IIRC: a Dataset of Incomplete Information Reading Comprehension Questions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Statement of Unclaimed Divided Amount for Theyear 2010-11
STATEMENT OF UNCLAIMED DIVIDED AMOUNT FOR THEYEAR 2010-11 Warrant Folio Name Amount 110 6 T V PRASADA RAO 520.00 3 11 ANIL KUMAR MANTRI 40.00 242 24 VANKATA RAO GUDURU 880.00 32 53 PAMPATI BALAJI 150.00 752 144 VINAY GUPTA 200.00 759 145 VIKAS GUPTA 200.00 897 186 RAVI KALRA 200.00 928 201 S PASCAL 200.00 936 203 AWTAR SINGH SODHI 200.00 948 207 YOUSA M 200.00 1026 238 OM PARKASH VIG 200.00 1034 241 NUTAN VERMA 200.00 1050 248 MANOJ KAPOOR 200.00 1109 274 RAGHUBIR SINGH RAWAT 200.00 1120 279 LAL DEVI 200.00 74 289 VAISHAK SHARES LIMITED 2.00 1154 299 K RAVISHANKAR 200.00 82 351 DOCTOR ZOHAIR 200.00 1262 357 JAGDISH RAI 200.00 83 361 KAILASH BHAGIRATH SAMDANI 40.00 1288 370 INDU JAIN 200.00 1310 379 ADESH CHAUDHARY 200.00 1381 427 HARISH CHHABRA 200.00 1453 477 ARVINDER KAUR 200.00 1473 490 SHARAD AGARWAL 200.00 1490 503 BHAGAT RAM SARDA 200.00 1516 523 KRISHNA GUPTA 200.00 1523 528 PRABHU DAYAL GUPTA 200.00 1525 529 CHINNAMMA MOVVA 200.00 1536 544 MUSHEER AHMAD 200.00 1551 555 SARITA DEVI TULSYAN 200.00 1584 578 SUSHILA AGARWAL 200.00 1588 583 SHAILOO PAHWA 200.00 1603 594 ARTI 200.00 1651 637 GYAN CHANDRA PANDEY 200.00 122 680 MUKESH KUMAR JAIN 40.00 1761 719 RAJIV SAXENA 200.00 1762 720 K C KHANDELWAL 200.00 1770 727 SYED AHMED RIZVI 200.00 128 731 NULI LAKSHMANA SWAMY NULI 30.00 1783 733 RENU BANSAL 200.00 1790 737 SURENDRA KUMAR SAXENA 200.00 1821 758 RENU AGARWAL 200.00 1845 782 KRISHNA CHANDRA YADAVA PWI 200.00 1857 791 JAI PRAKASH NARAIN DUBEY 200.00 1862 797 PRAKASH SONI 200.00 1894 826 RADHA DEVI 200.00 1902 830 VISHVA RAMAN -

List of Successful Candidates
11 - LIST OF SUCCESSFUL CANDIDATES CONSTITUENCY WINNER PARTY Andhra Pradesh 1 Nagarkurnool Dr. Manda Jagannath INC 2 Nalgonda Gutha Sukender Reddy INC 3 Bhongir Komatireddy Raj Gopal Reddy INC 4 Warangal Rajaiah Siricilla INC 5 Mahabubabad P. Balram INC 6 Khammam Nama Nageswara Rao TDP 7 Aruku Kishore Chandra Suryanarayana INC Deo Vyricherla 8 Srikakulam Killi Krupa Rani INC 9 Vizianagaram Jhansi Lakshmi Botcha INC 10 Visakhapatnam Daggubati Purandeswari INC 11 Anakapalli Sabbam Hari INC 12 Kakinada M.M.Pallamraju INC 13 Amalapuram G.V.Harsha Kumar INC 14 Rajahmundry Aruna Kumar Vundavalli INC 15 Narsapuram Bapiraju Kanumuru INC 16 Eluru Kavuri Sambasiva Rao INC 17 Machilipatnam Konakalla Narayana Rao TDP 18 Vijayawada Lagadapati Raja Gopal INC 19 Guntur Rayapati Sambasiva Rao INC 20 Narasaraopet Modugula Venugopala Reddy TDP 21 Bapatla Panabaka Lakshmi INC 22 Ongole Magunta Srinivasulu Reddy INC 23 Nandyal S.P.Y.Reddy INC 24 Kurnool Kotla Jaya Surya Prakash Reddy INC 25 Anantapur Anantha Venkata Rami Reddy INC 26 Hindupur Kristappa Nimmala TDP 27 Kadapa Y.S. Jagan Mohan Reddy INC 28 Nellore Mekapati Rajamohan Reddy INC 29 Tirupati Chinta Mohan INC 30 Rajampet Annayyagari Sai Prathap INC 31 Chittoor Naramalli