Understanding Basic Calculus
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Notes on Calculus II Integral Calculus Miguel A. Lerma
Notes on Calculus II Integral Calculus Miguel A. Lerma November 22, 2002 Contents Introduction 5 Chapter 1. Integrals 6 1.1. Areas and Distances. The Definite Integral 6 1.2. The Evaluation Theorem 11 1.3. The Fundamental Theorem of Calculus 14 1.4. The Substitution Rule 16 1.5. Integration by Parts 21 1.6. Trigonometric Integrals and Trigonometric Substitutions 26 1.7. Partial Fractions 32 1.8. Integration using Tables and CAS 39 1.9. Numerical Integration 41 1.10. Improper Integrals 46 Chapter 2. Applications of Integration 50 2.1. More about Areas 50 2.2. Volumes 52 2.3. Arc Length, Parametric Curves 57 2.4. Average Value of a Function (Mean Value Theorem) 61 2.5. Applications to Physics and Engineering 63 2.6. Probability 69 Chapter 3. Differential Equations 74 3.1. Differential Equations and Separable Equations 74 3.2. Directional Fields and Euler’s Method 78 3.3. Exponential Growth and Decay 80 Chapter 4. Infinite Sequences and Series 83 4.1. Sequences 83 4.2. Series 88 4.3. The Integral and Comparison Tests 92 4.4. Other Convergence Tests 96 4.5. Power Series 98 4.6. Representation of Functions as Power Series 100 4.7. Taylor and MacLaurin Series 103 3 CONTENTS 4 4.8. Applications of Taylor Polynomials 109 Appendix A. Hyperbolic Functions 113 A.1. Hyperbolic Functions 113 Appendix B. Various Formulas 118 B.1. Summation Formulas 118 Appendix C. Table of Integrals 119 Introduction These notes are intended to be a summary of the main ideas in course MATH 214-2: Integral Calculus. -

Thermodynamics of Spacetime: the Einstein Equation of State
gr-qc/9504004 UMDGR-95-114 Thermodynamics of Spacetime: The Einstein Equation of State Ted Jacobson Department of Physics, University of Maryland College Park, MD 20742-4111, USA [email protected] Abstract The Einstein equation is derived from the proportionality of entropy and horizon area together with the fundamental relation δQ = T dS connecting heat, entropy, and temperature. The key idea is to demand that this relation hold for all the local Rindler causal horizons through each spacetime point, with δQ and T interpreted as the energy flux and Unruh temperature seen by an accelerated observer just inside the horizon. This requires that gravitational lensing by matter energy distorts the causal structure of spacetime in just such a way that the Einstein equation holds. Viewed in this way, the Einstein equation is an equation of state. This perspective suggests that it may be no more appropriate to canonically quantize the Einstein equation than it would be to quantize the wave equation for sound in air. arXiv:gr-qc/9504004v2 6 Jun 1995 The four laws of black hole mechanics, which are analogous to those of thermodynamics, were originally derived from the classical Einstein equation[1]. With the discovery of the quantum Hawking radiation[2], it became clear that the analogy is in fact an identity. How did classical General Relativity know that horizon area would turn out to be a form of entropy, and that surface gravity is a temperature? In this letter I will answer that question by turning the logic around and deriving the Einstein equation from the propor- tionality of entropy and horizon area together with the fundamental relation δQ = T dS connecting heat Q, entropy S, and temperature T . -

Antiderivatives and the Area Problem
Chapter 7 antiderivatives and the area problem Let me begin by defining the terms in the title: 1. an antiderivative of f is another function F such that F 0 = f. 2. the area problem is: ”find the area of a shape in the plane" This chapter is concerned with understanding the area problem and then solving it through the fundamental theorem of calculus(FTC). We begin by discussing antiderivatives. At first glance it is not at all obvious this has to do with the area problem. However, antiderivatives do solve a number of interesting physical problems so we ought to consider them if only for that reason. The beginning of the chapter is devoted to understanding the type of question which an antiderivative solves as well as how to perform a number of basic indefinite integrals. Once all of this is accomplished we then turn to the area problem. To understand the area problem carefully we'll need to think some about the concepts of finite sums, se- quences and limits of sequences. These concepts are quite natural and we will see that the theory for these is easily transferred from some of our earlier work. Once the limit of a sequence and a number of its basic prop- erties are established we then define area and the definite integral. Finally, the remainder of the chapter is devoted to understanding the fundamental theorem of calculus and how it is applied to solve definite integrals. I have attempted to be rigorous in this chapter, however, you should understand that there are superior treatments of integration(Riemann-Stieltjes, Lesbeque etc..) which cover a greater variety of functions in a more logically complete fashion. -

