Testing Assumptions: Normality and Equal Variances
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hypothesis Testing and Likelihood Ratio Tests
Hypottthesiiis tttestttiiing and llliiikellliiihood ratttiiio tttesttts Y We will adopt the following model for observed data. The distribution of Y = (Y1, ..., Yn) is parameter considered known except for some paramett er ç, which may be a vector ç = (ç1, ..., çk); ç“Ç, the paramettter space. The parameter space will usually be an open set. If Y is a continuous random variable, its probabiiillliiittty densiiittty functttiiion (pdf) will de denoted f(yy;ç) . If Y is y probability mass function y Y y discrete then f(yy;ç) represents the probabii ll ii tt y mass functt ii on (pmf); f(yy;ç) = Pç(YY=yy). A stttatttiiistttiiicalll hypottthesiiis is a statement about the value of ç. We are interested in testing the null hypothesis H0: ç“Ç0 versus the alternative hypothesis H1: ç“Ç1. Where Ç0 and Ç1 ¶ Ç. hypothesis test Naturally Ç0 § Ç1 = ∅, but we need not have Ç0 ∞ Ç1 = Ç. A hypott hesii s tt estt is a procedure critical region for deciding between H0 and H1 based on the sample data. It is equivalent to a crii tt ii call regii on: a critical region is a set C ¶ Rn y such that if y = (y1, ..., yn) “ C, H0 is rejected. Typically C is expressed in terms of the value of some tttesttt stttatttiiistttiiic, a function of the sample data. For µ example, we might have C = {(y , ..., y ): y – 0 ≥ 3.324}. The number 3.324 here is called a 1 n s/ n µ criiitttiiicalll valllue of the test statistic Y – 0 . S/ n If y“C but ç“Ç 0, we have committed a Type I error. -

Data 8 Final Stats Review
Data 8 Final Stats review I. Hypothesis Testing Purpose: To answer a question about a process or the world by testing two hypotheses, a null and an alternative. Usually the null hypothesis makes a statement that “the world/process works this way”, and the alternative hypothesis says “the world/process does not work that way”. Examples: Null: “The customer was not cheating-his chances of winning and losing were like random tosses of a fair coin-50% chance of winning, 50% of losing. Any variation from what we expect is due to chance variation.” Alternative: “The customer was cheating-his chances of winning were something other than 50%”. Pro tip: You must be very precise about chances in your hypotheses. Hypotheses such as “the customer cheated” or “Their chances of winning were normal” are vague and might be considered incorrect, because you don’t state the exact chances associated with the events. Pro tip: Null hypothesis should also explain differences in the data. For example, if your hypothesis stated that the coin was fair, then why did you get 70 heads out of 100 flips? Since it’s possible to get that many (though not expected), your null hypothesis should also contain a statement along the lines of “Any difference in outcome from what we expect is due to chance variation”. Steps: 1) Precisely state your null and alternative hypotheses. 2) Decide on a test statistic (think of it as a general formula) to help you either reject or fail to reject the null hypothesis. • If your data is categorical, a good test statistic might be the Total Variation Distance (TVD) between your sample and the distribution it was drawn from. -

Use of Statistical Tables
TUTORIAL | SCOPE USE OF STATISTICAL TABLES Lucy Radford, Jenny V Freeman and Stephen J Walters introduce three important statistical distributions: the standard Normal, t and Chi-squared distributions PREVIOUS TUTORIALS HAVE LOOKED at hypothesis testing1 and basic statistical tests.2–4 As part of the process of statistical hypothesis testing, a test statistic is calculated and compared to a hypothesised critical value and this is used to obtain a P- value. This P-value is then used to decide whether the study results are statistically significant or not. It will explain how statistical tables are used to link test statistics to P-values. This tutorial introduces tables for three important statistical distributions (the TABLE 1. Extract from two-tailed standard Normal, t and Chi-squared standard Normal table. Values distributions) and explains how to use tabulated are P-values corresponding them with the help of some simple to particular cut-offs and are for z examples. values calculated to two decimal places. STANDARD NORMAL DISTRIBUTION TABLE 1 The Normal distribution is widely used in statistics and has been discussed in z 0.00 0.01 0.02 0.03 0.050.04 0.05 0.06 0.07 0.08 0.09 detail previously.5 As the mean of a Normally distributed variable can take 0.00 1.0000 0.9920 0.9840 0.9761 0.9681 0.9601 0.9522 0.9442 0.9362 0.9283 any value (−∞ to ∞) and the standard 0.10 0.9203 0.9124 0.9045 0.8966 0.8887 0.8808 0.8729 0.8650 0.8572 0.8493 deviation any positive value (0 to ∞), 0.20 0.8415 0.8337 0.8259 0.8181 0.8103 0.8206 0.7949 0.7872 0.7795 0.7718 there are an infinite number of possible 0.30 0.7642 0.7566 0.7490 0.7414 0.7339 0.7263 0.7188 0.7114 0.7039 0.6965 Normal distributions. -

