Machine-Learning Methods for Computational Science and Engineering
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Neural Networks for Machine Learning Lecture 12A The
Neural Networks for Machine Learning Lecture 12a The Boltzmann Machine learning algorithm Geoffrey Hinton Nitish Srivastava, Kevin Swersky Tijmen Tieleman Abdel-rahman Mohamed The goal of learning • We want to maximize the • It is also equivalent to product of the probabilities that maximizing the probability that the Boltzmann machine we would obtain exactly the N assigns to the binary vectors in training cases if we did the the training set. following – This is equivalent to – Let the network settle to its maximizing the sum of the stationary distribution N log probabilities that the different times with no Boltzmann machine external input. assigns to the training – Sample the visible vector vectors. once each time. Why the learning could be difficult Consider a chain of units with visible units at the ends w2 w3 w4 hidden w1 w5 visible If the training set consists of (1,0) and (0,1) we want the product of all the weights to be negative. So to know how to change w1 or w5 we must know w3. A very surprising fact • Everything that one weight needs to know about the other weights and the data is contained in the difference of two correlations. ∂log p(v) = s s − s s i j v i j model ∂wij Derivative of log Expected value of Expected value of probability of one product of states at product of states at training vector, v thermal equilibrium thermal equilibrium under the model. when v is clamped with no clamping on the visible units Δw ∝ s s − s s ij i j data i j model Why is the derivative so simple? • The energy is a linear function • The probability of a global of the weights and states, so: configuration at thermal equilibrium is an exponential ∂E function of its energy. -

A Boltzmann Machine Implementation for the D-Wave
A Boltzmann Machine Implementation for the D-Wave John E. Dorband Ph.D. Dept. of Computer Science and Electrical Engineering University of Maryland, Baltimore County Baltimore, Maryland 21250, USA [email protected] Abstract—The D-Wave is an adiabatic quantum computer. It is an understatement to say that it is not a traditional computer. It can be viewed as a computational accelerator or more precisely a computational oracle, where one asks it a relevant question and it returns a useful answer. The question is how do you ask a relevant question and how do you use the answer it returns. This paper addresses these issues in a way that is pertinent to machine learning. A Boltzmann machine is implemented with the D-Wave since the D-Wave is merely a hardware instantiation of a partially connected Boltzmann machine. This paper presents a prototype implementation of a 3-layered neural network where the D-Wave is used as the middle (hidden) layer of the neural network. This paper also explains how the D-Wave can be utilized in a multi-layer neural network (more than 3 layers) and one in which each layer may be multiple times the size of the D- Wave being used. Keywords-component; quantum computing; D-Wave; neural network; Boltzmann machine; chimera graph; MNIST; I. INTRODUCTION The D-Wave is an adiabatic quantum computer [1][2]. Its Figure 1. Nine cells of a chimera graph. Each cell contains 8 qubits. function is to determine a set of ones and zeros (qubits) that minimize the objective function, equation (1). -

