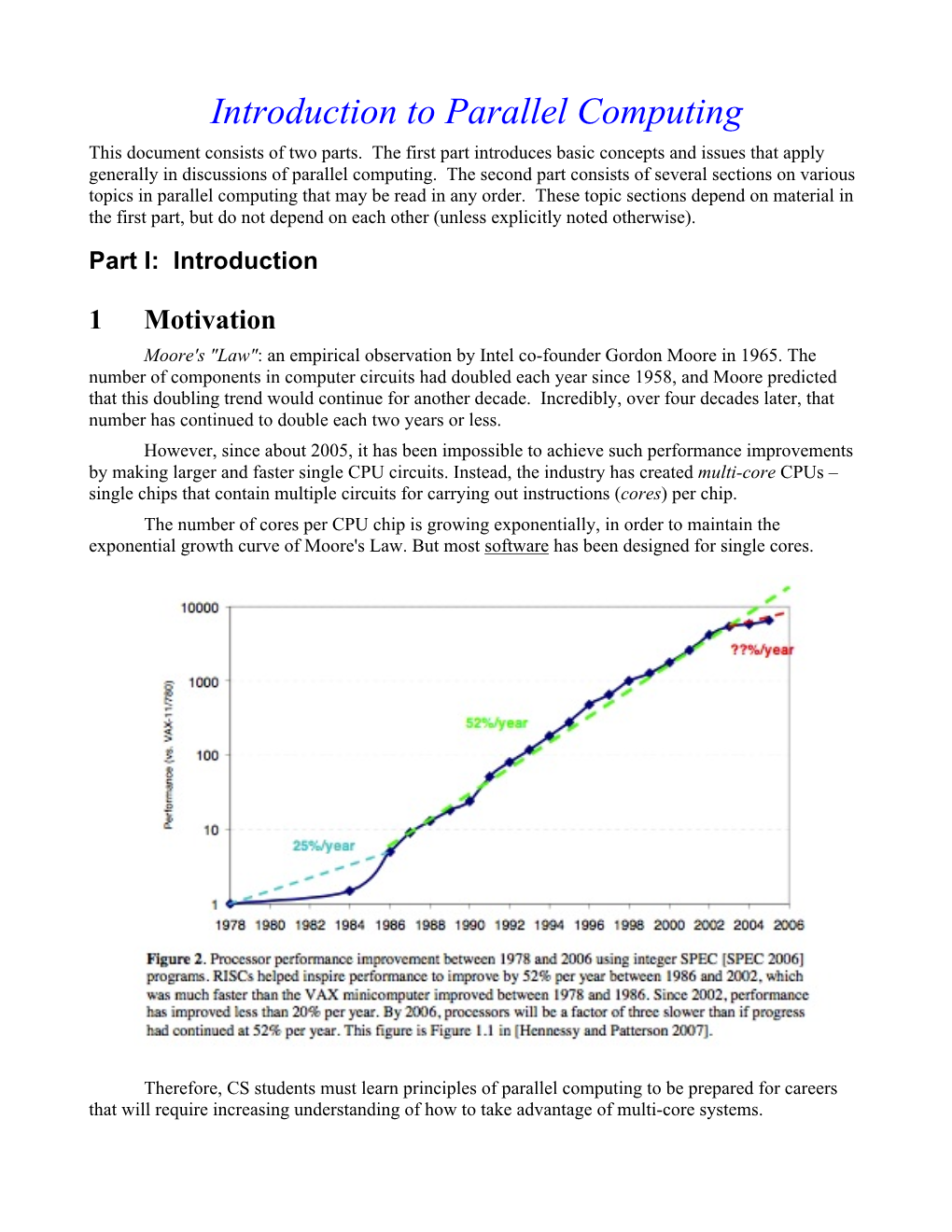
Introduction to Parallel Computing This Document Consists of Two Parts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Data-Level Parallelism
Fall 2015 :: CSE 610 – Parallel Computer Architectures Data-Level Parallelism Nima Honarmand Fall 2015 :: CSE 610 – Parallel Computer Architectures Overview • Data Parallelism vs. Control Parallelism – Data Parallelism: parallelism arises from executing essentially the same code on a large number of objects – Control Parallelism: parallelism arises from executing different threads of control concurrently • Hypothesis: applications that use massively parallel machines will mostly exploit data parallelism – Common in the Scientific Computing domain • DLP originally linked with SIMD machines; now SIMT is more common – SIMD: Single Instruction Multiple Data – SIMT: Single Instruction Multiple Threads Fall 2015 :: CSE 610 – Parallel Computer Architectures Overview • Many incarnations of DLP architectures over decades – Old vector processors • Cray processors: Cray-1, Cray-2, …, Cray X1 – SIMD extensions • Intel SSE and AVX units • Alpha Tarantula (didn’t see light of day ) – Old massively parallel computers • Connection Machines • MasPar machines – Modern GPUs • NVIDIA, AMD, Qualcomm, … • Focus of throughput rather than latency Vector Processors 4 SCALAR VECTOR (1 operation) (N operations) r1 r2 v1 v2 + + r3 v3 vector length add r3, r1, r2 vadd.vv v3, v1, v2 Scalar processors operate on single numbers (scalars) Vector processors operate on linear sequences of numbers (vectors) 6.888 Spring 2013 - Sanchez and Emer - L14 What’s in a Vector Processor? 5 A scalar processor (e.g. a MIPS processor) Scalar register file (32 registers) Scalar functional units (arithmetic, load/store, etc) A vector register file (a 2D register array) Each register is an array of elements E.g. 32 registers with 32 64-bit elements per register MVL = maximum vector length = max # of elements per register A set of vector functional units Integer, FP, load/store, etc Some times vector and scalar units are combined (share ALUs) 6.888 Spring 2013 - Sanchez and Emer - L14 Example of Simple Vector Processor 6 6.888 Spring 2013 - Sanchez and Emer - L14 Basic Vector ISA 7 Instr. -

