Dod 3235.1-H, Chap3
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Optimization of Configuration Management Processes
DEGREE PROJECT IN INFORMATION AND COMMUNICATION TECHNOLOGY, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2016 Optimization of Configuration Management Processes JOHAN KRISTENSSON KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF INFORMATION AND COMMUNICATION TECHNOLOGY Abstract Configuration management is a process for establishing and maintaining consistency of a product's performance, as well as functional and physical attributes with regards to requirements, design and operational information throughout its lifecycle. The way configuration management is implemented in a project has a huge impact on the project’s chance of success. Configuration management is, however, notoriously difficult to implement in a good way, i.e. in such a way that it increases performance and decrease the risk of projects. What works well in one field may be difficult to implement or will not work in another. The aim of this thesis is to present a process for optimizing configuration management processes, using a telecom company as a case study. The telecom company is undergoing a major overhaul of their customer relationship management system, and they have serious issues with quality of the software that is produced and meeting deadlines, and therefore wants to optimize its existing CM processes in order to help with these problems. Data collected in preparation for the optimization revealed that configuration management tools were not used properly, tasks that could be automated were done manually, and existing processes were not built on sound configuration management principles. The recommended optimization strategy would have been to fully implement a version handling tool, and change the processes to take better advantage of a properly implemented version handling tool. -

Industrial Maintenance
Industrial Maintenance Program CIP: 47.0303 – Industrial Maintenance Ordering Information Research and Curriculum Unit for Workforce Development Vocational and Technical Education Attention: Reference Room and Media Center Coordinator P.O. Drawer DX Mississippi State, MS 39762 www.rcu.msstate.edu/curriculum/download/ (662) 325-2510 Direct inquiries to Doug Ferguson Andy Sims Instructional Design Specialist Program Coordinator P.O. Drawer DX Office of Vocational Education and Workforce Mississippi State, MS 39762 Development (662) 325-2510 Mississippi Department of Education E-mail: [email protected] P.O. Box 771 Jackson, MS 39205 (601) 359-3479 E-mail: [email protected] Published by Office of Vocational and Technical Education Mississippi Department of Education Jackson, MS 39205 Research and Curriculum Unit for Workforce Development Vocational and Technical Education Mississippi State University Mississippi State, MS 39762 Robin Parker, EdD, Curriculum Coordinator Jolanda Harris, Educational Technologist The Research and Curriculum Unit (RCU), located in Starkville, MS, as part of Mississippi State University, was established to foster educational enhancements and innovations. In keeping with the land grant mission of Mississippi State University, the RCU is dedicated to improving the quality of life for Mississippians. The RCU enhances intellectual and professional development of Mississippi students and educators while applying knowledge and educational research to the lives of the people of the state. The RCU works within -

Operational Availability Modeling for Risk and Impact Analysis
Operational Availability Modeling for Risk and Impact Analysis David J. Hurst Manager Accreditation and Audits Aerospace Engineering and Project Management Division National Defence Headquarters Major General George R. Pearkes Building 400 Cumberland Street Ottawa, Ontario K1A 0K2 CANADA [email protected] ABSTRACT Availability is a system performance parameter which provides insight into the probability that an item or system will be available to be committed to a specified requirement. Depending on the application, availability can be defined to include reliability, maintainability and logistic support information. For fleet management purposes, the ability to quantify availability in terms of all of its contributing elements is essential. This paper provides a discussion on a steady state operational availability model which can be used to assist the Canadian Air Force in its aircraft fleet management requirements. The availability model embodies scheduled and unscheduled maintenance and allows for impact analysis using in-service maintenance data. The model is sensitive to fleet size, aircraft flying rate, frequency of downing events, aircraft maintainability, scheduled inspection frequency, and scheduled inspection duration. The predictive capability of this availability model is currently providing the Canadian Air Force with a more sophisticated maintenance analysis decision support capability. In order for this paper to be available for general distribution, it must be unclassified. As a result, the case studies presented do -

