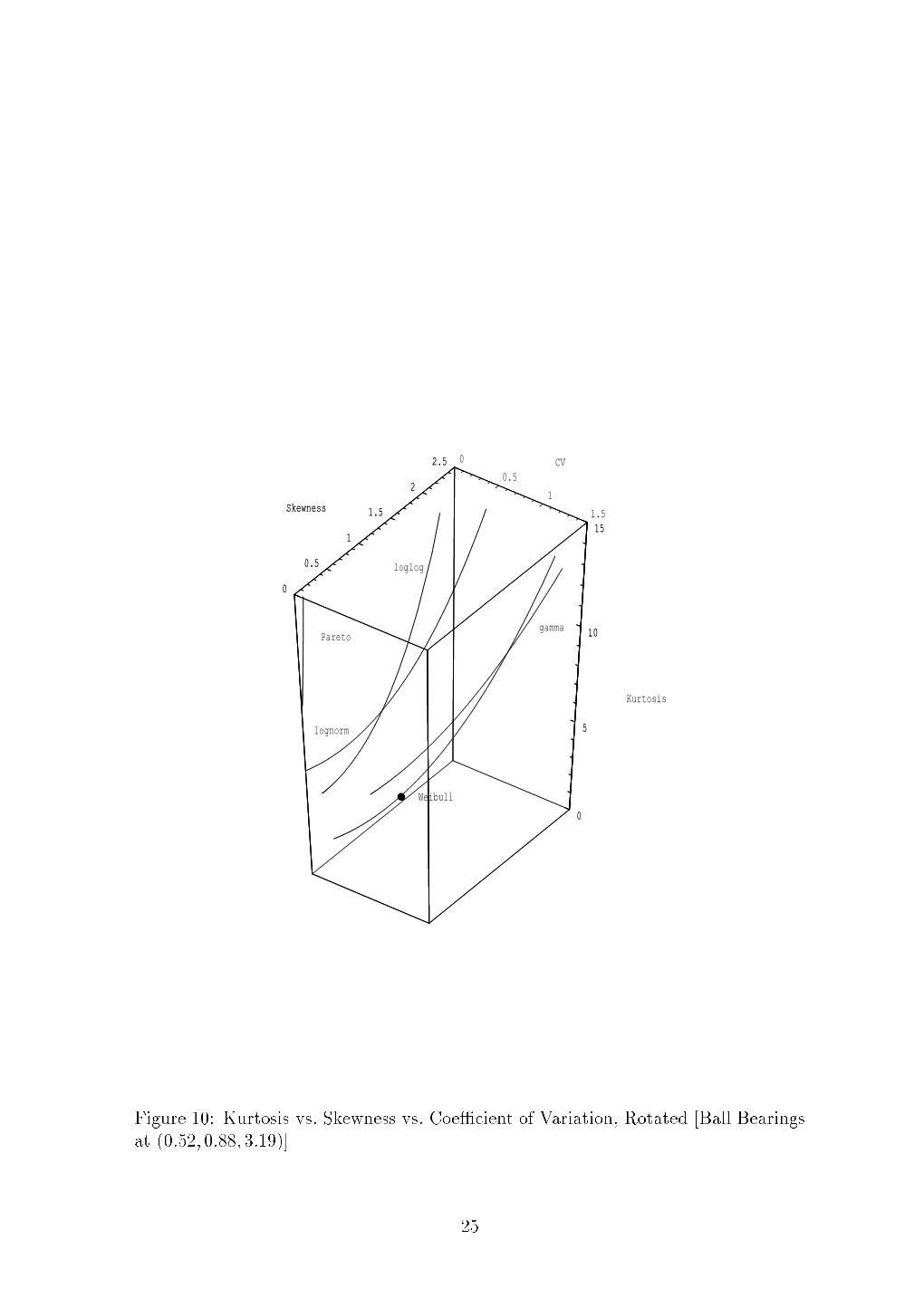
Kurtosis Vs. Skewness Vs. Coe Cient of Variation, Rotated Ball Bearings At
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Gompertz Distribution and Maximum Likelihood Estimation of Its Parameters - a Revision
Max-Planck-Institut für demografi sche Forschung Max Planck Institute for Demographic Research Konrad-Zuse-Strasse 1 · D-18057 Rostock · GERMANY Tel +49 (0) 3 81 20 81 - 0; Fax +49 (0) 3 81 20 81 - 202; http://www.demogr.mpg.de MPIDR WORKING PAPER WP 2012-008 FEBRUARY 2012 The Gompertz distribution and Maximum Likelihood Estimation of its parameters - a revision Adam Lenart ([email protected]) This working paper has been approved for release by: James W. Vaupel ([email protected]), Head of the Laboratory of Survival and Longevity and Head of the Laboratory of Evolutionary Biodemography. © Copyright is held by the authors. Working papers of the Max Planck Institute for Demographic Research receive only limited review. Views or opinions expressed in working papers are attributable to the authors and do not necessarily refl ect those of the Institute. The Gompertz distribution and Maximum Likelihood Estimation of its parameters - a revision Adam Lenart November 28, 2011 Abstract The Gompertz distribution is widely used to describe the distribution of adult deaths. Previous works concentrated on formulating approximate relationships to char- acterize it. However, using the generalized integro-exponential function Milgram (1985) exact formulas can be derived for its moment-generating function and central moments. Based on the exact central moments, higher accuracy approximations can be defined for them. In demographic or actuarial applications, maximum-likelihood estimation is often used to determine the parameters of the Gompertz distribution. By solving the maximum-likelihood estimates analytically, the dimension of the optimization problem can be reduced to one both in the case of discrete and continuous data. -