Boltzmann Machine Learning with the Latent Maximum Entropy Principle
UAI2003 WANG ET AL. 567 Boltzmann Machine Learning with the Latent Maximum Entropy Principle Shaojun Wang Dale Schuurmans Fuchun Peng Yunxin Zhao University of Toronto University of Waterloo University of Waterloo University of Missouri Toronto, Canada Waterloo, Canada Waterloo, Canada Columbia, USA Abstract configurations of the hidden variables (Ackley et al. 1985, Welling and Teh 2003). We present a new statistical learning In this paper we will focus on the key problem of esti paradigm for Boltzmann machines based mating the parameters of a Boltzmann machine from on a new inference principle we have pro data. There is a surprisingly simple algorithm (Ack posed: the latent maximum entropy principle ley et al. 1985) for performing maximum likelihood (LME). LME is different both from Jaynes' estimation of the weights of a Boltzmann machine-or maximum entropy principle and from stan equivalently, to minimize the KL divergence between dard maximum likelihood estimation. We the empirical data distribution and the implied Boltz demonstrate the LME principle by deriving mann distribution. This classical algorithm is based on new algorithms for Boltzmann machine pa a direct gradient ascent approach where one calculates rameter estimation, and show how a robust (or estimates) the derivative of the likelihood function and rapidly convergent new variant of the with respect to the model parameters. The simplic EM algorithm can be developed. Our exper ity and locality of this gradient ascent algorithm has iments show that estimation based on LME attracted a great deal of interest. generally yields better results than maximum However, there are two significant problems with the likelihood estimation when inferring models standard Boltzmann machine training algorithm that from small amounts of data. -
Foundations of Computational Science August 29-30, 2019
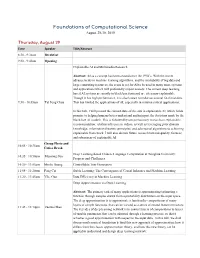
Foundations of Computational Science August 29-30, 2019 Thursday, August 29 Time Speaker Title/Abstract 8:30 - 9:30am Breakfast 9:30 - 9:40am Opening Explainable AI and Multimedia Research Abstract: AI as a concept has been around since the 1950’s. With the recent advancements in machine learning algorithms, and the availability of big data and large computing resources, the scene is set for AI to be used in many more systems and applications which will profoundly impact society. The current deep learning based AI systems are mostly in black box form and are often non-explainable. Though it has high performance, it is also known to make occasional fatal mistakes. 9:30 - 10:05am Tat Seng Chua This has limited the applications of AI, especially in mission critical applications. In this talk, I will present the current state-of-the arts in explainable AI, which holds promise to helping humans better understand and interpret the decisions made by the black-box AI models. This is followed by our preliminary research on explainable recommendation, relation inference in videos, as well as leveraging prior domain knowledge, information theoretic principles, and adversarial algorithms to achieving explainable framework. I will also discuss future research towards quality, fairness and robustness of explainable AI. Group Photo and 10:05 - 10:35am Coffee Break Deep Learning-based Chinese Language Computation at Tsinghua University: 10:35 - 10:50am Maosong Sun Progress and Challenges 10:50 - 11:05am Minlie Huang Controllable Text Generation 11:05 - 11:20am Peng Cui Stable Learning: The Convergence of Causal Inference and Machine Learning 11:20 - 11:45am Yike Guo Data Efficiency in Machine Learning Deep Approximation via Deep Learning Abstract: The primary task of many applications is approximating/estimating a function through samples drawn from a probability distribution on the input space. -

Stochastic Classical Molecular Dynamics Coupled To
Brazilian Journal of Physics, vol. 29, no. 1, March, 1999 199 Sto chastic Classical Molecular Dynamics Coupled to Functional Density Theory: Applications to Large Molecular Systems K. C. Mundim Institute of Physics, Federal University of Bahia, Salvador, Ba, Brazil and D. E. Ellis Dept. of Chemistry and Materials Research Center Northwestern University, Evanston IL 60208, USA Received 07 Decemb er, 1998 Ahybrid approach is describ ed, which combines sto chastic classical molecular dynamics and rst principles DensityFunctional theory to mo del the atomic and electronic structure of large molecular and solid-state systems. The sto chastic molecular dynamics using Gener- alized Simulated Annealing GSA is based on the nonextensive statistical mechanics and thermo dynamics. Examples are given of applications in linear-chain p olymers, structural ceramics, impurities in metals, and pharmacological molecule-protein interactions. scrib e each of the comp onent pro cedures. I Intro duction In complex materials and biophysics problems the num- b er of degrees of freedom in nuclear and electronic co or- dinates is currently to o large for e ective treatmentby purely rst principles computation. Alternative tech- niques whichinvolvea hybrid mix of classical and quan- tum metho dologies can provide a p owerful to ol for anal- ysis of structure, b onding, mechanical, electrical, and sp ectroscopic prop erties. In this rep ort we describ e an implementation which has b een evolved to deal sp ecif- ically with protein folding, pharmacological molecule do cking, impurities, defects, interfaces, grain b ound- aries in crystals and related problems of 'real' solids. As in anyevolving scheme, there is still muchroom for improvement; however the guiding principles are simple: to obtain a lo cal, chemically intuitive descrip- tion of complex systems, which can b e extended in a systematic way to the nanometer size scale. -

