A Corpus-Based Approach to the Computational Modelling of Melody
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Press Release BHILWARA SUR SANGAM 2018
Press Release BHILWARA SUR SANGAM 2018 Bhilwara Sur Sangam, a rare initiative on promoting Indian classical music by LNJ Bhilwara Group, enters 7th edition New Delhi, April 22, 2018:One of Delhi’s most prestigious annual classical Indian music shows, Bhilwara Sur Sangam this year saw top artists including Padma Shri Pandit Venkatesh Kumar (Hindustani Classical Vocalist), Pandit Ajay Shankar Prasanna (Flute), Ustad Shujaat Hussain Khan (Sitar), ShriAbhishek Borkar (Sarod), perform and enthrall the audience. Organised every year by LNJ Bhilwara Group, Bhilwara Sur Sangam completed its 7th year this year and like every time left the audience spellbound by the ragas and jugalbandi of artists. This year the Sur Sangam was dedicated to Ganasarswati Kishori Amonkar, who incidentally performed her last stage show in this program in 2017. Shri Ravi Jhunjhunwala, Chairman, LNJ Bhilwara Group, and key architect of this cultural show, said, “Bhilwara Sur Sangam is our modest endeavor to spread the rich heritage of Indian classical music traditions. It is indeed heartening that in its seven years of existence many legendary artists of diverse classical traditions and genres have performed on this platform, and helped us reiterate the pride of our great classical traditions.” Started in 2012, this classical musical fest has over the years featured exceptional and legendary artists including Pt. Jasraj, Pt. Hari Prasad Chaurasia, Ustad Shahid Pravez Khan, Ustad Rashid Khan, Pt. Ulhas Kashalkar, Ustad Shujaat Husain Khan, Gaansaraswati Kishori Amonkar, Dr N Rajam, Pt. Kumar Bose, Pt. Anindo Chatterjee, Pt. Ajoy Chakraborty, Sushri Kaushiki Chakraborty, Dr Ashwani Bhide Deshpande, to name a few. -

Famous Indian Classical Musicians and Vocalists Free Static GK E-Book
oliveboard FREE eBooks FAMOUS INDIAN CLASSICAL MUSICIANS & VOCALISTS For All Banking and Government Exams Famous Indian Classical Musicians and Vocalists Free static GK e-book Current Affairs and General Awareness section is one of the most important and high scoring sections of any competitive exam like SBI PO, SSC-CGL, IBPS Clerk, IBPS SO, etc. Therefore, we regularly provide you with Free Static GK and Current Affairs related E-books for your preparation. In this section, questions related to Famous Indian Classical Musicians and Vocalists have been asked. Hence it becomes very important for all the candidates to be aware about all the Famous Indian Classical Musicians and Vocalists. In all the Bank and Government exams, every mark counts and even 1 mark can be the difference between success and failure. Therefore, to help you get these important marks we have created a Free E-book on Famous Indian Classical Musicians and Vocalists. The list of all the Famous Indian Classical Musicians and Vocalists is given in the following pages of this Free E-book on Famous Indian Classical Musicians and Vocalists. Sample Questions - Q. Ustad Allah Rakha played which of the following Musical Instrument? (a) Sitar (b) Sarod (c) Surbahar (d) Tabla Answer: Option D – Tabla Q. L. Subramaniam is famous for playing _________. (a) Saxophone (b) Violin (c) Mridangam (d) Flute Answer: Option B – Violin Famous Indian Classical Musicians and Vocalists Free static GK e-book Famous Indian Classical Musicians and Vocalists. Name Instrument Music Style Hindustani -

