Electric Power Distribution Reliability
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
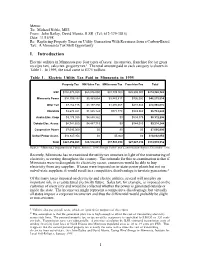
Replacing Property Taxes on Utility Generation with Revenues from a Carbon-Based Tax: a Minnesota Tax Shift Opportunity I
Memo: To: Michael Noble, ME3 From: John Bailey, David Morris, ILSR (Tel: 612-379-3815) Date: 11/15/98 Re: Replacing Property Taxes on Utility Generation With Revenues from a Carbon-Based Tax: A Minnesota Tax Shift Opportunity I. Introduction Electric utilities in Minnesota pay four types of taxes: income tax, franchise fee (or gross receipts tax), sales tax, property tax.1 The total amount paid in each category is shown in Table 1. In 1995, the total came to $375 million. Table 1. Electric Utility Tax Paid in Minnesota in 1995 Property Tax MN Sales Tax MN Income Tax Franchise Fee Total NSP $152,078,365 $65,076,000 $31,709,000 $25,505,000 $274,368,365 Minnesota Power $34,706,493 $5,963,664 $3,843,817 $700,000 $45,213,974 Otter Tail $7,152,715 $4,197,450 $1,370,067 $233,643 $12,953,875 Interstate $3,670,381 $1,935,124 $573,770 $569,969 $6,749,244 Anoka Elec. Coop $3,179,055 $4,658,862 $0 $534,379 $8,372,296 Dakota Elec. Assoc. $4,742,500 $4,487,719 $0 $144,025 $9,374,244 Cooperative Power $7,095,000 $0 $0 $0 $7,095,000 United Power Assoc. $10,827,954 $0 $5,000 $0 $10,832,954 Total $223,452,463 $86,318,819 $37,501,654 $27,687,016 $374,959,952 Source: Minnesota Department of Public Service, 1996 Energy Policy and Conservation Report, December 1996 Recently, Minnesota has re-examined the utility tax structure in light of the restructuring of electricity occurring throughout the country. -

Nuclear Power Reactors in California
Nuclear Power Reactors in California As of mid-2012, California had one operating nuclear power plant, the Diablo Canyon Nuclear Power Plant near San Luis Obispo. Pacific Gas and Electric Company (PG&E) owns the Diablo Canyon Nuclear Power Plant, which consists of two units. Unit 1 is a 1,073 megawatt (MW) Pressurized Water Reactor (PWR) which began commercial operation in May 1985, while Unit 2 is a 1,087 MW PWR, which began commercial operation in March 1986. Diablo Canyon's operation license expires in 2024 and 2025 respectively. California currently hosts three commercial nuclear power facilities in various stages of decommissioning.1 Under all NRC operating licenses, once a nuclear plant ceases reactor operations, it must be decommissioned. Decommissioning is defined by federal regulation (10 CFR 50.2) as the safe removal of a facility from service along with the reduction of residual radioactivity to a level that permits termination of the NRC operating license. In preparation for a plant’s eventual decommissioning, all nuclear plant owners must maintain trust funds while the plants are in operation to ensure sufficient amounts will be available to decommission their facilities and manage the spent nuclear fuel.2 Spent fuel can either be reprocessed to recover usable uranium and plutonium, or it can be managed as a waste for long-term ultimate disposal. Since fuel re-processing is not commercially available in the United States, spent fuel is typically being held in temporary storage at reactor sites until a permanent long-term waste disposal option becomes available.3 In 1976, the state of California placed a moratorium on the construction and licensing of new nuclear fission reactors until the federal government implements a solution to radioactive waste disposal. -