The Likelihood Principle
1 01/28/99 ãMarc Nerlove 1999 Chapter 1: The Likelihood Principle "What has now appeared is that the mathematical concept of probability is ... inadequate to express our mental confidence or diffidence in making ... inferences, and that the mathematical quantity which usually appears to be appropriate for measuring our order of preference among different possible populations does not in fact obey the laws of probability. To distinguish it from probability, I have used the term 'Likelihood' to designate this quantity; since both the words 'likelihood' and 'probability' are loosely used in common speech to cover both kinds of relationship." R. A. Fisher, Statistical Methods for Research Workers, 1925. "What we can find from a sample is the likelihood of any particular value of r [a parameter], if we define the likelihood as a quantity proportional to the probability that, from a particular population having that particular value of r, a sample having the observed value r [a statistic] should be obtained. So defined, probability and likelihood are quantities of an entirely different nature." R. A. Fisher, "On the 'Probable Error' of a Coefficient of Correlation Deduced from a Small Sample," Metron, 1:3-32, 1921. Introduction The likelihood principle as stated by Edwards (1972, p. 30) is that Within the framework of a statistical model, all the information which the data provide concerning the relative merits of two hypotheses is contained in the likelihood ratio of those hypotheses on the data. ...For a continuum of hypotheses, this principle -

A Family of Skew-Normal Distributions for Modeling Proportions and Rates with Zeros/Ones Excess
S S symmetry Article A Family of Skew-Normal Distributions for Modeling Proportions and Rates with Zeros/Ones Excess Guillermo Martínez-Flórez 1, Víctor Leiva 2,* , Emilio Gómez-Déniz 3 and Carolina Marchant 4 1 Departamento de Matemáticas y Estadística, Facultad de Ciencias Básicas, Universidad de Córdoba, Montería 14014, Colombia; [email protected] 2 Escuela de Ingeniería Industrial, Pontificia Universidad Católica de Valparaíso, 2362807 Valparaíso, Chile 3 Facultad de Economía, Empresa y Turismo, Universidad de Las Palmas de Gran Canaria and TIDES Institute, 35001 Canarias, Spain; [email protected] 4 Facultad de Ciencias Básicas, Universidad Católica del Maule, 3466706 Talca, Chile; [email protected] * Correspondence: [email protected] or [email protected] Received: 30 June 2020; Accepted: 19 August 2020; Published: 1 September 2020 Abstract: In this paper, we consider skew-normal distributions for constructing new a distribution which allows us to model proportions and rates with zero/one inflation as an alternative to the inflated beta distributions. The new distribution is a mixture between a Bernoulli distribution for explaining the zero/one excess and a censored skew-normal distribution for the continuous variable. The maximum likelihood method is used for parameter estimation. Observed and expected Fisher information matrices are derived to conduct likelihood-based inference in this new type skew-normal distribution. Given the flexibility of the new distributions, we are able to show, in real data scenarios, the good performance of our proposal. Keywords: beta distribution; centered skew-normal distribution; maximum-likelihood methods; Monte Carlo simulations; proportions; R software; rates; zero/one inflated data 1. -