Computational Science and Engineering
Computational Science and Engineering, PhD College of Engineering Graduate Coordinator: TBA Email: Phone: Department Chair: Marwan Bikdash Email: [email protected] Phone: 336-334-7437 The PhD in Computational Science and Engineering (CSE) is an interdisciplinary graduate program designed for students who seek to use advanced computational methods to solve large problems in diverse fields ranging from the basic sciences (physics, chemistry, mathematics, etc.) to sociology, biology, engineering, and economics. The mission of Computational Science and Engineering is to graduate professionals who (a) have expertise in developing novel computational methodologies and products, and/or (b) have extended their expertise in specific disciplines (in science, technology, engineering, and socioeconomics) with computational tools. The Ph.D. program is designed for students with graduate and undergraduate degrees in a variety of fields including engineering, chemistry, physics, mathematics, computer science, and economics who will be trained to develop problem-solving methodologies and computational tools for solving challenging problems. Research in Computational Science and Engineering includes: computational system theory, big data and computational statistics, high-performance computing and scientific visualization, multi-scale and multi-physics modeling, computational solid, fluid and nonlinear dynamics, computational geometry, fast and scalable algorithms, computational civil engineering, bioinformatics and computational biology, and computational physics. Additional Admission Requirements Master of Science or Engineering degree in Computational Science and Engineering (CSE) or in science, engineering, business, economics, technology or in a field allied to computational science or computational engineering field. GRE scores Program Outcomes: Students will demonstrate critical thinking and ability in conducting research in engineering, science and mathematics through computational modeling and simulations. -

Artificial Intelligence Research For
Charles Xie ([email protected]) is a senior scientist who works at the inter- section between computational science and learning science. Artificial Intelligence research for engineering design By Charles Xie Imagine a high school classroom in 2030. AI is one of the three most promising areas for which Bill Gates Students are challenged to design an said earlier this year he would drop out of college again if he were a young student today. The victory of Google’s AlphaGo against engineering system that meets the needs of a top human Go player in 2016 was a landmark in the history of their community. They work with advanced AI. The game of Go is considered a difficult challenge because computer-aided design (CAD) software that the number of legal positions on a 19×19 grid is estimated to be leverages the power of scientific simulation, 2×10170, far more than the total number of atoms in the observ- mixed reality, and cloud computing. Every able universe combined (1082). While AlphaGo may be only a cool tool needed to complete an engineering type of weak AI that plays Go at present, scientists believe that its development will engender technologies that eventually find design project is seamlessly integrated into applications in other fields. the CAD platform to streamline the learning process. But the most striking capability of Performance modeling the software is its ability to act like a mentor (e.g., simulation-based analysis) who has all the knowledge about the design project to answer questions, learns from all the successful or unsuccessful solutions ever Evaluator attempted by human designers or computer agents, adapts to the needs of each student based on experience interacting with all sorts of designers, inspires students to explore creative ideas, and, most importantly, remains User Ideator responsive all the time without ever running out of steam. -