Categorization of Stringed Instruments with Multifractal Detrended Fluctuation Analysis
CATEGORIZATION OF STRINGED INSTRUMENTS WITH MULTIFRACTAL DETRENDED FLUCTUATION ANALYSIS Archi Banerjee*, Shankha Sanyal, Tarit Guhathakurata, Ranjan Sengupta and Dipak Ghosh Sir C.V. Raman Centre for Physics and Music Jadavpur University, Kolkata: 700032 *[email protected] * Corresponding Author ABSTRACT Categorization is crucial for content description in archiving of music signals. On many occasions, human brain fails to classify the instruments properly just by listening to their sounds which is evident from the human response data collected during our experiment. Some previous attempts to categorize several musical instruments using various linear analysis methods required a number of parameters to be determined. In this work, we attempted to categorize a number of string instruments according to their mode of playing using latest-state-of-the-art robust non-linear methods. For this, 30 second sound signals of 26 different string instruments from all over the world were analyzed with the help of non linear multifractal analysis (MFDFA) technique. The spectral width obtained from the MFDFA method gives an estimate of the complexity of the signal. From the variation of spectral width, we observed distinct clustering among the string instruments according to their mode of playing. Also there is an indication that similarity in the structural configuration of the instruments is playing a major role in the clustering of their spectral width. The observations and implications are discussed in detail. Keywords: String Instruments, Categorization, Fractal Analysis, MFDFA, Spectral Width INTRODUCTION Classification is one of the processes involved in audio content description. Audio signals can be classified according to miscellaneous criteria viz. speech, music, sound effects (or noises). -

A Salute to the Music Maestro Cherished Are Those Whose Creativity Adds Melody to the World
A Salute to the Music Maestro Cherished are those whose creativity adds melody to the world It were madness to paint the lily, count the stars, sweeten honey or to fathom Balmurali’s colossal genius These words have been dedicated to the musical genius, Palghat Mani Iyer, but today they apprise the multifaceted Carnatic vocalist, composer, and music guru, Mangalampalli Balamurali Krishna who passed away in Chennai at the age of 86, leaving an irreplaceable void in the realm of Indian Classical Music. The rich imprint of his magnificently rich voice, verses and innovated ragas & taalas live on. M Balamurali Krishna An insignia of illimitable creativity, Balamurali (6 July 1930 – 22 November 2016) Krishna kept the Indian classical tradition alive while modernizing the whole Carnatic music system to make it relatable to the common man. He was a disciple of Parupalli Ramakrishnayya Pantulu, a “I breathe music, think music, talk direct inheritor of the shishya parampara of Tyagaraja, music and music is my energy and I and performed the first full-fledged concert at a am an instrument of music” Thyagaraja Aradhana in Vijayawada at the age of eight. He also gave his first radio concert at the "I like to sing my own creations. tender age of nine and the astounding performance There is a different level of innovation placed him on the list of A-grade artists at the All that one can do with one's own India Radio (AIR), Chennai. A born experimentalist, he bequeathed a new horizon to the two rivulets of compositions. That's exciting. -