11. Parameter Estimation
11. Parameter Estimation Chris Piech and Mehran Sahami May 2017 We have learned many different distributions for random variables and all of those distributions had parame- ters: the numbers that you provide as input when you define a random variable. So far when we were working with random variables, we either were explicitly told the values of the parameters, or, we could divine the values by understanding the process that was generating the random variables. What if we don’t know the values of the parameters and we can’t estimate them from our own expert knowl- edge? What if instead of knowing the random variables, we have a lot of examples of data generated with the same underlying distribution? In this chapter we are going to learn formal ways of estimating parameters from data. These ideas are critical for artificial intelligence. Almost all modern machine learning algorithms work like this: (1) specify a probabilistic model that has parameters. (2) Learn the value of those parameters from data. Parameters Before we dive into parameter estimation, first let’s revisit the concept of parameters. Given a model, the parameters are the numbers that yield the actual distribution. In the case of a Bernoulli random variable, the single parameter was the value p. In the case of a Uniform random variable, the parameters are the a and b values that define the min and max value. Here is a list of random variables and the corresponding parameters. From now on, we are going to use the notation q to be a vector of all the parameters: Distribution Parameters Bernoulli(p) q = p Poisson(l) q = l Uniform(a,b) q = (a;b) Normal(m;s 2) q = (m;s 2) Y = mX + b q = (m;b) In the real world often you don’t know the “true” parameters, but you get to observe data. -

Maximum Likelihood Estimation
Chris Piech Lecture #20 CS109 Nov 9th, 2018 Maximum Likelihood Estimation We have learned many different distributions for random variables and all of those distributions had parame- ters: the numbers that you provide as input when you define a random variable. So far when we were working with random variables, we either were explicitly told the values of the parameters, or, we could divine the values by understanding the process that was generating the random variables. What if we don’t know the values of the parameters and we can’t estimate them from our own expert knowl- edge? What if instead of knowing the random variables, we have a lot of examples of data generated with the same underlying distribution? In this chapter we are going to learn formal ways of estimating parameters from data. These ideas are critical for artificial intelligence. Almost all modern machine learning algorithms work like this: (1) specify a probabilistic model that has parameters. (2) Learn the value of those parameters from data. Parameters Before we dive into parameter estimation, first let’s revisit the concept of parameters. Given a model, the parameters are the numbers that yield the actual distribution. In the case of a Bernoulli random variable, the single parameter was the value p. In the case of a Uniform random variable, the parameters are the a and b values that define the min and max value. Here is a list of random variables and the corresponding parameters. From now on, we are going to use the notation q to be a vector of all the parameters: In the real Distribution Parameters Bernoulli(p) q = p Poisson(l) q = l Uniform(a,b) q = (a;b) Normal(m;s 2) q = (m;s 2) Y = mX + b q = (m;b) world often you don’t know the “true” parameters, but you get to observe data. -

Review of Maximum Likelihood Estimators
Libby MacKinnon CSE 527 notes Lecture 7, October 17, 2007 MLE and EM Review of Maximum Likelihood Estimators MLE is one of many approaches to parameter estimation. The likelihood of independent observations is expressed as a function of the unknown parameter. Then the value of the parameter that maximizes the likelihood of the observed data is solved for. This is typically done by taking the derivative of the likelihood function (or log of the likelihood function) with respect to the unknown parameter, setting that equal to zero, and solving for the parameter. Example 1 - Coin Flips Take n coin flips, x1, x2, . , xn. The number of heads and tails are, n0 and n1, respectively. θ is the probability of getting heads. That makes the probability of tails 1 − θ. This example shows how to estimate θ using data from the n coin flips and maximum likelihood estimation. Since each flip is independent, we can write the likelihood of the n coin flips as n0 n1 L(x1, x2, . , xn|θ) = (1 − θ) θ log L(x1, x2, . , xn|θ) = n0 log (1 − θ) + n1 log θ ∂ −n n log L(x , x , . , x |θ) = 0 + 1 ∂θ 1 2 n 1 − θ θ To find the max of the original likelihood function, we set the derivative equal to zero and solve for θ. We call this estimated parameter θˆ. −n n 0 = 0 + 1 1 − θ θ n0θ = n1 − n1θ (n0 + n1)θ = n1 n θ = 1 (n0 + n1) n θˆ = 1 n It is also important to check that this is not a minimum of the likelihood function and that the function maximum is not actually on the boundaries. -