Introduction Into Quaternions for Spacecraft Attitude Representation
Introduction into quaternions for spacecraft attitude representation Dipl. -Ing. Karsten Groÿekatthöfer, Dr. -Ing. Zizung Yoon Technical University of Berlin Department of Astronautics and Aeronautics Berlin, Germany May 31, 2012 Abstract The purpose of this paper is to provide a straight-forward and practical introduction to quaternion operation and calculation for rigid-body attitude representation. Therefore the basic quaternion denition as well as transformation rules and conversion rules to or from other attitude representation parameters are summarized. The quaternion computation rules are supported by practical examples to make each step comprehensible. 1 Introduction Quaternions are widely used as attitude represenation parameter of rigid bodies such as space- crafts. This is due to the fact that quaternion inherently come along with some advantages such as no singularity and computationally less intense compared to other attitude parameters such as Euler angles or a direction cosine matrix. Mainly, quaternions are used to • Parameterize a spacecraft's attitude with respect to reference coordinate system, • Propagate the attitude from one moment to the next by integrating the spacecraft equa- tions of motion, • Perform a coordinate transformation: e.g. calculate a vector in body xed frame from a (by measurement) known vector in inertial frame. However, dierent references use several notations and rules to represent and handle attitude in terms of quaternions, which might be confusing for newcomers [5], [4]. Therefore this article gives a straight-forward and clearly notated introduction into the subject of quaternions for attitude representation. The attitude of a spacecraft is its rotational orientation in space relative to a dened reference coordinate system. -

Anti-Chain Rule Name
Anti-Chain Rule Name: The most fundamental rule for computing derivatives in calculus is the Chain Rule, from which all other differentiation rules are derived. In words, the Chain Rule states that, to differentiate f(g(x)), differentiate the outside function f and multiply by the derivative of the inside function g, so that d f(g(x)) = f 0(g(x)) · g0(x): dx The Chain Rule makes computation of nearly all derivatives fairly easy. It is tempting to think that there should be an Anti-Chain Rule that makes antidiffer- entiation as easy as the Chain Rule made differentiation. Such a rule would just reverse the process, so instead of differentiating f and multiplying by g0, we would antidifferentiate f and divide by g0. In symbols, Z F (g(x)) f(g(x)) dx = + C: g0(x) Unfortunately, the Anti-Chain Rule does not exist because the formula above is not Z always true. For example, consider (x2 + 1)2 dx. We can compute this integral (correctly) by expanding and applying the power rule: Z Z (x2 + 1)2 dx = x4 + 2x2 + 1 dx x5 2x3 = + + x + C 5 3 However, we could also think about our integrand above as f(g(x)) with f(x) = x2 and g(x) = x2 + 1. Then we have F (x) = x3=3 and g0(x) = 2x, so the Anti-Chain Rule would predict that Z F (g(x)) (x2 + 1)2 dx = + C g0(x) (x2 + 1)3 = + C 3 · 2x x6 + 3x4 + 3x2 + 1 = + C 6x x5 x3 x 1 = + + + + C 6 2 2 6x Since these answers are different, we conclude that the Anti-Chain Rule has failed us. -

A Brief Tour of Vector Calculus
A BRIEF TOUR OF VECTOR CALCULUS A. HAVENS Contents 0 Prelude ii 1 Directional Derivatives, the Gradient and the Del Operator 1 1.1 Conceptual Review: Directional Derivatives and the Gradient........... 1 1.2 The Gradient as a Vector Field............................ 5 1.3 The Gradient Flow and Critical Points ....................... 10 1.4 The Del Operator and the Gradient in Other Coordinates*............ 17 1.5 Problems........................................ 21 2 Vector Fields in Low Dimensions 26 2 3 2.1 General Vector Fields in Domains of R and R . 26 2.2 Flows and Integral Curves .............................. 31 2.3 Conservative Vector Fields and Potentials...................... 32 2.4 Vector Fields from Frames*.............................. 37 2.5 Divergence, Curl, Jacobians, and the Laplacian................... 41 2.6 Parametrized Surfaces and Coordinate Vector Fields*............... 48 2.7 Tangent Vectors, Normal Vectors, and Orientations*................ 52 2.8 Problems........................................ 58 3 Line Integrals 66 3.1 Defining Scalar Line Integrals............................. 66 3.2 Line Integrals in Vector Fields ............................ 75 3.3 Work in a Force Field................................. 78 3.4 The Fundamental Theorem of Line Integrals .................... 79 3.5 Motion in Conservative Force Fields Conserves Energy .............. 81 3.6 Path Independence and Corollaries of the Fundamental Theorem......... 82 3.7 Green's Theorem.................................... 84 3.8 Problems........................................ 89 4 Surface Integrals, Flux, and Fundamental Theorems 93 4.1 Surface Integrals of Scalar Fields........................... 93 4.2 Flux........................................... 96 4.3 The Gradient, Divergence, and Curl Operators Via Limits* . 103 4.4 The Stokes-Kelvin Theorem..............................108 4.5 The Divergence Theorem ...............................112 4.6 Problems........................................114 List of Figures 117 i 11/14/19 Multivariate Calculus: Vector Calculus Havens 0. -