Sivaprasad TDP 32 Adilabad Rathod Ramesh TDP 33 Peddapalle Dr.G.Vivekanand INC 34 Karimnagar Ponnam Prabhakar INC 35 Nizamabad Madhu Yaskhi Goud INC 36 Zahirabad Suresh Kumar Shetkar INC 37 Medak Vijaya Shanthi .M TRS 38 Malkajgiri Sarvey Sathyanarayana INC 39 Secundrabad Anjan Kumar Yadav M INC 40 Hyderabad Asaduddin Owaisi AIMIM 41 Chelvella Jaipal Reddy Sudini INC 1 GENERAL ELECTIONS,INDIA 2009 LIST OF SUCCESSFUL CANDIDATE CONSTITUENCY WINNER PARTY Andhra Pradesh 42 Mahbubnagar K. -

National Conference On
REPORT NATIONAL CONFERENCE CHILDREN IN DISASTERS & EMERGENCIES: UNDERSTANDING VULNERABILITY, DEVELOPING CAPACITIES & PROMOTING RESILIENCE March 08-10, 2021 Organized By CHILD CENTRIC DISASTER RISK REDUCTION CENTRE (CCDRR), NIDM & SAVE THE CHILDREN Knowledge Partners 1 CHILDREN IN DISASTERS & EMERGENCIES: UNDERSTANDING VULNERABILITY, DEVELOPING CAPACITIES & PROMOTING RESILIENCE “CHILDREN CAN’T WAIT” CONTENTS S. No. Topic Pg. No 1 About the Conference 03 - 06 2 Programme & Session Schedule 07 - 10 3 Inaugural Session 11 - 13 4 Context Setting Session 13 - 15 5 Day 1 - Theme: Understanding Vulnerabilities – Protecting 15 - 16 Children in All Context of Disasters & Emergencies 6 Day 2 - Theme: Developing Capacities – All Children are 17 - 26 Safe, Learn and Thrive 7 Day 3 – Theme: Promoting Resilience – Commitment to 27 - 36 Reaching the Most Marginalised and Vulnerable Children 8 Valedictory Session 36 - 38 9 Summary of Recommendations 39 - 41 10 Profile of Speakers and Domain Experts 42 - 51 11 Profile of Programme Convenor & Coordinators 52 - 53 12 Annexure 1: List of Participants 54 - 151 2 1. About the Conference 1.1 BACKGROUND India is vulnerable to a large number of hazards which is compounded by increasing vulnerabilities related to changing demographics and socio-economic conditions, unplanned urbanization, development within high-risk zones, environmental degradation, climate change, geological hazards, epidemics and pandemics. This poses a serious threat to India’s overall economy, its population and sustainable development. Vulnerability from disasters varies from one community to the other and in space. Community’s preparedness always plays an important role in reducing disasters and emergency risk and vulnerability. India’s total Child population is (164.5 million1) as compared to the total 328.46 million2 US population; more than half of the total US population. -
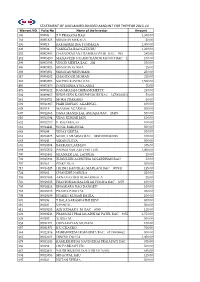
STATEMENT of UNCLAIMED DIVIDED AMOUNT for THEYEAR 2013-14 Warrant NO
STATEMENT OF UNCLAIMED DIVIDED AMOUNT FOR THEYEAR 2013-14 Warrant NO. Folio No Name of the Investor Amount 106 000006 T V PRASADA RAO 1,300.00 188 00001823 SRINIVAS MEKALA 20.00 191 000019 RAMAKRISHNA TUMMALA 1,000.00 220 000024 VANKATA RAO GUDURU 2,200.00 252 00002988 CHANDRAKANT RAMDAS PATIL BAC. 933 245.00 282 00003450 MAHAVEER UTTAMCHANDJI MUNOT BAC. 13 100.00 299 00003795 VINOD MEHTA BAC. 204 500.00 306 00003928 SRINIVAS KOTHA 25.00 308 00003951 SRINIVAS SIRIPURAM 250.00 317 00004202 CHANDOOR MOHAN 225.00 342 00004908 SACHIN KASERA BAC. 7,500.00 450 00007870 PUSPENDRA Y SOLANKI 75.00 473 00008512 KANAKAIAH CHIRAMCHETTY 250.00 504 00009457 REKHABEN KAMLESH MODI BAC. 14700100210 50.00 561 00010711 MOKA PRAKASH 50.00 602 00011887 HARI KISHAN AGARWAL . 