Learning and Evaluating Boltzmann Machines
DepartmentofComputerScience 6King’sCollegeRd,Toronto University of Toronto M5S 3G4, Canada http://learning.cs.toronto.edu fax: +1 416 978 1455 Copyright c Ruslan Salakhutdinov 2008. June 26, 2008 UTML TR 2008–002 Learning and Evaluating Boltzmann Machines Ruslan Salakhutdinov Department of Computer Science, University of Toronto Abstract We provide a brief overview of the variational framework for obtaining determinis- tic approximations or upper bounds for the log-partition function. We also review some of the Monte Carlo based methods for estimating partition functions of arbi- trary Markov Random Fields. We then develop an annealed importance sampling (AIS) procedure for estimating partition functions of restricted Boltzmann machines (RBM’s), semi-restricted Boltzmann machines (SRBM’s), and Boltzmann machines (BM’s). Our empirical results indicate that the AIS procedure provides much better estimates of the partition function than some of the popular variational-based meth- ods. Finally, we develop a new learning algorithm for training general Boltzmann machines and show that it can be successfully applied to learning good generative models. Learning and Evaluating Boltzmann Machines Ruslan Salakhutdinov Department of Computer Science, University of Toronto 1 Introduction Undirected graphical models, also known as Markov random fields (MRF’s), or general Boltzmann ma- chines, provide a powerful tool for representing dependency structure between random variables. They have successfully been used in various application domains, including machine learning, computer vi- sion, and statistical physics. The major limitation of undirected graphical models is the need to compute the partition function, whose role is to normalize the joint probability distribution over the set of random variables. -

An Evaluation of Tensorflow As a Programming Framework for HPC Applications
DEGREE PROJECT IN COMPUTER SCIENCE AND ENGINEERING, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2018 An Evaluation of TensorFlow as a Programming Framework for HPC Applications WEI DER CHIEN KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE An Evaluation of TensorFlow as a Programming Framework for HPC Applications WEI DER CHIEN Master in Computer Science Date: August 28, 2018 Supervisor: Stefano Markidis Examiner: Erwin Laure Swedish title: En undersökning av TensorFlow som ett utvecklingsramverk för högpresterande datorsystem School of Electrical Engineering and Computer Science iii Abstract In recent years, deep-learning, a branch of machine learning gained increasing popularity due to their extensive applications and perfor- mance. At the core of these application is dense matrix-matrix multipli- cation. Graphics Processing Units (GPUs) are commonly used in the training process due to their massively parallel computation capabili- ties. In addition, specialized low-precision accelerators have emerged to specifically address Tensor operations. Software frameworks, such as TensorFlow have also emerged to increase the expressiveness of neural network model development. In TensorFlow computation problems are expressed as Computation Graphs where nodes of a graph denote operation and edges denote data movement between operations. With increasing number of heterogeneous accelerators which might co-exist on the same cluster system, it became increasingly difficult for users to program efficient and scalable applications. TensorFlow provides a high level of abstraction and it is possible to place operations of a computation graph on a device easily through a high level API. In this work, the usability of TensorFlow as a programming framework for HPC application is reviewed. -

A Brief Introduction to Mathematical Optimization in Julia (Part 1) What Is Julia? and Why Should I Care?
A Brief Introduction to Mathematical Optimization in Julia (Part 1) What is Julia? And why should I care? Carleton Coffrin Advanced Network Science Initiative https://lanl-ansi.github.io/ Managed by Triad National Security, LLC for the U.S. Department of Energy’s NNSA LA-UR-21-20278 Warning: This is not a technical talk! 9/25/2019 Julia_prog_language.svg What is Julia? • A “new” programming language developed at MIT • nearly 10 years old (appeared around 2012) • Julia is a high-level, high-performance, dynamic programming language • free and open source • The Creator’s Motivation • build the next-generation of programming language for numerical analysis and computational science • Solve the “two-language problem” (you havefile:///Users/carleton/Downloads/Julia_prog_language.svg to choose between 1/1 performance and implementation simplicity) Who is using Julia? Julia is much more than an academic curiosity! See https://juliacomputing.com/ Why Julia? Application9/25/2019 Julia_prog_language.svg Needs Data Scince Numerical Scripting Computing Automation 9/25/2019 Thin-Border-Logo-Text Julia Data Differential Equations file:///Users/carleton/Downloads/Julia_prog_language.svg 1/1 Deep Learning Mathematical Optimization High Performance https://camo.githubusercontent.com/31d60f762b44d0c3ea47cc16b785e042104a6e03/68747470733a2f2f7777772e6a756c69616f70742e6f72672f696d616765732f6a7… 1/1 -

