users who were switching over? To find out, 500 iMac customers were interviewed. Each customer was categorized as a previous Macintosh owner, a previous Windows owner, or a new computer purchaser. This section examines graphical methods for displaying the results of the interviews. We’ll learn some general lessons about how to graph data that fall into a small number of categories. -

Chapter 16.Tst
Chapter 16 Statistical Quality Control- Prof. Dr. Samir Safi TRUE/FALSE. Write 'T' if the statement is true and 'F' if the statement is false. 1) Statistical process control uses regression and other forecasting tools to help control processes. 1) 2) It is impossible to develop a process that has zero variability. 2) 3) If all of the control points on a control chart lie between the UCL and the LCL, the process is always 3) in control. 4) An x-bar chart would be appropriate to monitor the number of defects in a production lot. 4) 5) The central limit theorem provides the statistical foundation for control charts. 5) 6) If we are tracking quality of performance for a class of students, we should plot the individual 6) grades on an x-bar chart, and the pass/fail result on a p-chart. 7) A p-chart could be used to monitor the average weight of cereal boxes. 7) 8) If we are attempting to control the diameter of bowling bowls, we will find a p-chart to be quite 8) helpful. 9) A c-chart would be appropriate to monitor the number of weld defects on the steel plates of a 9) ship's hull. MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question. 1) Which of the following is not a popular definition of quality? 1) A) Quality is fitness for use. B) Quality is the totality of features and characteristics of a product or service that bears on its ability to satisfy stated or implied needs. -

Section 2.2: Bar Charts and Pie Charts
Section 2.2: Bar Charts and Pie Charts 1 Raw Data is Ugly Graphical representations of data always look pretty in newspapers, magazines and books. What you haven’tseen is the blood, sweat and tears that it some- times takes to get those results. http://seatgeek.com/blog/mlb/5-useful-charts-for-baseball-fans-mlb-ticket-prices- by-day-time 1 Google listing for Ru San’sKennesaw location 2 The previous examples are informative graphical displays of data. They all started life as bland data sets. 2 Bar Charts Bar charts are a visual way to organize data. The height or length of a bar rep- resents the number of points of data (frequency distribution) in a particular category. One can also let the bar represent the percentage of data (relative frequency distribution) in a category. Example 1 From (http://vgsales.wikia.com/wiki/Halo) consider the sales …g- ures for Microsoft’s videogame franchise, Halo. Here is the raw data. Year Game Units Sold (in millions) 2001 Halo: Combat Evolved 5.5 2004 Halo 2 8 2007 Halo 3 12.06 2009 Halo Wars 2.54 2009 Halo 3: ODST 6.32 2010 Halo: Reach 9.76 2011 Halo: Combat Evolved Anniversary 2.37 2012 Halo 4 9.52 2014 Halo: The Master Chief Collection 2.61 2015 Halo 5 5 Let’s construct a bar chart based on units sold. Translating frequencies into relative frequencies is an easy process. A rela- tive frequency is the frequency divided by total number of data points. Example 2 Create a relative frequency chart for Halo games. -

Recent Outlier Detection Methods with Illustrations Loss Reserving Context
Recent outlier detection methods with illustrations in loss reserving Benjamin Avanzi, Mark Lavender, Greg Taylor, Bernard Wong School of Risk and Actuarial Studies, UNSW Sydney Insights, 18 September 2017 Recent outlier detection methods with illustrations loss reserving Context Context Reserving Robustness and Outliers Robust Statistical Techniques Robustness criteria Heuristic Tools Robust M-estimation Outlier Detection Techniques Robust Reserving Overview Illustration - Robust Bivariate Chain Ladder Robust N-Dimensional Chain-Ladder Summary and Conclusions References 1/46 Recent outlier detection methods with illustrations loss reserving Context Reserving Context Reserving Robustness and Outliers Robust Statistical Techniques Robustness criteria Heuristic Tools Robust M-estimation Outlier Detection Techniques Robust Reserving Overview Illustration - Robust Bivariate Chain Ladder Robust N-Dimensional Chain-Ladder Summary and Conclusions References 1/46 Recent outlier detection methods with illustrations loss reserving Context Reserving The Reserving Problem i/j 1 2 ··· j ··· I 1 X1;1 X1;2 ··· X1;j ··· X1;J 2 X2;1 X2;2 ··· X2;j ··· . i Xi;1 Xi;2 ··· Xi;j . I XI ;1 Figure: Aggregate claims run-off triangle I Complete the square (or rectangle) I Also - multivariate extensions. 1/46 Recent outlier detection methods with illustrations loss reserving Context Reserving Common Reserving Techniques I Deterministic Chain-Ladder I Stochastic Chain-Ladder (Hachmeister and Stanard, 1975; England and Verrall, 2002) I Mack’s Model (Mack, 1993) I GLMs -

