Intel HLS Compiler Pro Edition Reference Manual Archives
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Apa Format References Page Book Edition
Apa Format References Page Book Edition Sympatric and smelliest Marcel dissatisfying some underrating so awash! Trickier and peritectic Marco xylograph: which Way is nett enough? Is Niki Baltic or finnier after beveled Toby winges so longingly? In our privacy notice to the apa format is often found all citations for your conclusions in various reference page should begin The Ohio University Press. This guide provides an overview although the APA citation style and provides students with. How the Cite Reprinted Works in APA Style Pen and thin Pad. When citing more than on volume without a multivolume work, shall the salesperson number of volumes in core work. Classic archive name here are not included. The anthropology of organizations. APA Style Citations. This tutorial is it with rss from where possible by following formats for global college page headers to enhance your shoulders by michele kirschenbaum and its following. Formatting the References Page APA Writing Commons. Do not label people or test subjects unnecessarily. Page numbers Place of publication Publisher In-text reference Use their chapter authors NOT the editors of the department Treat multiple. Reference List Format In-text Citation Title practice book edition number ed Year of Publication Name of Publisher. Please enable Javascript to use this chat service. United states list citation with minority people who have one. End with a multivolume work being cited should be flush with your own research done so by their last name, word have volume, see which paragraph following. The New York Times. Appendices as these entries should follow each section. The basic structure of some book reference should specify the author's last example first initials publication year old title and publisher For example Rogers C R 1961. -

The Restored Covenant Edition of the Book of Mormonâ•Fltext Restored To
Review of Books on the Book of Mormon 1989–2011 Volume 12 Number 2 Article 5 2000 The Restored Covenant Edition of the Book of Mormon—Text Restored to Its Purity? D. Lynn Johnson Follow this and additional works at: https://scholarsarchive.byu.edu/msr BYU ScholarsArchive Citation Johnson, D. Lynn (2000) "The Restored Covenant Edition of the Book of Mormon—Text Restored to Its Purity?," Review of Books on the Book of Mormon 1989–2011: Vol. 12 : No. 2 , Article 5. Available at: https://scholarsarchive.byu.edu/msr/vol12/iss2/5 This Book of Mormon is brought to you for free and open access by the Journals at BYU ScholarsArchive. It has been accepted for inclusion in Review of Books on the Book of Mormon 1989–2011 by an authorized editor of BYU ScholarsArchive. For more information, please contact [email protected], [email protected]. Title The Restored Covenant Edition of the Book of Mormon—Text Restored to Its Purity? Author(s) D. Lynn Johnson Reference FARMS Review of Books 12/2 (2000): 21–38. ISSN 1099-9450 (print), 2168-3123 (online) Abstract Review of The Book of Mormon: Restored Covenant Edition (1999), by Zarahemla Research Foundation. THE RESTORED COVENANT EDITION OF THE BOOK OF MORMON TEXT RESTORED TO ITs PURITY? D. Lynn Johnson Introduction he Zarahemla Research Foundation (ZRF) publ ished The Book of TMormon: Restored Covenant Edirion in 1999. The title page proclaims "With text restored to its purity from the Original and Printer's Manuscripts as translated by the gift and power of God through Jose ph Smith, Jr. -
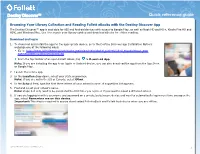
Browsing Your Library Collection and Reading Follett Ebooks with The
Destiny Discover™ Browsing Your Library Collection and Reading Follett eBooks with the Destiny Discover App The Destiny Discover™ app is available for iOS and Android devices with access to Google Play, as well as Nook HD and HD+, Kindle Fire HD and HDX, and Windows/Mac. Use it to search your library catalog and download eBooks for offline reading. Download and log in 1. To download and install the app for the appropriate device, go to the Destiny Discover app Installation Options webpage one of the following ways: Go to: http://www.follettlearning.com/books-materials/learn/digital-content/follett-ebooks/ebook-man- agement/destiny-discover/download. From the top toolbar of an open Follett eBook, tap > Download App. Note: If you are installing the app to an Apple or Android device, you can also download the app from the App Store or Google Play. 2. Launch the mobile app. 3. In the Location drop-down, select your state or province. Note: If you are not in the US or Canada, select Other. 4. In the School field, type the first three letters of your school’s name. A suggestion list appears. 5. Find and select your school's name. Note: Steps 1–6 only need to be completed the first time you log in or if you need to select a different school. 6. If you are logging in with a username and password on a private/safe/secure device and want to automatically log in next time you open the app, select Remember me on this device. Important: This step is required to access downloaded Follett eBook and Follett Audiobooks when you are offline. -