Parametric and Non-Parametric Statistics for Program Performance Analysis and Comparison Julien Worms, Sid Touati
Parametric and Non-Parametric Statistics for Program Performance Analysis and Comparison Julien Worms, Sid Touati To cite this version: Julien Worms, Sid Touati. Parametric and Non-Parametric Statistics for Program Performance Anal- ysis and Comparison. [Research Report] RR-8875, INRIA Sophia Antipolis - I3S; Université Nice Sophia Antipolis; Université Versailles Saint Quentin en Yvelines; Laboratoire de mathématiques de Versailles. 2017, pp.70. hal-01286112v3 HAL Id: hal-01286112 https://hal.inria.fr/hal-01286112v3 Submitted on 29 Jun 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Public Domain Parametric and Non-Parametric Statistics for Program Performance Analysis and Comparison Julien WORMS, Sid TOUATI RESEARCH REPORT N° 8875 Mar 2016 Project-Teams "Probabilités et ISSN 0249-6399 ISRN INRIA/RR--8875--FR+ENG Statistique" et AOSTE Parametric and Non-Parametric Statistics for Program Performance Analysis and Comparison Julien Worms∗, Sid Touati† Project-Teams "Probabilités et Statistique" et AOSTE Research Report n° 8875 — Mar 2016 — 70 pages Abstract: This report is a continuation of our previous research effort on statistical program performance analysis and comparison [TWB10, TWB13], in presence of program performance variability. In the previous study, we gave a formal statistical methodology to analyse program speedups based on mean or median performance metrics: execution time, energy consumption, etc. -
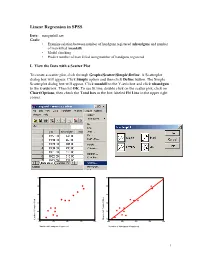
Linear Regression in SPSS
Linear Regression in SPSS Data: mangunkill.sav Goals: • Examine relation between number of handguns registered (nhandgun) and number of man killed (mankill) • Model checking • Predict number of man killed using number of handguns registered I. View the Data with a Scatter Plot To create a scatter plot, click through Graphs\Scatter\Simple\Define. A Scatterplot dialog box will appear. Click Simple option and then click Define button. The Simple Scatterplot dialog box will appear. Click mankill to the Y-axis box and click nhandgun to the x-axis box. Then hit OK. To see fit line, double click on the scatter plot, click on Chart\Options, then check the Total box in the box labeled Fit Line in the upper right corner. 60 60 50 50 40 40 30 30 20 20 10 10 Killed of People Number Number of People Killed 400 500 600 700 800 400 500 600 700 800 Number of Handguns Registered Number of Handguns Registered 1 Click the target button on the left end of the tool bar, the mouse pointer will change shape. Move the target pointer to the data point and click the left mouse button, the case number of the data point will appear on the chart. This will help you to identify the data point in your data sheet. II. Regression Analysis To perform the regression, click on Analyze\Regression\Linear. Place nhandgun in the Dependent box and place mankill in the Independent box. To obtain the 95% confidence interval for the slope, click on the Statistics button at the bottom and then put a check in the box for Confidence Intervals. -

Non Parametric Test: Chi Square Test of Contingencies
Weblinks http://www:stat.sc.edu/_west/applets/chisqdemo1.html http://2012books.lardbucket.org/books/beginning-statistics/s15-chi-square-tests-and-f- tests.html www.psypress.com/spss-made-simple Suggested Readings Siegel, S. & Castellan, N.J. (1988). Non Parametric Statistics for the Behavioral Sciences (2nd edn.). McGraw Hill Book Company: New York. Clark- Carter, D. (2010). Quantitative psychological research: a student’s handbook (3rd edn.). Psychology Press: New York. Myers, J.L. & Well, A.D. (1991). Research Design and Statistical analysis. New York: Harper Collins. Agresti, A. 91996). An introduction to categorical data analysis. New York: Wiley. PSYCHOLOGY PAPER No.2 : Quantitative Methods MODULE No. 15: Non parametric test: chi square test of contingencies Zimmerman, D. & Zumbo, B.D. (1993). The relative power of parametric and non- parametric statistics. In G. Karen & C. Lewis (eds.), A handbook for data analysis in behavioral sciences: Methodological issues (pp. 481- 517). Hillsdale, NJ: Lawrence Earlbaum Associates, Inc. Field, A. (2005). Discovering statistics using SPSS (2nd ed.). London: Sage. Biographic Sketch Description 1894 Karl Pearson(1857-1936) was the first person to use the term “standard deviation” in one of his lectures. contributed to statistical studies by discovering Chi square. Founded statistical laboratory in 1911 in England. http://www.swlearning.com R.A. Fisher (1890- 1962) Father of modern statistics was educated at Harrow and Cambridge where he excelled in mathematics. He later became interested in theory of errors and ultimately explored statistical problems like: designing of experiments, analysis of variance. He developed methods suitable for small samples and discovered precise distributions of many sample statistics. -