Godrej Consumer Products Limited
GODREJ CONSUMER PRODUCTS LIMITED List of shareholders in respect of whom dividend for the last seven consective years remains unpaid/unclaimed The Unclaimed Dividend amounts below for each shareholder is the sum of all Unclaimed Dividends for the period Nov 2009 to May 2016 of the respective shareholder. The equity shares held by each shareholder is as on Nov 11, 2016 Sr.No Folio Name of the Shareholder Address Number of Equity Total Dividend Amount shares due for remaining unclaimed (Rs.) transfer to IEPF 1 0024910 ROOP KISHORE SHAKERVA I R CONSTRUCTION CO LTD P O BOX # 3766 DAMMAM SAUDI ARABIA 180 6,120.00 2 0025470 JANAKIRAMA RAMAMURTHY KASSEMDARWISHFAKROO & SONS PO BOX 3898 DOHA QATAR 240 8,160.00 3 0025472 NARESH KUMAR MAHAJAN 176 HIGHLAND MEADOW CIRCLE COPPELL TEXAS U S A 240 8,160.00 4 0025645 KAPUR CHAND GUPTA C/O PT SOUTH PAC IFIC VISCOSE PB 11 PURWAKARTA WEST JAWA INDONESIA 360 12,240.00 5 0025925 JAGDISHCHANDRA SHUKLA C/O GEN ELECTRONICS & TDG CO PO BOX 4092 RUWI SULTANATE OF OMAN 240 8,160.00 6 0027324 HARISH KUMAR ARORA 24 STONEMOUNT TRAIL BRAMPTON ONTARIO CANADA L6R OR1 360 12,240.00 7 0028652 SANJAY VARNE SSB TOYOTA DIVI PO BOX 6168 RUWI AUDIT DEPT MUSCAT S OF OMAN 60 2,040.00 8 0028930 MOHAMMED HUSSAIN P A LEBANESE DAIRY COMPANY POST BOX NO 1079 AJMAN U A E 120 4,080.00 9 K006217 K C SAMUEL P O BOX 1956 AL JUBAIL 31951 KINGDOM OF SAUDI ARABIA 180 6,120.00 10 0001965 NIRMAL KUMAR JAIN DEP OF REVENUE [INCOMETAX] OFFICE OF THE TAX RECOVERY OFFICER 4 15/295A VAIBHAV 120 4,080.00 BHAWAN CIVIL LINES KANPUR 11 0005572 PRAVEEN -

Kothari International School Annual Academic Plan Subject-Hmv Grade-12 Session-2020-21 Weightage –Theory0-30 Marks
KOTHARI INTERNATIONAL SCHOOL ANNUAL ACADEMIC PLAN SUBJECT-HMV GRADE-12 SESSION-2020-21 WEIGHTAGE –THEORY0-30 MARKS /PRACTICAL-70 MARKS MONTH TOPIC SUB TOPICS BLOCK PERIODS MARCH THEORY- TO UNDERSTAND SHORT NOTES - THE MEANING & ALANKARA,VARNA,KA USE OF THESE 8.5 BLOCKS N,MEEND,KHATKA NOTES IN SINGING. APRIL RAGA BAGESHRI HOW TO SING SHORT NOTES- RAGA BAGESHRI 6 BLOCKS MURKI ,GAMAK WITH DRUTH LAYA ` TALA-DHAMAR RENDERING OF TAL BY HAND BEATS MAY LIFE SKETCH TO WRITE LIFE SANGEET PARIJAT SKETCH OF ABDUL DEFINITIONS- SADRA, KARIM KHAN & FAIYAJ 4.5 BLOCKS DADRA KHAN GRAM ,MURCHHANA ENABLE STUDENTS TO ,ALAP ,TANA APPLY THESE TERMS RAGA MALKOSH WHILE SINGING DRUT KHAYAL. TALA –JHAP TALA & TO STUDY RUPAK &UNDERSTAND TEEN 4.5 BLOCKS TAAL JULY TIME THEORY TO OF RAGA UNDERSTAND TALA-TILWADA THE VALUE OF THAH AND TIME IN RAGAS DUGUN TILWADA ON HAND BEATS SHORT HOW TO SING NOTE,VILAMBIT VILAMBIT 6 BLOCKS KHAYAL RAGA KHAHYALWITH BHAIRAV SIMPLE ELABORATIONS TALA DHAAMAR TO ENABLE STUDENTS HOW 6.5 BLOCKS LIFE SKETCH TO WRITE BADE NOTATION GULAMALI KHAN & TALA- KRISHNARAO DUGUN & THAH SHANKAR PANDIT AUGUST SHUDDHA AND TO UNDERSTAND VIKRIT SWARAS ABOUT SWARAS 6.5 BLOCKS RAGA BHAIRAV TO DEVELOP FOLK SONG PRACTICE OF BOOK -SANGEET SINGING RAGA RATNAKAR AND LIGHT MUSIC BRIEF STUDY OF BOOK. DHRUTH KHAYAL WITH ELLABORTATIONS 6.5 BLOCKS OF ALLAP,TAAN SEPTEMBER TO DEVELOP SHORT NOTES – KHAYAL 6 BLOCKS ALAP,TANA,SADRA,DADRA, SINGING STYLE GRAM,MURCHANA TALA TILWADA TO KNOW HOW VARIOUS PARTS OF TO SING DADRA 6 BLOCKS TANPURA TALA JHAPTAL,DHAMAR THAH ,DUGUN AND EKTAL CHAWGUNLAYA PRE – BOARD EXAMS OCTOBER PRE – BOARD EXAM 1 NOVEMBER PRE – BOARD EXAM 2 DECEMBER PRE – BOARD EXAM 3 . -

