NAB 2013 Paper
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Airpod Pro Making Weird Noise
1 / 2 Airpod-pro-making-weird-noise Jan 17, 2020 — A little while ago, they stopped doing that, which was really nice, but I didn't ... the loud engine noise and lets me better hear localizable sounds like tire swish. ... I currently cannot use my AirPods Pro in Noise Cancelling mode .... The left airpod makes a loud static wind-like sound whenever I use the passthrough mode or the noise cancelling mode. On the "none" mode. Everything is .... Like the H4n Pro, it doubles as an audio interface so you can record directly ... This cutoff at the low-end of the frequency spectrum can make someone with a low voice sound strange ... Feb 08, 2014 · Best thing to do is use headsets/airpods.. Been noticing a rattling noise in one side of AirPods Pro. Does hard reset/re-pair fix? Or is this an actual issue? 12:24 PM - 20 Feb 2020 from San Francisco, CA.. I have tried 2 different blue-tooth headsets, AirPod Pro and Beats. They both make a loud static noise after about 15/20 mins into a Zoom call. Once the noise ... Jan 19, 2020 — After leaving such a loud event, people tend to notice that they don't hear as well. ... Now, the noise cancellation of AirPods Pro does help reduce the ... AirPods are safe as long as people make sure not to repeatedly exceed .... Dec 20, 2019 — Whistling is one of them, and one redditor speculates it's all because the device tries to “protect your ears from loud high-pitch noises.” Others add ... -
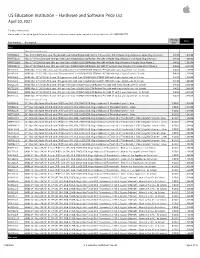
Apple US Education Price List
US Education Institution – Hardware and Software Price List April 30, 2021 For More Information: Please refer to the online Apple Store for Education Institutions: www.apple.com/education/pricelists or call 1-800-800-2775. Pricing Price Part Number Description Date iMac iMac with Intel processor MHK03LL/A iMac 21.5"/2.3GHz dual-core 7th-gen Intel Core i5/8GB/256GB SSD/Intel Iris Plus Graphics 640 w/Apple Magic Keyboard, Apple Magic Mouse 2 8/4/20 1,049.00 MXWT2LL/A iMac 27" 5K/3.1GHz 6-core 10th-gen Intel Core i5/8GB/256GB SSD/Radeon Pro 5300 w/Apple Magic Keyboard and Apple Magic Mouse 2 8/4/20 1,699.00 MXWU2LL/A iMac 27" 5K/3.3GHz 6-core 10th-gen Intel Core i5/8GB/512GB SSD/Radeon Pro 5300 w/Apple Magic Keyboard & Apple Magic Mouse 2 8/4/20 1,899.00 MXWV2LL/A iMac 27" 5K/3.8GHz 8-core 10th-gen Intel Core i7/8GB/512GB SSD/Radeon Pro 5500 XT w/Apple Magic Keyboard & Apple Magic Mouse 2 8/4/20 2,099.00 BR332LL/A BNDL iMac 21.5"/2.3GHz dual-core 7th-generation Core i5/8GB/256GB SSD/Intel IPG 640 with 3-year AppleCare+ for Schools 8/4/20 1,168.00 BR342LL/A BNDL iMac 21.5"/2.3GHz dual-core 7th-generation Core i5/8GB/256GB SSD/Intel IPG 640 with 4-year AppleCare+ for Schools 8/4/20 1,218.00 BR2P2LL/A BNDL iMac 27" 5K/3.1GHz 6-core 10th-generation Intel Core i5/8GB/256GB SSD/RP 5300 with 3-year AppleCare+ for Schools 8/4/20 1,818.00 BR2S2LL/A BNDL iMac 27" 5K/3.1GHz 6-core 10th-generation Intel Core i5/8GB/256GB SSD/RP 5300 with 4-year AppleCare+ for Schools 8/4/20 1,868.00 BR2Q2LL/A BNDL iMac 27" 5K/3.3GHz 6-core 10th-gen Intel Core i5/8GB/512GB -