High Performance Computing Through Parallel and Distributed Processing
Yadav S. et al., J. Harmoniz. Res. Eng., 2013, 1(2), 54-64 Journal Of Harmonized Research (JOHR) Journal Of Harmonized Research in Engineering 1(2), 2013, 54-64 ISSN 2347 – 7393 Original Research Article High Performance Computing through Parallel and Distributed Processing Shikha Yadav, Preeti Dhanda, Nisha Yadav Department of Computer Science and Engineering, Dronacharya College of Engineering, Khentawas, Farukhnagar, Gurgaon, India Abstract : There is a very high need of High Performance Computing (HPC) in many applications like space science to Artificial Intelligence. HPC shall be attained through Parallel and Distributed Computing. In this paper, Parallel and Distributed algorithms are discussed based on Parallel and Distributed Processors to achieve HPC. The Programming concepts like threads, fork and sockets are discussed with some simple examples for HPC. Keywords: High Performance Computing, Parallel and Distributed processing, Computer Architecture Introduction time to solve large problems like weather Computer Architecture and Programming play forecasting, Tsunami, Remote Sensing, a significant role for High Performance National calamities, Defence, Mineral computing (HPC) in large applications Space exploration, Finite-element, Cloud science to Artificial Intelligence. The Computing, and Expert Systems etc. The Algorithms are problem solving procedures Algorithms are Non-Recursive Algorithms, and later these algorithms transform in to Recursive Algorithms, Parallel Algorithms particular Programming language for HPC. and Distributed Algorithms. There is need to study algorithms for High The Algorithms must be supported the Performance Computing. These Algorithms Computer Architecture. The Computer are to be designed to computer in reasonable Architecture is characterized with Flynn’s Classification SISD, SIMD, MIMD, and For Correspondence: MISD. Most of the Computer Architectures preeti.dhanda01ATgmail.com are supported with SIMD (Single Instruction Received on: October 2013 Multiple Data Streams). -