GURUJI Padmashree Pt. Ajoy Chakrabarty: As I Have Seen Him
GURUJI Padmashree Pt. Ajoy Chakrabarty: As I have seen Him Author- KAUSTUV KANTI GANGULI Department of Electrical Engineering, IIT Bombay & ITC Sangeet Research Academy, Kolkata [email protected]/[email protected]/[email protected] Phone- +919769753366 / +919830899474 An Article for- Samakalika Sangeetham: A ‘Sangeet Natak Academy’ Journal, October 2012 Issue GURUJI Padmashree Pt. Ajoy Chakrabarty: As I have seen Him Brief Bio-data of the Author KAUSTUV KANTI GANGULI, born on 8th June, 1990 in a musical family, had his initial lessons in vocal music at the age of 4 from his grandfather, Late Phanindra Mohan Ganguli & was encouraged by his father Shri Partha Sarathi Ganguli who learnt Sitar and mother Smt. Subhra Ganguli, vocal music. At the age of 7, Kaustuv became a student of SHRUTINANDAN from the year of its inception that is 1997. Since 2009, he is a Scholar at the ITC Sangeet Research Academy, Kolkata under the tutelage of GURUJI PANDIT AJOY CHAKRABARTY. Having done his schooling in ‘Ramakrishna Mission, Rahara’ & ‘St. Lawrence High School’, Kaustuv has done his B.Tech. in Electronics & Instrumentation Engineering under West Bengal University of Technology. He has also publications of papers in the proceedings of The National Conference, COIN-2011, The International Symposium FRSM-2012 and The West Bengal Science and Technology Congress 2012. He is now studying under the Department of Electrical Engineering, IIT Bombay as a Research Associate under the guidance of Prof. Preeti Rao. In music, Kaustuv got the first place in ‘Khayal’ both in Ravi Kichlu Foundation Talent Search 2003 and The Dover Lane Music Conference (Young Talent Search) 2008-09. -

Entrance Exaff Ination '?Otz PG Diploma in Health Communication Y -36
inl:. .'::i:-j].. " :,.a_.;;::..:a, . ',. :: -a ',i'-. ir: 'r - I ' :i '::: - t,; .t Entrance Exaff inatiOn '?Otz PG Diploma in Health Communication Y -36 Max, Martrrs: 75 Time:Z'Hours ,: GENERAL INSTRUCTIONS o Please read the instructions for each section carefully. o Enter your hall ticket nurnber on the guestion paper. OMe sheet and answif booklet without fail. o Please return the oMR sheet, Question Booklet and the Answer Book to the invigilator. o Read the instructions on the oMR sheet carefrrlly before proceeding.t. Answer all the 75 questions in PART A of"the question paper in the OUn rnu.t - All questions of PTART A carry equal negative marks. 0.33 marks will be subtracted for every wrong answer. o PART B fstatement of Purposel tt"r to" be *rio.n in the answer booklet. The questiin und.. PART B is mandatory and does not carry *"tl<s. Howe"u., y*r p"ffiffioi be evaluated if you "nydo not answer the question. TorAt NUMBER oF PAcEs ExctuDING THIS pAGE: 14 (FOURTEEN) PART A \ --z{ SECTION 1: GENERAL AWARENESS AND MEDIA AWARENESS (20 x 1= marks) 1. Who was recipient of the 59tr National Award in the BestActress category? (A) Priyanka Chopra (B)Vidya Balan (C) Rani Mukherjee (D) Kangana Ranaut 2. Which sports personality recently went through treatment for a life- threatening disease? (A)YuwajSingh (B) Baichung Bhutia (C) Gagan Narang (D) None ofthe above 3. The world's billionth baby was named (AJAfreen (B)famila (C) Falak (D) Nupur 4. What isthe capital offharkand? [A) Ranchi [B) lamshedpur (CJ Raipur (D) Dhantevada 5. -

