Principles of Building Scalable and Robust Event-Based Systems —Distributed Network-Centric Adaptation of Event Processing and Pub- Lish/Subscribe Dr
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Eakta Jain A. Professional Preparation: B. Appointments: C. Publications
Eakta Jain Department of Computer and Information Science and Engineering University of Florida Phone: (352) 562-3979 E-mail: [email protected] Webpage: jainlab.cise.ufl.edu A. Professional Preparation: Indian Institute of Technology Kanpur, India B.Tech. (Electrical Engineering) 2006 Carnegie Mellon University M.S. (Robotics) 2010 Carnegie Mellon University Ph.D. (Robotics) 2012 B. Appointments: 02/14 – present Assistant Professor, Department of Computer and Information Science and Engi- neering, University of Florida, Gainesville, FL 12/12-02/14 Member of Technical Staff, Texas Instruments Embedded Signal Processing Lab, Computer Vision Branch, Dallas, TX 07/12-12/12 Systems Software Engineer, Natural User Interfaces Team, Texas Instruments, Dallas, TX 09/11-01/12 Lab Associate, Disney Research Pittsburgh, PA 06/10-08/10 Lab Associate, Disney Research Pittsburgh, PA 06/08-08/08 Lab Associate, Disney Research Pittsburgh, PA 06/07-08/07 Walt Disney Animation Studios, Burbank, CA C. Publications: Is the Motion of a Child Perceivably Different from the Motion of an Adult? Jain, E., Anthony, L., Aloba, A., Castonguay, A., Cuba, I., Shaw, A. and Woodward, J. (2016). ACM Transactions on Applied Percep- tion (TAP), 13(4), Article 22. DOI: 10.1145/2947616 Decoupling Light Reflex from Pupillary Dilation to Measure Emotional Arousal in Videos, Rai- turkar, P., Kleinsmith, A., Keil, A., Banerjee, A., and Jain, E. (2016), ACM Symposium on Ap- plied Perception (SAP), 89-96. Gaze-driven Video Re-editing, Jain, E., Sheikh, Y., Shamir, A. and Hodgins, J., (2015), ACM Transac- tions on Graphics (TOG) (34, p21:1-p21:12). DOI: 10.1145/2699644 3D Saliency from Eye Tracking with Tomography, Ma, B., Jain, E., and Entezari, A. -

SIGOPS Annual Report 2012
SIGOPS Annual Report 2012 Fiscal Year July 2012-June 2013 Submitted by Jeanna Matthews, SIGOPS Chair Overview SIGOPS is a vibrant community of people with interests in “operatinG systems” in the broadest sense, includinG topics such as distributed computing, storaGe systems, security, concurrency, middleware, mobility, virtualization, networkinG, cloud computinG, datacenter software, and Internet services. We sponsor a number of top conferences, provide travel Grants to students, present yearly awards, disseminate information to members electronically, and collaborate with other SIGs on important programs for computing professionals. Officers It was the second year for officers: Jeanna Matthews (Clarkson University) as Chair, GeorGe Candea (EPFL) as Vice Chair, Dilma da Silva (Qualcomm) as Treasurer and Muli Ben-Yehuda (Technion) as Information Director. As has been typical, elected officers agreed to continue for a second and final two- year term beginning July 2013. Shan Lu (University of Wisconsin) will replace Muli Ben-Yehuda as Information Director as of AuGust 2013. Awards We have an excitinG new award to announce – the SIGOPS Dennis M. Ritchie Doctoral Dissertation Award. SIGOPS has lonG been lackinG a doctoral dissertation award, such as those offered by SIGCOMM, Eurosys, SIGPLAN, and SIGMOD. This new award fills this Gap and also honors the contributions to computer science that Dennis Ritchie made durinG his life. With this award, ACM SIGOPS will encouraGe the creativity that Ritchie embodied and provide a reminder of Ritchie's leGacy and what a difference a person can make in the field of software systems research. The award is funded by AT&T Research and Alcatel-Lucent Bell Labs, companies that both have a strong connection to AT&T Bell Laboratories where Dennis Ritchie did his seminal work. -