Scalable and Distributed Deep Learning (DL): Co-Design MPI Runtimes and DL Frameworks
Scalable and Distributed Deep Learning (DL): Co-Design MPI Runtimes and DL Frameworks OSU Booth Talk (SC ’19) Ammar Ahmad Awan [email protected] Network Based Computing Laboratory Dept. of Computer Science and Engineering The Ohio State University Agenda • Introduction – Deep Learning Trends – CPUs and GPUs for Deep Learning – Message Passing Interface (MPI) • Research Challenges: Exploiting HPC for Deep Learning • Proposed Solutions • Conclusion Network Based Computing Laboratory OSU Booth - SC ‘18 High-Performance Deep Learning 2 Understanding the Deep Learning Resurgence • Deep Learning (DL) is a sub-set of Machine Learning (ML) – Perhaps, the most revolutionary subset! Deep Machine – Feature extraction vs. hand-crafted Learning Learning features AI Examples: • Deep Learning Examples: Logistic Regression – A renewed interest and a lot of hype! MLPs, DNNs, – Key success: Deep Neural Networks (DNNs) – Everything was there since the late 80s except the “computability of DNNs” Adopted from: http://www.deeplearningbook.org/contents/intro.html Network Based Computing Laboratory OSU Booth - SC ‘18 High-Performance Deep Learning 3 AlexNet Deep Learning in the Many-core Era 10000 8000 • Modern and efficient hardware enabled 6000 – Computability of DNNs – impossible in the 4000 ~500X in 5 years 2000 past! Minutesto Train – GPUs – at the core of DNN training 0 2 GTX 580 DGX-2 – CPUs – catching up fast • Availability of Datasets – MNIST, CIFAR10, ImageNet, and more… • Excellent Accuracy for many application areas – Vision, Machine Translation, and -

Introduction to Multi-Threading and Vectorization Matti Kortelainen Larsoft Workshop 2019 25 June 2019 Outline
Introduction to multi-threading and vectorization Matti Kortelainen LArSoft Workshop 2019 25 June 2019 Outline Broad introductory overview: • Why multithread? • What is a thread? • Some threading models – std::thread – OpenMP (fork-join) – Intel Threading Building Blocks (TBB) (tasks) • Race condition, critical region, mutual exclusion, deadlock • Vectorization (SIMD) 2 6/25/19 Matti Kortelainen | Introduction to multi-threading and vectorization Motivations for multithreading Image courtesy of K. Rupp 3 6/25/19 Matti Kortelainen | Introduction to multi-threading and vectorization Motivations for multithreading • One process on a node: speedups from parallelizing parts of the programs – Any problem can get speedup if the threads can cooperate on • same core (sharing L1 cache) • L2 cache (may be shared among small number of cores) • Fully loaded node: save memory and other resources – Threads can share objects -> N threads can use significantly less memory than N processes • If smallest chunk of data is so big that only one fits in memory at a time, is there any other option? 4 6/25/19 Matti Kortelainen | Introduction to multi-threading and vectorization What is a (software) thread? (in POSIX/Linux) • “Smallest sequence of programmed instructions that can be managed independently by a scheduler” [Wikipedia] • A thread has its own – Program counter – Registers – Stack – Thread-local memory (better to avoid in general) • Threads of a process share everything else, e.g. – Program code, constants – Heap memory – Network connections – File handles -

