Architecture of the Escherichia Coli Nucleoid
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(NAP) and Illustration of DNA Flexure Angles at Single Molecule Resolution Debayan Purkait†A, Debolina Bandyopadhyay†A, and Padmaja P
bioRxiv preprint doi: https://doi.org/10.1101/2020.09.11.293639; this version posted September 11, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Vital Insights into Prokaryotic Genome Compaction by Nucleoid-Associated Protein (NAP) and Illustration of DNA Flexure Angles at Single Molecule Resolution Debayan Purkait†a, Debolina Bandyopadhyay†a, and Padmaja P. Mishra*a aChemical Sciences Division, Saha Institute of Nuclear Physics, India aHomi Bhaba National Institute (HBNI), India †Both the authors have contributed equally. * Corresponding author Abstract Integration Host Factor (IHF) is a heterodimeric site-specific nucleoid-associated protein (NAP) well known for its DNA bending ability. The binding is mediated through the narrow minor grooves of the consensus sequence, involving van der-Waals interaction and hydrogen bonding. Although the DNA bend state of IHF has been captured by both X-ray Crystallography and Atomic Force Microscopy (AFM), the range of flexibility and degree of heterogeneity in terms of quantitative analysis of the nucleoprotein complex has largely remained unexplored. Here we have monitored and compared the trajectories of the conformational dynamics of a dsDNA upon binding of wild-type (wt) and single-chain (sc) IHF at millisecond resolution through single-molecule FRET (smFRET). Our findings reveal that the nucleoprotein complex exists in a ‘Slacked-Dynamic’ state throughout the observation window where many of them have switched between multiple ‘Wobbling States’ in the course of attainment of packaged form. A range of DNA ‘Flexure Angles’ has been calculated that give us vital insights regarding the nucleoid organization and transcriptional regulation in prokaryotes. -

Cell Cycle Regulation by the Bacterial Nucleoid
Available online at www.sciencedirect.com ScienceDirect Cell cycle regulation by the bacterial nucleoid David William Adams, Ling Juan Wu and Jeff Errington Division site selection presents a fundamental challenge to all terminate in the terminus region (Ter; 1808). Once organisms. Bacterial cells are small and the chromosome chromosome replication and segregation are complete (nucleoid) often fills most of the cell volume. Thus, in order to the cell is ready to divide. In Bacteria this normally occurs maximise fitness and avoid damaging the genetic material, cell by binary fission and in almost all species this is initiated division must be tightly co-ordinated with chromosome by the assembly of the tubulin homologue FtsZ into a replication and segregation. To achieve this, bacteria employ a ring-like structure (‘Z-ring’) at the nascent division site number of different mechanisms to regulate division site (Figure 1) [1]. The Z-ring then functions as a dynamic selection. One such mechanism, termed nucleoid occlusion, platform for assembly of the division machinery [2,3]. Its allows the nucleoid to protect itself by acting as a template for central role in division also allows FtsZ to serve as a nucleoid occlusion factors, which prevent Z-ring assembly over regulatory hub for the majority of regulatory proteins the DNA. These factors are sequence-specific DNA-binding identified to date [2,4]. Nevertheless, the precise ultra- proteins that exploit the precise organisation of the nucleoid, structure of the Z-ring and whether or not it plays a direct allowing them to act as both spatial and temporal regulators of role in force-generation during division remains contro- bacterial cell division. -

The Epigenetic Regulator Cfp1
Article in press - uncorrected proof BioMol Concepts, Vol. 1 (2010), pp. 325–334 • Copyright ᮊ by Walter de Gruyter • Berlin • New York. DOI 10.1515/BMC.2010.031 Review The epigenetic regulator Cfp1 David G. Skalnik concept is illustrated by a variety of phenomena, including Wells Center for Pediatric Research, Section of Pediatric X-chromosome inactivation, in which one X chromosome in Hematology/Oncology, Departments of Pediatrics and each cell of a developing female blastocyst becomes irre- Biochemistry and Molecular Biology, Indiana University versibly inactivated; genomic imprinting, in which mater- School of Medicine, 1044 W. Walnut St., Indianapolis, nally and paternally derived alleles of a gene are IN 46202, USA differentially expressed; and the observation that diverse tis- sues express distinct sets of genes to permit unique func- e-mail: [email protected] tional properties, yet each (with rare exceptions) carries identical genetic information (1–4). Epigenetic information is largely encoded within chro- matin structure. A major class of epigenetic modifications is Abstract post-translational modification of histones. Dozens of dis- Numerous epigenetic modifications have been identified and tinct covalent modifications at specific amino acid residues correlated with transcriptionally active euchromatin or have been identified, including acetylation, methylation, repressed heterochromatin and many enzymes responsible phosphorylation, and sumoylation (2, 5, 6). Many of these for the addition and removal of these marks have been char- modifications are tightly correlated with either transcription- acterized. However, less is known regarding how these ally active euchromatin or transcriptionally silenced hetero- enzymes are regulated and targeted to appropriate genomic chromatin. Relatively subtle changes of covalent modifica- locations. -