Differentiation Rules (Differential Calculus)
Differentiation Rules (Differential Calculus) 1. Notation The derivative of a function f with respect to one independent variable (usually x or t) is a function that will be denoted by D f . Note that f (x) and (D f )(x) are the values of these functions at x. 2. Alternate Notations for (D f )(x) d d f (x) d f 0 (1) For functions f in one variable, x, alternate notations are: Dx f (x), dx f (x), dx , dx (x), f (x), f (x). The “(x)” part might be dropped although technically this changes the meaning: f is the name of a function, dy 0 whereas f (x) is the value of it at x. If y = f (x), then Dxy, dx , y , etc. can be used. If the variable t represents time then Dt f can be written f˙. The differential, “d f ”, and the change in f ,“D f ”, are related to the derivative but have special meanings and are never used to indicate ordinary differentiation. dy 0 Historical note: Newton used y,˙ while Leibniz used dx . About a century later Lagrange introduced y and Arbogast introduced the operator notation D. 3. Domains The domain of D f is always a subset of the domain of f . The conventional domain of f , if f (x) is given by an algebraic expression, is all values of x for which the expression is defined and results in a real number. If f has the conventional domain, then D f usually, but not always, has conventional domain. Exceptions are noted below. -
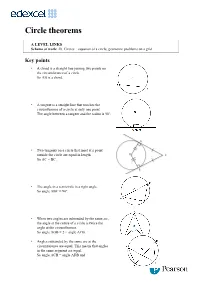
Circle Theorems
Circle theorems A LEVEL LINKS Scheme of work: 2b. Circles – equation of a circle, geometric problems on a grid Key points • A chord is a straight line joining two points on the circumference of a circle. So AB is a chord. • A tangent is a straight line that touches the circumference of a circle at only one point. The angle between a tangent and the radius is 90°. • Two tangents on a circle that meet at a point outside the circle are equal in length. So AC = BC. • The angle in a semicircle is a right angle. So angle ABC = 90°. • When two angles are subtended by the same arc, the angle at the centre of a circle is twice the angle at the circumference. So angle AOB = 2 × angle ACB. • Angles subtended by the same arc at the circumference are equal. This means that angles in the same segment are equal. So angle ACB = angle ADB and angle CAD = angle CBD. • A cyclic quadrilateral is a quadrilateral with all four vertices on the circumference of a circle. Opposite angles in a cyclic quadrilateral total 180°. So x + y = 180° and p + q = 180°. • The angle between a tangent and chord is equal to the angle in the alternate segment, this is known as the alternate segment theorem. So angle BAT = angle ACB. Examples Example 1 Work out the size of each angle marked with a letter. Give reasons for your answers. Angle a = 360° − 92° 1 The angles in a full turn total 360°. = 268° as the angles in a full turn total 360°. -

9.2. Undoing the Chain Rule
< Previous Section Home Next Section > 9.2. Undoing the Chain Rule This chapter focuses on finding accumulation functions in closed form when we know its rate of change function. We’ve seen that 1) an accumulation function in closed form is advantageous for quickly and easily generating many values of the accumulating quantity, and 2) the key to finding accumulation functions in closed form is the Fundamental Theorem of Calculus. The FTC says that an accumulation function is the antiderivative of the given rate of change function (because rate of change is the derivative of accumulation). In Chapter 6, we developed many derivative rules for quickly finding closed form rate of change functions from closed form accumulation functions. We also made a connection between the form of a rate of change function and the form of the accumulation function from which it was derived. Rather than inventing a whole new set of techniques for finding antiderivatives, our mindset as much as possible will be to use our derivatives rules in reverse to find antiderivatives. We worked hard to develop the derivative rules, so let’s keep using them to find antiderivatives! Thus, whenever you have a rate of change function f and are charged with finding its antiderivative, you should frame the task with the question “What function has f as its derivative?” For simple rate of change functions, this is easy, as long as you know your derivative rules well enough to apply them in reverse. For example, given a rate of change function …. … 2x, what function has 2x as its derivative? i.e. -