100.00 603 000119 MANISH AGARWAL 500.00 607 00012063 DAXA MANEKLAL ASHARA BAC. 25455 500.00 610 00012094 VIJAY KUMAR JAIN 100.00 622 00012717 E. RAJAMOULI 100.00 661 00014241 SUNIL BAKLIWAL 500.00 663 000144 VINAY GUPTA 500.00 668 00014473 SUNITA SHARMA BAC. 043010100242943 100.00 669 000145 VIKAS GUPTA 500.00 681 00014904 BAKKAM LAXMAN 375.00 689 00015312 PADMA SAILAJA CHITLURI 1,000.00 700 00015881 SHANKER LAL LADDHA 15.00 703 00015936 TUMULURI ACHUTHA JANARDHAN RAO 50.00 707 000161 PINKY DUA 500.00 717 00016425 HITESH KANTILAL MADLANI BAC. 007841 125.00 724 000165 CHANDER NARULA 500.00 755 00017685 ARNAVAZ BEJI BUHARIWALA 25.00 766 00018025 PRAVINBHAI BALUBHAI POKIYA BAC. 6070 100.00 780 00018518 BHASKARA RAO DANGETI 100.00 783 00018713 PRADEEP MITTAL 250.00 793 00019199 SUMEET KUMAR BATRA 100.00 801 000196 T BALA SARASWATHI DEVI 500.00 810 000201 S PASCAL 500.00 811 00020153 AJIT KUMAR S. -

Nominations for Padma Awards 2011
c Nominations fof'P AWARDs 2011 ADMA ~ . - - , ' ",::i Sl. Name';' Field State No ShriIshwarappa,GurapJla Angadi Art Karnataka " Art-'Cinema-Costume Smt. Bhanu Rajopadhye Atharya Maharashtra 2. Designing " Art - Hindustani 3. Dr; (Smt.).Prabha Atre Maharashtra , " Classical Vocal Music 4. Shri Bhikari.Charan Bal Art - Vocal Music 0, nssa·' 5. Shri SamikBandyopadhyay Art - Theatre West Bengal " 6: Ms. Uttara Baokar ',' Art - Theatre , Maharashtra , 7. Smt. UshaBarle Art Chhattisgarh 8. Smt. Dipali Barthakur Art " Assam Shri Jahnu Barua Art - Cinema Assam 9. , ' , 10. Shri Neel PawanBaruah Art Assam Art- Cinema Ii. Ms. Mubarak Begum Rajasthan i", Playback Singing , , , 12. ShriBenoy Krishen Behl Art- Photography Delhi " ,'C 13. Ms. Ritu Beri , Art FashionDesigner Delhi 14. Shri.Madhur Bhandarkar Art - Cinema Maharashtra Art - Classical Dancer IS. Smt. Mangala Bhatt Andhra Pradesh Kathak Art - Classical Dancer 16. ShriRaghav Raj Bhatt Andhra Pradesh Kathak : Art - Indian Folk I 17., Smt. Basanti Bisht Uttarakhand Music Art - Painting and 18. Shri Sobha Brahma Assam Sculpture , Art - Instrumental 19. ShriV.S..K. Chakrapani Delhi, , Music- Violin , PanditDevabrata Chaudhuri alias Debu ' Art - Instrumental 20. , Delhi Chaudhri ,Music - Sitar 21. Ms. Priyanka Chopra Art _Cinema' Maharashtra 22. Ms. Neelam Mansingh Chowdhry Art_ Theatre Chandigarh , ' ,I 23. Shri Jogen Chowdhury Art- Painting \VesfBengal 24.' Smt. Prafulla Dahanukar Art ~ Painting Maharashtra ' . 25. Ms. Yashodhara Dalmia Art - Art History Delhi Art - ChhauDance 26. Shri Makar Dhwaj Darogha Jharkhand Seraikella style 27. Shri Jatin Das Art - Painting Delhi, 28. Shri ManoharDas " Art Chhattisgarh ' 29. , ShriRamesh Deo Art -'Cinema ,Maharashtra Art 'C Hindustani 30. Dr. Ashwini Raja Bhide Deshpande Maharashtra " classical vocalist " , 31. ShriDeva Art - Music Tamil Nadu Art- Manipuri Dance 32. -