A Versatile Couple with Roles in Replication and Recombination
Colloquium Bacteriophage T4 gene 41 helicase and gene 59 helicase-loading protein: A versatile couple with roles in replication and recombination Charles E. Jones*, Timothy C. Mueser†, Kathleen C. Dudas‡, Kenneth N. Kreuzer‡, and Nancy G. Nossal*§ *Laboratory of Molecular and Cellular Biology, National Institute of Diabetes and Digestive and Kidney Diseases, National Institutes of Health, Bethesda, MD 20892-0830; †Department of Chemistry, University of Toledo, 2801 West Bancroft Street, Toledo, OH 43606; and ‡Department of Microbiology, Duke University Medical Center, Durham, NC 27710 Bacteriophage T4 uses two modes of replication initiation: origin- protein (gene 45) that is loaded by the complex of the gene 44 dependent replication early in infection and recombination-depen- and 62 proteins. In the presence of the T4 gene 32 single- dent replication at later times. The same relatively simple complex stranded DNA binding protein, T4 DNA polymerase, the clamp, of T4 replication proteins is responsible for both modes of DNA and the clamp loader are sufficient for slow strand displacement synthesis. Thus the mechanism for loading the T4 41 helicase must synthesis of the leading strand. The 5Ј to 3Ј gene 41 helicase be versatile enough to allow it to be loaded on R loops created by unwinds DNA ahead of the fork and increases the elongation transcription at several origins, on D loops created by recombina- rate more than 10-fold to 400 nt͞sec, comparable to that in vivo. tion, and on stalled replication forks. T4 59 helicase-loading protein Although the helicase can load on nicked and forked DNA by is a small, basic, almost completely ␣-helical protein whose N- itself, its loading is greatly accelerated by the 59 helicase-loading terminal domain has structural similarity to high mobility group protein. -

Catalytic Domain of Plasmid Pad1 Relaxase Trax Defines a Group Of
Catalytic domain of plasmid pAD1 relaxase TraX defines a group of relaxases related to restriction endonucleases María Victoria Franciaa,1, Don B. Clewellb,c, Fernando de la Cruzd, and Gabriel Moncaliánd aServicio de Microbiología, Hospital Universitario Marqués de Valdecilla e Instituto de Formación e Investigación Marqués de Valdecilla, Santander 39008, Spain; bDepartment of Biologic and Materials Sciences, University of Michigan School of Dentistry, Ann Arbor, MI 48109; cDepartment of Microbiology and Immunology, University of Michigan Medical School, Ann Arbor, MI 48109; and dDepartamento de Biología Molecular e Instituto de Biomedicina y Biotecnología de Cantabria, Universidad de Cantabria–Consejo Superior de Investigaciones Científicas–Sociedad para el Desarrollo Regional de Cantabria, Santander 39011, Spain Edited by Roy Curtiss III, Arizona State University, Tempe, AZ, and approved July 9, 2013 (received for review May 30, 2013) Plasmid pAD1 is a 60-kb conjugative element commonly found in known relaxases show two characteristic sequence motifs, motif I clinical isolates of Enterococcus faecalis. The relaxase TraX and the containing the catalytic Tyr residue (which covalently attaches to primary origin of transfer oriT2 are located close to each other and the 5′ end of the cleaved DNA) and motif III with the His-triad have been shown to be essential for conjugation. The oriT2 site essential for relaxase activity (facilitating the cleavage reaction contains a large inverted repeat (where the nic site is located) by activation of the catalytic Tyr). This His-triad has been used as adjacent to a series of short direct repeats. TraX does not show a relaxase diagnostic signature (12). fi any of the typical relaxase sequence motifs but is the prototype of Plasmid pAD1 relaxase, TraX, was identi ed (9) and shown to oriT2 a unique family of relaxases (MOB ). -