THE EPIC STORY of MAXIMUM LIKELIHOOD 3 Error Probabilities Follow a Curve
Statistical Science 2007, Vol. 22, No. 4, 598–620 DOI: 10.1214/07-STS249 c Institute of Mathematical Statistics, 2007 The Epic Story of Maximum Likelihood Stephen M. Stigler Abstract. At a superficial level, the idea of maximum likelihood must be prehistoric: early hunters and gatherers may not have used the words “method of maximum likelihood” to describe their choice of where and how to hunt and gather, but it is hard to believe they would have been surprised if their method had been described in those terms. It seems a simple, even unassailable idea: Who would rise to argue in favor of a method of minimum likelihood, or even mediocre likelihood? And yet the mathematical history of the topic shows this “simple idea” is really anything but simple. Joseph Louis Lagrange, Daniel Bernoulli, Leonard Euler, Pierre Simon Laplace and Carl Friedrich Gauss are only some of those who explored the topic, not always in ways we would sanction today. In this article, that history is reviewed from back well before Fisher to the time of Lucien Le Cam’s dissertation. In the process Fisher’s unpublished 1930 characterization of conditions for the consistency and efficiency of maximum likelihood estimates is presented, and the mathematical basis of his three proofs discussed. In particular, Fisher’s derivation of the information inequality is seen to be derived from his work on the analysis of variance, and his later approach via estimating functions was derived from Euler’s Relation for homogeneous functions. The reaction to Fisher’s work is reviewed, and some lessons drawn. -

Maximum Likelihood Estimation ∗ Contents
Statistical Inference: Maximum Likelihood Estimation ∗ Konstantin Kashin Spring óþÕ¦ Contents Õ Overview: Maximum Likelihood vs. Bayesian Estimationó ó Introduction to Maximum Likelihood Estimation¢ ó.Õ What is Likelihood and the MLE?..............................................¢ ó.ó Examples of Analytical MLE Derivations..........................................ß ó.ó.Õ MLE Estimation for Sampling from Bernoulli Distribution..........................ß ó.ó.ó MLE Estimation of Mean and Variance for Sampling from Normal Distribution.............. ó.ó.ì Gamma Distribution................................................. ó.ó.¦ Multinomial Distribution..............................................É ó.ó.¢ Uniform Distribution................................................ Õþ ì Properties of MLE: e Basics ÕÕ ì.Õ Functional Invariance of MLE................................................ÕÕ ¦ Fisher Information and Uncertainty of MLE Õó ¦.þ.Õ Example of Calculating Fisher Information: Bernoulli Distribution...................... Õ¦ ¦.Õ e eory of Fisher Information.............................................. Õß ¦.Õ.Õ Derivation of Unit Fisher Information...................................... Õß ¦.Õ.ó Derivation of Sample Fisher Information..................................... ÕÉ ¦.Õ.ì Relationship between Expected and Observed Fisher Information...................... ÕÉ ¦.Õ.¦ Extension to Multiple Parameters......................................... óþ ¢ Proofs of Asymptotic Properties of MLE óÕ ¢.Õ Consistency of MLE..................................................... -

The Binomial Likelihood Function
The Binomial Likelihood Function The likelihood function for the binomial model is _(p± n, y) = n pC (1–p)8•C . y This function involves the parameter p, given the data (the ny and ). The discrete data and the statistic y (a count or summation) are known. The likelihood function is not a probability function; but it is a positive function and 0p 1. The left hand side is read “the likelihood of the parameter p, given ny and . Likelihood theory and the likelihood function are fundamental in the statistical sciences. Note the similarity between the probability function and the likelihood function; the right hand sides are the same. The difference between the two functions is the conditioning of the left hand sides. The probability function returns probabilities of the data, given the sample size and the parameters, while the likelihood function gives the relative likelihoods for different values of the parameter, given the sample size and the data. Some experience will allow an understanding of relative likelihood. Consider n flips of an unfair coin, whereby y are “HEADS." Let ny = 11 flips and = 7 heads. Thus, 4 are tails (by subtraction or observation). The conceptual motivation behind parameter estimation is to pick that value of the parameter that is “most likely", given the data. So, we can use the likelihood to evaluate some relative likelihoods for several values of p. We find that n = 330. Then, y p Likelihood 0.3 0.0173 0.5 0.1611 0.7 0.2201 0.8 0.1107. Given the data (n and yp), the value = 0.3 is relatively unlikely as the underlying parameter. -