US Education Institution Price List
US Education Institution – Hardware and Software Price List April 1, 2017 For More Information: Please refer to the online Apple Store for Education Institutions: www.apple.com/education/pricelists or call 1-800-800-2775. Pricing Price Part Number Description Date iMac MK142LL/A iMac 21.5"/1.6DC/8GB/1TB w/ Apple Magic Keyboard and Apple Magic Mouse 2 10/13/15 1,049.00 MK442LL/A iMac 21.5"/2.8QC/8GB/1TB w/ Apple Magic Keyboard and Apple Magic Mouse 2 10/13/15 1,249.00 MK452LL/A iMac 21.5"4K/3.1QC/8GB/1TB w/ Apple Magic Keyboard and Apple Magic Mouse 2 10/13/15 1,399.00 MK462LL/A iMac 27" 5K/3.2QC/8GB/1TB/M380 w/ Apple Magic Keyboard and Apple Magic Mouse 2 10/13/15 1,699.00 MK472LL/A iMac 27" 5K/3.2QC/8GB/1TB FD/M390 w/Apple Magic Keyboard & Apple Magic Mouse 2 10/13/15 1,899.00 MK482LL/A iMac 27" 5K/3.3QC/8GB/2TB FD/M395 w/Apple Magic Keyboard & Apple Magic Mouse 2 10/13/15 2,099.00 BLRU2LL/A BNDL iMac 21.5"/1.6DC/8GB/1TB with AppleCare Protection Plan 10/13/15 1,168.00 BLRV2LL/A BNDL iMac 21.5"/2.8QC/8GB/1TB APP with AppleCare Protection Plan 10/13/15 1,368.00 BLRW2LL/A BNDL iMac 21.5" 4K/3.1QC/8GB/1TB APP with AppleCare Protection Plan 10/13/15 1,518.00 BLRX2LL/A BNDL iMac 27" 5K/3.2QC/8GB/1TB/M380 APP with AppleCare Protection Plan 10/13/15 1,818.00 BLRY2LL/A BNDL iMac 27" 5K/3.2QC/8GB/1TBFD/M390APP with AppleCare Protection Plan 10/13/15 2,018.00 BLRZ2LL/A BNDL iMac 27" 5K/3.3QC/8GB/2TBFD/M395APP with AppleCare Protection Plan 10/13/15 2,218.00 Mac mini MGEM2LL/A Mac mini/1.4GHZ/4GB/500GB hard drive 10/16/14 479.00 MGEN2LL/A Mac mini/2.6GHZ/8GB/1TB -

US Education Institution Price List
US Education Institution – Hardware and Software Price List December 14, 2017 For More Information: Please refer to the online Apple Store for Education Institutions: www.apple.com/education/pricelists or call 1-800-800-2775. Pricing Price Part Number Description Date iMac MMQA2LL/A iMac 21.5"/2.3GHz dual-core Intel Core i5/8GB/1TB hard drive/Intel Iris Plus Graphics 640 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,049.00 MNDY2LL/A iMac 21.5" 4K/3.0GHz quad-core Intel Core i5/8GB/1TB hard drive/Radeon Pro 555 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,249.00 MNE02LL/A iMac 21.5" 4K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 560 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,399.00 MNE92LL/A iMac 27" 5K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 570 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,699.00 MNEA2LL/A iMac 27" 5K/3.5GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 575 w/Apple Magic Keyboard & Apple Magic Mouse 2 6/5/17 1,899.00 MNED2LL/A iMac 27" 5K/3.8GHz quad-core Intel Core i5/8GB/2TB Fusion drive/Radeon Pro 580 w/Apple Magic Keyboard & Apple Magic Mouse 2 6/5/17 2,099.00 BMPP2LL/A BNDL iMac 21.5"/2.3GHz dual-core Intel Core i5/8GB/1TB hard drive/Intel IPG 640 with AppleCare+ for Mac 6/5/17 1,168.00 BMPQ2LL/A BNDL iMac 21.5" 4K/3.0GHz quad-core Intel Core i5/8GB/1TB hard drive/RP 555 with AppleCare+ for Mac 6/5/17 1,368.00 BMPR2LL/A BNDL iMac 21.5" 4K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/RP 560 with AppleCare+ for Mac -

