C:\Papers\Ee\Idr\HLRS\Papers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

NYSTED KRØNIKEN 2006, Som I År Er Udgivet Af LOKALHISTORISK ARKIV I NYSTED, Beskrevet Og Redigeret Af John Voigt
NNYSTED KKRØNIKEN 22000066 Foto: John Voigt Fortalt af: John Voigt Udgivet i samarbejde med Lokalhistorisk Arkiv i Nysted Vejledende udsalgspris: kr. 90,- 1 F O R O R D: Velkommen til NYSTED KRØNIKEN 2006, som i år er udgivet af LOKALHISTORISK ARKIV I NYSTED, beskrevet og redigeret af John Voigt. Ved læsningen af NYSTED KRØNIKEN 2006 vil du igen få og opleve et aktuelt tidsbillede af livets gang i Nysted. Optegnelser, som fortæller om store og små tildragelser i vort lille samfund – alt som på en eller anden måde danner grundlag for vort virke i fremtiden. Husk – at det er i fortidens folder, at fremtiden ligger gemt. Og hvad har der så været af vigtige tildragelser i årets løb? Ja, lægesituationen i Nysted og de efterfølgende reaktioner må have første prioriteten. Herefter følger nok menighedsrådsbyggeriet og kommunesammenlægningen. Igen ved dette års udgivelse skal Lokalhistorisk Arkiv og forfatteren takke de mange medborgere i Nysted og omegn, som ved deres bidrag i form af supplerende oplysninger og billeder har medvirket ved udformningen af NYSTED KRØNIKEN 2006. Med håb og forventning til mange timers læsning – og snak i familierne - ønskes god fornøjelse med læsningen. 2 NYSTED KRØNIKEN Årgang 2006. Forfattet af: John Voigt 1. januar 2006. Nysted Kommune vil fra 1. januar 2007 være en del af Guldborgsund kommune og dermed ophøre som en selvstændig kommune. I århundrede har Nysted kommune – Danmarks sydligste Købstad - haft sin plads på landkortet og i historien. Omstruktureringer har præget tiden og kommunen har gennem årene været gennem mange og lange træk i sammenlægningsproblematikken – først i 1970-erne og nu senest her i 2005/06 – samt i den modernisering, der har været nødvendig for at kommunen fortsat kunne yde den bedste service til kommunens borgere. -

2004, Som Er Udgivet Af NYSTED KOMMUNE, Beskrevet Og Redigeret Af John Voigt
NNYSTED KKRØNIKEN 22000044 Foto: Lilli Nielsen. Fortalt af: John Voigt Udgivet af: NYSTED KOMMUNE Vejledende udsalgspris: kr. F O R O R D: Du sidder nu med NYSTED KRØNIKEN 2004, som er udgivet af NYSTED KOMMUNE, beskrevet og redigeret af John Voigt. Starten på NYSTED KRØNIKEN tog sin begyndelse i juli måned 1901, da dr. med og byrådsmedlem Carl Adam Hansen tog initiativ til at nedfælde en beskrivelse af Nysted. Dette skrift var begyndelsen på NYSTED KRØNIKEN, og for at bringe denne tradition ud til en større kreds af Nysted borgere og andre interessenter – har Nysted kommune taget initiativ til en videreførelse af denne. Carl Adam Hansens målsætninger om NYSTED KRØNIKEN er forsøgt fastholdt, nemlig: Den skal give et så fyldigt billede som muligt af livet i Nysted gennem årets gang, meddele nøjagtige og pålidelige oplysninger om dets forskellige fremtoninger og bevare mindet om mænd og kvinder, der have levet og virket i vort lille samfund, og skulle således afkræfte gyldigheden af de bekendte ord i visen: "Om hundred År er alting glemt". Man har bestræbt sig på, at give fremstillingen et objektivt præg og har søgt at holde sig til forskriften: " De mortnis nil nisi bene" efterrettelig, ligesom man også har afholdt sig fra kritik over de levende. Redaktøren har dog med velberådt hu hist og her ladet sin stemning og mening skinne igennem, så stilen på steder får en lidt mere subjektiv farvetone. Derved skulle læsningen blive mindre kedelig og trættende. Beskrivelsen er suppleret med billeder/fotografier af mænd og kvinder - både nulevende og afdøde - samt flere begivenheder, der er forekommet i årets løb. -