1. Point Estimators, Review
AMS571 Prof. Wei Zhu 1. Point Estimators, Review Example 1. Let be a random sample from . Please find a good point estimator for Solutions. ̂ ̅ ̂ There are the typical estimators for and . Both are unbiased estimators. Property of Point Estimators Unbiased Estimators. ̂ is said to be an unbiased estimator for if ( ̂) . ̅ ( ) (*make sure you know how to derive this.) Unbiased estimator may not be unique. Example 2. ∑ ∑ ∑ ̃ ̃ ∑ Variance of the unbiased estimators – unbiased estimator with smaller variance is preferred (*why?) 1 ̅ } ̅ Methods for deriving point estimators 1. Maximum Likelihood Estimator (MLE) 2. Method Of Moment Estimator (MOME) Example 3. 1. Derive the MLE for . 2. Derive the MOME for . Solution. 1. MLE [i] [ ] √ [ii] likelihood function ∏ ∏ { [ ]} ∑ [ ] [iii] log likelihood function ∑ ( ) [iv] 2 ∑ ∑ { ̂ ̅ { ∑ ̅ ̂ 2. MOME Population Order Sample Moment Moment st 1 nd 2 th k Example 3 (continued): ̅ ∑ ̂ ̅ { ∑ ̂ ̅ ∑ ∑ ̅ ̅ ̂ ̅ ̅ ∑ ̅ ∑ ̅ ̅ ∑ ̅ ̅ ∑ ̅ 3 Therefore, the MLE and MOME for 2 are the same for the normal population. ̅ ̅ ∑ ∑ ( ̂) [ ] [ ] ⇒ (asymptotically unbiased) Example 4. Let . Please derive 1. The MLE of p 2. The MOME of p. Solution. 1. MLE [i] ∑ ∑ [ii] ∏ [iii] ∑ ∑ ∑ ∑ ∑ [iv] ̂ 2. MOME ∑ ̂ 4 Example 5. Let be a random sample from exp(λ) Please derive 1. The MLE of λ 2. The MOME of λ. Solution: 1. MLE: ∏ ∏ ∑ ∑ ∑ Thus ̂ ̅ 2. MOME: Thus setting: ̅ We have: ̂ ̅ 5 2. Order Statistics, Review. Let X1, X2, …, be a random sample from a population with p.d.f. -

The P-Value Function and Statistical Inference
The American Statistician ISSN: 0003-1305 (Print) 1537-2731 (Online) Journal homepage: https://www.tandfonline.com/loi/utas20 The p-value Function and Statistical Inference D. A. S. Fraser To cite this article: D. A. S. Fraser (2019) The p-value Function and Statistical Inference, The American Statistician, 73:sup1, 135-147, DOI: 10.1080/00031305.2018.1556735 To link to this article: https://doi.org/10.1080/00031305.2018.1556735 © 2019 The Author(s). Published by Informa UK Limited, trading as Taylor & Francis Group. Published online: 20 Mar 2019. Submit your article to this journal Article views: 1983 View Crossmark data Citing articles: 1 View citing articles Full Terms & Conditions of access and use can be found at https://www.tandfonline.com/action/journalInformation?journalCode=utas20 THE AMERICAN STATISTICIAN 2019, VOL. 73, NO. S1, 135–147: Statistical Inference in the 21st Century https://doi.org/10.1080/00031305.2019.1556735 The p-value Function and Statistical Inference D. A. S. Fraser Department of Statistical Sciences, University of Toronto, Toronto, Canada ABSTRACT ARTICLE HISTORY This article has two objectives. The first and narrower is to formalize the p-value function, which records Received March 2018 all possible p-values, each corresponding to a value for whatever the scalar parameter of interest is for the Revised November 2018 problem at hand, and to show how this p-value function directly provides full inference information for any corresponding user or scientist. The p-value function provides familiar inference objects: significance KEYWORDS Accept–Reject; Ancillarity; levels, confidence intervals, critical values for fixed-level tests, and the power function at all values ofthe Box–Cox; Conditioning; parameter of interest. -

Chapter 1 Introduction
Outline Chapter 1 Introduction • Variable types • Review of binomial and multinomial distributions • Likelihood and maximum likelihood method Yibi Huang • Inference for a binomial proportion (Wald, score and likelihood Department of Statistics ratio tests and confidence intervals) University of Chicago • Sample sample inference 1 Regression methods are used to analyze data when the response variable is numerical • e.g., temperature, blood pressure, heights, speeds, income • Stat 22200, Stat 22400 Methods in categorical data analysis are used when the response variable takes categorical (or qualitative) values Variable Types • e.g., • gender (male, female), • political philosophy (liberal, moderate, conservative), • region (metropolitan, urban, suburban, rural) • Stat 22600 In either case, the explanatory variables can be numerical or categorical. 2 Two Types of Categorical Variables Nominal : unordered categories, e.g., • transport to work (car, bus, bicycle, walk, other) • favorite music (rock, hiphop, pop, classical, jazz, country, folk) Review of Binomial and Ordinal : ordered categories Multinomial Distributions • patient condition (excellent, good, fair, poor) • government spending (too high, about right, too low) We pay special attention to — binary variables: success or failure for which nominal-ordinal distinction is unimportant. 3 Binomial Distributions (Review) Example If n Bernoulli trials are performed: Vote (Dem, Rep). Suppose π = Pr(Dem) = 0:4: • only two possible outcomes for each trial (success, failure) Sample n = 3 voters,