Milestones in Future Mobility, Annual Report 2018
ANNUAL REPORT 2018 #Milestones in Future Mobility ANNUAL 2018 ANNUAL REPORT We are inventing the mobility of the future, in which we think and work in new ways. We invite you to learn more about how we see the future today. CONTENTS 1 4 TO OUR SHAREHOLDERS CORPORATE Page 4 BMW Group in Figures GOVERNANCE Page 8 Report of the Supervisory Board Page 200 Statement on Corporate Governance Page 16 Statement of the Chairman of the (Part of the Combined Management Report) Board of Management Page 200 Information on the Company’s Governing Constitution Page 201 Declaration of the Board of Management and of the Page 20 BMW AG Stock and Capital Markets in 2018 Supervisory Board Pursuant to § 161 AktG Page 202 Members of the Board of Management Page 203 Members of the Supervisory Board Page 206 Composition and Work Procedures of the Board of 2 Management of BMW AG and its Committees Page 208 Composition and Work Procedures of the COMBINED Super visory Board of BMW AG and its Committees Page 215 Disclosures Pursuant to the Act on Equal MANAGEMENT REPORT Gender Participation Page 216 Information on Corporate Governance Practices Applied Page 26 General Information and Group Profile beyond Mandatory Requirements Page 26 Organisation and Business Model Page 218 Compliance in the BMW Group Page 36 Management System Page 223 Compensation Report Page 40 Report on Economic Position (Part of the Combined Management Report) Page 40 General and Sector-specific Environment Page 239 Responsibility Statement by the Page 44 Overall Assessment by Management Company’s -

World Bank Document
Public Disclosure Authorized .51 " I I -11 I Public Disclosure Authorized i i7 nt "li ! 'Ini 1r; r I.-I Public Disclosure Authorized 0 i i Public Disclosure Authorized EMP * WERMENT AND POVERTY REDUCTION A So u rce book EMP * WERMENT AND POVERTY REDUCTION A So u rce book Edited by Deepa Narayan THE WORLD BANK Washington, DC © 2002 The International Bank for Reconstruction and Development / The World Bank 1818 H Street, NW Washington, DC 20433 All rights reserved. First printing June 2002 1 2 3 4 05 04 03 02 The findings, interpretations, and conclusions expressed here are those of the author(s) and do not necessarily reflect the views of the Board of Executive Directors of the World Bank or the governments they represent. The World Bank cannot guarantee the accuracy of the data included in this work. The boundaries, colors, denominations, and other information shown on any map in this work do not imply on the part of the World Bank any judgment of the legal status of any territory or the endorsement or acceptance of such boundaries. Rights and Permissions The material in this work is copyrighted. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photo- copying, recording, or inclusion in any information storage and retrieval system, with- out the prior written permission of the World Bank. The World Bank encourages dis- semination of its work and will normally grant permission promptly. For permission to photocopy or reprint, please send a request with complete informa- tion to the Copyright Clearance Center, Inc., 222 Rosewood Drive, Danvers, MA, 01923, USA, telephone 978-750-8400, fax 978-750-4470, www.copyright.com. -

Configuration Management in Nuclear Power Plants
IAEA-TECDOC-1335 Configuration management in nuclear power plants January 2003 The originating Section of this publication in the IAEA was: Nuclear Power Engineering Section International Atomic Energy Agency Wagramer Strasse 5 P.O. Box 100 A-1400 Vienna, Austria CONFIGURATION MANAGEMENT IN NUCLEAR POWER PLANTS IAEA, VIENNA, 2003 IAEA-TECDOC-1335 ISBN 92–0–100503–2 ISSN 1011–4289 © IAEA, 2003 Printed by the IAEA in Austria January 2003 FOREWORD Configuration management (CM) is the process of identifying and documenting the characteristics of a facility’s structures, systems and components of a facility, and of ensuring that changes to these characteristics are properly developed, assessed, approved, issued, implemented, verified, recorded and incorporated into the facility documentation. The need for a CM system is a result of the long term operation of any nuclear power plant. The main challenges are caused particularly by ageing plant technology, plant modifications, the application of new safety and operational requirements, and in general by human factors arising from migration of plant personnel and possible human failures. The IAEA Incident Reporting System (IRS) shows that on average 25% of recorded events could be caused by configuration errors or deficiencies. CM processes correctly applied ensure that the construction, operation, maintenance and testing of a physical facility are in accordance with design requirements as expressed in the design documentation. An important objective of a configuration management program is to ensure that accurate information consistent with the physical and operational characteristics of the power plant is available in a timely manner for making safe, knowledgeable, and cost effective decisions with confidence. -

