Musical Trends and Predictability of Success in Contemporary Songs in and out of the Top Charts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Official Albums Chart Rules
Rules for Chart Eligibility Albums January 2020 Official Charts Operations Team 020 7620 7450 [email protected] www.officialcharts.com Rules for Chart Eligibility January 2020 INTRODUCTION The following Chart Rules exist to determine eligibility for entry into the Official UK Album Charts. The aim of the Rules is to protect the integrity of the Charts and to ensure that they are an accurate reflection of the popularity of each recording by reference to genuine transactions. The Rules apply equally to all companies issuing and/or distributing recordings. They set out the conditions on which an album will be eligible for inclusion in the Chart. The rules also apply to the UK’s Official genre charts, subject to variation where appropriate. It should be noted that record companies and distributors remain free to package and market their products in any way they choose. However, releases which do not comply with the Rules will not be eligible to be included in the Chart. The Chart Rules are issued by the Official Charts Company in conjunction with the Chart Supervisory Committee (CSC) under the supervision of the Official Charts Company board. The Official Charts Company is responsible for interpreting and applying the Chart Rules on a day-to-day basis under the supervision of the CSC. The Official Charts Company may, at its discretion, refer any matter concerning the interpretation of the Chart Rules with respect to one or more recordings to the CSC, a designated sub-committee of the CSC or the board, for a decision. The decision of the board will be final. -

The Roots of Middle-Earth: William Morris's Influence Upon J. R. R. Tolkien
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Doctoral Dissertations Graduate School 12-2007 The Roots of Middle-Earth: William Morris's Influence upon J. R. R. Tolkien Kelvin Lee Massey University of Tennessee - Knoxville Follow this and additional works at: https://trace.tennessee.edu/utk_graddiss Part of the Literature in English, British Isles Commons Recommended Citation Massey, Kelvin Lee, "The Roots of Middle-Earth: William Morris's Influence upon J. R. R. olkien.T " PhD diss., University of Tennessee, 2007. https://trace.tennessee.edu/utk_graddiss/238 This Dissertation is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a dissertation written by Kelvin Lee Massey entitled "The Roots of Middle-Earth: William Morris's Influence upon J. R. R. olkien.T " I have examined the final electronic copy of this dissertation for form and content and recommend that it be accepted in partial fulfillment of the equirr ements for the degree of Doctor of Philosophy, with a major in English. David F. Goslee, Major Professor We have read this dissertation and recommend its acceptance: Thomas Heffernan, Michael Lofaro, Robert Bast Accepted for the Council: Carolyn R. Hodges Vice Provost and Dean of the Graduate School (Original signatures are on file with official studentecor r ds.) To the Graduate Council: I am submitting herewith a dissertation written by Kelvin Lee Massey entitled “The Roots of Middle-earth: William Morris’s Influence upon J. -

Finding Aid for the Sheldon Harris Collection (MUM00682)
University of Mississippi eGrove Archives & Special Collections: Finding Aids Library November 2020 Finding Aid for the Sheldon Harris Collection (MUM00682) Follow this and additional works at: https://egrove.olemiss.edu/finding_aids Recommended Citation Sheldon Harris Collection, Archives and Special Collections, J.D. Williams Library, The University of Mississippi This Finding Aid is brought to you for free and open access by the Library at eGrove. It has been accepted for inclusion in Archives & Special Collections: Finding Aids by an authorized administrator of eGrove. For more information, please contact [email protected]. University of Mississippi Libraries Finding aid for the Sheldon Harris Collection MUM00682 TABLE OF CONTENTS SUMMARY INFORMATION Summary Information Repository University of Mississippi Libraries Biographical Note Creator Scope and Content Note Harris, Sheldon Arrangement Title Administrative Information Sheldon Harris Collection Related Materials Date [inclusive] Controlled Access Headings circa 1834-1998 Collection Inventory Extent Series I. 78s 49.21 Linear feet Series II. Sheet Music General Physical Description note Series III. Photographs 71 boxes (49.21 linear feet) Series IV. Research Files Location: Blues Mixed materials [Boxes] 1-71 Abstract: Collection of recordings, sheet music, photographs and research materials gathered through Sheldon Harris' person collecting and research. Prefered Citation Sheldon Harris Collection, Archives and Special Collections, J.D. Williams Library, The University of Mississippi Return to Table of Contents » BIOGRAPHICAL NOTE Born in Cleveland, Ohio, Sheldon Harris was raised and educated in New York City. His interest in jazz and blues began as a record collector in the 1930s. As an after-hours interest, he attended extended jazz and blues history and appreciation classes during the late 1940s at New York University and the New School for Social Research, New York, under the direction of the late Dr. -