Department of Computer Science and Engineering
Department of Computer Science and Engineering Journals SJR Title ISSN SJR Quartile Country Molecular Systems Biology ISSN 17444292 8.87 Q1 United Kingdom IEEE Transactions on Pattern Analysis and Machine Intelligence ISSN 01628828 7.653 Q1 United States MIS Quarterly: Management Information Systems ISSN 02767783 6.984 Q1 United States Wiley Interdisciplinary Reviews: Computational Molecular Science ISSN 17590884, 17590876 6.715 Q1 United States Foundations and Trends in Machine Learning ISSN 19358237 6.194 Q1 United States IEEE Transactions on Fuzzy Systems ISSN 10636706 5.8 Q1 United States International Journal of Computer Vision ISSN 09205691 5.633 Q1 Netherlands Journal of Supply Chain Management ISSN 15232409 5.343 Q1 United Kingdom Journal of Operations Management ISSN 02726963 5.052 Q1 Netherlands IEEE Transactions on Smart Grid ISSN 19493053 4.784 Q1 United States Bioinformatics ISSN 13674811, 13674803 4.643 Q1 United Kingdom Information Systems Research ISSN 15265536, 10477047 4.397 Q1 United States IEEE Transactions on Evolutionary Computation ISSN 1089778X 4.308 Q1 United States IEEE Transactions on Automatic Control ISSN 00189286 4.238 Q1 United States International Journal of Robotics Research ISSN 02783649 4.184 Q1 United States Briefings in Bioinformatics ISSN 14774054, 14675463 4.086 Q1 United Kingdom SIAM Journal on Optimization ISSN 10526234, 10957189 3.943 Q1 United States IEEE Transactions on Systems, Man and Cybernetics Part B: Cybernetics ISSN 10834419 3.921 Q1 United States Internet and Higher Education ISSN 10967516 -

Shanlu › About › Cv › CV Shanlu.Pdf Shan Lu
Shan Lu University of Chicago, Dept. of Computer Science Phone: +1-773-702-3184 5730 S. Ellis Ave., Rm 343 E-mail: [email protected] Chicago, IL 60637 USA Homepage: http://people.cs.uchicago.edu/~shanlu RESEARCH INTERESTS Tool support for improving the correctness and efficiency of large scale software systems EMPLOYMENT 2019 – present Professor, Dept. of Computer Science, University of Chicago 2014 – 2019 Associate Professor, Dept. of Computer Sciences, University of Chicago 2009 – 2014 Assistant Professor, Dept. of Computer Sciences, University of Wisconsin – Madison EDUCATION 2008 University of Illinois at Urbana-Champaign, Urbana, IL Ph.D. in Computer Science Thesis: Understanding, Detecting, and Exposing Concurrency Bugs (Advisor: Prof. Yuanyuan Zhou) 2003 University of Science & Technology of China, Hefei, China B.S. in Computer Science HONORS AND AWARDS 2019 ACM Distinguished Member Among 62 members world-wide recognized for outstanding contributions to the computing field 2015 Google Faculty Research Award 2014 Alfred P. Sloan Research Fellow Among 126 “early-career scholars (who) represent the most promising scientific researchers working today” 2013 Distinguished Alumni Educator Award Among 3 awardees selected by Department of Computer Science, University of Illinois 2010 NSF Career Award 2021 Honorable Mention Award @ CHI for paper [C71] (CHI 2021) 2019 Best Paper Award @ SOSP for paper [C62] (SOSP 2019) 2019 ACM SIGSOFT Distinguished Paper Award @ ICSE for paper [C58] (ICSE 2019) 2017 Google Scholar Classic Paper Award for -

Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems Pdfauthor=Jonathan Mace, Ryan Roelke, Rodrigo Fonseca
PivoT Tracing:Dynamic Causal MoniToring for DisTribuTed SysTems JonaThan Mace Ryan Roelke Rodrigo Fonseca Brown UniversiTy AbsTracT MoniToring and TroubleshooTing disTribuTed sysTems is noToriously diõcult; poTenTial prob- lems are complex, varied, and unpredicTable. _e moniToring and diagnosis Tools commonly used Today – logs, counTers, and meTrics – have Two imporTanT limiTaTions: whaT gets recorded is deûned a priori, and The informaTion is recorded in a componenT- or machine-cenTric way, making iT exTremely hard To correlaTe events ThaT cross These boundaries. _is paper presents PivoT Tracing, a moniToring framework for disTribuTed sysTems ThaT addresses boTh limiTaTions by combining dynamic insTrumenTaTion wiTh a novel relaTional operaTor: The happened-before join. PivoT Tracing gives users, aT runTime, The abiliTy To deûne arbiTrary meTrics aT one poinT of The sysTem, while being able To selecT, ûlTer, and group by events mean- ingful aT oTher parts of The sysTem, even when crossing componenT or machine boundaries. We have implemenTed a proToType of PivoT Tracing for Java-based sysTems and evaluaTe iT on a heTerogeneous Hadoop clusTer comprising HDFS, HBase, MapReduce, and YARN. We show ThaT PivoT Tracing can eòecTively idenTify a diverse range of rooT causes such as soware bugs, misconûguraTion, and limping hardware. We show ThaT PivoT Tracing is dynamic, exTensible, and enables cross-Tier analysis beTween inTer-operaTing applicaTions, wiTh low execuTion overhead. Ë. InTroducTion MoniToring and TroubleshooTing disTribuTed sysTems -
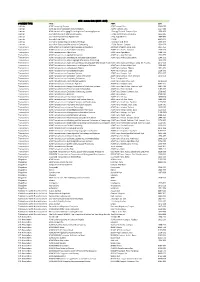
A ACM Transactions on Trans. 1553 TITLE ABBR ISSN ACM Computing Surveys ACM Comput. Surv. 0360‐0300 ACM Journal
ACM - zoznam titulov (2016 - 2019) CONTENT TYPE TITLE ABBR ISSN Journals ACM Computing Surveys ACM Comput. Surv. 0360‐0300 Journals ACM Journal of Computer Documentation ACM J. Comput. Doc. 1527‐6805 Journals ACM Journal on Emerging Technologies in Computing Systems J. Emerg. Technol. Comput. Syst. 1550‐4832 Journals Journal of Data and Information Quality J. Data and Information Quality 1936‐1955 Journals Journal of Experimental Algorithmics J. Exp. Algorithmics 1084‐6654 Journals Journal of the ACM J. ACM 0004‐5411 Journals Journal on Computing and Cultural Heritage J. Comput. Cult. Herit. 1556‐4673 Journals Journal on Educational Resources in Computing J. Educ. Resour. Comput. 1531‐4278 Transactions ACM Letters on Programming Languages and Systems ACM Lett. Program. Lang. Syst. 1057‐4514 Transactions ACM Transactions on Accessible Computing ACM Trans. Access. Comput. 1936‐7228 Transactions ACM Transactions on Algorithms ACM Trans. Algorithms 1549‐6325 Transactions ACM Transactions on Applied Perception ACM Trans. Appl. Percept. 1544‐3558 Transactions ACM Transactions on Architecture and Code Optimization ACM Trans. Archit. Code Optim. 1544‐3566 Transactions ACM Transactions on Asian Language Information Processing 1530‐0226 Transactions ACM Transactions on Asian and Low‐Resource Language Information Proce ACM Trans. Asian Low‐Resour. Lang. Inf. Process. 2375‐4699 Transactions ACM Transactions on Autonomous and Adaptive Systems ACM Trans. Auton. Adapt. Syst. 1556‐4665 Transactions ACM Transactions on Computation Theory ACM Trans. Comput. Theory 1942‐3454 Transactions ACM Transactions on Computational Logic ACM Trans. Comput. Logic 1529‐3785 Transactions ACM Transactions on Computer Systems ACM Trans. Comput. Syst. 0734‐2071 Transactions ACM Transactions on Computer‐Human Interaction ACM Trans. -

