End-To-End and Direct Human-Flying Robot Interaction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Intel® Desktop Board D33217GKE
Intel® Desktop Board D33217GKE Next Unit of Computing by Intel® • Superior processing and graphics • Stunningly small form factor • Advanced Technologies producT brief Next Unit of Computing by Intel® with Intel® Desktop Board D33217GKE 4” (10 cm) Think you know what small can do? Think again. No more compromising between performance, profile, and price. The Next Unit of Computing (NUC) is a tiny 4”×4”×2” computing device with the power of the 3rd generation Intel® Core™ i3 processor. Its lower power consumption enables innovative system designs and energy- efficient applications in places like digital signage, home entertainment, and portable uses. Superior processing and graphics Visibly smart graphics using the 3rd generation Intel® Core™ i3-3217U processor deliver amaz- ing performance and visually stunning graphics. Stunningly small form factor The 4”×4”×2” form factor unlocks a world of potential design applications, from digital signage and kiosks to portable innovations. 4” (10 cm) Advanced Technologies The NUC features two SO-DIMM sockets for expandability upto 16 GB of memory, two PCIe* mini-card connectors for flexible support of wireless and SSD configurations, BIOS vault tech- nology, fast boot and the Intel® Visual BIOS. The NUC also supports Intel® Anti-Theft™ Technol- ogy providing hardware intelligence designed to protect your device and its data if its lost or stolen. Intel® Core™ i3-3217U Processor Intel® QS77 Express Chipset 2 Intel® Desktop Board D33217GKE Features and Benefits 1 × USB 2.0 connector on the front panel -

Draft NISTIR 8320A, Hardware-Enabled Security
NISTIR 8320A Hardware-Enabled Security: Container Platform Security Prototype Michael Bartock Murugiah Souppaya Jerry Wheeler Tim Knoll Uttam Shetty Ryan Savino Joseprabu Inbaraj Stefano Righi Karen Scarfone This publication is available free of charge from: https://doi.org/10.6028/NIST.IR.8320A NISTIR 8320A Hardware-Enabled Security: Container Platform Security Prototype Michael Bartock Joseprabu Inbaraj Murugiah Souppaya Stefano Righi Computer Security Division AMI Information Technology Laboratory Atlanta, GA Jerry Wheeler Karen Scarfone Tim Knoll Scarfone Cybersecurity Uttam Shetty Clifton, VA Ryan Savino Intel Corporation Santa Clara, CA This publication is available free of charge from: https://doi.org/10.6028/NIST.IR.8320A June 2021 U.S. Department of Commerce Gina Raimondo, Secretary National Institute of Standards and Technology James K. Olthoff, Performing the Non-Exclusive Functions and Duties of the Under Secretary of Commerce for Standards and Technology & Director, National Institute of Standards and Technology National Institute of Standards and Technology Interagency or Internal Report 8320A 48 pages (June 2021) This publication is available free of charge from: https://doi.org/10.6028/NIST.IR.8320A Certain commercial entities, equipment, or materials may be identified in this document in order to describe an experimental procedure or concept adequately. Such identification is not intended to imply recommendation or endorsement by NIST, nor is it intended to imply that the entities, materials, or equipment are necessarily the best available for the purpose. There may be references in this publication to other publications currently under development by NIST in accordance with its assigned statutory responsibilities. The information in this publication, including concepts and methodologies, may be used by federal agencies even before the completion of such companion publications. -