Relaxation Complexes of Plasmids Colel and Cole2:Unique Site of The
Proc. Nat. Acad. Sci. USA Vol. 71, No. 10, pp. 3854-3857, October 1974 Relaxation Complexes of Plasmids ColEl and ColE2: Unique Site of the Nick in the Open Circular DNA of the Relaxed Complexes (Escherichia coli/supercoiled DNA/endonuclease/restriction enzyme/DNA replication) MICHAEL A. LOVETT, DONALD G. GUINEY, AND DONALD R. HELINSKI Department of Biology, University of California, San Diego, La Jolla, Calif. 92037 Communicated by Stanley L. Miller, June 26, 1974 ABSTRACT The product of the induced relaxation of volved in the production of a single-strand cleavage in the supercoiled DNA-protein relaxation complexes of colicino- initiation of replication and/or conjugal transfer of plasmid genic factors El (ColEl) and E2 (CoIE2) is an open circular DNA molecule with a strand-specific nick. Cleavage of the DNA. An involvement in such processes would most likely open circular DNA of each relaxed complex with the EcoRI require that the relaxation event take place at a unique site restriction endonuclease demonstrates that the single- in the DNA molecule. In this report, evidence will be pre- strand break is at a unique position. The site of the single- sented from studies using the EcoRI restriction endonuclease strand break in the relaxed ColEl complex is approximately the same distance from the EcoRI cleavage site as the that the strand-specific relaxation event takes place at a origin of ColEl DNA replication. unique site on both the ColEl and CoIE2 plasmid molecules. The location of this site, at least in the case of the ColEl Many of extrachromosomal circular DNA elements (plas- plasmid, is approximately the same distance from the single mids) of Escherichia coli, differing in molecular weight, num- EcoRI site as the origin of replication for this plasmid. -

Palindromes in DNA—A Risk for Genome Stability and Implications in Cancer
International Journal of Molecular Sciences Review Palindromes in DNA—A Risk for Genome Stability and Implications in Cancer Marina Svetec Mikleni´cand Ivan Krešimir Svetec * Faculty of Food Technology and Biotechnology, University of Zagreb, Pierottijeva 6, 10000 Zagreb, Croatia; [email protected] * Correspondence: [email protected]; Tel.: +385-1483-6016 Abstract: A palindrome in DNA consists of two closely spaced or adjacent inverted repeats. Certain palindromes have important biological functions as parts of various cis-acting elements and protein binding sites. However, many palindromes are known as fragile sites in the genome, sites prone to chromosome breakage which can lead to various genetic rearrangements or even cell death. The ability of certain palindromes to initiate genetic recombination lies in their ability to form secondary structures in DNA which can cause replication stalling and double-strand breaks. Given their recombinogenic nature, it is not surprising that palindromes in the human genome are involved in genetic rearrangements in cancer cells as well as other known recurrent translocations and deletions associated with certain syndromes in humans. Here, we bring an overview of current understanding and knowledge on molecular mechanisms of palindrome recombinogenicity and discuss possible implications of DNA palindromes in carcinogenesis. Furthermore, we overview the data on known palindromic sequences in the human genome and efforts to estimate their number and distribution, as well as underlying mechanisms of genetic rearrangements specific palindromic sequences cause. Keywords: DNA palindromes; quasipalindromes; palindromic amplification; palindrome-mediated genetic recombination; carcinogenesis Citation: Svetec Mikleni´c,M.; Svetec, I.K. Palindromes in DNA—A Risk for Genome Stability and Implications in Cancer. -