An Oral History of Computer Science Cornell University
An Oral History of Computer Science at Cornell University https://ecommons.cornell.edu/handle/1813/40569 Gates Hall, Cornell University Twelve senior faculty members share their personal journeys and their recollections of the early days of computer science at Cornell University and the leadership role in bringing a new field of study into existence. Birman, Ken Hopcroft, John E Cardie, Claire Kozen, Dexter Constable, Robert Nerode, Anil Conway, Richard W. Schneider, Fred B Gries, David Teitelbaum, Tim Hartmanis, Juris Van Loan, Charlie (Click on a name above to scroll to an abstract and a live link to the associated streaming video.) version: 16Jun16 1. KEN BIRMAN Ken Birman, who joined CS in 1981, exemplifies the successful synergy of research and entrepreneurial activities. His research in distributed systems led to his founding ISIS Distributed Systems, Inc., in 1988, which developed software used by the New York Stock Exchange (NYSE) and Swiss Exchange, the French Air Traffic Control sys- tem, the AEGIS warship, and others. He started two other companies, Reliable Network Solutions and Web Sci- ences LLC. This entrepreneurship has in turn generated new research ideas and has also led to Ken’s advising various organi- zations on distributed systems and cloud computing, including the French Civil Aviation Organization, the north- eastern electric power grid, NATO, the US Treasury, and the US Air Force. Ken has received several awards for his research, among them the IEEE Tsutomu Kanai Award for his work on trustworthy computing, the Cisco “Technology Visionary” award, and the ACM SIGOPS Hall of Fame Award. He also has written two successful texts. -
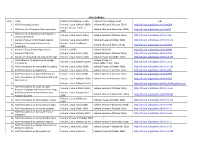
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11. -

Semperos: a Distributed Capability System
SemperOS: A Distributed Capability System Matthias Hille† Nils Asmussen† ∗ Pramod Bhatotia‡ Hermann Härtig† ∗ †Technische Universität Dresden ‡The University of Edinburgh ∗ Barkhausen Institut Abstract systems have received renewed attention recently to provide Capabilities provide an efficient and secure mechanism for an efficient and secure mechanism for resource management fine-grained resource management and protection. However, in modern hardware architectures [5, 24, 30, 36, 44, 64, 67]. as the modern hardware architectures continue to evolve Today the main improvements in compute capacity with large numbers of non-coherent and heterogeneous cores, are achieved by either adding more cores or integrating we focus on the following research question: can capability accelerators into the system. However, the increasing core systems scale to modern hardware architectures? counts exacerbate the hardware complexity required for global In this work, we present a scalable capability system to drive cache coherence. While on-chip cache coherence is likely to future systems with many non-coherent heterogeneous cores. remain a feature of future hardware architectures [45], we see More specifically, we have designed a distributed capability characteristics of distributed systems added to the hardware system based on a HW/SW co-designed capability system. by giving up on global cache coherence across a whole We analyzed the pitfalls of distributed capability operations machine [6, 28]. Additionally, various kinds of accelerators running concurrently and built the protocols in accordance are added like the Xeon Phi Processor, the Matrix-2000 accel- with the insights. We have incorporated these distributed erator, GPUs, FPGAs, or ASICs, which are used in numerous capability management protocols in a new microkernel-based application fields [4,21,32,34,43,60]. -

1 Acmsmall Author Submission Guide: Setting up Your Latex2ε Files
1 acmsmall Author Submission Guide: Setting Up Your LATEX2ε Files DONALD E. KNUTH, Stanford University LESLIE LAMPORT, Microsoft Corporation A The LTEX 2ε acmsmall document class formats articles in the style of the ACM small size journals and A transactions. Users who have prepared their document with LTEX 2ε can, with very little effort, produce camera-ready copy for these journals. Categories and Subject Descriptors: D.2.7 [Software Engineering]: Distribution and Maintenance—doc- umentation; H.4.0 [Information Systems Applications]: General; I.7.2 [Text Processing]: Document Preparation—languages; photocomposition General Terms: Documentation, Languages Additional Key Words and Phrases: Document preparation, publications, typesetting ACM Reference Format: Donald E. Knuth and Leslie Lamport. 2010. acmsmall Author submission guide: setting up your LATEX 2ε files. ACM Comput. Surv. 2, 3, Article 1 (July 2010), 14 pages. DOI:http://dx.doi.org/10.1145/0000000.0000000 1. INTRODUCTION This article is a description of the LATEX 2ε acmsmall document class for typesetting articles in the format of the ACM small size transactions and journals—Transactions on Programming Languages and Systems, Journal of the ACM, etc. It has, of course, been typeset using this document class, so it is a self-illustrating article. The reader is assumed to be familiar with LATEX, as described by Lamport [1986]. This document also describes the acmsmall bibliography style. LATEX 2ε is a document preparation system implemented as a macro package in Don- ald Knuth’s TEX typesetting system [Knuth 1984]. It is based upon the premise that the user should describe the logical structure of his document and not how the docu- ment is to be formatted. -