Apple Education Institution Price List
US Education Institution – Hardware and Software Price List July 7, 2017 For More Information: Please refer to the online Apple Store for Education Institutions: www.apple.com/education/pricelists or call 1-800-800-2775. Pricing Price Part Number Description Date iMac MMQA2LL/A iMac 21.5"/2.3GHz dual-core Intel Core i5/8GB/1TB hard drive/Intel Iris Plus Graphics 640 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,049.00 MNDY2LL/A iMac 21.5" 4K/3.0GHz quad-core Intel Core i5/8GB/1TB hard drive/Radeon Pro 555 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,249.00 MNE02LL/A iMac 21.5" 4K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 560 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,399.00 MNE92LL/A iMac 27" 5K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 570 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,699.00 MNEA2LL/A iMac 27" 5K/3.5GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 575 w/Apple Magic Keyboard & Apple Magic Mouse 2 6/5/17 1,899.00 MNED2LL/A iMac 27" 5K/3.8GHz quad-core Intel Core i5/8GB/2TB Fusion drive/Radeon Pro 580 w/Apple Magic Keyboard & Apple Magic Mouse 2 6/5/17 2,099.00 BMPP2LL/A BNDL iMac 21.5"/2.3GHz dual-core Intel Core i5/8GB/1TB hard drive/Intel IPG 640 with AppleCare+ for Mac 6/5/17 1,168.00 BMPQ2LL/A BNDL iMac 21.5" 4K/3.0GHz quad-core Intel Core i5/8GB/1TB hard drive/RP 555 with AppleCare+ for Mac 6/5/17 1,368.00 BMPR2LL/A BNDL iMac 21.5" 4K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/RP 560 with AppleCare+ for Mac 6/5/17 -

Apple US Education Institution Price List
US Education Institution – Hardware and Software Price List December 10, 2019 For More Information: Please refer to the online Apple Store for Education Institutions: www.apple.com/education/pricelists or call 1-800-800-2775. Pricing Price Part Number Description Date iMac MMQA2LL/A iMac 21.5"/2.3GHz dual-core 7th-gen Intel Core i5/8GB/1TB hard drive/Intel Iris Plus Graphics 640 w/Apple Magic Keyboard, Apple Magic Mouse 2 6/5/17 1,049.00 MRT32LL/A iMac 21.5" 4K/3.6GHz quad-core 8th-gen Intel Core i3/8GB/1TB hard drive/Radeon Pro 555X w/Apple Magic Keyboard and Apple Magic Mouse 2 3/19/19 1,249.00 MRT42LL/A iMac 21.5" 4K/3.0GHz 6-core 8th-gen Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 560X w/Apple Magic Keyboard and Apple Magic Mouse 2 3/19/19 1,399.00 MRQY2LL/A iMac 27" 5K/3.0GHz 6-core 8th-gen Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 570X w/Apple Magic Keyboard and Apple Magic Mouse 2 3/19/19 1,699.00 MRR02LL/A iMac 27" 5K/3.1GHz 6-core 8th-gen Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 575X w/Apple Magic Keyboard & Apple Magic Mouse 2 3/19/19 1,899.00 MRR12LL/A iMac 27" 5K/3.7GHz 6-core 8th-gen Intel Core i5/8GB/2TB Fusion drive/Radeon Pro 580X w/Apple Magic Keyboard & Apple Magic Mouse 2 3/19/19 2,099.00 BMPP2LL/A BNDL iMac 21.5"/2.3GHz dual-core 7th-generation Core i5/8GB/1TB hard drive/Intel IPG 640 with AppleCare+ for Mac 6/5/17 1,168.00 BNR82LL/A BNDL iMac 21.5" 4K/3.6GHz quad-core 8th-generation Intel Core i3/8GB/1TB hard drive/RP 555X with AppleCare+ for Mac 3/19/19 1,368.00 BNR92LL/A BNDL iMac 21.5" 4K/3.0GHz 6-core -