HINDUSTANI MUSIC (Vocal)
H$moS> Z§. Code No. 33 /C amob Z§. narjmWu H$moS >H$mo CÎma-nwpñVH$m Ho$ _wI-n¥ð Roll No. >na Adí` {bIo§ & Candidates must write the Code on the title page of the answer-book. ZmoQ> NOTE (I) H¥$n`m Om±M H$a b| {H$ Bg àíZ-nÌ _o§ _w{ÐV (I) Please check that this question n¥ð> 7 h¢ & paper contains 7 printed pages. (II) àíZ-nÌ _| Xm{hZo hmW H$s Amoa {XE JE H$moS (II) Code number given on the right >Zå~a H$mo N>mÌ CÎma-nwpñVH$m Ho$ _wI-n¥ð> na hand side of the question paper {bI| & should be written on the title page of the answer-book by the candidate. (III) H¥$n`m Om±M H$a b| {H$ Bg àíZ-nÌ _| (III) Please check that this question >5 àíZ h¢ & paper contains 5 questions. (IV) H¥$n`m àíZ H$m CÎma {bIZm ewê$ H$aZo go (IV) Please write down the Serial nhbo, CÎma-nwpñVH$m _| àíZ H$m H«$_m§H$ Number of the question in the Adí` {bI| & answer-book before attempting it. (V) Bg àíZ-nÌ H$mo n‹T>Zo Ho$ {bE 15 {_ZQ >H$m (V) 15 minute time has been allotted to g_` {X`m J`m h¡ & àíZ-nÌ H$m {dVaU read this question paper. The nydm©• _| 10.15 ~Oo {H$`m OmEJm & question paper will be distributed at 10.15 a.m. From 10.15 a.m. -
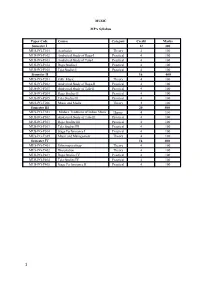
MUSIC MPA Syllabus Paper Code Course Category Credit Marks
MUSIC MPA Syllabus Paper Code Course Category Credit Marks Semester I 12 300 MUS-PG-T101 Aesthetics Theory 4 100 MUS-PG-P102 Analytical Study of Raga-I Practical 4 100 MUS-PG-P103 Analytical Study of Tala-I Practical 4 100 MUS-PG-P104 Raga Studies I Practical 4 100 MUS-PG-P105 Tala Studies I Practical 4 100 Semester II 16 400 MUS-PG-T201 Folk Music Theory 4 100 MUS-PG-P202 Analytical Study of Raga-II Practical 4 100 MUS-PG-P203 Analytical Study of Tala-II Practical 4 100 MUS-PG-P204 Raga Studies II Practical 4 100 MUS-PG-P205 Tala Studies II Practical 4 100 MUS-PG-T206 Music and Media Theory 4 100 Semester III 20 500 MUS-PG-T301 Modern Traditions of Indian Music Theory 4 100 MUS-PG-P302 Analytical Study of Tala-III Practical 4 100 MUS-PG-P303 Raga Studies III Practical 4 100 MUS-PG-P303 Tala Studies III Practical 4 100 MUS-PG-P304 Stage Performance I Practical 4 100 MUS-PG-T305 Music and Management Theory 4 100 Semester IV 16 400 MUS-PG-T401 Ethnomusicology Theory 4 100 MUS-PG-T402 Dissertation Theory 4 100 MUS-PG-P403 Raga Studies IV Practical 4 100 MUS-PG-P404 Tala Studies IV Practical 4 100 MUS-PG-P405 Stage Performance II Practical 4 100 1 Semester I MUS-PG-CT101:- Aesthetic Course Detail- The course will primarily provide an overview of music and allied issues like Aesthetics. The discussions will range from Rasa and its varieties [According to Bharat, Abhinavagupta, and others], thoughts of Rabindranath Tagore and Abanindranath Tagore on music to aesthetics and general comparative. -

This Article Has Been Made Available to SAWF by Dr. Veena Nayak. Dr. Nayak Has Translated It from the Original Marathi Article Written by Ramkrishna Baakre