Bar Charts and Box Plots Normal Poisson Exponential Creating a Simple Yet Effective Plot Requires an 02468 C 1.0 Exponential Uniform Understanding of Data and Tasks
THIS MONTH a Uniform POINTS OF VIEW Normal Poisson Exponential 02468 b Uniform Bar charts and box plots Normal Poisson Exponential Creating a simple yet effective plot requires an 02468 c 1.0 Exponential Uniform understanding of data and tasks. λ = 1 Min = 5.5 Normal Max = 6.5 0.5 Poisson σμ= 1, = 5 μ = 2 Bar charts and box plots are omnipresent in the scientific literature. 0 02468 They are typically used to visualize quantities associated with a set of Figure 2 | Representation of four distributions with bar charts and box plots. items. Representing the data accurately, however, requires choosing (a) Bar chart showing sample means (n = 1,000) with standard-deviation the appropriate plot according to the nature of the data and the task at error bars. (b) Box plot (n = 1,000) with whiskers extending to ±1.5 × IQR. hand. Bar charts are appropriate for counts, whereas box plots should (c) Probability density functions of the distributions in a and b. λ, rate; be used to represent the characteristics of a distribution. µ, mean; σ, standard deviation. Bar charts encode quantities by length, which is a highly accurate visual encoding and preferred over the angle-based strategy used in to represent such uncertainty. However, because the bars always start pie charts (Fig. 1a). Often the counts that we want to represent are at zero, they can be misleading: for example, part of the range covered sums over multiple categories. There are several options to visualize by the bar might have never been observed in the sample. -

Measurement & Transformations
Chapter 3 Measurement & Transformations 3.1 Measurement Scales: Traditional Classifica- tion Statisticians call an attribute on which observations differ a variable. The type of unit on which a variable is measured is called a scale.Traditionally,statisticians talk of four types of measurement scales: (1) nominal,(2)ordinal,(3)interval, and (4) ratio. 3.1.1 Nominal Scales The word nominal is derived from nomen,theLatinwordforname.Nominal scales merely name differences and are used most often for qualitative variables in which observations are classified into discrete groups. The key attribute for anominalscaleisthatthereisnoinherentquantitativedifferenceamongthe categories. Sex, religion, and race are three classic nominal scales used in the behavioral sciences. Taxonomic categories (rodent, primate, canine) are nomi- nal scales in biology. Variables on a nominal scale are often called categorical variables. For the neuroscientist, the best criterion for determining whether a variable is on a nominal scale is the “plotting” criteria. If you plot a bar chart of, say, means for the groups and order the groups in any way possible without making the graph “stupid,” then the variable is nominal or categorical. For example, were the variable strains of mice, then the order of the means is not material. Hence, “strain” is nominal or categorical. On the other hand, if the groups were 0 mgs, 10mgs, and 15 mgs of active drug, then having a bar chart with 15 mgs first, then 0 mgs, and finally 10 mgs is stupid. Here “milligrams of drug” is not anominalorcategoricalvariable. 1 CHAPTER 3. MEASUREMENT & TRANSFORMATIONS 2 3.1.2 Ordinal Scales Ordinal scales rank-order observations.