What Handel Taught the Viennese About the Trombone
291 What Handel Taught the Viennese about the Trombone David M. Guion Vienna became the musical capital of the world in the late eighteenth century, largely because its composers so successfully adapted and blended the best of the various national styles: German, Italian, French, and, yes, English. Handel’s oratorios were well known to the Viennese and very influential.1 His influence extended even to the way most of the greatest of them wrote trombone parts. It is well known that Viennese composers used the trombone extensively at a time when it was little used elsewhere in the world. While Fux, Caldara, and their contemporaries were using the trombone not only routinely to double the chorus in their liturgical music and sacred dramas, but also frequently as a solo instrument, composers elsewhere used it sparingly if at all. The trombone was virtually unknown in France. It had disappeared from German courts and was no longer automatically used by composers working in German towns. J.S. Bach used the trombone in only fifteen of his more than 200 extant cantatas. Trombonists were on the payroll of San Petronio in Bologna as late as 1729, apparently longer than in most major Italian churches, and in the town band (Concerto Palatino) until 1779. But they were available in England only between about 1738 and 1741. Handel called for them in Saul and Israel in Egypt. It is my contention that the influence of these two oratorios on Gluck and Haydn changed the way Viennese composers wrote trombone parts. Fux, Caldara, and the generations that followed used trombones only in church music and oratorios. -

Download YAM011
yetanothermagazine filmtvmusic aug2010 lima film festival 2010 highlights blockbuster season from around the world in this yam we review // aftershocks, inception, toy story 3, the ghost writer, taeyang, se7en, boa, shinee, bibi zhou, jing chang, the derek trucks band, time of eve and more // yam exclusive interview with songwriter diane warren film We keep working on that, but there’s toy story 3 pg4 the ghost writer pg5 so much territory to cover, and so You know the address: aftershocks pg6 very little of us. This is why we need [email protected] inception pg7 lima film festival// yam contributors. We know our highlights pg9 readers are primarily located in the amywong // cover// US, but I’m hoping to get people yam exclusive from other countries to review their p.s.: I actually spoke to Diane interview with diane warren pg12 local releases. The more the merrier, Warren. She's like the soundtrack music people. of our lives, to anyone of my the derek trucks band - roadsongs pg16 generation anyway. Check it out. se7en - digital bounce pg16 shinee - lucifer pg17 Yup, we’re grovelling for taeyang - solar pg17 contributors. I’m particularly eminem - recovery pg18 macy gray - the sellout pg18 interested in someone who is jing chang - the opposite me pg18 located in New York, since we’ve bibi zhou - i.fish.light.mirror pg18 nick chou - first album pg19 received a couple of screening boa - hurricane venus pg19 invites, but we got no one there. tv Interested? Hit me up. bad guy pg20 time of eve pg20 books uso. -

Japanese Native Speakers' Attitudes Towards
JAPANESE NATIVE SPEAKERS’ ATTITUDES TOWARDS ATTENTION-GETTING NE OF INTIMACY IN RELATION TO JAPANESE FEMININITIES THESIS Presented in Partial Fulfillment of the Requirements for The Degree Master of Arts in the Graduate School of The Ohio State University By Atsuko Oyama, M.E. * * * * * The Ohio State University 2008 Master’s Examination Committee: Approved by Professor Mari Noda, Advisor Professor Mineharu Nakayama Advisor Professor Kathryn Campbell-Kibler Graduate Program in East Asian Languages and Literatures ABSTRACT This thesis investigates Japanese people’s perceptions of the speakers who use “attention-getting ne of intimacy” in discourse in relation to femininity. The attention- getting ne of intimacy is the particle ne that is used within utterances with a flat or a rising intonation. It is commonly assumed that this attention-getting ne is frequently used by children as well as women. Feminine connotations attached to this attention-getting ne when used by men are also noted. The attention-getting ne of intimacy is also said to connote both intimate and over-friendly impressions. On the other hand, recent studies on Japanese femininity have proposed new images that portrays figures of immature and feminine women. Assuming the similarity between the attention-getting ne and new images of Japanese femininity, this thesis aims to reveal the relationship between them. In order to investigate listeners’ perceptions of women who use the attention- getting ne of intimacy with respect to femininity, this thesis employs the matched-guise technique as its primary methodological choice using the presence of attention-getting ne of intimacy as its variable. In addition to the implicit reactions obtained in the matched- guise technique, people’s explicit thoughts regarding being onnarashii ‘womanly’ and kawairashii ‘endearing’ were also collected in the experiment. -