Life Cycle Management Services Integrated Logistics Support for Mission Critical Systems
Life Cycle Management Services Integrated Logistics Support for Mission Critical Systems Fleet management today is increasingly challenging. Aging fleets, budget constraints, and rising operation and maintenance (O&M) costs may represent your organization’s only constants. Fleet managers can benefit significantly from accurate performance data, O&M scenario simulation, trending, and other specialized life cycle management tools and services. CAE is a world leader in life cycle management and in-service Integrated Logistics Support (ILS). Over the last 20 years, CAE has built an international reputation for ILS engineering excellence through its support programs for the Canadian Forces’ CF-18 fleet and managing stringent ILS programs for numerous military customers around the world. Using field data and cutting-edge technology, we monitor aircraft and support network performance. Our team excels at identifying, validating, and analyzing the impacts of performance metric variations on fleet operations, logistics networks, and resources before adverse effects are experienced. CAE extends your analysis and modelling capabilities by providing an innovative, flexible, competent, and dedicated workforce. Fleet managers are empowered with up-to-date information and can be confident in the decisions they make to ensure long-term cost-effective support solutions. Achievements Benefits Identification of significant cost savings resulting from: • Superior lifecycle management • Full fleet/item sparing support program • Enabling performance-based management -

Interconnections Between Reliability, Maintenance and Availability
Interconnections between Reliability, Maintenance and Availability Catalin Mihai, Sorin Abagiu, Larisa Zoitanu, and Elena Helerea Transilvania University of Brasov, 29, Eroilor Str., Brasov, Romania [email protected] Abstract. The assurance of power quality depends on factors which influence the performances of the availability: the reliability and its support – the mainte- nance. This paper deals with the interactions between the indicators of reliabil- ity, maintenance, availability and with the methods for the calculation of the reliability indicators. For an overhead line of 110 kV the characteristics of the reliability of the system are determined by modeling and analyzing its function- ality by the Markov process of continuous time. The value of the availability index and the maintenance function function contributes to ascertain for the studied case that the value of the availability coefficient has the same value with the probability of success and the probability of repairing an equipment is closely connected to the maintenance function. Keywords: Reliability, maintenance, availability, Markov process, electric lines. 1 Introduction The equipment used on the power systems is relatively old and increases the financial effort for their maintenance. Therefore appear features of the electrical systems that are closely interrelated, such as: reliability, availability and maintenance, their interactions determining the qualitative and quantitative aspects of the analyzed system, its safe operation. The reliability, as a feature of the system in fulfilling the specific functions in a certain period of time, continues to be the subject of many researches [1],[5],[7] and [10]. There are many papers [2],[8],[12] and [13] that have as a research subject the maintenance, their goal being to determine the optimum technical – organisational actions to maintain or to repair the system functionality. -
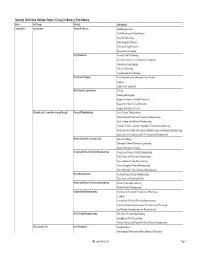
Industry Mapping File
Industry Definition Outline: Sector / Group / Industry / Subindustry Sector Ind. Group Industry Subindustry Commodities Agribusiness Animal Production Animal Aquaculture Cattle Ranching and Dairy Farming Hog and Pig Farming Other Animal Production Poultry and Egg Production Sheep and Goat Farming Crop Production Fruit and Tree Nut Farming Greenhouse, Nursery, and Floriculture Production Oilseed and Grain Farming Other Crop Farming Vegetable and Melon Farming Forestry and Logging Forest Nurseries and Gathering of Forest Products Logging Timber Tract Operations Miscellaneous Agribusiness Fishing Hunting and Trapping Support Activities for Animal Production Support Activities for Crop Production Support Activities for Forestry Materials and Commodities (except Energy) Chemical Manufacturing Basic Chemical Manufacturing Other Chemical Product and Preparation Manufacturing Paint, Coating, and Adhesive Manufacturing Pesticide, Fertilizer, and Other Agricultural Chemical Manufacturing Resin, Synthetic Rubber, and Artificial Synthetic Fibers and Filaments Manufacturing Soap, Cleaning Compound, and Toilet Preparation Manufacturing Mining (except Oil, Gas, and Coal) Metal Ore Mining Nonmetallic Mineral Mining and Quarrying Support Activities for Mining Nonmetallic Mineral Product Manufacturing Cement and Concrete Product Manufacturing Clay Product and Refractory Manufacturing Glass and Glass Product Manufacturing Lime and Gypsum Product Manufacturing Other Nonmetallic Mineral Product Manufacturing Paper Manufacturing Converted Paper Product Manufacturing -

