An Evaluation of XML Associated Vulnerabilities in the Xerces-C++ Parser
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SDL Livecontent S1000D Delivery Server Installation and Upgrade Manual
SDL LiveContent S1000D Delivery Server Installation and Upgrade Manual SDL LiveContent S1000D 5.6 January 2018 Legal notice Copyright and trademark information relating to this product release. Copyright © 2009–2018 SDL Group. SDL Group means SDL PLC. and its subsidiaries and affiliates. All intellectual property rights contained herein are the sole and exclusive rights of SDL Group. All references to SDL or SDL Group shall mean SDL PLC. and its subsidiaries and affiliates details of which can be obtained upon written request. All rights reserved. Unless explicitly stated otherwise, all intellectual property rights including those in copyright in the content of this website and documentation are owned by or controlled for these purposes by SDL Group. Except as otherwise expressly permitted hereunder or in accordance with copyright legislation, the content of this site, and/or the documentation may not be copied, reproduced, republished, downloaded, posted, broadcast or transmitted in any way without the express written permission of SDL. LiveContent S1000D is a registered trademark of SDL Group. All other trademarks are the property of their respective owners. The names of other companies and products mentioned herein may be the trademarks of their respective owners. Unless stated to the contrary, no association with any other company or product is intended or should be inferred. This product may include open source or similar third-party software, details of which can be found by clicking the following link: “Acknowledgments ” on page 15. Although SDL Group takes all reasonable measures to provide accurate and comprehensive information about the product, this information is provided as-is and all warranties, conditions or other terms concerning the documentation whether express or implied by statute, common law or otherwise (including those relating to satisfactory quality and fitness for purposes) are excluded to the extent permitted by law. -

Oracle Revenue Management and Billing Installation Guide
Oracle® Revenue Management and Billing Version 2.8.0.0.0 Installation Guide Revision 16.2 F17820-01 June, 2019 Oracle Revenue Management and Billing Installation Guide Oracle Revenue Management and Billing Installation Guide F17820-01 Copyright Notice Copyright © 2019, Oracle and/or its affiliates. All rights reserved. Trademark Notice Oracle, Java, JD Edwards, PeopleSoft, and Siebel are registered trademarks of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Intel and Intel Xeon are trademarks or registered trademarks of Intel Corporation. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. AMD, Opteron, the AMD logo, and the AMD Opteron logo are trademarks or registered trademarks of Advanced Micro Devices. UNIX is a registered trademark of The Open Group. License Restrictions Warranty/Consequential Damages Disclaimer This software and related documentation are provided under a license agreement containing restrictions on use and disclosure, and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or de-compilation of this software, unless required by law for interoperability, is prohibited. Warranty Disclaimer The information contained herein is subject to change without notice and is not warranted to be error- free. If you find any errors, please report them to us in writing. Restricted Rights Notice If this software or related documentation is delivered to the U.S. -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -

TU07 XML at The
ApacheCon 2004 November 2004 XML at the ASF Ted Leung [email protected] Copyright © Sauria Associates, LLC 2004 1 ApacheCon 2004 November 2004 Overview xml.apache.org ws.apache.org Xerces XML-RPC Xalan Axis FOP WSIF Batik JaxMe Xindice cocoon.apache.org Forrest XML-Security Cocoon XML-Commons Lenya XMLBeans Copyright © Sauria Associates, LLC ApacheCon 2004 2 There are three major XML focused projects at the ASF. Originally there was one project, xml.apache.org. Earlier this year, the Cocoon and web services projects were formed. Xml.apache.org contains a number of projects that are general purpose XML tools. Most of these tools are based on specifications from the World Wide Web Consortium. This includes XML itself, XSLT, XSL Formatting object, Scalable Vector Graphics, and XML Signature and XML Encryption The web services project, ws.apache.org contains projects that cluster around standards for dealing with Web Services, including SOAP and XML-RPC The Cocoon project is oriented around the Cocoon Web publishing framework which is basd on XML, XSLT, and a number of other XML related technologies. I’m not going to be able to give you any deep technical details regarding all of these projects. Instead, I’m going to try to describe what these projects are, what standards they implement, and talk about situations where you might use them. Unless I say otherwise, I’m going to be covering the Java projects. There are a few projects which have C/C++ versions and I’ll mention that where applicable. Copyright © Sauria Associates, -