Unclaimed-Dividend-2
STATEMENT OF UNCLAIMED DIVIDED AMOUNT FOR THEYEAR 2012-13 WARRANT NO. FOLIO NO. NAME AMOUNT 91 000006 T V PRASADA RAO 1,040.00 107 00000777 MUKESHKUMAR BALCHAND SANGHAVI 400.00 115 00000946 BHUSHAN LAL CHADHA 400.00 132 00001132 ANUP RAMCHAND RADHAKRISHNANI 80.00 158 00001626 ISHWARA RAMA BHAT 24.00 172 000019 RAMAKRISHNA TUMMALA 800.00 181 00001973 SANDEEP DAGHDU SHINDE 200.00 190 00002109 MUKESHKUMAR BALCHAND SANGHVI HUF 800.00 203 000024 VANKATA RAO GUDURU 1,760.00 232 00002988 CHANDRAKANT RAMDAS PATIL 196.00 275 00003732 DEVENDRA ZARKAR 400.00 308 00004509 MANJI JADAVA PINDORIYA 400.00 310 00004522 ROHIT CHAWLA 40.00 321 00004853 S.D.GUNASEKARAN . 80.00 337 00005482 PRATAP KHANNA 200.00 401 00007152 INDU MITHAL 160.00 481 00009379 MANJU JOHARI 80.00 486 00009457 REKHABEN KAMLESH MODI 40.00 487 00009542 SAMAY PAL SINGH 400.00 539 00010597 MINABEN MUKESHKUMAR GOPANI 80.00 541 00010711 MOKA PRAKASH 40.00 584 000119 MANISH AGARWAL 400.00 591 00012094 VIJAY KUMAR JAIN 80.00 626 00013711 K KRISHNA RAO 400.00 642 000144 VINAY GUPTA 400.00 645 00014473 SUNITA SHARMA 80.00 646 000145 VIKAS GUPTA 400.00 659 00014904 BAKKAM LAXMAN 200.00 665 00015087 PRADIP LALCHAND SHAH 80.00 667 00015121 RAJKANVAR SARDA . 16.00 671 00015312 PADMA SAILAJA CHITLURI 800.00 687 00015881 SHANKER LAL LADDHA 12.00 689 00015936 TUMULURI ACHUTHA JANARDHAN RAO 40.00 690 00015951 Kanchedilal Jain 400.00 706 000165 CHANDER NARULA 400.00 708 000166 RAM SARUP KHANNA 400.00 722 000171 RUCHITA SABHARWAL 400.00 727 00017249 MADHU SUDAN KUMAR 800.00 738 00017685 ARNAVAZ BEJI BUHARIWALA 20.00 747 00018025 PRAVINBHAI BALUBHAI POKIYA 80.00 755 00018518 BHASKARA RAO DANGETI 80.00 760 00018713 PRADEEP MITTAL 200.00 766 00019178 VIMALA DEVI 400.00 767 00019199 SUMEET KUMAR BATRA 80.00 784 000201 S PASCAL 400.00 785 00020153 AJIT KUMAR S. -
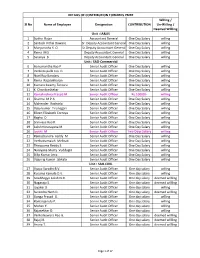
Sl No Name of Employee Designation CONTRIBUTION Willing / Un
DETAILS OF CONTRIBUTION TOWARDS PMRF Willing / Sl No Name of Employee Designation CONTRIBUTION Un-Willing / Deemed Willling Unit : IA&AS 1 Sudha Rajan Accountant General One Day Salary willing 2 Santosh Vithal Daware Sr. Deputy Accountant General One Day Salary willing 3 Manjunatha K O Sr.Deputy Accountant General One Day Salary willing 4 Rema M S Deputy Accountant General One Day Salary willing 5 Saranya B Deputy Accountant General One Day Salary willing Unit : SAO-Commercial 6 Hanumantha Rao P Senior Audit Officer One Day Salary willing 7 Venkata pulla rao G Senior Audit Officer One Day Salary willing 8 Noel Roy Bandaru Senior Audit Officer One Day Salary willing 9 Rema Rajasekharan Senior Audit Officer One Day Salary willing 10 Kumara Swamy Tanniru Senior Audit Officer One Day Salary willing 11 K Chandrashekar Senior Audit Officer One Day Salary willing 12 Ramakrishna Prasad M Senior Audit Officer Rs.10000/- willing 13 Sharma M P A Senior Audit