The Coast Guard Integrated Logistics Support (ILS) Manual
U.S. Department of Homeland Security United States Coast Guard The Coast Guard Integrated Logistics Support (ILS) Manual COMDTINST M4105.14 March 2018 Distribution Statement A: Approved for public release. Distribution is unlimited. COMDTINST M4105.14 This page intentionally left blank. ii Commandant US Coast Guard Stop 7714 United States Coast Guard 2703 Martin Luther King JR Ave SE Washington DC 20597-7714 Staff Symbol: CG-444 Phone: 202 475 5637 Fax: 202 475 5955 COMDTINST M4105.14 March 12, 2018 COMMANDANT INSTRUCTION M4105.14 Subj: THE COAST GUARD INTEGRATED LOGISTICS SUPPORT (ILS) MANUAL Ref: (a) Information and Life Cycle Management Manual, COMDTINST M5212.12 (series) (b) Major Systems Acquisition Manual (MSAM) Handbook (series) (c) Coast Guard Configuration Management Manual, COMDTINST M4130.6 (series) (d) Diminishing Manufacturing Sources and Material Shortages (DMSMS) Manual, COMDTINST M4105.12 (series) (e) Supply Policy and Procedures Manual (SPPM), COMDTINST M4400.19 (series) (f) Deputy Commandant for Mission Support (DCMS) Engineering Technical Authority (ETA) Policy, COMDTINST 5402.4 (series) (g) Aeronautical Engineering Maintenance Management Manual, COMDTINST M13020.1 (series) (h) Provisioning Allowance and Fitting Out Support (PAFOS) Policies and Procedures Manual, NAVSEA 9090-1500 (i) Civil Engineering Manual, COMDTINST M11000.11 (series) (j) U.S. Coast Guard Real Property Management Manual, COMDTINST M11011.11 (series) 1. PURPOSE. This Manual establishes policy and procedures for the practice of the ILS process throughout the Coast Guard. 2. ACTION. All Coast Guard unit commanders, commanding officers, officers-in-charge, deputy/assistant commandants, and chiefs of headquarters staff elements must comply with the provisions of this Manual. Internet release is authorized. -

Reliabilty and Maintainability Objectives Hierarchy
Reliability and Maintainability Objectives Hierarchy R&M Objectives Hierarchy – Top Level Context: Expectations derived from crew safety, MMOD concerns, facility safety, public safety, mission obj., sustainment, …, considerations and associated risk tolerance Top Objective: System performs as required over the lifecycle to satisfy mission objectives Context: System/function description and requirements, including design information and interfaces Context: Reference mission + Strategy: Prevent faults and failures, provide mitigation before/after capabilities as needed to maintain an acceptable level of functionality considering safety, performance, and sustainability objectives Context: Range of nominal / off- nominal usage and conditions/ environments Objective: System Objective: System is Objective: System Objective: System remains functional tolerant to faults, failures is designed to have conforms to design intent for intended lifetime, and other anomalous an acceptable level and performs as planned environment, operating internal and external of availability and (1) conditions and usage events maintenance demands (2) (3) (4) R&M Hierarchy Objective: System conforms to design intent and Context: All other non-R&M centered performs as planned Sub – Obj. verification and validation activities (1) 1 Strategy: Verify and validate nominal Strategy: Test and inspect adequately to identify and resolve Strategy: Achieve high level of functionality process reliability (1.A) faults, issues and defects (1.B) (1.C) Objective: Nominal functionality -

Configuration Management Guidelines
Configuration Management Guidelines Date: April 2014 www.iaqg.org/scmh Section 7.5 Forward . The guideline describes Configuration Management functions and principles and defines Configuration Management terminology for use with Aerospace and Defense AS&D product line. It is targeted at Small and Medium size companies acting as subcontractors/suppliers either in a Build to Print or a Build to Spec relationship. The intention of these guidelines is to assist organizations with understanding the concept and process of Configuration Management and is not intended to be a requirement, nor auditable. 2 Introduction . The Aerospace Standards (e.g. IAQG 9100) call for the implementation of Configuration Management and documents control throughout the entire life cycle of product realization. Configuration Management establishes a language of understanding between the customer and the supplier both in predefined relationship (such as Built to Print) and those in which the supplier is given some freedom (such as Built to Spec). 3 Introduction . When Configuration Management principles are applied using effective practices, return on investment is maximized, product life cycle costs are reduced and the small investment in resources necessary for effective Configuration Management is returned many fold in cost avoidance. These Guidelines provide the reader with the basic ideas of the industry needs, the benefits to the implementing organization and describes Configuration Management functions and principles. 4 List of Topics 1. What is “Configuration”? 2. Why it is important to manage and control configuration in AS&D 3. Applicable Terms and Definitions 4. The objectives of Configuration Management 5. Benefits for an enterprise gained through application of CM 6.