Open Source Licenses Applicable to Hitachi's Products Earlier Versions
Open Source Licenses Applicable to Hitachi’s Products EARLIER VERSIONS Several products are listed below together with certain open source licenses applicable to the particular product. The open source software licenses are included at the end of this document. If the open source package has been modified, an asterisk (*) appears next to the name of the package. Note that the source code for packages licensed under the GNU General Public License or similar type of license that requires the licensor to make the source code publicly available (“GPL Software”) may be available for download as indicated below. If the source code for GPL Software is not included in the software or available for download, please send requests for source code for GPL Software to the contact person listed for the applicable product. The materials below are provided “AS IS,” without warranty of any kind, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. Access to this material grants you no right or license, express or implied, statutorily or otherwise, under any patent, trade secret, copyright, or any other intellectual property right of Hitachi Vantara Corporation (“Hitachi”). Hitachi reserves the right to change any material in this document, and any information and products on which this material is based, at any time, without notice. Hitachi shall have no responsibility or liability to any person or entity with respect to any damages, losses, or costs arising from the materials -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Apachecon 2004 November 13-17, 2004 Las Vegas Nevada
ApacheCon 2004 November 13-17, 2004 Las Vegas Nevada CLICK SESSION TITLE FOR PRESENTATION TUTORIALS MONDAY TUESDAY WEDNESDAY T01 Introduction to the Apache Web Server T02 mod_perl 2.0 by Example T03 Apache Portable Runtime 1.0 Tutorial T06 Mangling data with XSLT T07 Test-Driven Apache Module Development T08 Tapestry In Action T09 SpamAssassin Tutorial T10 Everything You Always Wanted to Know About XML Parsing T11 Scalable Internet Architectures T12 Apache Derby/Cloudscape: Embed This! T13 Struts: the good, the bad, and the ugly T14 Subversion Tutorial T15 Digging deep into XML Schema with Apache XMLBeans T16 PHP Security T17 Taming Apache Cocoon T18 Lucene in Action Search Next Help ApacheCon 2004 November 13-17, 2004 Las Vegas Nevada CLICK SESSION TITLE FOR PRESENTATION TUTORIALS MONDAY TUESDAY WEDNESDAY MO01 Behind the Scenes of the Apache Software Foundation MO02 Apache 2.0 on Windows MO03 The State of Apache Geronimo MO04 Advanced Topics in Module Design: Threadsafety and Portability MO05 The Incubator: Starting a Successful Apache Open Source Project MO06 Apache authentication MO07 Comparing Web Frameworks: Struts, Spring MVC, WebWork, Tapestry & JSF MO08 WebDAV and Apache MO09 New and upcoming features in SpamAssassin v3 MO10 What's so great about Apache 2.0? MO11 Embedding Tomcat 5 into Applications Servers MO12 Logging and Configuration - Demystifying the banes of App development MO13 Storing SpamAssassin User Data in SQL Databases MO14 Shoehorning Apache Onto Your Box: System Sizing Tips MO15 Highly available web sites with Tomcat -
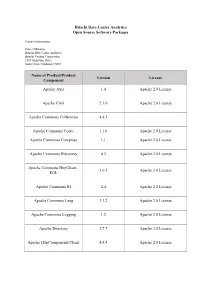
Hitachi Data Center Analytics Open Source Software Packages
Hitachi Data Center Analytics Open Source Software Packages Contact Information: Project Manager Hitachi Data Center Analytics Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component Apache Axis 1.4 Apache 2.0 License Apache Click 2.3.0 Apache 2.0 License Apache Commons Collections 4.4.1 Apache Commons Codec 1.10 Apache 2.0 License Apache Commons Compress 1.1 Apache 2.0 License Apache Commons Discovery 0.2 Apache 2.0 License Apache Commons HttpClient - 3.0.1 Apache 2.0 License EOL Apache Commons IO 2.4 Apache 2.0 License Apache Commons Lang 3.3.2 Apache 2.0 License Apache Commons Logging 1.2 Apache 2.0 License Apache Directory 2.7.7 Apache 2.0 License Apache HttpComponents Client 4.4.4 Apache 2.0 License Name of Product/Product Version License Component Apache HttpComponents 5.5.2 Apache 2.0 License Apache Log4j 1.2.17 Apache 2.0 License Apache Log4net 1.2.10 Apache 2.0 License Apache PDF Box 2.0.2 Apache 2.0 License Apache POI 3.15 Apache 2.0 License Apache Thrift 0.9.1 Apache 2.0 License Apache Web Services 1.0.2 Apache 2.0 License Apache Xerces Java Parser 2.9.0 Apache 2.0 License Apache XML Graphics 1.4 Apache 2.0 License Apache XML-RPC 3.1 Apache 2.0 License Apache XMLBeans 2.6.0 Apache 2.0 License Bouncy Castle Crypto API 1.45.0 MIT license CHILKAT CRYPT 9.5.0 Paid click-calendar 1.3.0 Apache 2.0 License Customized log4j File Appender Apache 2.0 License docx4j 2.7.0 Apache 2.0 License Name of Product/Product Version License Component dom4j 1.6.1 Apache 2.0 -