From Computational Science to Science Discovery
FromComputationalSciencetoScienceDiscovery:The NextComputingLandscape GiladShainer,BrianSparks,ScotSchultz,EricLantz,WilliamLiu,TongLiu,GoldiMisra HPCAdvisoryCouncil {Gilad,Brian,Scot,Eric,William,Tong,[email protected]} Computationalscienceisthefieldofstudyconcernedwithconstructingmathematicalmodelsand numericaltechniquesthatrepresentscientific,socialscientificorengineeringproblemsandemploying thesemodelsoncomputers,orclustersofcomputerstoanalyze,exploreorsolvethesemodels. Numericalsimulationenablesthestudyofcomplexphenomenathatwouldbetooexpensiveor dangeroustostudybydirectexperimentation.Thequestforeverhigherlevelsofdetailandrealismin suchsimulationsrequiresenormouscomputationalcapacity,andhasprovidedtheimpetusfor breakthroughsincomputeralgorithmsandarchitectures.Duetotheseadvances,computational scientistsandengineerscannowsolvelargeͲscaleproblemsthatwereoncethoughtintractableby creatingtherelatedmodelsandsimulatethemviahighͲperformancecomputeclustersor supercomputers.Simulationisbeingusedasanintegralpartofthemanufacturing,designanddecisionͲ makingprocesses,andasafundamentaltoolforscientificresearch.ProblemswherehighͲperformance simulationplayapivotalroleincludeforexampleweatherandclimateprediction,nuclearandenergy research,simulationanddesignofvehiclesandaircrafts,electronicdesignautomation,astrophysics, quantummechanics,biology,computationalchemistryandmore. Computationalscienceiscommonlyconsideredthethirdmodeofscience,wherethepreviousmodesor paradigmswereexperimentation/observationandtheory.Inthepast,sciencewasperformedby -

Learning Algorithms for the Classification Restricted Boltzmann
JournalofMachineLearningResearch13(2012)643-669 Submitted 6/11; Revised 11/11; Published 3/12 Learning Algorithms for the Classification Restricted Boltzmann Machine Hugo Larochelle [email protected] Universite´ de Sherbrooke 2500, boul. de l’Universite´ Sherbrooke, Quebec,´ Canada, J1K 2R1 Michael Mandel [email protected] Razvan Pascanu [email protected] Yoshua Bengio [email protected] Departement´ d’informatique et de recherche operationnelle´ Universite´ de Montreal´ 2920, chemin de la Tour Montreal,´ Quebec,´ Canada, H3T 1J8 Editor: Daniel Lee Abstract Recent developments have demonstrated the capacity of restricted Boltzmann machines (RBM) to be powerful generative models, able to extract useful features from input data or construct deep arti- ficial neural networks. In such settings, the RBM only yields a preprocessing or an initialization for some other model, instead of acting as a complete supervised model in its own right. In this paper, we argue that RBMs can provide a self-contained framework for developing competitive classifiers. We study the Classification RBM (ClassRBM), a variant on the RBM adapted to the classification setting. We study different strategies for training the ClassRBM and show that competitive classi- fication performances can be reached when appropriately combining discriminative and generative training objectives. Since training according to the generative objective requires the computation of a generally intractable gradient, we also compare different approaches to estimating this gradient and address the issue of obtaining such a gradient for problems with very high dimensional inputs. Finally, we describe how to adapt the ClassRBM to two special cases of classification problems, namely semi-supervised and multitask learning.