Pitfalls and Options in Hypothesis Testing for Comparing Differences in Means
Annals of Nuclear Cardiology Vol. 4 No. 1 83-87 REVIEW ARTICLE Statistics in Nuclear Cardiology: So, What’s the Difference? The t-Test: Pitfalls and Options in Hypothesis Testing for Comparing Differences in Means David N. Williams, PhD1), Kathryn A. Williams, MS2) and Michael Monuteaux, ScD3) Received: June 18, 2018/Revised manuscript received: July 19, 2018/Accepted: July 30, 2018 ○C The Japanese Society of Nuclear Cardiology 2018 Abstract Decisions related to differences of the measures of central tendency of population parameters are an important part of clinical research. Choice of the appropriate statistical test is critical to avoiding errors when making those decisions. All statistical tests require that one or more assumptions be met. The t-test is one of the most widely used tools but is not appropriate when assumptions such as normality are not met, especially when small samples, <40, are used. Non-parametric tests, such as the Wilcoxon rank sum and others, offer effective alternatives when there are questions about meeting assumptions. When normality is in question, the Wilcoxon non-parametric tests offer substantially higher levels of power and an reliable alternative to the t-test. Keywords: Assumptions, Difference of means, Mann-Whitney, Non-parametric, t-test, Violations, Wilcoxon Ann Nucl Cardiol 2018; 4(1): 83 -87 ome of the most important studies in clinical research and what degree those assumptions are violated should be an S decision-making are those related to differences in important step in analysis but one that is often left un-done (2). measures of central tendency of population parameters i.e. -

8.5 Testing a Claim About a Standard Deviation Or Variance
8.5 Testing a Claim about a Standard Deviation or Variance Testing Claims about a Population Standard Deviation or a Population Variance ² Uses the chi-squared distribution from section 7-4 → Requirements: 1. The sample is a simple random sample 2. The population has a normal distribution (n −1)s 2 → Test Statistic for Testing a Claim about or ²: 2 = 2 where n = sample size s = sample standard deviation σ = population standard deviation s2 = sample variance σ2 = population variance → P-values and Critical Values: Use table A-4 with df = n – 1 for the number of degrees of freedom *Remember that table A-4 is based on cumulative areas from the right → Properties of the Chi-Square Distribution: 1. All values of 2 are nonnegative and the distribution is not symmetric 2. There is a different 2 distribution for each number of degrees of freedom 3. The critical values are found in table A-4 (based on cumulative areas from the right) --locate the row corresponding to the appropriate number of degrees of freedom (df = n – 1) --the significance level is used to determine the correct column --Right-tailed test: Because the area to the right of the critical value is 0.05, locate 0.05 at the top of table A-4 --Left-tailed test: With a left-tailed area of 0.05, the area to the right of the critical value is 0.95 so locate 0.95 at the top of table A-4 --Two-tailed test: Divide the significance level of 0.05 between the left and right tails, so the areas to the right of the two critical values are 0.975 and 0.025. -

Inferential Statistics Katie Rommel-Esham Education 604 Probability
Inferential Statistics Katie Rommel-Esham Education 604 Probability • Probability is the scientific way of stating the degree of confidence we have in predicting something • Tossing coins and rolling dice are examples of probability experiments • The concepts and procedures of inferential statistics provide us with the language we need to address the probabilistic nature of the research we conduct in the field of education From Samples to Populations • Probability comes into play in educational research when we try to estimate a population mean from a sample mean • Samples are used to generate the data, and inferential statistics are used to generalize that information to the population, a process in which error is inherent • Different samples are likely to generate different means. How do we determine which is “correct?” The Role of the Normal Distribution • If you were to take samples repeatedly from the same population, it is likely that, when all the means are put together, their distribution will resemble the normal curve. • The resulting normal distribution will have its own mean and standard deviation. • This distribution is called the sampling distribution and the corresponding standard deviation is known as the standard error. Remember me? Sampling Distributions • As before, with the sampling distribution, approximately 68% of the means lie within 1 standard deviation of the distribution mean and 96% would lie within 2 standard deviations • We now know the probable range of means, although individual means might vary somewhat The Probability-Inferential Statistics Connection • Armed with this information, a researcher can be fairly certain that, 68% of the time, the population mean that is generated from any given sample will be within 1 standard deviation of the mean of the sampling distribution. -