20180626 Mississippi ITS Apple Express Product List EPL 3774.Xlsx
Apple Inc. Mississippi ITS Apple Express Product List (EPL) 3774-A Effective June 2015 US Education Institution – Hardware and Software Price List Part Number Description Price iMac MMQA2LL/A iMac 21.5"/2.3GHz dual-core Intel Core i5/8GB/1TB hard drive/Intel Iris Plus Graphics 640 w/Apple Magic Keyboard and Apple Magic Mouse 2 1,049.00 MNDY2LL/A iMac 21.5" 4K/3.0GHz quad-core Intel Core i5/8GB/1TB hard drive/Radeon Pro 555 w/Apple Magic Keyboard and Apple Magic Mouse 2 1,249.00 MNE02LL/A iMac 21.5" 4K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 560 w/Apple Magic Keyboard and Apple Magic Mouse 2 1,399.00 MNE92LL/A iMac 27" 5K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 570 w/Apple Magic Keyboard and Apple Magic Mouse 2 1,699.00 MNEA2LL/A iMac 27" 5K/3.5GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 575 w/Apple Magic Keyboard & Apple Magic Mouse 2 1,899.00 MNED2LL/A iMac 27" 5K/3.8GHz quad-core Intel Core i5/8GB/2TB Fusion drive/Radeon Pro 580 w/Apple Magic Keyboard & Apple Magic Mouse 2 2,099.00 BMPP2LL/A BNDL iMac 21.5"/2.3GHz dual-core Intel Core i5/8GB/1TB hard drive/Intel IPG 640 with AppleCare+ for Mac 1,168.00 BMPQ2LL/A BNDL iMac 21.5" 4K/3.0GHz quad-core Intel Core i5/8GB/1TB hard drive/RP 555 with AppleCare+ for Mac 1,368.00 BMPR2LL/A BNDL iMac 21.5" 4K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/RP 560 with AppleCare+ for Mac 1,518.00 BMPS2LL/A BNDL iMac 27" 5K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/RP 570 with AppleCare+ for Mac 1,818.00 BMPT2LL/A BNDL iMac -

Apple Earpods Teardown Guide ID: 10501 - Draft: 2013-08-06
Apple EarPods Teardown Guide ID: 10501 - Draft: 2013-08-06 Apple EarPods Teardown Investigating the mysteries of the EarPods since September 16, 2012. Written By: Brett Hartt This document was generated on 2020-11-16 03:02:55 PM (MST). © iFixit — CC BY-NC-SA www.iFixit.com Page 1 of 14 Apple EarPods Teardown Guide ID: 10501 - Draft: 2013-08-06 INTRODUCTION After three years of research and development, Apple has released the newest version of their popular headphones, now dubbed "EarPods." Join us as we crack these pods open and take a look at what three years of R & D can accomplish. Love all of these gadget teardowns? Be sure to follow @ifixit and stay up to date on all the latest happenings from our teardown lab. TOOLS: Precision Utility Knife (1) iFixit Opening Picks set of 6 (1) Metal Spudger (1) This document was generated on 2020-11-16 03:02:55 PM (MST). © iFixit — CC BY-NC-SA www.iFixit.com Page 2 of 14 Apple EarPods Teardown Guide ID: 10501 - Draft: 2013-08-06 Step 1 — Apple EarPods Teardown What better accessory to accompany the new-and-improved iPhone than a set of new-and- improved headphones?!? Here are some of the hot new features on Apple's freshest auditory accessory: Redesigned case for improved in- ear fitment and sound distribution. Exterior acoustic vents for increased bass. In-line microphone and volume remote. Dual-material speaker diaphragms to cut sound loss and increase output. Standard issue with any new iPhone 5, iPod Touch 5th Generation, or iPod Nano 7th Generation. -