Toward a Sustainable Electric Utility Sector
The Distributed Utility Concept: Toward a Sustainable Electric Utility Sector Steven Letendre, John Byrne, and Young-Doo Wang, Center for Energy and Environmental Policy, University of Delaware The U.S. electric utility sector is entering an uncertain period as pressure mounts to cut costs and minimize environmental impacts. Many analysts believe that exposing the industry to competition is the key to reducing costs. Most restructuring proposals acknowledge the need to maintain environmental quality and suggest mechanisms for assuring continued support for end-use efficiency and renewable energy in a deregulated electric utility industry. Two of the most prominent ideas are non-bypassable line charges and portfolio standards. This paper suggests another option based on the distributed utility (DU) concept in which net metering and a form of performance-based ratemaking allow distributed generation, storage, and DSM to play an important role in a new competitive electric utility sector. A DU option directly incorporates these resources into the electric system by explicitly acknowledging their value in deferring distribution equipment upgrades. INTRODUCTION electric utility industry. In our view, the DU option has been neglected in the current debate. The electric utility sector in the U.S. is on the verge of A DU strategy involves a fundamental shift in the way fundamental change as regulators, policymakers, and indus- electricity is delivered, with a move away from large-scale try officials seek a strategy for introducing competition into central generation to distributed small-scale generation and the industry. The move toward competition is driven by the storage, and targeted demand-side management. To date, belief that significant efficiency gains could be realized by the DU concept has mainly been analyzed in terms of its exposing the industry to market forces. -

Mcleod Cooperative Power Twins Clinic a Big Hit with Area Youth
McLeod Cooperative Power June 2017 In this issue... EWS N Twins Clinic a big hit with area youth Our office will be closed on Tuesday, July 4 n Saturday, May 27, about 80 area youth participated in the Minnesota Twins Youth Baseball O Clinic in Arlington MN. Local students were coached by members of the Minnesota Twins organization on hitting, throwing and catching, and baseball fundamentals. There were two 90-minute sessions conducted for each age School safety programs ....8 bracket: 6-9 years of age and 10-13 years of age. The event was hosted locally by McLeod Co-op Power of Official publication of Glencoe and the Arlington Baseball Association. Water for the participants was provided by Locher Bros. Distributing of Green Isle. These youth baseball clinics are sponsored by the Minnesota Twins Foundation and Great River Energy in communities across the state. Participants each received a baseball from McLeod Co-op Power and a backpack from Great River Energy. www.mcleodcoop.com Only a few seats Off-peak programs can lower your bill remain on the MN rograms like the Hot Water air conditioner or heat pump in half, you calculate your personal savings Storage Program and Cycled and you have some significant based on number of persons in the Twins game bus Cooling Program can summer savings. An average family family and help size your water heater Psignificantly reduce your family’s saves $80 per year on the cycled capacity needs. oin the Co-op for an afternoon monthly electric bill. Appliance use on air program. -

Regularization of Business Investment in the Electric Utility Industry
This PDF is a selection from an out-of-print volume from the National Bureau of Economic Research Volume Title: Regularization of Business Investment Volume Author/Editor: Universities-National Bureau Volume Publisher: Princeton University Press/NBER Volume ISBN: 0-87014-195-3 Volume URL: http://www.nber.org/books/univ54-1 Publication Date: 1954 Chapter Title: Regularization of Business Investment in the Electric Utility Industry Chapter Author: Edward W. Morehouse Chapter URL: http://www.nber.org/chapters/c3026 Chapter pages in book: (p. 213 - 282) REGULARIZATION OF BUSINESS INVESTMENT IN THE ELECTRIC UTILITY INDUSTRY' EDWARD W. MOREHOUSE GENERAL PUBLIC UTILITIES CORPORATION Introduction THIS PAPER explores the possibilities of regularizing business invest- ment by the electric utility industry. The program for the conference adds, "as means of maintaining high productive employment in a private enterprise economy." This ultimate goal of "high productive employment" as an incen- tive for regularization of investment is of less importance in the electric utility industry than in other industries, as data submitted later tend to show. Electric utilities already have achieved a rela- tively high stability of employment of operating personnel, and the impact of investment on wages and employment in electric utility operations is relatively less significant to the total economy than it is in other industries. Any contribution that electric utilities might make by stabilizing their capital expenditures would be a contribu- tion to employment stability generally, and particularly to employ- ment in the building of plant, or the manufacture of plant and equipment items, needed by electric utilities. These indirect em- ployment effects would bulk larger than the direct effects on the number of employees used in utility operations. -