Parallel Programming
Parallel Programming Parallel Programming Parallel Computing Hardware Shared memory: multiple cpus are attached to the BUS all processors share the same primary memory the same memory address on different CPU’s refer to the same memory location CPU-to-memory connection becomes a bottleneck: shared memory computers cannot scale very well Parallel Programming Parallel Computing Hardware Distributed memory: each processor has its own private memory computational tasks can only operate on local data infinite available memory through adding nodes requires more difficult programming Parallel Programming OpenMP versus MPI OpenMP (Open Multi-Processing): easy to use; loop-level parallelism non-loop-level parallelism is more difficult limited to shared memory computers cannot handle very large problems MPI(Message Passing Interface): require low-level programming; more difficult programming scalable cost/size can handle very large problems Parallel Programming MPI Distributed memory: Each processor can access only the instructions/data stored in its own memory. The machine has an interconnection network that supports passing messages between processors. A user specifies a number of concurrent processes when program begins. Every process executes the same program, though theflow of execution may depend on the processors unique ID number (e.g. “if (my id == 0) then ”). ··· Each process performs computations on its local variables, then communicates with other processes (repeat), to eventually achieve the computed result. In this model, processors pass messages both to send/receive information, and to synchronize with one another. Parallel Programming Introduction to MPI Communicators and Groups: MPI uses objects called communicators and groups to define which collection of processes may communicate with each other. -

Parallel Computer Architecture
Parallel Computer Architecture Introduction to Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 2 – Parallel Architecture Outline q Parallel architecture types q Instruction-level parallelism q Vector processing q SIMD q Shared memory ❍ Memory organization: UMA, NUMA ❍ Coherency: CC-UMA, CC-NUMA q Interconnection networks q Distributed memory q Clusters q Clusters of SMPs q Heterogeneous clusters of SMPs Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 2 Parallel Architecture Types • Uniprocessor • Shared Memory – Scalar processor Multiprocessor (SMP) processor – Shared memory address space – Bus-based memory system memory processor … processor – Vector processor bus processor vector memory memory – Interconnection network – Single Instruction Multiple processor … processor Data (SIMD) network processor … … memory memory Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 3 Parallel Architecture Types (2) • Distributed Memory • Cluster of SMPs Multiprocessor – Shared memory addressing – Message passing within SMP node between nodes – Message passing between SMP memory memory nodes … M M processor processor … … P … P P P interconnec2on network network interface interconnec2on network processor processor … P … P P … P memory memory … M M – Massively Parallel Processor (MPP) – Can also be regarded as MPP if • Many, many processors processor number is large Introduction to Parallel Computing, University of Oregon, -

Demystifying Parallel and Distributed Deep Learning: an In-Depth Concurrency Analysis
1 Demystifying Parallel and Distributed Deep Learning: An In-Depth Concurrency Analysis TAL BEN-NUN and TORSTEN HOEFLER, ETH Zurich, Switzerland Deep Neural Networks (DNNs) are becoming an important tool in modern computing applications. Accelerating their training is a major challenge and techniques range from distributed algorithms to low-level circuit design. In this survey, we describe the problem from a theoretical perspective, followed by approaches for its parallelization. We present trends in DNN architectures and the resulting implications on parallelization strategies. We then review and model the different types of concurrency in DNNs: from the single operator, through parallelism in network inference and training, to distributed deep learning. We discuss asynchronous stochastic optimization, distributed system architectures, communication schemes, and neural architecture search. Based on those approaches, we extrapolate potential directions for parallelism in deep learning. CCS Concepts: • General and reference → Surveys and overviews; • Computing methodologies → Neural networks; Parallel computing methodologies; Distributed computing methodologies; Additional Key Words and Phrases: Deep Learning, Distributed Computing, Parallel Algorithms ACM Reference Format: Tal Ben-Nun and Torsten Hoefler. 2018. Demystifying Parallel and Distributed Deep Learning: An In-Depth Concurrency Analysis. 47 pages. 1 INTRODUCTION Machine Learning, and in particular Deep Learning [143], is rapidly taking over a variety of aspects in our daily lives. -