Southern Zealand
© Lonely Planet Publications 137 Southern Zealand Towns in this nontouristy region are primarily modern, and most people shoot through them on their way to the southern beaches or to Jutland. However, there are nuggets of gold to be panned from the gravel. Køge is the prettiest town in the area, a delightfully preserved cobbledy place, with a medieval church and half-timbered houses straight from the lid of a chocolate box. Nearby is the adorable hamlet of Vallø, with a fairy-tale moated castle complete with frogs on lily pads. The third historical settlement worth your time is Sorø, again rich in history and tilted wooden homes. Viking fans have a gem in the remains of 1000-year-old Trelleborg, the best-preserved ring fortress in Scandinavia. It’s an evocative site, deep in Denmark’s rural heart and pretty much unencumbered by modern buildings and roads – squint, and you can almost believe SOUTHERN ZEALAND yourself back in Harald Bluetooth’s time. If you have kids, then Næstved is a must. Within a radius of 10km you’ll find the theme park BonBon-Land; FantasyLand, an indoor playground for younger kids; Holmegaard Glassworks, where your young ‘uns can engrave their names on glass or blow their own masterpiece; Næstved Zoo; and child-friendly beaches at Karrebæksminde. The triangular region between Næstved in the south and Sorø and Korsør to the north is spotted with forests, small lakes and streams, as close to undomesticated nature as you’ll find in Zealand. Hire a canoe in Næstved and explore the waterways at your leisure. -

Supplementary to ``Eliciting Risk and Time Preferences''
Econometrica Supplementary Material SUPPLEMENTARY TO “ELICITING RISK AND TIME PREFERENCES” (Econometrica, Vol. 76, No. 3, May 2008, 583–618) BY STEFFEN ANDERSEN,GLENN W. H ARRISON,W.HARRISON, MORTEN I. LAU, AND E. ELISABET RUTSTRÖM Table of Contents Appendix A: Questionnaires . .......................................1 A.1 Part I of the Experiment: Socio-Demographic Questionnaire. .1 A.2QuestionnaireAboutPlansWithMoneyinIDRPart..............4 A.3PartIVoftheExperiment:QuestionnaireAboutFinances.........4 Appendix B: Sample Design . ..........................................14 B.1OverallDesign..................................................14 B.2ListofDanishMunicipalitiesandCountyCodes..................15 B.3MapofDenmark...............................................22 B.4RecruitmentProcedures.........................................23 B.5LettersofInvitationandCorrespondence........................27 Appendix C: Experimenter Script . .....................................30 Appendix D: Data and Statistical Analysis . ............................45 Appendix E: Theoretical Notes . ....................................46 APPENDIX A: QUESTIONNAIRES This appendix presents the survey questions asked of subjects in Parts I and IV of the experiment, as well as the data coding for responses. These are all translations of the original Danish, available on request. A.1. Part I of the Experiment: Socio-Demographic Questionnaire In this survey most of the questions asked are descriptive. The questions may seem personal, but they will help us analyze -
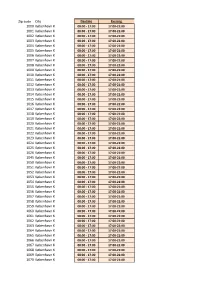
Zipcode Area Home Delivery Day and Evening.Xlsx
Zip code City Daytime Evening 1000 København K 08:00 - 17:00 17:00-21:00 1001 København K 08:00 - 17:00 17:00-21:00 1002 København K 08:00 - 17:00 17:00-21:00 1003 København K 08:00 - 17:00 17:00-21:00 1004 København K 08:00 - 17:00 17:00-21:00 1005 København K 08:00 - 17:00 17:00-21:00 1006 København K 08:00 - 17:00 17:00-21:00 1007 København K 08:00 - 17:00 17:00-21:00 1008 København K 08:00 - 17:00 17:00-21:00 1009 København K 08:00 - 17:00 17:00-21:00 1010 København K 08:00 - 17:00 17:00-21:00 1011 København K 08:00 - 17:00 17:00-21:00 1012 København K 08:00 - 17:00 17:00-21:00 1013 København K 08:00 - 17:00 17:00-21:00 1014 København K 08:00 - 17:00 17:00-21:00 1015 København K 08:00 - 17:00 17:00-21:00 1016 København K 08:00 - 17:00 17:00-21:00 1017 København K 08:00 - 17:00 17:00-21:00 1018 København K 08:00 - 17:00 17:00-21:00 1019 København K 08:00 - 17:00 17:00-21:00 1020 København K 08:00 - 17:00 17:00-21:00 1021 København K 08:00 - 17:00 17:00-21:00 1022 København K 08:00 - 17:00 17:00-21:00 1023 København K 08:00 - 17:00 17:00-21:00 1024 København K 08:00 - 17:00 17:00-21:00 1025 København K 08:00 - 17:00 17:00-21:00 1026 København K 08:00 - 17:00 17:00-21:00 1045 København K 08:00 - 17:00 17:00-21:00 1050 København K 08:00 - 17:00 17:00-21:00 1051 København K 08:00 - 17:00 17:00-21:00 1052 København K 08:00 - 17:00 17:00-21:00 1053 København K 08:00 - 17:00 17:00-21:00 1054 København K 08:00 - 17:00 17:00-21:00 1055 København K 08:00 - 17:00 17:00-21:00 1056 København K 08:00 - 17:00 17:00-21:00 1057 København K 08:00 - 17:00 -