DNA Topology Influences P53 Sequence-Specific DNA Binding
DNA topology influences p53 sequence-specific DNA binding through structural transitions within the target sites Eva Brázdová Jagelská, Václav Brázda, Petr Pečinka, Emil Paleček, Miroslav Fojta To cite this version: Eva Brázdová Jagelská, Václav Brázda, Petr Pečinka, Emil Paleček, Miroslav Fojta. DNA topology influences p53 sequence-specific DNA binding through structural transitions within the target sites. Biochemical Journal, Portland Press, 2008, 412 (1), pp.57-63. 10.1042/BJ20071648. hal-00478935 HAL Id: hal-00478935 https://hal.archives-ouvertes.fr/hal-00478935 Submitted on 30 Apr 2010 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Biochemical Journal Immediate Publication. Published on 14 Feb 2008 as manuscript BJ20071648 DNA TOPOLOGY INFLUENCES P53 SEQUENCE-SPECIFIC DNA BINDING THROUGH STRUCTURAL TRANSITIONS WITHIN THE TARGET SITES Eva Brázdová Jagelskáa, Václav Brázdaa*, Petr Pečinkab, Emil Palečeka and Miroslav Fojtaa aInstitute of Biophysics, Academy of Sciences of the Czech Republic, 612 65 Brno, Czech Republic bFaculty of Science, University of Ostrava, 701 03 Ostrava, Czech Republic *Corresponding author Tel.: 420 541517231 Fax.: 420 541211293 e-mail: [email protected] Abbreviations: scDNA, supercoiled DNA; lin, linear DNA; o, oligodeoxynucleotide; SK, plasmid pBluescript SK-; fl, full length; wt, wild-type; Keywords: p53 protein / DNA binding / protein-DNA complex Short title: DNA topology affects p53 binding THIS IS NOT THE FINAL VERSION - see doi:10.1042/BJ20071648 Stage 2(a) POST-PRINT Page 1 Licenced copy. -

Cruciform Structures Are a Common DNA Feature Important for Regulating Biological Processes Václav Brázda1*, Rob C Laister2, Eva B Jagelská1 and Cheryl Arrowsmith3
Brázda et al. BMC Molecular Biology 2011, 12:33 http://www.biomedcentral.com/1471-2199/12/33 REVIEW Open Access Cruciform structures are a common DNA feature important for regulating biological processes Václav Brázda1*, Rob C Laister2, Eva B Jagelská1 and Cheryl Arrowsmith3 Abstract DNA cruciforms play an important role in the regulation of natural processes involving DNA. These structures are formed by inverted repeats, and their stability is enhanced by DNA supercoiling. Cruciform structures are fundamentally important for a wide range of biological processes, including replication, regulation of gene expression, nucleosome structure and recombination. They also have been implicated in the evolution and development of diseases including cancer, Werner’s syndrome and others. Cruciform structures are targets for many architectural and regulatory proteins, such as histones H1 and H5, topoisomerase IIb, HMG proteins, HU, p53, the proto-oncogene protein DEK and others. A number of DNA-binding proteins, such as the HMGB-box family members, Rad54, BRCA1 protein, as well as PARP-1 polymerase, possess weak sequence specific DNA binding yet bind preferentially to cruciform structures. Some of these proteins are, in fact, capable of inducing the formation of cruciform structures upon DNA binding. In this article, we review the protein families that are involved in interacting with and regulating cruciform structures, including (a) the junction- resolving enzymes, (b) DNA repair proteins and transcription factors, (c) proteins involved in replication and (d) chromatin-associated proteins. The prevalence of cruciform structures and their roles in protein interactions, epigenetic regulation and the maintenance of cell homeostasis are also discussed. Keywords: cruciform structure, inverted repeat, protein-DNA binding Review representation of inverted repeats, which occurs nonran- Genome sequencing projects have inundated us with domly in the DNA of all organisms, has been noted in information regarding the genetic basis of life. -

Chromosomal Instability Mediated by Non-B DNA: Cruciform Conformation and Not DNA Sequence Is Responsible for Recurrent Translocation in Humans
Downloaded from genome.cshlp.org on September 26, 2021 - Published by Cold Spring Harbor Laboratory Press Letter Chromosomal instability mediated by non-B DNA: Cruciform conformation and not DNA sequence is responsible for recurrent translocation in humans Hidehito Inagaki,1 Tamae Ohye,1 Hiroshi Kogo,1 Takema Kato,1,2 Hasbaira Bolor,2 Mariko Taniguchi,1,4 Tamim H. Shaikh,3 Beverly S. Emanuel,3 and Hiroki Kurahashi1,5 1Division of Molecular Genetics, Institute for Comprehensive Medical Science, Fujita Health University, Toyoake, Aichi 470-1192, Japan; 221st Century COE Program, Development Center for Targeted and Invasive Diagnosis and Treatment, Fujita Health University, Toyoake, Aichi 470-1192, Japan; 3Division of Human Genetics, The Children’s Hospital of Philadelphia and Department of Pediatrics, University of Pennsylvania School of Medicine, Philadelphia, Pennsylvania 19104, USA Chromosomal aberrations have been thought to be random events. However, recent findings introduce a new paradigm in which certain DNA segments have the potential to adopt unusual conformations that lead to genomic instability and nonrandom chromosomal rearrangement. One of the best-studied examples is the palindromic AT-rich repeat (PATRR), which induces recurrent constitutional translocations in humans. Here, we established a plasmid-based model that pro- motes frequent intermolecular rearrangements between two PATRRs in HEK293 cells. In this model system, the pro- portion of PATRR plasmid that extrudes a cruciform structure correlates to the levels of rearrangement. Our data suggest that PATRR-mediated translocations are attributable to unusual DNA conformations that confer a common pathway for chromosomal rearrangements in humans. [Supplemental material is available online at www.genome.org.] Chromosomal aberrations, including translocations or deletions, (Kurahashi et al. -