Parallel Programming: Performance
Introduction Parallel Programming: Rich space of techniques and issues • Trade off and interact with one another Performance Issues can be addressed/helped by software or hardware • Algorithmic or programming techniques • Architectural techniques Todd C. Mowry Focus here on performance issues and software techniques CS 418 • Point out some architectural implications January 20, 25 & 26, 2011 • Architectural techniques covered in rest of class –2– CS 418 Programming as Successive Refinement Outline Not all issues dealt with up front 1. Partitioning for performance Partitioning often independent of architecture, and done first 2. Relationshipp,y of communication, data locality and • View machine as a collection of communicating processors architecture – balancing the workload – reducing the amount of inherent communication 3. Orchestration for performance – reducing extra work • Tug-o-war even among these three issues For each issue: Then interactions with architecture • Techniques to address it, and tradeoffs with previous issues • Illustration using case studies • View machine as extended memory hierarchy • Application to g rid solver –extra communication due to archlhitectural interactions • Some architectural implications – cost of communication depends on how it is structured • May inspire changes in partitioning Discussion of issues is one at a time, but identifies tradeoffs 4. Components of execution time as seen by processor • Use examples, and measurements on SGI Origin2000 • What workload looks like to architecture, and relate to software issues –3– CS 418 –4– CS 418 Page 1 Partitioning for Performance Load Balance and Synch Wait Time Sequential Work 1. Balancing the workload and reducing wait time at synch Limit on speedup: Speedupproblem(p) < points Max Work on any Processor • Work includes data access and other costs 2. -

Real-Time Performance During CUDA™ a Demonstration and Analysis of Redhawk™ CUDA RT Optimizations
A Concurrent Real-Time White Paper 2881 Gateway Drive Pompano Beach, FL 33069 (954) 974-1700 www.concurrent-rt.com Real-Time Performance During CUDA™ A Demonstration and Analysis of RedHawk™ CUDA RT Optimizations By: Concurrent Real-Time Linux® Development Team November 2010 Overview There are many challenges to creating a real-time Linux distribution that provides guaranteed low process-dispatch latencies and minimal process run-time jitter. Concurrent Real Time’s RedHawk Linux distribution meets and exceeds these challenges, providing a hard real-time environment on many qualified hardware configurations, even in the presence of a heavy system load. However, there are additional challenges faced when guaranteeing real-time performance of processes while CUDA applications are simultaneously running on the system. The proprietary CUDA driver supplied by NVIDIA® frequently makes demands upon kernel resources that can dramatically impact real-time performance. This paper discusses a demonstration application developed by Concurrent to illustrate that RedHawk Linux kernel optimizations allow hard real-time performance guarantees to be preserved even while demanding CUDA applications are running. The test results will show how RedHawk performance compares to CentOS performance running the same application. The design and implementation details of the demonstration application are also discussed in this paper. Demonstration This demonstration features two selectable real-time test modes: 1. Jitter Mode: measure and graph the run-time jitter of a real-time process 2. PDL Mode: measure and graph the process-dispatch latency of a real-time process While the demonstration is running, it is possible to switch between these different modes at any time. -