Officer One Day Salary willing 14 Mahender Racharla Senior Audit Officer One Day Salary willing 15 Vijay kumar Tirunagari Senior Audit Officer One Day Salary willing 16 Eileen Elizabeth Correya Senior Audit Officer One Day Salary willing 17 Raghu D Senior Audit Officer One Day Salary willing 18 Srinivasa Rao K Senior Audit Officer One Day Salary willing 19 Lakshminarayana M Senior Audit Officer One Day Salary willing 20 Jyothi M Senior Audit Officer Two Days Salary willing 21 Ramachandra reddy M Senior Audit Officer One Day Salary willing 22 Venkatramaiah Melinati Senior Audit Officer One Day Salary willing 23 Thirupama Reddy S Senior Audit Officer One Day Salary willing 24 Narayana Murty Vuddagiri Senior Audit Officer One Day Salary willing 25 Dilip Kumar Jena Senior Audit Officer One Day Salary willing 26 Vijay raj kumar Jakkala Senior Audit Officer One Day Salary willing Unit : SAO-CIVIL 27 Vijaya Saradhi B.V. -

Grand Alliance in up Weighs On
CHENNAI BusinessLine 18 POLLSCAPE WEDNESDAY • APRIL 24 • 2019 Grand Alliance in UP weighs on BJP Mubarakpur’s silk industry pines for Caste arithmetic the surface, aligned in support of ity of heart and a will to serve lost sheen, hopes for revival of fortunes the SP. But ever since I have star people,” Pratapgarhi said after a and consolidation ted campaigning, I have realised massive roadshow in the SHISHIR SINHA that the local people, whether Moradabad city on the last day of Azamgarh, April 23 of minority votes Think of Banaras, one thing Hindus or Muslims, will support the campaign. that immediately comes to pose challenge to me. He has called me names, In the neighbouring Lok mind is the Banarasi sari . tried to humiliate me and the Sabha seat of Sambhal, SP vet PM’s popularity However, not many will people are ready to give him a be eran Shafiqur Rehman Barq lost know that the root of a fitting answer,” Jaya Prada told to Satyapal Saini of the BJP in 2014 Banarasi sarilies in Mubarak POORNIMA JOSHI BusinessLine. by a margin of 4,932 votes. The pur, 13 km from district Rampur, April 23 In Moradabad, the State Minis BSP secured 2,52,640 votes. This headquarter of Azamgarh. The fastemerging story of Uttar ter with Independent Charge of time, because of the SPBSP alli Once you reach Mubarak Pradesh in the ongoing Lok Voters wait in long queues to cast their vote at a polling station in Panchayati Raj, Chaudhary Bhu ance, Barq’s chances are said to pur, you will notice a sign Sabha elections is the nailbiting Moradabad on Tuesday PTI pendra Singh, disclosed how the very high. -

St. Ann's College of Engineering & Technology : Chirala List of Selected Students in Phase-1
