Local-Area Internetworks: Measurements and Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
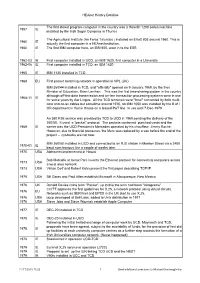
00 Heanet Dateline
HEAnet History Dateline The first stored program computer in the country was a Holerith 1200 series machine 1957 IE installed by the Irish Sugar Company in Thurles The Agricultural Institute (An Foras Taluntais ) installed an Elliott 803 around 1960. This is 1960 IE actually the first computer in a HEAnet institution. 1960 IE The first IBM computer here, an IBM 650, went in to the ESB 1962-03 IE First computer installed in UCD, an IBM 1620, first computer in a University 1962-06 IE First computer installed in TCD, an IBM 1620 1965 IE IBM 1130 installed in TCD 1968 EU First packet switching network in operation in NPL (UK) IBM 360/44 installed in TCD, and "officially" opened on 9 January,1969, by the then Minister of Education, Brian Lenihan. This was the first time-sharing system in the country although off-line data transmission and on-line transaction processing systems were in use 1968-11 IE for some years by Aer Lingus. All the TCD terminals were "local" connected by both multi- core and co-ax cables but sometime around 1970, an IBM 1050 was installed by the B of I OR department in Hume House on a leased P&T line. In use until 7-Dec-1979 An 360 RJE service was provided by TCD to UCD in 1969 pending the delivery of the 360/50. It used a "packet" protocol. The packets contained punched cards and the 1969 IE carrier was the UCD President's Mercedes operated by his chauffeur, Jimmy Roche. However, due to financial pressures, the Merc was replaced by a van before the end of the project - cut-backs are not new. -

Investing in Our Future
PRESIDENT’S INFORMATION TECHNOLOGY ADVISORY COMMITTEE REPORT TO THE PRESIDENT Information Technology Research: Investing in Our Future February 24, 1999 National Coordination Office for Computing, Information, and Communications 4201 Wilson Boulevard, Suite 690 Arlington, VA 22230 (703) 306-4722 www.ccic.gov President’s Information Technology Advisory Committee PRESIDENT’S INFORMATION TECHNOLOGY ADVISORY COMMITTEE February 24, 1999 The President of the United States The White House Dear Mr. President: We are pleased to present our final report, “Information Technology Research: Investing in Our Future,” on future directions for Federal support of research and development for information technology. This report adds detail to the findings and recommendations in our interim report dated August 1998, and strengthens our previous recommendations regarding the importance of social and economic research on the impacts of information technology to inform key policy decisions. PITAC members are strongly encouraged by and enthusiastically supportive of the Administration’s Information Technology for the Twenty-First Century (IT2) initiative. This initiative is a vital first step in increasing funding for long-term, high-risk information technology research and development. Increased Federal support is critical to meeting the challenge of capturing the opportunities available from information technology in the 21st Century through appropriate research and development. The economic and strategic importance of information technology and the unique role of the Federal Government in sponsoring information technology research make it necessary to increase Federal support over a period of years to ensure our Nation’s future well-being. We hope that our recommendations will be helpful as you consider the priorities for Federal investments. -

Stanford University's Economic Impact
Stanford University’s Economic Impact via Innovation and Entrepreneurship October 2012 Charles E. Eesley, Assistant Professor in Management Science & Engineering; and Morgenthaler Faculty Fellow, School of Engineering, Stanford University William F. Miller, Herbert Hoover Professor of Public and Private Management Emeritus; Professor of Computer Science Emeritus and former Provost, Stanford University and Faculty Co-director, SPRIE EXECUTIVE SUMMARY Stanford University has a deep history in entrepreneurship and technological innovation. For more than a century, the university has incubated ideas, educated entrepreneurs and fostered breakthrough technologies that have been instrumental in the rise and constant regeneration of Silicon Valley, and at the same time, contributed to the broader global economy. Stanford graduates have founded, built or led thousands of businesses, including some of the world’s most recognized companies – Google, Nike, Cisco, Hewlett-Packard, Charles Schwab, Yahoo!, Gap, VMware, IDEO, Netflix and Tesla. In the area of social innovation, the Stanford community has created thousands of non-profit organizations over the decades, including such well-known organizations as Kiva, the Special Olympics and Acumen Fund. This report focuses on data gathered from a large-scale, systematic survey of Stanford alumni, faculty and selected staff in 2011 to assess the university’s economic impact based on its involvement in entrepreneurship. The report describes Stanford’s role in fostering entrepreneurship, discusses how the Stanford environment encourages creativity and entrepreneurship and details best practices for creating an entrepreneurial ecosystem. The report on 2011 survey, sponsored by the venture capital firm Sequoia Capital, estimates that 39,900 active companies can trace their roots to Stanford. -