Apple US Education Price List
US Education Institution – Hardware and Software Price List October 30, 2018 For More Information: Please refer to the online Apple Store for Education Institutions: www.apple.com/education/pricelists or call 1-800-800-2775. Pricing Price Part Number Description Date iMac MMQA2LL/A iMac 21.5"/2.3GHz dual-core Intel Core i5/8GB/1TB hard drive/Intel Iris Plus Graphics 640 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,049.00 MNDY2LL/A iMac 21.5" 4K/3.0GHz quad-core Intel Core i5/8GB/1TB hard drive/Radeon Pro 555 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,249.00 MNE02LL/A iMac 21.5" 4K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 560 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,399.00 MNE92LL/A iMac 27" 5K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 570 w/Apple Magic Keyboard and Apple Magic Mouse 2 6/5/17 1,699.00 MNEA2LL/A iMac 27" 5K/3.5GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 575 w/Apple Magic Keyboard & Apple Magic Mouse 2 6/5/17 1,899.00 MNED2LL/A iMac 27" 5K/3.8GHz quad-core Intel Core i5/8GB/2TB Fusion drive/Radeon Pro 580 w/Apple Magic Keyboard & Apple Magic Mouse 2 6/5/17 2,099.00 BMPP2LL/A BNDL iMac 21.5"/2.3GHz dual-core Intel Core i5/8GB/1TB hard drive/Intel IPG 640 with AppleCare+ for Mac 6/5/17 1,168.00 BMPQ2LL/A BNDL iMac 21.5" 4K/3.0GHz quad-core Intel Core i5/8GB/1TB hard drive/RP 555 with AppleCare+ for Mac 6/5/17 1,368.00 BMPR2LL/A BNDL iMac 21.5" 4K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/RP 560 with AppleCare+ for Mac -

Wrap up the Best Deals on Great Gear
Wrapup the Best Deals on Great Gear p. 28–29 p. 12 p. 07 p. 45 FREE DELIVERY ON ORDERS $49+ p. 46 p. 44 AND MEMORY ORDERS $25+ p. 49 QUALITY SOLUTIONS. EXPERT SUPPORT. SINCE 1988. 1-800-275-4576 | +1-815-338-8685 | MACSALES.COM Table of Contents In terms of interesting, 2020 has to be high on airborne bacteria and viruses. We are proud the list. Not the kind of interesting we’d prefer, to report there has not been a single on-site and I suspect even less so by the time this infection/transmission throughout COVID-19 letter is published. That said, it should also and we’re going to keep it that way. 04 OWC Eclipse 40 Pre-owned Refurbished Macs be a time in history where we can appreciate the challenges we have prevailed through and Team members that can work from home do 05 Education: Thunderbolt 4 42 Solid State Drives create new hope and expectation for a far so. As a result, they have given us a wealth different, far better 2021. of information about the realities of working 06 Envoy Pro Storage 46 OWC Memory from home. Their firsthand experience has Throughout it all, we are glad to be here helped us more effectively address the 09 World’s First Products 48 2019 Mac Pro Upgrades for you. We have been able to pull out all concerns of all of those working and learning the stops to ensure the best solutions and remotely today. 10 ThunderBay Storage 50 2013 Mac Pro Upgrades experience for you, our customer. -

20170630 Mississippi ITS Apple Express Product List EPL 3774.Xlsx