U.S. Electric Power Industry - Context and Structure
U.S. Electric Power Industry - Context and Structure Authored by Analysis Group for Advanced Energy Economy November 2011 Industry Organization The electric industry across the United States contains Figure 1 significant variations from the perspectives of structure, A History of the U.S. Electric Industry organization, physical infrastructure characteristics, 1870 cost/price drivers, and regulatory oversight. The variation stems from a mix of geographical influences, population Thomas Edison demonstrates the electric light bulb and generator and industry make up, and the evolution of federal and 1880 state energy law and policy. Edison launches Pearl Street station, the first modern electricity generation station th In the early part of the 20 century, the electric industry 1890 evolved quickly through the creation, growth and Development begins on the Niagra Falls hydroelectric project consolidation of vertically-integrated utilities – that is, Samuel Insull suggests the utility industry is a natural companies that own and operate all of the power plants, 1900 monopoly - electric industry starts to become vertically transmission lines, and distribution systems that generate integrated and deliver power to ultimate customers. At the same Wisconsin enacts first private utility regulation and 30 states time, efficiency of electricity generation dramatically follow suit shortly thereafter 1910 improved, encouraging growth, consolidation of the industry, and expansion into more and more cities, and The Federal Power Act created the Federal Power Commission across a wider geographic area. Over time, consolidated (now FERC) utilities were granted monopoly franchises with exclusive 1920 service territories by states, in exchange for an obligation to serve customers within that territory at rates for service 1 1930 based on state-regulated, cost-of-service ratemaking. -

Smart Bioenergy – Innovations for a Sustainable Future Come and Join Us!
Biogas production on the way towards competitiveness – process optimization options and requirements Jan Liebetrau © Anklam Bioethanol GmbH Bioethanol Anklam© 4th Inter Baltic Biogas Arena Workshop Esbjerg, 25 – 26 August 2016 Background Competitiveness – within which criteria? Cheap electricity and heat? Cheap waste treatment? GHG mitigation? Circular economy? Options: Optimization of cost structure (e.g. substrates, technology) Generating new income (electricity markets, heat, material production) 2 Background – Germany perspective Waste wood based CHP Paper industry Wood based CHP ) Manure based small scale plants MWel ( Flexibility Energy crops based plants Organic waste based plants Biomethan CHP Oil based Installed capacity capacity Installed year Dotzauer et al 2016 • Political support currently rather low, future perspective highly unclear • Discussion about time beyond Feed in tariffs has started – new economic perspectives are needed –and/or relevance for safe electricity provision has to be proven 3 Substrates 4 Biogas plants cost structure - Different situation in different plant configurations - High share of costs for energy crops (agricultural plants) - High investment costs (in particular waste treating plants) - High specific investment costs (manure based plants) - High maintenance and replacement costs (effect of depreciation is limited) - Increasing requirements from authorities - Difference between feed in tariff and market price is for energy crop based and manure based plants currently not conceivable - Waste based -