Cisco Enterprise Wireless
Cisco Enterprise Wireless Intuitive Wi-Fi starts here 2nd edition Preface 7 Authors 8 Acknowledgments 10 Organization of this book 11 Intended audience 12 Book writing methodology 13 What is new in this edition of the book? 14 Introduction 15 Intent-based networking 16 Introducing Cisco IOS® XE for Cisco Catalyst® wireless 18 Benefits of Cisco IOS XE 19 Cisco wireless portfolio 22 Infrastructure components 29 Introduction 30 Deployment mode flexibility 32 Resiliency in wireless networks 41 Wireless network automation 58 Programmability 61 Radio excellence 63 Introduction 64 802.11ax/Wi-Fi 6 66 High density experience (HDX) 71 Hardware innovations 77 Introduction 78 Dual 5 GHz radio 79 Modularity 83 Multigigabit 85 CleanAir-SAgE 87 RF ASIC - software defined radio 89 Innovative AP deployment solutions 91 Infrastructure security 97 Introduction 98 Securing the network 100 Securing the air 109 Encrypted Traffic Analytics (ETA) 114 WPA3 119 Policy 121 Introduction 122 Security policy 123 QoS policy 132 Analytics 145 Introduction 146 Enhanced experience through partnerships 148 Cisco DNA Center – wireless assurance 150 Cisco location technology explained 156 Cisco DNA Spaces 160 Migrating to Catalyst 9800 163 The Catalyst 9800 configuration model 164 Configuration conversion tools 168 Inter-Release Controller Mobility (IRCM) 171 Summary 175 The next generation of wireless 176 References 177 Acronyms 178 Further reading 183 Preface 8 Preface Authors In May 2018, a group of engineers from diverse backgrounds and geographies gathered together in San Jose, California in an intense week-long collaborative effort to write about their common passion, enterprise wireless networks. This book is a result of that effort. -

Content Creation Solution Brief
Content Creation Solution Brief Intel® NUC delivers stunning visuals and edge-of-your-seat performance in an ultra-small package. Powered by a visibly smart 3rd generation Intel® Core™ i5 processor on a 4-by-4 inch board and enclosed in a tiny case, the Intel NUC is big on performance yet surprisingly small in size. It’s an ideal form factor that can be easily transported to the studio, while packing the horsepower to record, mix, create, and play back amazing audio and video content. Intel NUC is the definitive crowd-pleaser for today’s prosumer. B007 Multiscreen Content Creaton Setup Technologies This section offers a guideline for the hardware and software needed to design Intel NUC into a small form factor prosumer solution. Included in Intel NUC Kit: • Intel NUC – DC53427HYE • VESA Bracket • Power Adapter Hardware Needed Quantity Item Manufacturer Model 1 Intel® NUC DC53427HYE Intel® Intel® Next Unit of Computing Kit DC53427HYE 2 Memory Any 4 GB DDR3 1600 SODIMM 1 Storage Intel Intel® Solid-State Drive 525 Series 240 GB mSATA 1 Intel® Centrino Wireless Intel Intel Centrino 6235 IEEE 802.11n Mini PCI Express* Bluetooth* 4.0 - Wi-Fi/Bluetooth Combo Adapter 2 Display Port Capable Displays Any Any 1 HDMI Capable Display Any Any 1 USB Audio Interface Any Any 2 Reference Monitor Speakers Any Any 1 External Storage Any Any USB or Network Attached Storage Software Needed Item Manufacturer Model Pro Tools* Avid® Technology, Inc. http://www.avid.com/ Windows* 7 Microsoft* http://windows.microsoft.com Note: For more information on the software listed in this table, contact the manufacturer of the software directly. -