Exploiting Parallelism in Many-Core Architectures: Architectures G Bortolotti, M Caberletti, G Crimi Et Al
Journal of Physics: Conference Series OPEN ACCESS Related content - Computing on Knights and Kepler Exploiting parallelism in many-core architectures: Architectures G Bortolotti, M Caberletti, G Crimi et al. Lattice Boltzmann models as a test case - Implementing the lattice Boltzmann model on commodity graphics hardware Arie Kaufman, Zhe Fan and Kaloian To cite this article: F Mantovani et al 2013 J. Phys.: Conf. Ser. 454 012015 Petkov - Many-core experience with HEP software at CERN openlab Sverre Jarp, Alfio Lazzaro, Julien Leduc et al. View the article online for updates and enhancements. Recent citations - Lattice Boltzmann benchmark kernels as a testbed for performance analysis M. Wittmann et al - Enrico Calore et al - Computing on Knights and Kepler Architectures G Bortolotti et al This content was downloaded from IP address 170.106.202.58 on 23/09/2021 at 15:57 24th IUPAP Conference on Computational Physics (IUPAP-CCP 2012) IOP Publishing Journal of Physics: Conference Series 454 (2013) 012015 doi:10.1088/1742-6596/454/1/012015 Exploiting parallelism in many-core architectures: Lattice Boltzmann models as a test case F Mantovani1, M Pivanti2, S F Schifano3 and R Tripiccione4 1 Department of Physics, Univesit¨atRegensburg, Germany 2 Department of Physics, Universit`adi Roma La Sapienza, Italy 3 Department of Mathematics and Informatics, Universit`adi Ferrara and INFN, Italy 4 Department of Physics and CMCS, Universit`adi Ferrara and INFN, Italy E-mail: [email protected], [email protected], [email protected], [email protected] Abstract. In this paper we address the problem of identifying and exploiting techniques that optimize the performance of large scale scientific codes on many-core processors. -

Map, Reduce and Mapreduce, the Skeleton Way$
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Procedia Computer Science ProcediaProcedia Computer Computer Science Science 00 1 (2010)(2012) 1–9 2095–2103 www.elsevier.com/locate/procedia International Conference on Computational Science, ICCS 2010 Map, Reduce and MapReduce, the skeleton way$ D. Buonoa, M. Daneluttoa, S. Lamettia aDept. of Computer Science, Univ. of Pisa, Italy Abstract Composition of Map and Reduce algorithmic skeletons have been widely studied at the end of the last century and it has demonstrated effective on a wide class of problems. We recall the theoretical results motivating the intro- duction of these skeletons, then we discuss an experiment implementing three algorithmic skeletons, a map,areduce and an optimized composition of a map followed by a reduce skeleton (map+reduce). The map+reduce skeleton implemented computes the same kind of problems computed by Google MapReduce, but the data flow through the skeleton is streamed rather than relying on already distributed (and possibly quite large) data items. We discuss the implementation of the three skeletons on top of ProActive/GCM in the MareMare prototype and we present some experimental obtained on a COTS cluster. ⃝c 2012 Published by Elsevier Ltd. Open access under CC BY-NC-ND license. Keywords: Algorithmic skeletons, map, reduce, list theory, homomorphisms 1. Introduction Algorithmic skeletons have been around since Murray Cole’s PhD thesis [1]. An algorithmic skeleton is a paramet- ric, reusable, efficient and composable programming construct that exploits a well know, efficient parallelism exploita- tion pattern. A skeleton programmer may build parallel applications simply picking up a (composition of) skeleton from the skeleton library available, providing the required parameters and running some kind of compiler+run time library tool specific of the target architecture at hand [2]. -

Unit: 4 Processes and Threads in Distributed Systems
Unit: 4 Processes and Threads in Distributed Systems Thread A program has one or more locus of execution. Each execution is called a thread of execution. In traditional operating systems, each process has an address space and a single thread of execution. It is the smallest unit of processing that can be scheduled by an operating system. A thread is a single sequence stream within in a process. Because threads have some of the properties of processes, they are sometimes called lightweight processes. In a process, threads allow multiple executions of streams. Thread Structure Process is used to group resources together and threads are the entities scheduled for execution on the CPU. The thread has a program counter that keeps track of which instruction to execute next. It has registers, which holds its current working variables. It has a stack, which contains the execution history, with one frame for each procedure called but not yet returned from. Although a thread must execute in some process, the thread and its process are different concepts and can be treated separately. What threads add to the process model is to allow multiple executions to take place in the same process environment, to a large degree independent of one another. Having multiple threads running in parallel in one process is similar to having multiple processes running in parallel in one computer. Figure: (a) Three processes each with one thread. (b) One process with three threads. In former case, the threads share an address space, open files, and other resources. In the latter case, process share physical memory, disks, printers and other resources.