Apple Inc. Mississippi ITS Apple Express Product List (EPL) 3774-A Effective June 2015 US Education Institution – Hardware and Software Price List Part Number Description Price iMac MMQA2LL/A iMac 21.5"/2.3GHz dual-core Intel Core i5/8GB/1TB hard drive/Intel Iris Plus Graphics 640 w/Apple Magic Keyboard and Apple Magic Mouse 2 1,049.00 MNDY2LL/A iMac 21.5" 4K/3.0GHz quad-core Intel Core i5/8GB/1TB hard drive/Radeon Pro 555 w/Apple Magic Keyboard and Apple Magic Mouse 2 1,249.00 MNE02LL/A iMac 21.5" 4K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 560 w/Apple Magic Keyboard and Apple Magic Mouse 2 1,399.00 MNE92LL/A iMac 27" 5K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 570 w/Apple Magic Keyboard and Apple Magic Mouse 2 1,699.00 MNEA2LL/A iMac 27" 5K/3.5GHz quad-core Intel Core i5/8GB/1TB Fusion drive/Radeon Pro 575 w/Apple Magic Keyboard & Apple Magic Mouse 2 1,899.00 MNED2LL/A iMac 27" 5K/3.8GHz quad-core Intel Core i5/8GB/2TB Fusion drive/Radeon Pro 580 w/Apple Magic Keyboard & Apple Magic Mouse 2 2,099.00 BMPP2LL/A BNDL iMac 21.5"/2.3GHz dual-core Intel Core i5/8GB/1TB hard drive/Intel IPG 640 with AppleCare+ for Mac 1,168.00 BMPQ2LL/A BNDL iMac 21.5" 4K/3.0GHz quad-core Intel Core i5/8GB/1TB hard drive/RP 555 with AppleCare+ for Mac 1,368.00 BMPR2LL/A BNDL iMac 21.5" 4K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/RP 560 with AppleCare+ for Mac 1,518.00 BMPS2LL/A BNDL iMac 27" 5K/3.4GHz quad-core Intel Core i5/8GB/1TB Fusion drive/RP 570 with AppleCare+ for Mac 1,818.00 BMPT2LL/A BNDL iMac -

Apple US Education Price List
US Education Institution – Hardware and Software Price List September 15, 2020 For More Information: Please refer to the online Apple Store for Education Institutions: www.apple.com/education/pricelists or call 1-800-800-2775. Pricing Price Part Number Description Date iMac MHK03LL/A iMac 21.5"/2.3GHz dual-core 7th-gen Intel Core i5/8GB/256GB SSD/Intel Iris Plus Graphics 640 w/Apple Magic Keyboard, Apple Magic Mouse 2 8/4/20 1,049.00 MHK23LL/A iMac 21.5" 4K/3.6GHz quad-core 8th-gen Intel Core i3/8GB/256GB SSD/Radeon Pro 555X w/Apple Magic Keyboard and Apple Magic Mouse 2 8/4/20 1,249.00 MHK33LL/A iMac 21.5" 4K/3.0GHz 6-core 8th-gen Intel Core i5/8GB/256GB SSD/Radeon Pro 560X w/Apple Magic Keyboard and Apple Magic Mouse 2 8/4/20 1,399.00 MXWT2LL/A iMac 27" 5K/3.1GHz 6-core 10th-gen Intel Core i5/8GB/256GB SSD/Radeon Pro 5300 w/Apple Magic Keyboard and Apple Magic Mouse 2 8/4/20 1,699.00 MXWU2LL/A iMac 27" 5K/3.3GHz 6-core 10th-gen Intel Core i5/8GB/512GB SSD/Radeon Pro 5300 w/Apple Magic Keyboard & Apple Magic Mouse 2 8/4/20 1,899.00 MXWV2LL/A iMac 27" 5K/3.8GHz 8-core 10th-gen Intel Core i7/8GB/512GB SSD/Radeon Pro 5500 XT w/Apple Magic Keyboard & Apple Magic Mouse 2 8/4/20 2,099.00 BR332LL/A BNDL iMac 21.5"/2.3GHz dual-core 7th-generation Core i5/8GB/256GB SSD/Intel IPG 640 with 3-year AppleCare+ for Schools 8/4/20 1,168.00 BR342LL/A BNDL iMac 21.5"/2.3GHz dual-core 7th-generation Core i5/8GB/256GB SSD/Intel IPG 640 with 4-year AppleCare+ for Schools 8/4/20 1,218.00 BR3G2LL/A BNDL iMac 21.5" 4K/3.6GHz quad-core 8th-gen Intel Core i3/8GB/256GB