Bringing Two SGET Standards Together
boards & solutions + Combined Print Magazine for the European Embedded Market November 06/15 COVER STORY: Modular embedded NUC systems with Qseven modules Bringing two SGET Standards together SPECIAL FEATURES: SPECIAL ISSUE Boards & Modules Industrial Control Industrial Communications Industrial Internet-of-Things VIEWPOINT Dear Readers, And once again its show time! Beside the exhibition Embedded World in springtime there is another import- ant event for the embedded com- munity in Germany: SPS IPC Drives in fall. This year this international exhibition for industrial automa- tion will be held from 24th to 26th of November in the Exhibition Cen- tre in Nuremberg. More than 1,600 exhibitors including all key players in this industry will present their innovations and trend-setting new products as well as future technolo- gies. Main focus of many exhibitors this year will be Industrie 4.0. To simplify it for visitors getting infor- mation about this important topic the organizer created for the first time the “Industrie 4.0 Area” in Hall 3A. In this area there will be the joint stand and forum “Automation meets IT” which will present data based business models as well as IT based automation solutions for the future digital production. The joint stand “MES goes Automation“ will show how the use of MES optimizes order processing and production processes. The special show space SmartFactory will demonstrate the multi-vendor intelligent factory of the future. Industry associations ZVEI in hall 2 and VDMA in hall 3 will offer competent lectures and panel discussions about actual topics. The joint stands “AMA Centre for Sensors, Test and Measurement” and VDMA´s “Machine Vision” in hall 4A as well as “Wireless in Automation” will inform visitors extensive about the respective topics. -

Intel Next Unit of Computing Kit DC53427HYE UCFF, 1 X Core I5 3427U / 1.8 Ghz, RAM 0 MB, No HDD, HD Graphics 4000, Gigabit LAN, No OS, Vpro, Monitor : None
Siewert & Kau Computertechnik GmbH Walter-Gropius-Str. 12a DE 50126 Bergheim Telephone: 02271 - 763 0 Fax: 02271 - 763 280 E-Mail: [email protected] Internet: http://www.siewert-kau.com Intel Next Unit of Computing Kit DC53427HYE UCFF, 1 x Core i5 3427U / 1.8 GHz, RAM 0 MB, no HDD, HD Graphics 4000, Gigabit LAN, no OS, vPro, Monitor : none. A revolution in ultra-compact device design, Intel NUC packages a fully scalable, computing solution in the smallest possible form factor, complete with the Intel Core i5 processor. This computing device provides a flexible, customizable engine to drive digital signage, kiosks, and intelligent computing for small spaces, or anywhere else you can imagine. General information Intel Category Desktops & Servers Article number 103267 BOXDC53427HYE Technical specifications Product Description Intel Next Unit of Computing Kit DC53427HYE - Core i5 3427U 1.8 GHz - Monitor : none. Type PC barebone Platform Technology Intel vPro Technology Form Factor Ultra compact form factor Processor 1 x Intel Core i5 (3rd Gen) 3427U / 1.8 GHz ( 2.8 GHz ) ( Dual-Core ) Processor Main Features Hyper-Threading Technology, Intel Execute Disable Bit, Enhanced Intel SpeedStep Technology, Intel Virtualization Technology, Intel Turbo Boost Technology 2, Intel 64 Technology Cache Memory 3 MB Cache Per Processor 3 MB RAM 0 MB (installed) / 16 GB (max) - DDR3 SDRAM Hard Drive No HDD Monitor None. Graphics Controller Intel HD Graphics 4000 Audio Output Integrated - 7.1 channel surround Networking Gigabit LAN OS Provided No operating -