Her Findes Teleslynge-Anlæg
Hvad er en teleslynge? En teleslynge er et høreteknisk hjælpemiddel. Når teleslyngen er tændt, forstærker den et givent lydsignal og sender det trådløst direkte til dit høreapparat. På denne måde kan teleslyngen være en hjælp til at høre, selv om der er afstand til lydkilden, dårlig akustik eller baggrundsstøj i lokalet. Hvem kan bruge en teleslynge? Du kan bruge en teleslynge, hvis der i dit høreapparat er telespole: programmet T eller M/T. Høreapparatet skal stilles på dette program, når du skal høre via teleslyngen. Hvor findes der teleslynge? Denne pjece giver en oversigt over offentligt tilgængelige lokaler med teleslynge i kommunerne: Næstved, Faxe, Vordingborg, Guldborgsund og Lolland. Kender du et sted, hvor der er en teleslynge, som ikke optræder i vores pjece, så ring venligst til ViSP - Videnscenter for Specialpædagogik eller send os en mail. Se vores kontaktoplysninger bag på pjecen. Næstved Kommune Bakkegården, Lovvej 3, Mogenstrup, Næstved (Sal og Café) BioCity Næstved, Fabriksvej 1, Næstved (i alle 6 sale) Fensmark Bibliotek/Borgerservice, Kildegårdsvej 56, Holmegaard Fugleparken, Nattergalevej 1, Fuglebjerg FuturaCaféen, Frivillighedscentret, Farimagsvej 22, Næstved Grønnegades Kaserne, Grønnegade 10, Næstved (Ny Ridehus og Musikstalden) Hovedbiblioteket/borgerservice, Kvægtorvet 4-6, Næstved Karrebæksminde Kursuscenter, Enø Kystvej 55, Karrebæksminde (Har ikke stationær teleslynge, men lejer efter behov) Menstrup Kro, Menstrup Bygade 29, Næstved (pris efter forbrug) Pejsestuen, Frivillighedscentret, Farimagsvej -