Business As Usual and Nuclear Power
BUSINESS AS USUAL AND NUCLEAR POWER 1974 .1999 OECD, 2000. Software: 1987-1996, Acrobat is a trademark of ADOBE. All rights reserved. OECD grants you the right to use one copy of this Program for your personal use only. Unauthorised reproduction, lending, hiring, transmission or distribution of any data or software is prohibited. You must treat the Program and associated materials and any elements thereof like any other copyrighted material. All requests should be made to: Head of Publications Service, OECD Publications Service, 2, rue Andr´e-Pascal, 75775 Paris Cedex 16, France. OECD PROCEEDINGS BUSINESS AS USUAL AND NUCLEAR POWER Joint IEA/NEA Meeting Paris, France 14-15 October 1999 NUCLEAR ENERGY AGENCY INTERNATIONAL ENERGY AGENCY ORGANISATION FOR ECONOMIC CO-OPERATION AND DEVELOPMENT ORGANISATION FOR ECONOMIC CO-OPERATION AND DEVELOPMENT Pursuant to Article 1 of the Convention signed in Paris on 14th December 1960, and which came into force on 30th September 1961, the Organisation for Economic Co-operation and Development (OECD) shall promote policies designed: − to achieve the highest sustainable economic growth and employment and a rising standard of living in Member countries, while maintaining financial stability, and thus to contribute to the development of the world economy; − to contribute to sound economic expansion in Member as well as non-member countries in the process of economic development; and − to contribute to the expansion of world trade on a multilateral, non-discriminatory basis in accordance with international obligations. The original Member countries of the OECD are Austria, Belgium, Canada, Denmark, France, Germany, Greece, Iceland, Ireland, Italy, Luxembourg, the Netherlands, Norway, Portugal, Spain, Sweden, Switzerland, Turkey, the United Kingdom and the United States. -

Nuclear Energy: Statistics Dr
Nuclear Energy: Statistics Dr. Elizabeth K. Ervin Civil Engineering Today’s Motivation The more people learn about nuclear power, the more supportive they are of it { 73% positive in Clean and Safe Energy Coalition survey in 2006. Nuclear power plants produce no controlled air pollutants, such as sulfur and particulates, or greenhouse gases. { The use of nuclear energy helps keep the air clean, preserve the earth's climate, avoid ground-level ozone formation, and prevent acid rain. One of the few growing markets { Jobs, capital… { 2006: 36 new plants under construction in 14 countries, 223 proposed. Worried about Nuclear Power Plants? Dirty Bombs? Radon? U.S. civilian nuclear reactor program: 0 deaths Each year, 100 coal miners and 100 coal transporters are killed; 33,134 total from 1931 to 1995. Aviation deaths since 1938: 54,000 “That’s hot.” { Coal-fired plant releases 100 times more radiation than equivalent nuclear reactor { Three Mile Island released 1/6 of the radiation of a chest x-ray { Despite major human mistakes, 56 Chernobyl deaths Nuclear power plants: 15.2% of the world's electricity production in 2006. 34% of EU 20% France: 78.1% 16 countries > 25% of their electricity 31 countries worldwide operating 439 nuclear reactors for electricity generation. U.S. Nuclear There are 104 commercial nuclear power plants in the United States. They are located at 64 sites in 31 states. { 35 boiling water reactors { 69 pressurized water reactors { 0 next generation reactors Nuclear already provides 20 percent of the United State’s electricity, or 787.2 billion kilowatt-hours (bkWh) Electricity demands expected to increase 30% nationally by 2030. -

Utility Use of Renewable Resources: Legal and Economic Implications
Denver Law Review Volume 59 Issue 4 Article 4 February 2021 Utility Use of Renewable Resources: Legal and Economic Implications Jan G. Laitos Follow this and additional works at: https://digitalcommons.du.edu/dlr Recommended Citation Jan G. Laitos, Utility Use of Renewable Resources: Legal and Economic Implications, 59 Denv. L.J. 663 (1982). This Article is brought to you for free and open access by the Denver Law Review at Digital Commons @ DU. It has been accepted for inclusion in Denver Law Review by an authorized editor of Digital Commons @ DU. For more information, please contact [email protected],[email protected]. UTILITY USE OF RENEWABLE RESOURCES: LEGAL AND ECONOMIC IMPLICATIONS* JAN G. LAITOS** I. Overview: The Nature of Utility Involvement in Renewable Energy Applications ......................................... 666 A. Types of Utilities and Their Differing Relationships to Renewable Energy ...................................... 666 1. Electric Utilities and Renewable Energy .............. 666 2. Gas Utilities and Renewable Energy ................. 669 B. Prospects for Utility Interest in Renewable Energy ....... 671 II. Utilities and Decentralized Renewable Energy Applications ... 672 A. Utilities and Nonelectric, Decentralized, Renewable Technologies ..... ................................ 673 1. The Effect of Nonelectric Renewable Technologies on U tilities ............................................. 673 2. Responses of Utilities to Nonelectric Renewable Technologies ........................................ 676 a. Utility -