Code Smell Prediction Employing Machine Learning Meets Emerging Java Language Constructs"
Appendix to the paper "Code smell prediction employing machine learning meets emerging Java language constructs" Hanna Grodzicka, Michał Kawa, Zofia Łakomiak, Arkadiusz Ziobrowski, Lech Madeyski (B) The Appendix includes two tables containing the dataset used in the paper "Code smell prediction employing machine learning meets emerging Java lan- guage constructs". The first table contains information about 792 projects selected for R package reproducer [Madeyski and Kitchenham(2019)]. Projects were the base dataset for cre- ating the dataset used in the study (Table I). The second table contains information about 281 projects filtered by Java version from build tool Maven (Table II) which were directly used in the paper. TABLE I: Base projects used to create the new dataset # Orgasation Project name GitHub link Commit hash Build tool Java version 1 adobe aem-core-wcm- www.github.com/adobe/ 1d1f1d70844c9e07cd694f028e87f85d926aba94 other or lack of unknown components aem-core-wcm-components 2 adobe S3Mock www.github.com/adobe/ 5aa299c2b6d0f0fd00f8d03fda560502270afb82 MAVEN 8 S3Mock 3 alexa alexa-skills- www.github.com/alexa/ bf1e9ccc50d1f3f8408f887f70197ee288fd4bd9 MAVEN 8 kit-sdk-for- alexa-skills-kit-sdk- java for-java 4 alibaba ARouter www.github.com/alibaba/ 93b328569bbdbf75e4aa87f0ecf48c69600591b2 GRADLE unknown ARouter 5 alibaba atlas www.github.com/alibaba/ e8c7b3f1ff14b2a1df64321c6992b796cae7d732 GRADLE unknown atlas 6 alibaba canal www.github.com/alibaba/ 08167c95c767fd3c9879584c0230820a8476a7a7 MAVEN 7 canal 7 alibaba cobar www.github.com/alibaba/ -

Operations Hub Open Source Software List
GE Operations Hub Open Source Software List (for Version 1.7) In accordance with certain software license terms, the General Electric Company (“GE”) makes available the following software package installations. This code is provided to you on an “as is” basis, and GE makes no representations or warranties for the use of this code by you independent of any GE provided software or services. Refer to the licenses and copyright notices files for each package for any specific license terms that apply to each software bundle, associated with this product release. NOTE: These software package versions may change or be removed as needed for updates to this product. Copyright © 2018 General Electric Company. All rights reserved. Page 1 of 67 Software Name & Company Link License Name & Copyright Version Version (by Component) HikariCP https://github.com/brettwooldr Apache 2.0 3.4.2 idge/HikariCP Not found MsSql Jdbc 7.4.1.jre8 Copyright(c) 2019 Microsoft MIT https://www.microsoft.com/ Corporation snakeyaml http://www.snakeyaml.org Copyright (c) 2008, Apache License 2.0 1.2.6 http://www.snakeyaml.org COMMON DEVELOPMENT HK2 Class-Model 2.5.0-b06 https://javaee.github.io/glassfish/ AND DISTRIBUTION LICENSE Copyright (c) 2010-2015 Oracle and/or (CDDL) Version 1.1 its affiliates. All rights reserved. https://code.google.com/archive/p/ Copyright (C) 2003-2013 Virginia Tech. VT Crypt Library 2.1.4 Apache License 2.0 vt-middleware/ All rights reserved. https://code.google.com/archive/p/ Copyright (C) 2003-2013 Virginia Tech. VT Dictionary Libraries 3.0 Apache License 2.0 vt-middleware/ All rights reserved. -