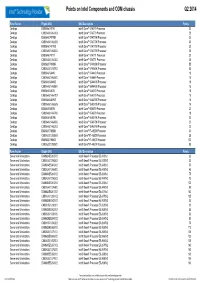
Q2 Matrix Final.Xlsx
Points on Intel Components and ODM chassis Q2 2014 Form Factor Eligble SKU SKU Description Points Desktop BX80646I74770 Intel® Core™ i7-4770 Processor 30 Desktop CM8064601464303 Intel® Core™ i7-4770 Processor 28 Desktop BX80646I74770K Intel® Core™ i7-4770K Processor 32 Desktop CM8064601464206 Intel® Core™ i7-4770K Processor 30 Desktop BX80646I74770S Intel® Core™ i7-4770S Processor 30 Desktop CM8064601465504 Intel® Core™ i7-4770S Processor 28 Desktop BX80646I74771 Intel® Core™ i7-4771 Processor 30 Desktop CM8064601464302 Intel® Core™ i7-4771 Processor 28 Desktop BX80633I74930K Intel® Core™ i7-4930K Processor 55 Desktop CM8063301292702 Intel® Core™ i7-4930K Processor 53 Desktop BX80646I54440 Intel® Core™ i5-4440 Processor 18 Desktop CM8064601464800 Intel® Core™ i5-4440 Processor 16 Desktop BX80646I54440S Intel® Core™ i5-4440S Processor 18 Desktop CM8064601465804 Intel® Core™ i5-4440S Processor 16 Desktop BX80646I54570 Intel® Core™ i5-4570 Processor 18 Desktop CM8064601464707 Intel® Core™ i5-4570 Processor 16 Desktop BX80646I54570S Intel® Core™ i5-4570S Processor 18 Desktop CM8064601465605 Intel® Core™ i5-4570S Processor 16 Desktop BX80646I54670 Intel® Core™ i5-4670 Processor 20 Desktop CM8064601464706 Intel® Core™ i5-4670 Processor 18 Desktop BX80646I54670K Intel® Core™ i5-4670K Processor 22 Desktop CM8064601464506 Intel® Core™ i5-4670K Processor 20 Desktop CM8064601465703 Intel® Core™ i5-4670S Processor 20 Desktop BX80633I74820K Intel® Core™i7-4820K Processor 30 Desktop CM8063301292805 Intel® Core™i7-4820K Processor 28 Desktop BX80633I74960X -

Intel® NUC Ecosystem Enabling Specification
Intel® NUC Updated: May 25, 2016 The shape that fits the future Table of Contents . Peripheral Suppliers . Chassis Suppliers . Lid Suppliers . VESA Extension Bracket . Expansion Board . Kiosk Stand . Mini UPS . Display Emulator 2 Peripheral Suppliers MODULE MODULE MODULE MODULE MANUFACTURER PART NUMBER SIZE SPEED SO-DIMM MEMORY * ADATA* AM1L16BC8R2-B1NS 8 GB 1601 MHz ADATA AM1L16BC4R1-B1MS 4 GB 1600 MHz ADATA AM1L16BC8R2-B1QS 8 GB 1600 MHz ADATA AM1L16BC4R1-B1PS 4 GB 1600 MHz ADATA* AXDS1600GC4G9-2 4 GB 1600 MHz A-DATA* AD73I1A0873EG 1 GB 1333 A-DATA EL73I1B1672ZU 2 GB 1333 A-DATA AD3S1333C2G9 4 GB 1333 A-DATA AD7311C1674EV 4 GB 1333 Apacer* 78.A2GC6.9L1 2 GB 1333 Centon Electronics M1050.01 8 GB 1600 MHz Centon Electronics M1051.01 8 GB 1600 MHz Centon Electronics M1052.01 8 GB 1600 MHz Crucial* CT51264BF160BJ 4 GB 1600 MHz Crucial CT102464BF160B.M16FED, CL11 8 GB 1600 MHz Crucial-Ballistix* BLS2K8G3N169ES4, CL9 8 GB x 2 1600 MHz Crucial* CT8G3S160BM 8 GB 1600 MHz Crucial CT51264BF160BJ.C8FER 4 GB 1600 MHz Elpida EBJ10UE8BDS0-DJ-F 1 GB 1333 Elpida EBJ21UE8BDS0-DJ-F 2 GB 1333 Elpida EBJ21UE8BFU0-DJ-F 2 GB 1333 G.Skill* F3-1866C11S-4GRSL 4 GB 1866 MHz G.Skill F3-1866C11S-8GRSL 8 GB 1866 MHz G.Skill F3-1866C10S-4GRSL 4 GB 1866 MHz Cont… 4 Peripheral Suppliers MODULE MODULE MODULE MODULE MANUFACTURER PART NUMBER SIZE SPEED SO-DIMM MEMORY * G.Skill F3-1866C10S-8GRSL 8 GB 1866 MHz G.Skill F3-1333C9S-4GSL 4 GB 1333 MHz G.Skill F3-1333C9S-8GSL 8 GB 1333 MHz G.Skill F3-1600C11S-4GSL 4 GB 1600 MHz G.Skill F3-1600C11S-8GSL 8 GB 1600 MHz G.Skill -