Akf Working Paper
10. august 2006 J.nr. 2740 ml/jp 33145949 ♪ 85 e-mail [email protected] Akf working paper Pendlingsoplande i Østdanmark af Morten Marott Larsen Indhold Summary ......................................................................................................................2 Forord...........................................................................................................................3 1. Indledning.............................................................................................................4 2. Hvordan defineres et pendlingsopland? ...............................................................4 3. Inddeling af Østdanmark i pendlingsoplande ......................................................6 4. Pendlingsoplande i Østdanmark opdelt på køn, alder og uddannelse..................9 5. Konklusion .........................................................................................................15 Bilag A .......................................................................................................................16 Bilagstabeller..............................................................................................................16 Referencer ..................................................................................................................22 Summary Commuting areas and the importance of labour force characteristics. Several studies have carried out delineations of Local Labour Market Areas (LLMA), but surpris- ingly few studies have considered the importance of the characteristics -
Resultatliste - Pistolterræn 18-10-2015
Resultatliste - Pistolterræn 18-10-2015 19-10-2015 20:13:16 - DDS SP v.3.15.10.1 RESULTATLISTE Pistolterræn 18-10-2015 5%-Skytte, Terrænskydning, Pistol cal. .22, 63 5%-Skytte, Terrænskydning, Grovvåben - GPA, 55 5%-Skytte, Terrænskydning, Grovvåben - GP32, 68 5%-Skytte, Terrænskydning, Grovvåben - GR, 55 Terrænskydning, Pistol cal. .22 - Klasse UNG 1 92240 Rasmus Wrønding 21-360 Københavns Amts Skyttelaug 60/27/18 2 53043 Simon Løje 23-040 Kongsted Skytteforening 47/20/19 3 56175 Mikkel Kristensen 23-014 Holmegaard Skytteforening 46/20/08 4 121977 Kasper Ringstrøm Madsen 17-318 Fløng-Hedehusene Skf. 26/12/08 5 96742 Morten Larsen 23-014 Holmegaard Skytteforening 25/11/00 6 92288 Anders Danielsen 23-035 Stege Ndr. Skytteforening 24/10/17 Terrænskydning, Pistol cal. .22 - Klasse 1 1 66086 Ejner Nicolaisen 18-048 Hørsholm Pistolforening 70/31/17 2 87057 Jonas Ørtoft Larsen 17-373 Ballerup Skf. 69/30/18 3 70806 Claudi Flørnæs 21-360 Københavns Amts Skyttelaug 67/29/16 4 56361 Kent Vincent Andersen 23-014 Holmegaard Skytteforening 66/29/19 5 91804 Morten Jensen 17-001 Slagelse Skytteforening 66/29/18 6 70304 Thomas Kofoed-Andersen 21-388 Skytteforening af 1949 65/28/18 7 56529 Finn Berg 17-374 Brøndby Skf. 64/28/16 8 59362 Dennis Samuelsen 17-003 Korsør Skytteforening 63/28/19 9 68155 Erling von Fuglsang 17-373 Ballerup Skf. 63/28/10 10 68358 Hans Jørgen Larsen 21-338 Hjortespring Skytte- & Idrætsf. 63/28/08 11 56382 Heidi Nyberg Hansen 23-014 Holmegaard Skytteforening 63/28/00 12 62650 Niels W. -
1. Geographic and Administrative Division of the Öresund Region in the Örestat Databank
Date: 15 May 2014 Author, Statistics Denmark: Michael Berg Rasmussen 1. Geographic and administrative division of the Öresund Region in the Örestat databank Geographic delimitation of The Örestat databank defines the Öresund Region as an area the Öresund Region comprising: In Denmark - Region Hovedstaden (Copenhagen Region) and Region Sjælland with municipalities (i.e. all Danish municipalities located east of the Great Belt). In Sweden – Skåne Län with municipalities Location of the Öresund Region Öresund statistics compiled In the Örestat databank, the statistics covering the Öresund Region are at 5 geographic levels compiled at 5 different levels: Municipality, province, region, main province and the total Öresund Region. To this is added, a metropolitan area for Malmø and the reference areas that make up parts of Denmark and Sweden located outside the Öresund Region. Municipality as the smallest The municipality is the smallest geographic unit in the Örestat databank. geographic unit In most tables, the statistical data are presented at this level. Applying Örestat databank’s aggregation tool opens up the possibility of undertaking summation of data at municipal level, to a higher geographic level (province, region, etc.) However, it should be noted that in cases where summation is meaningless (e.g. statistics showing unemployment rates, price indexes, and the like), undertaking summation is not possible. Statistics on levels of larger In some statistics, it is not possible to obtain statistics at municipal level, geographic units due to statistical uncertainty, non-disclosure practice, etc. Here, geographic areas, such as provinces (in Sweden called regional areas) regions and main provinces (in Sweden called provinces) are the smallest geographic building stones. -

Statistical Yearbook 2000 Income, Consumption and Prices Table 216 Total Family Income, by Type of Dwelling 1998
Income, consumption, and prices Income, consumption, and prices 1. Developments within income and consumption The distribution of income is an important indication of any imbalances in a society, and is vital to the opportunities for consumption available to various groups of the population. In 1998, the average personal income for persons aged 15 and above was DKK 189,000. Men had larger incomes than women, as the average income of men was DKK 224,900, while the average income of women was DKK 154,500. However, since 1984, women's incomes have increased at higher rates than men's: whereas men's incomes have increased by 68 per cent, women's incomes have increased by 97 per cent. Figure 1 Average personal income, by age group DKK thousands 300 250 200 1984 1998 150 100 50 0 1515---1818 2020- --2323 2525- --2828 3030- --3333 3535- --3838 4040- --4343 4545- --4848 5050- --5353 5555- --5858 6060- --6363 6565- --6868 7070- --7373 + 74 When considering personal incomes as they relate to socio-economic status, we see that only 4.5 per cent of all top-level managers (salaried employees at upper levels) made less than DKK 200,000 in 1998. When considering the other end of the scale, 93.1 per cent of all pensioners, 93.9 per cent of all unemployed people, and 99.8 per cent of all students had incomes of less than DKK 200,000. Income, consumption, and prices Figure 2 Personal income, by socio-economic status 1998 Others not economicalley active Pensioneers, etc. DKK 300 000 + Receiving education DKK 200 000 - 299 999 Unemployed DKK 100 000 - 199 999 Other employees < DKK 100 000 Employees, basic level Employees, medium level Employees, higher level Top managers Self-employed & ass. -