Distributed Event Routing in Publish/Subscribe Communication Systems: a Survey
Distributed Event Routing in Publish/Subscribe Communication Systems: a Survey Roberto Baldoni1, Leonardo Querzoni1, and Antonino Virgillito1 Dipartimento di Informatica e Sistemistica Universit`adi Roma “La Sapienza” Abstract. Distributed event routing has emerged as a key technology for achieving scalable information dissemination. In particular it has been used as preferential com- munication backbone within publish/subscribe communication system. Its aim is to reduce the network and computational overhead per event diffusion to a set (possibly large) of interested recipients. This paper introduces an unifying framework, namely a publish/subscribe architecture, that points out the functional decomposition be- tween event-based routing layer, the overlay infrastructure layer and the network protocols layer. Hence the paper, firstly, surveys current algorithms for event based routing and possible overlay infrastructures in wired and mobile systems and, sec- ondly, it discusses how and when single solutions at each level can be combined in the publish/subscribe architecture. Finally the paper positions existing publish/subscribe systems within the proposed architecture. 1 Introduction Since the early nineties, anonymous and asynchronous dissemination of information has been a basic building block for typical distributed application such as stock exchanges, news tickers and air-traffic control. With the advent of ubiquitous com- puting and of the ambient intelligence, information dissemination solutions have to face challenges such as the exchange of huge amounts of information, large and dynamic number of participants possibly deployed over a large network (e.g. peer- to-peer systems), mobility and scarcity of resources (e.g. mobile ad-hoc and sensor networks) [1]. Publish/Subscribe (pub/sub) systems are a key technology for information dis- semination. -

Operating Systems and Middleware: Supporting Controlled Interaction
Operating Systems and Middleware: Supporting Controlled Interaction Max Hailperin Gustavus Adolphus College Revised Edition 1.1 July 27, 2011 Copyright c 2011 by Max Hailperin. This work is licensed under the Creative Commons Attribution-ShareAlike 3.0 Unported License. To view a copy of this license, visit http://creativecommons.org/licenses/by-sa/3.0/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. Bibliography [1] Atul Adya, Barbara Liskov, and Patrick E. O’Neil. Generalized iso- lation level definitions. In Proceedings of the 16th International Con- ference on Data Engineering, pages 67–78. IEEE Computer Society, 2000. [2] Alfred V. Aho, Peter J. Denning, and Jeffrey D. Ullman. Principles of optimal page replacement. Journal of the ACM, 18(1):80–93, 1971. [3] AMD. AMD64 Architecture Programmer’s Manual Volume 2: System Programming, 3.09 edition, September 2003. Publication 24593. [4] Dave Anderson. You don’t know jack about disks. Queue, 1(4):20–30, 2003. [5] Dave Anderson, Jim Dykes, and Erik Riedel. More than an interface— SCSI vs. ATA. In Proceedings of the 2nd Annual Conference on File and Storage Technology (FAST). USENIX, March 2003. [6] Ross Anderson. Security Engineering: A Guide to Building Depend- able Distributed Systems. Wiley, 2nd edition, 2008. [7] Apple Computer, Inc. Kernel Programming, 2003. Inside Mac OS X. [8] Apple Computer, Inc. HFS Plus volume format. Technical Note TN1150, Apple Computer, Inc., March 2004. [9] Ozalp Babaoglu and William Joy. Converting a swap-based system to do paging in an architecture lacking page-referenced bits.