Abkürzungs-Liste ABKLEX
Abkürzungs-Liste ABKLEX (Informatik, Telekommunikation) W. Alex 1. Juli 2021 Karlsruhe Copyright W. Alex, Karlsruhe, 1994 – 2018. Die Liste darf unentgeltlich benutzt und weitergegeben werden. The list may be used or copied free of any charge. Original Point of Distribution: http://www.abklex.de/abklex/ An authorized Czechian version is published on: http://www.sochorek.cz/archiv/slovniky/abklex.htm Author’s Email address: [email protected] 2 Kapitel 1 Abkürzungen Gehen wir von 30 Zeichen aus, aus denen Abkürzungen gebildet werden, und nehmen wir eine größte Länge von 5 Zeichen an, so lassen sich 25.137.930 verschiedene Abkür- zungen bilden (Kombinationen mit Wiederholung und Berücksichtigung der Reihenfol- ge). Es folgt eine Auswahl von rund 16000 Abkürzungen aus den Bereichen Informatik und Telekommunikation. Die Abkürzungen werden hier durchgehend groß geschrieben, Akzente, Bindestriche und dergleichen wurden weggelassen. Einige Abkürzungen sind geschützte Namen; diese sind nicht gekennzeichnet. Die Liste beschreibt nur den Ge- brauch, sie legt nicht eine Definition fest. 100GE 100 GBit/s Ethernet 16CIF 16 times Common Intermediate Format (Picture Format) 16QAM 16-state Quadrature Amplitude Modulation 1GFC 1 Gigabaud Fiber Channel (2, 4, 8, 10, 20GFC) 1GL 1st Generation Language (Maschinencode) 1TBS One True Brace Style (C) 1TR6 (ISDN-Protokoll D-Kanal, national) 247 24/7: 24 hours per day, 7 days per week 2D 2-dimensional 2FA Zwei-Faktor-Authentifizierung 2GL 2nd Generation Language (Assembler) 2L8 Too Late (Slang) 2MS Strukturierte -

Low-Level Hardware Programming for Non-Electrical Engineers
Low-Level Hardware Programming for Non-Electrical Engineers Jeff Tranter Integrated Computer Solutions, Inc. Agenda Agenda ● About the Speaker ● Introduction ● Some History ● Safety ● Some Basics ● Hardware Interfaces ● Sensors and Other Devices ● Embedded Development Platforms ● Relevant Qt APIs ● Linux Drivers and APIs ● Tips ● Gotchas ● References About The Speaker About The Speaker ●Jeff Tranter <[email protected]> ●Qt Consulting manager at Integrated Computer Solutions, Inc. ●Based in Ottawa, Canada ●Used Qt since 1.x ●Originally educated as Electrical Engineer Introduction Introduction Some History Some History ●1970s: Hard-coded logic ●1980s: 8-bit microprocessors (assembler) ●Today: 64-bit, multicore, 3D, etc. (high-level languages) ●This presentation won't cover: ●Programming languages other than C/C++ ●Much systems other than embedded Linux ●Video, sound ●Building embedded software: cross-compilation, debugging, etc. A Few Words About Safety A Few Words About Safety ●High voltage ●High current (e.g. batteries) ●High temperature (e.g. soldering) ●Eye protection (solder, clip leads) ●Chemicals ESD ESD ●Electrostatic discharge, i.e. static electricity ●Many devices can be damaged by high voltages from static ●Use static safe packaging, work mat, wrist strap, soldering iron Some Basics ●Ohms Law: I = V / R (sometimes E) ●Power P = V x I Measuring Measuring (e.g. with a multimeter) ●Voltage - in parallel (across) ●Current - in series (break the circuit) ●Resistance - out of circuit, powered off Electronic Components Common Electronic Components ●Passive components: ● resistor unit: Ohm (kilohm, megohm) ● capacitor unit: Farad (µF, nF, pF) ● inductor unit: Henry (µH, mH) ●Active components: ● vacuum tube (valve) ● diode/LED ● transistor (many types) ● ICs (many types) Electronic Components Common Electronic Components ●Components identified by: ● part identifier (e.g. -