Notat Liste Over Modtagne Høringssvar, 1. Kontor
Trafikudvalget (2. samling) L 84 - Bilag 1 Offentligt Notat Trafikudvalget Dato : 23. februar 2005 J.nr. : SJ 400-1 Sagsbeh. : Org. enhed : 1. Kontor Liste over modtagne høringssvar, 1. kontor 1. Akademikernes Centralorganisation 2. Amtsrådsforeningen 3. Centralorganisationernes Fællesudvalg 4. Danmarks Transp ortForskning 5. Dansk Arbejdsgiverforening 6. Dansk Byggeri 7. Dansk Handel & Service 8. Dansk Industri 9. Dansk Landbrug (Medlem af Landbrugsrådet) 10. Dansk Transport og Logistik 11. Dansk Vejforening 12. Datatilsynet 13. Det Kommunale Kartel 14. Domstolsstyrelsen 15. Forbundet af Offentlige Ansatte (Medlem af Det Kommunale Ka r- tel) 16. FDM 17. Foreningen af Statsautoriserede Revisorer 18. Funktionærernes og Tjenestemændenes Fællesråd 19. Handel, Transport og Serviceerhvervene 20. KL 21. Rådet for Større Færdselssikkerhed 22. Aalborg Kommune 23. Bornholms Kommune 24. Bov Ko mmune 25. Bycirklen a. Ballerup Kommune b. Gundsø Kommune c. Ledøje Kommune d. Smørum Kommune c. Slangerup Kommune d. Frederikssund Kommune e. Jægerspris Kommune f. Skibby Kommune g. Ølstykke Kommune Side 2 af 4 26. Børkop Kommune 27. Egtved Komm une 28. Ejby Kommune 29. Erhvervsknudep unktet Hovedstadens Vestegn a. Albertslund Kommune b. Brøndby Kommune c. Glostrup Kommune d. Hvidovre Kommune e. Høje -Taastrup Kommune f. Ishøj Kommune g. Rødovre Kommune h. Vallensbæk Kommune i. Københavns Amt j. Arbejdsmarkedsrådet i Storkøbenhavn 30. Farum Kommune 31. Fladså Kommune 32. Foreningen af Kommuner i Københavns Amt a. Albertslund Kommune b. Ballerup Kommune c. Brøndby Kommune d. Dragør Kommune e. Gentofte Kommune f. Gladsaxe Kommune g. Glostrup Kommune h. Herlev Kommune i. Hvidovre Kommune j. Hø je -Taastrup Kommune k. Ishøj Kommune l. Ledøje -Smørum Kommune m. Lyngby -Taarbæk Ko mmune n. -

Let Your Local Shipping Company Handle Your Cargo
Let your local shipping company handle your cargo WE DO AGENCY AND STEVEDORING ACTIVITIES IN 9 HARBORS AT LOLLAND-FALSTER AND SOUTHERN ZEALAND Your Local Shipping Company Odense Slagelse Haslev Nyborg Korsr Store Boeslunde Fuglebjerg Heddinge Fyn Sklskr Holmegaard Faxe Faxe Nstved Ladeplads Hesselager Oure Prst Faaborg Svendobrg THIS IS WHERE WE OPERATE Mern Borre WE ARE Vordingborg Stege Klintholm THE KRINAK GROUP Rudkjbing Havn Trs Nrre Alslev Ærø Falster Langeland Bandholm Nakskov Sakskbing We have an extensive local knowledge on Lolland- Nykbing Dannemare Maribo Falster and Zealand, when it comes to Shipping, Trans- Falster port, Logistics, Loading/discharging of vessels, Office Lolland facilities, Warehouse facilities, Port adminstration, Vggerlse Weighing, Manpower and Agency. Rdby Nysted Marielyst Gedser Krinak A/S is a ship broker company established in 1919 with its headquarter in Nakskov. We operate in all ports of Lolland-Falster and Southern Zealand. We have a large local, Puttgarden national and international network, and are therefore able Femern to offer our customers the best solutions within shipping, logistics, door-door solutions, manpower etc. We prioritize We are located close to these security, service and quality at the highest level. new infrastructure projects: We have equipment for stevedoring and can therefore FEHMARNBELT CONNECTION handle project cargo, bulk goods and pallet goods with com- petent and experienced stevedore employees as coordina- STORSTRØMSBROEN tors. RAILWAY RINGSTED-FEHMARNBAHN. Krinak A/S is certified in accordance to ISO 9001:2015, We have many thousand square meters of ground GMP+B3/GMP+B4 certified and the Fonasba Quality Standard. facilities, offices, warehouse facilities and storage facilities on our harbours.