Silicon Valley
Silicon Valley A silicon wafer (Photo © AP Images) In this issue: The Power of the Chip Zoom in on America The Birth of Silicon Valley If you look for Silicon Valley on a map, you might not find it. Silicon Valley is the nickname of the region near San Francisco that today is synonymous with innovation and high-tech companies. Silicon Valley traces its roots to 1939, when William Hewlett and David Packard, both Stanford University alumni, opened an electronics shop in a Palo Alto garage. Geographically, Silicon Valley lies in the area of the Santa ries of articles entitled “Silicon Valley in the USA” that he Clara Valley south of San Francisco. Previously the area wrote for the weekly Electronic News. Hoefler did not in- was famous for its orchards and agriculture. In fact it used vent the term himself; he took it from his friend, business- to be nicknamed the Valley of Heart’s Delight. The region man Ralph Vaerst. “Silicon” refers to the production of covers some 100 km², and its main city is San Jose, which computer semiconductors, in which silicon chips are used. now has a population of close to 1 million people. While people trace the birth of Silicon Valley back to 1939, the In 1849, gold miners seeking riches flocked to California term “Silicon Valley” was not used until 1971. Economic from all over the world in one of the world’s greatest gold commentator Don Hoefler popularized the name in a se- rushes. Almost 100 years later, high-tech industry started The house where Hewlett-Packard was founded in Palo Alto. -
Stanford University's Economic Impact Via Innovation and Entrepreneurship
Impact: Stanford University’s Economic Impact via Innovation and Entrepreneurship October 2012 Charles E. Eesley, Assistant Professor in Management Science & Engineering; and Morgenthaler Faculty Fellow, School of Engineering, Stanford University William F. Miller, Herbert Hoover Professor of Public and Private Management Emeritus; Professor of Computer Science Emeritus and former Provost, Stanford University and Faculty Co-director, SPRIE* *We thank Sequoia Capital for its generous support of this research. 1 About the authors: Charles Eesley, is an assistant professor and Morgenthaler Faculty Fellow in the department of Management Science and Engineering at Stanford University. His research interests focus on strategy and technology entrepreneurship. His research seeks to uncover which individual attributes, strategies and institutional arrangements optimally drive high growth and high tech entrepreneurship. He is the recipient of the 2010 Best Dissertation Award in the Business Policy and Strategy Division of the Academy of Management, of the 2011 National Natural Science Foundation Award in China, and of the 2007 Ewing Marion Kauffman Foundation Dissertation Fellowship Award for his work on entrepreneurship in China. His research appears in the Strategic Management Journal, Research Policy and the Journal of Economics & Management Strategy. Prior to receiving his PhD from the Sloan School of Management at MIT, he was an entrepreneur in the life sciences and worked at the Duke University Medical Center, publishing in medical journals and in textbooks on cognition in schizophrenia. William F. Miller has spent about half of his professional life in business and half in academia. He served as vice president and provost of Stanford University (1971-1979) where he conducted research and directed many graduate students in computer science. -

A Study on the Marketing Strategies of the Cisco - Online Store
Shanlax International Journal of Management ISSN: 2321-4643 UGC Approval No: 44278 Impact Factor: 2.082 A STUDY ON THE MARKETING STRATEGIES OF THE CISCO - ONLINE STORE Article Particulars Received: 19.7.2017 Accepted: 26.7.2017 Published: 28.7.2017 K. ARCHUNAN Assistant Professor in Commerce, Subbalakshmi Lakshmipathy College of Science, TVR Nagar, Aruppukottai Road, Madurai, Tamil Nadu, India Introduction During 1991, there was the greatest invention in the field of Information Technology (IT), due to that a demand for the accessories for IT sectors. But there was no one entered in the manufacturing field. In the late1980s some of the technicians are developing accessories for the computers. The PC was simply a mainframe on your desk. Of course it unleashed a wonderful stream of personal productivity applications that in turn contributed greatly to the growth of enterprise data and the start of digitizing business-related, home-based activities. But I would argue that the major quantitative and qualitative leap occurred only when work PCs were connected to each other via Local Area Networks (LANs) —where Ethernet became the standard— and then long-distance via Wide Area Networks (WANs). With the PC, we could digitally create letters, pictures, designs and transactions. Due to the birth of the internet, the PCs are connected within the organization, for these purposes, it needs the connectors, switches and other accessories. Later the computer networks are linked are connected globally. There were very few innovative companies are entered into the market. Among those companies Cisco was dominating all and enjoyed with huge amount of profit more than a decade. -