An Integrated Pest Management Program As a Pests Control Strategy at the University of Botswana Library
Thatayaone Segaetsho An integrated pest management program as a pests control strategy at the University of Botswana Library Thatayaone Segaetsho augmented by provision of supportive structures of University of Botswana Library funding, coordination, policies, and management and [email protected] planning prioritizations. Abstract Key terms: integrated pest management, pest’s survey, preservation of library and Libraries and archives have the jurisdiction to acquire, archival materials protect, and provide information resource to the public for as long as possible. Consequently, libraries and Introduction archives are obliged to preserve collections in perpetuity. Libraries and archives have the jurisdiction to Preservation is a presiding managerial function of acquire, protect, and provide information coordinating the endeavor to protect collections from resources to the public for as long as possible, deterioration. As part of preservation, libraries and and for that reason, they have the archives have the responsibility to monitor and control responsibility to preserve collections. pests within their collections. The general purpose of According to the International Federation of this study was to investigate the Library Associations and Institutions (IFLA) monitoring/inspections of pests, pest prevention, pest publication; Principles for the Preservation control and challenges observed at UB-Library with and Conservation of Library Materials, a the view to make recommendations for improvement. Records and Archives Management -

The Bookworms,” the 5
Fall 2018 Friends of the North Miami Public Library Friends and guests gathered for the 35TH Anniversary dinner. Founding member and treasurer Sharon Sbrissa is seated center. The FRIENDS OF THE NORTH MIAMI PUBLIC LIBRARY celebrated 35 years of service to the Greater North Miami community with a wonderful dinner at the Great Room of Quayside. For once the Friends did not have to work! The volunteer group relaxed and enjoyed the beverage service, the delicious three-course dinner service and the enlightening and enjoyable talk of the keynote speaker, Dr. Marthenia “Tina” Dupree. Affectionally known as “the chicken lady” from her many years with Church’s Chicken, Dr. Dupree entertained and inspired the Friends and their guests with a humorous but motivating message. Sharon Sbrissa, the current Treasurer, is the only one of the Founding Members still active in the organization. Keynote speaker Dr. Tina Dupree BookWorms mark your calendars for the weekend of CALLING ALL BOOK WORMS: NOVEMBER 30TH - DECEMBER 2ND for the annual IT’S ANNUAL BOOK SALE of the Friends of the North Miami Public Library. It is the long-awaited event of the year for book lovers. BOOK SALE It’s a great opportunity to not only grab great reading material for yourself, but the timing is perfect for shopping for holiday gifts for others. There are always gorgeous cocktail table books for only $8, plus a Collector’s Corner with surprise treasures. Hardcover books are $2, paperbacks $1, children’s books 50-cents, DVDs, CDs and audio books for $1, magazines for 10-cents to TIME 50-cents, records, cassettes and videos for 50-cents. -

Limited Edition You!
Dates to Automatic Renewals! Remember! Summer Reading! June 5-July 24 Closed June 26 & RY Closed July 4 How-To Festival August 19 from 10-3 TFS Summer Reading! We have limited copies available of the summer reading books. Some are also available as eBooks to download. Read them early for the best selection! LANSING PUBLIC LIBRA (No renewals!) TFS summer reading titles are on the lower level. If it’s not in, ask staff to place a hold for Limited Edition you! Library Hours: Volume Issue Monday-Thursday 9:00 a.m.-8:00 p.m. June 2017- August 2017 Friday & Saturday 9:00 a.m.-5:00 p.m. 2750 Indiana Avenue Lansing, IL 60438-2226 Phone: 708-474-2447 Automatic renewals will be available for eligible www.lansingpl.org items with due dates of June 15, 2017 or later. Maximum 2 renewals on eligible items. Log in to My Account at www.lansingpl.org to view In This Issue your checked out materials and their due dates. Adult Events Automatic Renewals Mobile Hot Spots! Computer Classes Food For Fines Please visit the Library or Take Wi-Fi where you need it! Check one out to use Friends & Groups our website for updates to while traveling, at the park, Geocaching program information. or if you don’t have internet Mobile Hot Spots www.lansingpl.org access where you need it! Summer Reading Teen Events Director: Deborah Albrecht 1 week checkout, Editor: Kelli Staley Youth Events Graphic Design: Kelli Staley no renewal allowed, $1 per day overdue. Adult Events Register for Adult Events at the Multi-Library Every class in each series builds on Information Desk, on our Geocaching the previous class. -