TE Commander 8.8.3 - Use of Third-Party Libraries
TE Commander 8.8.3 - Use of Third-Party Libraries Name Selected License axis 1.4 (Apache 2.0) Apache License 2.0 axis-jaxrpc 1.4 (Apache v2.0) Apache License 2.0 axis-saaj 1.4 (Apache v2.0) Apache License 2.0 commons-cli 1.4.0 (Apache-2.0) Apache License 2.0 commons-codec 1.14.0 (Apache-2.0) Apache License 2.0 commons-collections4 4.4 (Apache-2.0) Apache License 2.0 commons-compress 1.18 (Apache-2.0) Apache License 2.0 commons-discovery 0.5 (Apache 2.0) Apache License 2.0 commons-io 2.6 (Apache-2.0) Apache License 2.0 commons-lang3 3.9 (Apache-2.0) Apache License 2.0 commons-logging 1.2 (Apache-2.0) Apache License 2.0 commons-math3 3.6.1 (Apache-2.0) Apache License 2.0 gson 2.8.6 (Apache-2.0) Apache License 2.0 guava 28.2 (Apache-2.0) Apache License 2.0 httpasyncclient 4.1.4 (Apache-2.0) Apache License 2.0 httpclient 4.5.12 (Apache-2.0) Apache License 2.0 httpcore 4.4.13 (Apache-2.0) Apache License 2.0 httpcore-nio 4.4.13 (Apache-2.0) Apache License 2.0 httpmime 4.5.12 (Apache-2.0) Apache License 2.0 jackson-annotations 2.10.3 (Apache-2.0) Apache License 2.0 jackson-core 2.10.3 (Apache-2.0) Apache License 2.0 jackson-databind 2.10.3 (Apache-2.0) Apache License 2.0 jackson-datatype-jsr310 2.10.3 (Apache-2.0) Apache License 2.0 jansi 1.18 (Apache-2.0) Apache License 2.0 log4j-over-slf4j 1.7.30 (Apache v2.0) Apache License 2.0 maven-artifact 3.6.3 (Apache-2.0) Apache License 2.0 passay 1.4.0 (Apache-2.0) Apache License 2.0 plexus-utils 3.3.0 (Apache-2.0) Apache License 2.0 poi 4.1.0 (Apache-2.0) Apache License 2.0 xmlbeans 3.1.0 (Apache v2.0) -

Eyeglass Search OSS Licenses and Packages V9
ECA 15.1 opensuse https://en.opensuse.org/openSUSE:License Package Licence Name Version Type Key Licence Name opensuse 15.1 OS annogen:annogen 0.1.0 JAR Not Found antlr:antlr 2.7.7 JAR BSD Berkeley Software Distribution (BSD) aopalliance:aopalliance 1 JAR Public DomainPublic Domain asm:asm 3.1 JAR Not Found axis:axis 1.4 JAR Apache-2.0 The Apache Software License, Version 2.0 axis:axis-wsdl4j 1.5.1 JAR Not Found backport-util-concurrent:backport-util-concurrent3.1 JAR Public DomainPublic Domain com.amazonaws:aws-java-sdk 1.1.7.1 JAR Apache-2.0 The Apache Software License, Version 2.0 com.beust:jcommander 1.72 JAR Apache-2.0 The Apache Software License, Version 2.0 com.carrotsearch:hppc 0.6.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.clearspring.analytics:stream 2.7.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.drewnoakes:metadata-extractor 2.4.0-beta-1JAR Public DomainPublic Domain com.esotericsoftware:kryo-shaded 3.0.3 JAR BSD Berkeley Software Distribution (BSD) com.esotericsoftware:minlog 1.3.0 JAR BSD Berkeley Software Distribution (BSD) com.fasterxml.jackson.core:jackson-annotations2.6.1 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.5.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.2.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.9.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.6.0