Arithmetic Algorisms in Different Bases
Arithmetic Algorisms in Different Bases The Addition Algorithm Addition Algorithm - continued To add in any base – Step 1 14 Step 2 1 Arithmetic Algorithms in – Add the digits in the “ones ”column to • Add the digits in the “base” 14 + 32 5 find the number of “1s”. column. + 32 2 + 4 = 6 5 Different Bases • If the number is less than the base place – If the sum is less than the base 1 the number under the right hand column. 6 > 5 enter under the “base” column. • If the number is greater than or equal to – If the sum is greater than or equal 1+1+3 = 5 the base, express the number as a base 6 = 11 to the base express the sum as a Addition, Subtraction, 5 5 = 10 5 numeral. The first digit indicates the base numeral. Carry the first digit Multiplication and Division number of the base in the sum so carry Place 1 under to the “base squared” column and Carry the 1 five to the that digit to the “base” column and write 4 + 2 and carry place the second digit under the 52 column. the second digit under the right hand the 1 five to the “base” column. Place 0 under the column. “fives” column Step 3 “five” column • Repeat this process to the end. The sum is 101 5 Text Chapter 4 – Section 4 No in-class assignment problem In-class Assignment 20 - 1 Example of Addition The Subtraction Algorithm A Subtraction Problem 4 9 352 Find: 1 • 3 + 2 = 5 < 6 →no Subtraction in any base, b 35 2 • 2−4 can not do. -

Section 3.7 Notes
Section 3.7 Notes Rational Functions 1 Introduction Definition • A rational function is fraction of two polynomials. 2x2 − 1 • For example, f(x) = is a rational function. 3x2 + 2x − 5 Properties of Rational Graphs • The graph of every rational function is smooth (no sharp corners) • However, many rational functions are discontinuous . In other words, the graph might have several separate \sections" to the graph, similar to the way piecewise functions look. 1 For example, remember the graph of f(x) = x : Notice how the graph is drawn in two separate pieces. Asymptotes • An asymptote to a function is a line which the function gets closer and closer to without touching. • Rational functions have two categories of asymptote: 1. vertical asymptotes 2. asymptotes which determine the end behavior - these could be either horizontal asymp- totes or slant asymptotes Vertical Asymptote Horizontal Slant Asymptote Asymptote 1 2 Vertical Asymptotes Description • A vertical asymptote of a rational function is a vertical line which the graph never crosses, but does get closer and closer to. • Rational functions can have any number of vertical asymptotes • The number of vertical asymptotes determines the number of \pieces" the graph has. Since the graph will never cross any vertical asymptotes, there will be separate pieces between and on the sides of all the vertical asymptotes. Finding Vertical Asymptotes 1. Factor the denominator. 2. Set each factor equal to zero and solve. The locations of the vertical asymptotes are nothing more than the x-values where the function is undefined. Behavior Near Vertical Asymptotes The multiplicity of the vertical asymptote determines the behavior of the graph near the asymptote: Multiplicity Behavior even The two sides of the asymptote match - they both go up or both go down. -

Angles ANGLE Topics • Coterminal Angles • Defintion of an Angle
Angles ANGLE Topics • Coterminal Angles • Defintion of an angle • Decimal degrees to degrees, minutes, seconds by hand using the TI-82 or TI-83 Plus • Degrees, seconds, minutes changed to decimal degree by hand using the TI-82 or TI-83 Plus • Standard position of an angle • Positive and Negative angles ___________________________________________________________________________ Definition: Angle An angle is created when a half-ray (the initial side of the angle) is drawn out of a single point (the vertex of the angle) and the ray is rotated around the point to another location (becoming the terminal side of the angle). An angle is created when a half-ray (initial side of angle) A: vertex point of angle is drawn out of a single point (vertex) AB: Initial side of angle. and the ray is rotated around the point to AC: Terminal side of angle another location (becoming the terminal side of the angle). Hence angle A is created (also called angle BAC) STANDARD POSITION An angle is in "standard position" when the vertex is at the origin and the initial side of the angle is along the positive x-axis. Recall: polynomials in algebra have a standard form (all the terms have to be listed with the term having the highest exponent first). In trigonometry, there is a standard position for angles. In this way, we are all talking about the same thing and are not trying to guess if your math solution and my math solution are the same. Not standard position. Not standard position. This IS standard position. Initial side not along Initial side along negative Initial side IS along the positive x-axis.