Wizards and Their Wonders: Portraits in Computing
. Atanasoff, 1, Marc Andreessen, John Charles Bachman, J eas Bechtolsheim, Gordon Bell, Gwen Bell, Eric Benhar :h, Leonard Bosack, Jeff Braun, Dan Bricklin, Fred Broo ]atmull, Vint Cerf, John Chambers, John Chowning, W< Fernando Corbato, Joel Birnbaum, Jim Blinn, Erich Bl , Whitfield Diffie, John Doerr, Esther Dyson, Presper Ec iordon Eubanks, Jr. Wizards Robert Evans, Robert Eve , Jay Forrester, William Foster and Bob Frankston, Chri William Gates Their Louis Gerstner, Charles Geschke, J eilmeier, Andrew Heller Wonders Gardner Hendrie, J , Grace Murray Hopper, Max Hopper, Charles House, D in, Philippe Kahn, Jerrold Kaplan, Mitchell Kapor, Alan i, Steven Kirsch, Leonard Kleinrock, Donald Knuth, The *nda Laurel, David Liddle, Robert Lucky, Dan Lynch, B^ irdt, Max Matthews, John Mauchly, John McCarthy, Ed^ aly, Carver Mead Portraits William Melton, Robert JV hrvold Nicholas Negroponte in Allen Newell, Kenneth < ymour Papert Computing Suhas Patil, David Pattersoi Rick Rashid, Justin Rattner, Raj Reddy, Dennis Ritchie, izen, Benjamin Rosen, Harry Saal, Pamela Samuelson, J( chard Shaffer, John Shoch, Edward Shortliffe, Herbert S 1, Gary Starkweather, Ray Stata, George Stibitz, Michael ardTennant, Dorothy Terrell, Ken Thompson, Joseph Tr in von Neumann, Steven Walske, Charles Wang, John W ite, Ann Winblad, Steve Wozniak, William Wulf, John Yc Wizards and Their Wonders: Portraits in Computing Wizards and Their Wonders: Portraits in Computing is a tribute by The Computer Museum and the Association for Computing Machinery (ACM) to the many people who made the computer come alive in this century. It is unabashedly American in slant: the people in this book were either born in the United States or have done their major work there. -

Career Research Report Google and Cisco
Career Research Report Google and Cisco Prepared for Mahsa Modirzadeh, Professor Linguistics and Language Development Department San Jose State University Prepared by San Jose State University October 16, 2013 Pg. 1 TABLE OF CONTENTS Introduction……………………………………….……………………………………………….3 The Ideal Company……………………………….……………………………………………….3 Company I: Cisco…………………………………………………………………………………4 Background……………………………….……………………………………………….4 Products and Services…………………….……………………………………………….4 HR Work Culture…………….……………………………………………………………4 SWOT Analysis…….……………………………………………………………………..5 Company II: Google………….…………………………………………………………………...6 Background………………………………………………………………………………..6 Products and Services………………….………………………………………………….6 HR Work Culture……………………….…………………………………………………6 SWOT Analysis...………………….. ………………………………………………….....6 Conclusion………………………………………………………………………………………...8 Next Steps…………………………………………………………………………………………9 References………………………………………………………………………………………..10 Pg. 2 INTRODUCTION One of the most difficult decisions one has to make is the career path that they will take, and the right company to work for. It is essential for me to find a company that I would love to go to everyday because I believe that if you are happy at where you are working then you will exceed at your job naturally. Therefore, the purpose of this report is to discover a company that best suits my standards and criteria, from the company’s work environment to their size and location. Due to my major being business administration with a concentration in human resources management, I -

V3 Apr24'2019
Creando el artículo - V3 Apr24'2019 Contenido 1984 – 1995: Orígenes y crecimiento inicial 1996 – 2005: Inteligencia de Internet y del silicio 2006 – 2012: La red humana Actual día 1984 – 1995: Orígenes y crecimiento inicial Video El primer router de Cisco, el router del Advanced Gateway Server (AGS) (1986) Cisco Systems fue fundado en diciembre de 1984 por Sandy Lerner, un director de las instalaciones informáticas para la escuela del Stanford University del negocio. Lerner partnered con su marido, Leonard Bosack, que estaba responsable del computers.[6] del departamento de informática del Stanford University El producto inicial de Cisco tiene raíces en tecnología del campus de Stanford University. En los estudiantes y el personal tempranos de los años 80 en Stanford; incluyendo Bosack, tecnología usada en el campus para enlazar los sistemas informáticos de toda la escuela para hablar con uno otro, creando un cuadro que funcionó mientras que un router multiprotocolo llamó el “recuadro azul. “[7] el recuadro azul utilizó el software que fue escrito originalmente en Stanford por el ingeniero Guillermo Yeager.[7] de la investigación En 1985, el empleado Kirk Lougheed de Bosack y de Stanford comenzó un proyecto formalmente al campus.[7] de Stanford de la red que él adaptó el software de Yeager en qué se convirtió en la fundación para el Cisco IOS, a pesar de las demandas de Yeager que le habían negado el permiso para vender el recuadro azul comercialmente. En julio 11, 1986, Bosack y Lougheed fueron forzados a dimitir de Stanford y la universidad