Smart Bioenergy – Innovations for a Sustainable Future Come and Join Us!
Flexibilisation of biogas plants and impact on the grid operation Jan Liebetrau, Marcus Trommler, Eric Mauky, Tino Barchmann, Martin Dotzauer © Anklam Bioethanol GmbH © BioethanolAnklam Biogas Workshop, Vlijmen, April 5th 2017 Electricity provision – future scenarios Biogas is in comparison expensive There will be times of excess energy and lack of energy Flexibility will be a must for Biogas Agora Energiewende: 12 insights on Germany's Energiewende February 2013 2 Conditions for flexible operation Different market options with different requirements for participation Biogas plants have individual constructive and operational design which define the limits of flexibility Barchmann et. al. 2016 3 Conditions for flexible operation Barchmann et. al. 2016 [Fuchs 2012] 4 Conclusion - why do we need to operate biogas plants flexible? - provide energy when needed (electricity and heat) - Market price oriented, increase utilization - Grid stabilization oriented - reduces losses at specific operational conditions (e.g. maintenance shutdown, weather changes) - respond to substrate changes in amount and quality 5 Flexibilisation Basic principle for flexibilisation 6 Technical options for flexibility, services to the grid and sector coupling on site • Increase of CHP capacity (and grid access) - in case of constant annual energy output • Increase of gas storage capacity • Control of biogas production rate (controlled feeding, storage of intermediates) • Power to heat • Biomethane • Power to gas 7 Financial support for flexible concepts • EEG 2014: • §54 Flexibility bonus for existing plants • 130 €/kW/a (Allocation to produced electricity ) for 10 years • Appendix 3 Number I: • Direct marketing compulsory • Paverage ≤ 0,2*Pinst • Padded = max. 0,5*Pinst • Registration and expert statement • „Average capacitiy“ (§ 101 EEG 2014) limited • EEG 2017: • Obligation to have twice as much capacity installed in relation to average capacity • 40€/kW installed for existing plants 9 Motivation for flexible operation • Financial motivation 1. -

State of Oklahoma
STATE OF OKLAHOMA 1st Session of the 46th Legislature (1997) HOUSE BILL NO. 1941 By: Morgan AS INTRODUCED An Act relating to public utilities; creating the Oklahoma Electric Utility Reform Act; stating purpose of the act; defining terms; providing for open access to electric distribution systems; directing electric utilities to provide open access; providing purchasing options for customers; authorizing the Corporation Commission to promulgate certain rules; authorizing the Commission to establish certain fees; limiting authority of the Commission to regulate certain entities; making effective date contingent upon certain occurrences; providing for levy of an electric sales gross receipts tax; making tax in lieu of other taxes; providing for apportionment of tax; providing for payment of tax; requiring sellers of electricity to file certain forms; requiring certain reports; requiring preservation of records; providing for semiannual payments in certain circumstances; amending 17 O.S. 1991, Sections 151 and 152, as last amended by Section 6, Chapter 315, O.S.L. 1994 (17 O.S. Supp. 1996, Section 152), which relate to regulation of public utilities; modifying definition; deleting certain statutory cite; amending 17 O.S. 1991, Sections 180.1 and 180.2, which relate to advertising by public utilities; modifying definitions; amending Section 43, Chapter 278, O.S.L. 1993, as amended by Section 1, Chapter 91, O.S.L. 1996 (17 O.S. Supp. 1996, Section 180.11), which relates to public utility assessment; adding certain utility subject to assessment; modifying definition; amending 17 O.S. 1991, Sections 250, 251, as amended by Section 16, Chapter 315, O.S.L. 1994, 252, 253 and 254 (17 O.S.