Location-Scale Distributions
Location–Scale Distributions Linear Estimation and Probability Plotting Using MATLAB Horst Rinne Copyright: Prof. em. Dr. Horst Rinne Department of Economics and Management Science Justus–Liebig–University, Giessen, Germany Contents Preface VII List of Figures IX List of Tables XII 1 The family of location–scale distributions 1 1.1 Properties of location–scale distributions . 1 1.2 Genuine location–scale distributions — A short listing . 5 1.3 Distributions transformable to location–scale type . 11 2 Order statistics 18 2.1 Distributional concepts . 18 2.2 Moments of order statistics . 21 2.2.1 Definitions and basic formulas . 21 2.2.2 Identities, recurrence relations and approximations . 26 2.3 Functions of order statistics . 32 3 Statistical graphics 36 3.1 Some historical remarks . 36 3.2 The role of graphical methods in statistics . 38 3.2.1 Graphical versus numerical techniques . 38 3.2.2 Manipulation with graphs and graphical perception . 39 3.2.3 Graphical displays in statistics . 41 3.3 Distribution assessment by graphs . 43 3.3.1 PP–plots and QQ–plots . 43 3.3.2 Probability paper and plotting positions . 47 3.3.3 Hazard plot . 54 3.3.4 TTT–plot . 56 4 Linear estimation — Theory and methods 59 4.1 Types of sampling data . 59 IV Contents 4.2 Estimators based on moments of order statistics . 63 4.2.1 GLS estimators . 64 4.2.1.1 GLS for a general location–scale distribution . 65 4.2.1.2 GLS for a symmetric location–scale distribution . 71 4.2.1.3 GLS and censored samples . -

A Robust Rescaled Moment Test for Normality in Regression
Journal of Mathematics and Statistics 5 (1): 54-62, 2009 ISSN 1549-3644 © 2009 Science Publications A Robust Rescaled Moment Test for Normality in Regression 1Md.Sohel Rana, 1Habshah Midi and 2A.H.M. Rahmatullah Imon 1Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia 2Department of Mathematical Sciences, Ball State University, Muncie, IN 47306, USA Abstract: Problem statement: Most of the statistical procedures heavily depend on normality assumption of observations. In regression, we assumed that the random disturbances were normally distributed. Since the disturbances were unobserved, normality tests were done on regression residuals. But it is now evident that normality tests on residuals suffer from superimposed normality and often possess very poor power. Approach: This study showed that normality tests suffer huge set back in the presence of outliers. We proposed a new robust omnibus test based on rescaled moments and coefficients of skewness and kurtosis of residuals that we call robust rescaled moment test. Results: Numerical examples and Monte Carlo simulations showed that this proposed test performs better than the existing tests for normality in the presence of outliers. Conclusion/Recommendation: We recommend using our proposed omnibus test instead of the existing tests for checking the normality of the regression residuals. Key words: Regression residuals, outlier, rescaled moments, skewness, kurtosis, jarque-bera test, robust rescaled moment test INTRODUCTION out that the powers of t and F tests are extremely sensitive to the hypothesized error distribution and may In regression analysis, it is a common practice over deteriorate very rapidly as the error distribution the years to use the Ordinary Least Squares (OLS) becomes long-tailed. -

Testing Normality: a GMM Approach Christian Bontempsa and Nour
Testing Normality: A GMM Approach Christian Bontempsa and Nour Meddahib∗ a LEEA-CENA, 7 avenue Edouard Belin, 31055 Toulouse Cedex, France. b D´epartement de sciences ´economiques, CIRANO, CIREQ, Universit´ede Montr´eal, C.P. 6128, succursale Centre-ville, Montr´eal (Qu´ebec), H3C 3J7, Canada. First version: March 2001 This version: June 2003 Abstract In this paper, we consider testing marginal normal distributional assumptions. More precisely, we propose tests based on moment conditions implied by normality. These moment conditions are known as the Stein (1972) equations. They coincide with the first class of moment conditions derived by Hansen and Scheinkman (1995) when the random variable of interest is a scalar diffusion. Among other examples, Stein equation implies that the mean of Hermite polynomials is zero. The GMM approach we adopt is well suited for two reasons. It allows us to study in detail the parameter uncertainty problem, i.e., when the tests depend on unknown parameters that have to be estimated. In particular, we characterize the moment conditions that are robust against parameter uncertainty and show that Hermite polynomials are special examples. This is the main contribution of the paper. The second reason for using GMM is that our tests are also valid for time series. In this case, we adopt a Heteroskedastic-Autocorrelation-Consistent approach to estimate the weighting matrix when the dependence of the data is unspecified. We also make a theoretical comparison of our tests with Jarque and Bera (1980) and OPG regression tests of Davidson and MacKinnon (1993). Finite sample properties of our tests are derived through a comprehensive Monte Carlo study.