This article has been made available to SAWF by Dr. Veena Nayak. Dr. Nayak has translated it from the original Marathi article written by Ramkrishna Baakre. From: Veena Nayak Subject: Dr. Vasantrao Deshpande - Part Two (Long!) Newsgroups: rec.music.indian.classical, rec.music.indian.misc Date: 2000/03/12 Presenting the second in a three-part series on this vocalist par excellence. It has been translated from a Marathi article by Ramkrishna Baakre. Baakre is also the author of 'Buzurg', a compilation of sketches of some of the grand old masters of music. In Part One, we got a glimpse of Vasantrao's childhood years and his early musical training. The article below takes up from the point where the first one ended (although there is some overlap). It discusses his influences and associations, his musical career and more importantly, reveals the generous and graceful spirit that lay behind the talent. The original article is rather desultory. I have, therefore, taken editorial liberties in the translation and rearranged some parts to smoothen the flow of ideas. I am very grateful to Aruna Donde and Ajay Nerurkar for their invaluable suggestions and corrections. Veena THE MUSICAL 'BRAHMAKAMAL' - Ramkrishna Baakre (translated by Dr. Veena Nayak) It was 1941. Despite the onset of November, winter had not made even a passing visit to Pune. In fact, during the evenings, one got the impression of a lazy October still lingering around. Pune has been described in many ways by many people, but to me it is the city of people with the habit of going for strolls in the morning and evening. -

Music from the Beginning
Review Article iMedPub Journals 2015 Insights in Blood Pressure http://journals.imedpub.com Vol. 1 No. 1:2 ISSN 2471-9897 Music and its Effect on Body, Brain/Mind: Archi Banerjee, Shankha A Study on Indian Perspective by Neuro- Sanyal, Ranjan Sengupta, Dipak Ghosh physical Approach Sir CV Raman Centre for Physics and Music, Jadavpur University, Kolkata Keywords: Music Cognition, Music Therapy, Diabetes, Blood Pressure, Neurocognitive Benefits Corresponding author: Archi Banerjee Received: Sep 20, 2015, Accepted: Sep 22, 2015, Submitted:Sep 29, 2015 [email protected] Music from the Beginning Sir CV Raman Centre for Physics and Music, The singing of the birds, the sounds of the endless waves of the Jadavpur University, Kolkata 700032. sea, the magical sounds of drops of rain falling on a tin roof, the murmur of trees, songs, the beautiful sounds produced by Tel: +919038569341 strumming the strings of musical instruments–these are all music. Some are produced by nature while others are produced by man. Natural sounds existed before human beings appeared Citation: Banerjee A, Sanyal S, Sengupta R, on earth. Was it music then or was it just mere sounds? Without et al. Music and its Effect on Body, Brain/ an appreciative mind, these sounds are meaningless. So music Mind: A Study on Indian Perspective by has meaning and music needs a mind to appreciate it. Neuro-physical Approach. Insights Blood Press 2015, 1:1. Music therefore may be defined as a form of auditory communication between the producer and the receiver. There are other forms of auditory communication, like speech, but the past and Raman, Kar followed by Rossing and Sundberg later on, difference is that music is more universal and evokes emotion.