St. Ann's College of Engineering & Technology : Chirala List of selected students in Phase-1 Branch Sno NAME Father's Name Mother's Name GENDER Category Alloted VIRUPAKSHAPURAM 1 VIRUPAKSHAPURAM SAIKUMAR VIRUPAKSHAPURAM CHECHITHA M BC_A AIML SUBRAMANYAM 2 DOGUPARTHY RENUKA KRISHNA DOGUPARTHY JAYA KRISHNA NASIKA GEERVANI F BC_B AIML 3 VELADANDI SOUMITH VELADANDI PRASAD VELADANDI JAYA PRADA F BC_B AIML 4 BADISA NAVEEN KUMAR BADISA SIVAPRASAD BADISA RAMADEVI M BC-B AIML 5 ASODI AVINASH REDDY ASODI SUBBAREDDY ASODI SAVITRI M OC AIML 6 ASADI MANIKANTA ASADI VENKATESWARLU REDDY ASADI MADHAVI M OC AIML 7 NANDYALA YUVA PRASANTH NANDYALA SRINIVASA RAO NANDYALA KALYANI M OC AIML 8 VUTUKURI NAGASHALINI VUTUKURI SEETHAIAH GUPTHA VUTUKURI NAGA PADMA PRIYA F OC AIML 9 MUTTINENI MANI TEJA MUTTINENI TIRUMALA RAO MUTTINENI NAGA SULOCHANA M OC AIML BABDARU VENKATA SRINIVASA 10 BANDARU SAI VENKAT BABDARU RAMA DEVI M OC AIML RAO VENKATA SUBBA RAO 11 GNANA SRIVALLI KOTHAMASU NEELIMA KOTHAMASU F OC AIML KOTHAMASU 12 NANDURU YAMINI KALYANI VEERANJANEYULU NAGA MANI F OC AIML VASAMSETTI LAKSHMI VENKATA SIVA 13 VASAMSETTI SRINIVAS VASAMSETTI KUMARI M BC_B CIV KUMAR 14 IMADABATTUNI VAMSI DURGA RAO IMADABATTUNI NARASIMHA RAO IMADABATTUNI LAKSHMANA REKHA M CIV 15 ANNAM BHARGAV ANNAM SRINIVASA RAO ANNAM SUBHASHINI M BC_A CIV 16 UTUKURI VENKATESH UTUKURI THIRUPATHI VENKAIAH VUTUKURI YANADAMMA M BC-D CIV 17 AATLA SIVA SAI KRISHNA REDDY AATLA KRISHNA REDDY AATLA KOTESWARI M OC CIV 18 DEVARAKONDA AKASH DEVARAKONDA NAGAIAH PERAM MALLESWARI M ST CIV 19 KATEMPUDI SURESH -

1St Filmfare Awards 1953
FILMFARE NOMINEES AND WINNER FILMFARE NOMINEES AND WINNER................................................................................ 1 1st Filmfare Awards 1953.......................................................................................................... 3 2nd Filmfare Awards 1954......................................................................................................... 3 3rd Filmfare Awards 1955 ......................................................................................................... 4 4th Filmfare Awards 1956.......................................................................................................... 5 5th Filmfare Awards 1957.......................................................................................................... 6 6th Filmfare Awards 1958.......................................................................................................... 7 7th Filmfare Awards 1959.......................................................................................................... 9 8th Filmfare Awards 1960........................................................................................................ 11 9th Filmfare Awards 1961........................................................................................................ 13 10th Filmfare Awards 1962...................................................................................................... 15 11st Filmfare Awards 1963..................................................................................................... -

12 CHAPTER 6.Pdf