Galileo, Linux and the Internet of Things
Galileo, Linux and the Internet of Things Brian DeLacey 1/15/2014 @ MIT BLU http://blu.org/cgi-bin/calendar/2014-jan IoT Festival – www.iotfestival.com 1 The parts of this talk Galileo Quark Arduino Linux Linux InstallFest on 3/1/2014 http://blu.org/cgi-bin/calendar/2014-ifest51 IoT (Internet of Things) IoT Festival on 2/22/2014 http://www.iotfestival.com/ Audience How many own a Galileo? How many own an Arduino? How many own a RPi, BBB, or other? Who writes code? Who does web development? Who does electronics / hardware? Who plans to “make” something this year? Who owns a thermostat? 2 Nice Nest Source: http://www.cnn.com , 1/14/2014 Hardware Evolution “How the Nest thermostat was created” CNN Money, 3/25/2013 ( link ) 3 Atom Next Unit of Computing (NUC) 4 Galileo What’s Next? Edison Galileo is not Edison Edison is in the future: http://www.intel.com/content/www/us/en/do- it-yourself/edison.html 5 Galileo Introduction to Galileo “The Intel® Galileo board is based on the Intel® Quark SoC X1000, a 32-bit Intel Pentium®-class system on a chip (SoC). It is the first board based on Intel® architecture designed to be hardware and software pin- compatible with shields designed for the Arduino Uno R3. The Galileo board is also software-compatible with the Arduino Software Development Environment, which makes getting started a snap.” Source: Intel® Galileo Product Brief https://communities.intel.com/docs/DOC-21836 6 Galileo Development Board Layout Matt’s Top 10 Shield Compatibility Familiar IDE Ethernet Library Compatibility -

Notebook • Alienware
Compatibilité Alienware - M11x (2nd-Gen Core i5/i7) Notebook Alienware - M14x Notebook (2nd Gen Intel Core) Alienware - M14x R2 Notebook Alienware - M17x (2nd-Gen Core i7) Notebook Alienware - M17x R3 Notebook Alienware - M17x R4 Notebook Alienware - M18X R2 Notebook AOpen - DE6100 Series AOpen - DE6140 Series ASRock - Mini PC CoreHT 252B ASRock - Mini PC M8 D45 ASRock - Mini PC M8 Z97-600W ASRock - Mini PC Vision 3D 241B ASRock - Mini PC Vision 3D 245B ASRock - Mini PC Vision 3D 252B ASRock - Mini PC Vision HT 311D ASRock - Mini PC Vision HT 312D ASRock - Mini PC Vision HT 321B ASRock - Mini PC Vision HT 323B ASRock - Mini PC Vision HT 400D ASRock - Mini PC Vision HT 420D ASRock - Mini PC Vision HT 421D ASRock - Mini PC VisionX 321B ASRock - Mini PC VisionX 323B ASRock - Mini PC VisionX 420D ASRock - Mini PC VisionX 421D ASRock - Mini PC VisionX 471D ASRock - Motherboard B75TM-ITX ASRock - Motherboard H61TM-ITX ASRock - Motherboard H77TM-ITX ASRock - Motherboard H81TM-ITX ASRock - Motherboard IMB-170 ASRock - Motherboard IMB-180 ASRock - Motherboard IMB-181-D ASRock - Motherboard IMB-181-L ASRock - Motherboard IMB-182 ASRock - Motherboard IMB-182-L ASRock - Motherboard IMB-184 ASRock - Motherboard IMB-185 ASRock - Motherboard Z77TM-ITX ASUS/ASmobile - A Series Notebook A55A ASUS/ASmobile - A Series Notebook A56CB ASUS/ASmobile - A Series Notebook A75VM ASUS/ASmobile - All-in-One PC ET2301INTH ASUS/ASmobile - All-in-One PC ET2702IGKH ASUS/ASmobile - All-in-One PC ET2702IGTH ASUS/ASmobile -