Recognition of Local DNA Structures by P53 Protein
International Journal of Molecular Sciences Review Recognition of Local DNA Structures by p53 Protein Václav Brázda * and Jan Coufal Institute of Biophysics, Academy of Sciences of the Czech Republic v.v.i., Královopolská 135, 612 65 Brno, Czech Republic; [email protected] * Correspondence: [email protected]; Tel.: +420-541-517-231 Academic Editor: Tomoo Iwakuma Received: 24 November 2016; Accepted: 3 February 2017; Published: 10 February 2017 Abstract: p53 plays critical roles in regulating cell cycle, apoptosis, senescence and metabolism and is commonly mutated in human cancer. These roles are achieved by interaction with other proteins, but particularly by interaction with DNA. As a transcription factor, p53 is well known to bind consensus target sequences in linear B-DNA. Recent findings indicate that p53 binds with higher affinity to target sequences that form cruciform DNA structure. Moreover, p53 binds very tightly to non-B DNA structures and local DNA structures are increasingly recognized to influence the activity of wild-type and mutant p53. Apart from cruciform structures, p53 binds to quadruplex DNA, triplex DNA, DNA loops, bulged DNA and hemicatenane DNA. In this review, we describe local DNA structures and summarize information about interactions of p53 with these structural DNA motifs. These recent data provide important insights into the complexity of the p53 pathway and the functional consequences of wild-type and mutant p53 activation in normal and tumor cells. Keywords: p53 protein; local DNA structures; protein-DNA interactions 1. Introduction p53 is one of the most intensively studied tumor suppressor proteins and its regulation and relation to cancer has been reviewed extensively [1–3]. -
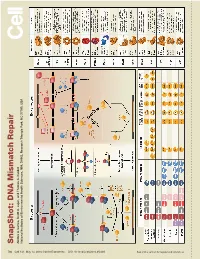
S Na P S H O T: D N a Mism a Tc H R E P a Ir
SnapShot: Repair DNA Mismatch Scott A. Lujan, and Thomas Kunkel A. Larrea, Andres Park, NC 27709, USA Triangle Health Sciences, NIH, DHHS, Research National Institutes of Environmental 730 Cell 141, May 14, 2010 ©2010 Elsevier Inc. DOI 10.1016/j.cell.2010.05.002 See online version for legend and references. SnapShot: DNA Mismatch Repair Andres A. Larrea, Scott A. Lujan, and Thomas A. Kunkel National Institutes of Environmental Health Sciences, NIH, DHHS, Research Triangle Park, NC 27709, USA Mismatch Repair in Bacteria and Eukaryotes Mismatch repair in the bacterium Escherichia coli is initiated when a homodimer of MutS binds as an asymmetric clamp to DNA containing a variety of base-base and insertion-deletion mismatches. The MutL homodimer then couples MutS recognition to the signal that distinguishes between the template and nascent DNA strands. In E. coli, the lack of adenine methylation, catalyzed by the DNA adenine methyltransferase (Dam) in newly synthesized GATC sequences, allows E. coli MutH to cleave the nascent strand. The resulting nick is used for mismatch removal involving the UvrD helicase, single-strand DNA-binding protein (SSB), and excision by single-stranded DNA exonucleases from either direction, depending upon the polarity of the nick relative to the mismatch. DNA polymerase III correctly resynthesizes DNA and ligase completes repair. In bacteria lacking Dam/MutH, as in eukaryotes, the signal for strand discrimination is uncertain but may be the DNA ends associated with replication forks. In these bacteria, MutL harbors a nick-dependent endonuclease that creates a nick that can be used for mismatch excision. Eukaryotic mismatch repair is similar, although it involves several dif- ferent MutS and MutL homologs: MutSα (MSH2/MSH6) recognizes single base-base mismatches and 1–2 base insertion/deletions; MutSβ (MSH2/MSH3) recognizes insertion/ deletion mismatches containing two or more extra bases.