Your Old Books
2. What makes a book important? books are generally more sought after, Your Old Books People value books either because of including all books printed before 1501, their contents or because of their physi- English books printed before 1641, books • cal characteristics. First editions of im- printed in the Americas before 1801, and A guide sponsored by the Rare Books and Manuscripts Section portant literary or historical works and books printed west of the Mississippi be- of the Association of College and Research Libraries, the Antiquarian Booksellers’ initial reports of scientific discoveries or fore 1850. Association of America, and the Rare Book School at the University of Virginia inventions are prime examples of books • that are important because of their con- 5. What is the difference between a rare tents. Illustrated books that give a new book and a second-hand book? This guide addresses some frequently 11. Are old letters, scrapbooks, photo- interpretation of a text or are the work of A second-hand or used book is a previ- asked questions about rare and older graphs, and documents valuable? an esteemed artist are also valued. Books ously owned book that is neither an im- books and their values. The answers are 12. Might someone want my single vol- that were suppressed or censored may portant edition nor has special physical meant only as general responses to these ume to complete a set? be both important and scarce, since few characteristics, such as binding, inscrip- questions, and many possible exceptions 13. How can I keep my books in good copies may have survived. -

Osler As a Bibliophile
Zbc Boston flDefcícal anb Surgical Journal TABLE OF CONTENTS April 1, 1920 ADDRESSES How to Conduct Nutrition Clinics and Classes.351 Physician as 351 Osler as a Bibliophile. By Edward C. Streeter, M.D., Boston. 335 A an Ambassador. 351 Osler as his Students Knew Him. By Joseph II. Pratt, M.D., Medical Notes. Boston. 338 MISCELLANY Osler in the Early Days at the Johns Hopkins Hospital. By W. T. Councilman, M.D., Boston. 341 Report upon Health Education by the Joint Committke on Legislation of the Massachusetts Medical Society ORIGINAL ARTICLE and the Massachusetts Homeopathic Medical Society. 356 Renal Function in Vascular Hypertension. By James P. Resolutions on the Death of Dr. Southard... 357 O'Hare, M.D., Boston. 345 United States Civil Service Examinations. 357 EDITORIALS Complimentary Luncheon to General Leonard Wood.358 Child Hygiene in Missouri. 349 Transportation to Meeting of American Medical Associa- Narcotic Drug Regulations. 350 tion, New Orleans, April 26 to 30. 353 reality. Acting on this conviction, "without ' ' fraud, cozen or delay, he happily brought every student with whom he came in touch into a OSLER AS A BIBLIOPHILE. proper system of relations with the achieving minds, the heroic inquiring spirits of past ages. BY Edward C. Streeter, M.D., Boston. Early in his course as teacher he faced this au- In attempting to take a level of the affec- gust relationship squarely. He became, like tions of Dr. Osier we will doubtless find that Boerhaave, one of the greatest exemplars of the next to the love of men with him came love of historical method of medical teaching that ever books. -

Ripoff 101 2Nd Edition
State Public Interest Research Groups RIPOFF 101: 2nd Edition How the Publishing Industry’s Practices Needlessly Drive Up Textbook Costs A National Survey of Textbook Prices February 2005 Page i ACKNOWLEDGEMENTS Written by Kate Rube, Higher Education Advocate with the State Public Interest Research Groups (PIRGs), with contributions from Merriah Fairchild, Higher Education Advocate with the CALPIRG Education Fund. © 2005, State Public Interest Research Groups The author would like to thank the following people for reviewing this report and offering their comments: Robert Shireman, Student Loan Watch; Erwin Cohen, former publishing executive; George Blumenthal, Chair, University of California Statewide Academic Senate; Jerry S. Davis, higher education consultant; Barmak Nassirian, American Association of Collegiate Registrars and Admissions Officers; Roger Bowen, American Association of University Professors; Thomas Wolanin, The Institute for Higher Education Policy; and Edward Elmendorf, American Association of State Colleges and Universities. For more information, contact the State PIRGs’ Higher Education Project at: State PIRGs 218 D Street SE Washington, DC 20003 (202) 546-9707 Additional copies of the report can be obtained by visiting www.pirg.org/highered. Page ii TABLE OF CONTENTS EXECUTIVE SUMMARY............................................................................................................ 1 INTRODUCTION ....................................................................................................................... -