135 The ‘moving pictures’ or movies, or films, or cinema came into the global entertainment arena with a storm in the early 20 th century. While the initial efforts were ‘silent’ with live music played and dialogues spoken from the ‘pit’, as the filming technology developed, ‘sub -titles’ came in, displayed within the frame itself. And then it was only a matter of time before sound could be incorporated in the framework, with the actors ‘talking’, thus leading to the new form being also called ‘talkies’. Cinema had its roots in theatre, but combined dramatic narration, song and music, dance and performance. The fact that it allowed multiple screenings at a fraction of the cost of going to a theatre performance, made it an extraordinarily popular medium with the classes and the masses. Unlike in Western (American and European) cinema, song and dance hardly played any role except in a genre called the ‘musical’, in Indian cinema, song and dance are an integral part of the film, often taking the narrative forward in a significant way. In fact, song and dance from Bollywood films also have a life of their own outside the film. In India, movie- making quickly became a huge industry, with Hindi language cinema establishing its roots in Mumbai (Bollywood). But also steadily, film-making in regional languages became equally if not more popular. In this process, many theatre actors as well as trained classical dancers, also made their transition to this new medium which made them better known amongst the masses and earned them much more money than theatre did. -

Township: Vernon Board of Review
Board of Review - Docket Book Township: Vernon 2020 Owner Agent PIN Case # Pre-BOR AV Increase Decrease BOR AV Land Use Code Withdrawn Residential KANAKIS, JR, CHARLES 1501201047 20016442 317,750 0 0 317,750 Improvements Residential YI, SEUNG Y LINN, SCOTT 1501201056 20031651 317,388 0 25,750 291,638 Improvements Residential SIEBER, JAMES E KAMEGO, KYLE 1501201073 20026921 255,974 0 0 255,974 Improvements Residential CORTRIGHT, ADAM J KAMEGO, KYLE 1501201074 20020874 188,662 0 12,370 176,292 Improvements Residential URASKI, THERESE SCHAEFGES, RYAN 1501201082 20034115 262,947 0 12,472 250,475 Improvements Residential SHERRY A GIMBEL TR DTD 12/29/17 1501202044 20033407 266,690 0 31,713 234,977 Improvements JOANNE MICHAEL MARTIN TTEES Residential KINGSLEY, RONALD 1501202049 20031242 342,529 0 39,226 303,303 UTD 5-23-1 Improvements Residential SIEGEL, SHERWIN KAMEGO, KYLE 1501202050 20026917 316,363 0 0 316,363 Improvements Residential CHRISTOPHER SHOUP PIERSON, CRAIG 1501202052 20033175 281,787 0 21,813 259,974 Improvements Residential TANEY, WILLIAM GAIL 1501202054 20019983 236,374 0 19,729 216,645 Improvements Residential WHITE, JOHN KAMEGO, KYLE 1501202066 20026060 385,756 0 5,158 380,598 Improvements Residential DONATO, MICHAEL P ANDRE, MICHAEL 1501202072 20031547 415,327 0 47,346 367,981 Improvements Residential A. HARRIS WALKER, TRUSTEE KINGSLEY, RONALD 1501202082 20024179 288,534 0 10,228 278,306 Improvements Residential PICHIETTI, MARY C FISHBEIN, LISA 1501202083 20028665 235,200 0 17,983 217,217 Improvements SUZANNE V PATRICK J