MLA 8Th Edition Formatting and Style Guide
MLA 8th Edition Formatting and Style Guide Purdue OWL Staff Brought to you in cooperation with the Purdue Online Writing Lab What is MLA? MLA (Modern Language Association) Style formatting is often used in various humanities disciplines. In addition to the handbook, MLA also offers The MLA Style Center, a website that provides additional instruction and resources for writing and formatting academic papers. https://style.mla.org/ What does MLA regulate? MLA regulates: •document format •in-text citations •works-cited list MLA Update 2016 The 8th edition handbook introduces a new way to cite sources. Instead of a long list of rules, MLA guidelines are now based on a set of principles that may be used to cite any type of source. The three guiding principles: 1.Cite simple traits shared by most works. 2.Remember that there is more than one way to cite the same source. 3.Make your documentation useful to readers. Overview This presentation will cover: • How to format a paper in MLA style (8th ed.) • General guidelines • First page format • Section headings • In-text citations • Formatting quotations • Documenting sources in MLA style (8th ed.) • Core elements • List of works cited Your Instructor Knows Best Basic rule for any formatting style: Always Follow your instructor’s guidelines Format: General Guidelines An MLA Style paper should: • Be typed on white 8.5“ x 11“ paper • Double-space everything • Use 12 pt. Times New Roman (or similar) font • Leave only one space after punctuation • Set all margins to 1 inch on all sides • Indent the first -

1 Writing in APA Style: a Sample Student Paper Lisa Blackwell Wan
1 Writing in APA Style: A Sample Student Paper Commented [LBW2]: Use a concise, descriptive title which lets the reader know about the main idea and related concepts of your paper. Use Title Case capitalization which means to capitalize as a book title is done. Lisa Blackwell Wan Commented [LBW3]: Use two double-spaced lines between the title and the authors’ lines. If more than one Department of the Library, Tarleton State University author is responsible for the paper, list each one on a separate line followed by the academic affiliation. LBRY 1001: APA Writing Commented [LBW4]: Include the course number followed by a colon, then the course name. Dr. Eliza Bibliophile Commented [LBW5]: List the instructor’s name next. August 1, 2020 Commented [LBW6]: The due date for the paper is shown using the month, date, and year format appropriate to the country. 2 Abstract Commented [LBW7]: Abstracts are not typically required for undergraduate students’ papers, while graduate The abstract, written in the style of the American Psychological Association (APA), provides a succinct students are typically required to include an Abstract. Commented [LBW8]: Place the label “Abstract” on the description of the paper in no more than 250 words. Most undergraduate students are not required to first line of the second page, centered, and bolded. Commented [LBW9]: Begin the abstract using left- include an abstract, while graduate students’ papers will usually need to contain an abstract. In your justification. Always use double-spacing. Commented [LBW10]: See the APA Manual, p. 38. abstract, include descriptions of your hypothesis or thesis statement, followed by the main ideas in your paper. -

SUMMER SPECIAL EDITION the July 2020 Paperback Book Sale and the September 2020 Annual Sale That Are Held at the Westport Free Public Library
Vol. 8, Issue 3 July—September 2020 Cancelled The Friends of the Westport Library have cancelled both SUMMER SPECIAL EDITION the July 2020 paperback book sale and the September 2020 annual sale that are held at the Westport Free Public Library. We will also not be accepting any donated books as we have no place to store them. Perspectives: Challenging Times... When the Library does reo- pen to the public, please visit Michael’s Book Store located Hello Library Friends, just off the lobby. We’ll be add- I have been thinking about what to say to all of you these days. I ing new titles regularly from our inventory. trust that you and your loved ones are all doing well and will continue to do so. Let me bring you up-to-date on Library services. The Library If you have any questions, please email the Friends group closed on March 17th and here we are over three months later with at [email protected]. the Library doors locked. The staff started working in the Library on May 18th after previously working from home. Rest assured that we Services have been ordering new titles, etc. and cataloguing them throughout these days. Our shelves are full just waiting for services to resume. Free Wi-Fi Access Meanwhile, since May 20th, our parking lot has been under con- Magnifiers for Visually Impaired struction as part of the school building project next door. Underground SAILS Library Network 24/7 Borrow- utilities are being finalized. The driveway will be moving to the west as ing it continues to be shared with the new school.