Twitterbrainz What Music Do People Share on Twitter?
TwitterBrainz what music do people share on Twitter? February 15, 2015 Open Data Project Research and Innovation Quim Llimona Àngel Farguell Modelling for Science and Engineering Abstract In this report we present TwitterBrainz, an interactive, real-time visualization of what songs are people posting on Twitter. Our system uses the MusicBrainz and Acous- ticBrainz APIs to identify the songs and extract acoustic metadata from them, which is displayed along with metadata from the tweet itself using a scatterplot metaphor for easy exploration. Clicking one of the dots/tweets/songs plays it back using the Tomahawk API, which can be used for reinventing our app into a music discovery tool. Contents 1 Introduction 2 1.1 Previous similar works . 2 2 Development 3 2.1 Sources . 3 2.2 Pre-processing . 4 2.3 Visualization . 6 3 Product 6 3.1 Functionality . 6 3.2 Limitations . 8 3.3 Example uses . 9 4 Future improvements 11 1 1 Introduction The aim of this project is to build a web-based interactive visualization using Open Data tools. Since we are both musicians, we thought it had to be about visualizing music, in any of its forms. We knew about the AcousticBrainz API, which provides acoustic information about commercial songs, and found in Twitter a great opportunity for integration. The original idea was to find tweets from users that referenced the user was listening to a particular song, find metadata about that song, and then plot the metadata along with features extracted from the tweet itself, looking for correlations. For instance, one could expect that in work days people listen to more relaxed music than during the weekend. -

1; Iya WEEKLY
Platinum Blonde - more than just a pretty -faced rock trio (Page 5) Volume 39 No. 23 February 11, 1984 $1.00 :1;1; iyAWEEKLY . Virgin Canada becomes hotti Toronto: Virgin Records Canada, headed Canac by Bob Muir as President, moves into the You I fifth month flying its own banner and has become one of the hottest labels in the Cultu country. action THE PROMISE CONTINUES.... Contributing to the success of the label by th has been Culture Club with their albums of th4 Basil', Kissing To Be Clever and Colour By Num- bers. Also a major contributor is the break- W. out of the UB40 album, Labour Of Love, first ; boosted by the reggae group's cover of the forth Watch for: old Neil Diamond '60s hit, Red Red Wine. sampl "Over100,000 Colour By Numbers also t albums were shipped in the first ten days band' -the new Images In Vogue video of 1984 alone," said Muir. "The last Ulle40 Tt album only did about 13,000 here. Now, The' albun ... with Labour Of Love, we have the first gold Lust for Love album outside of Europe, and the success ships here is opening doors in the U.S. The record and c; broke in Calgary and Edmonton and started Al -Darkroom's tour (with the Payola$) spreading." Colour By Numbers has just surpassed quintuple platinum status in Canada which Ca] ...Feb. 17-29 represents 500,000 units sold, which took Va. about 16 weeks. The album was boosted and a new remixed 7" and 12" of San Paku by the hit singles Church Of The Poison Toros Mind, now well over gold, and the latest based single, Karma Chameleon, now well over of Ca the platinum mark in less than ten weeks prom This - a newsingle by Ann Mortifee of release. -
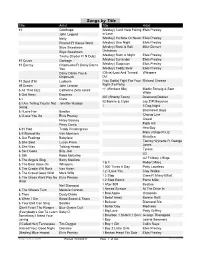
Songs by Title
Songs by Title Title Artist Title Artist #1 Goldfrapp (Medley) Can't Help Falling Elvis Presley John Legend In Love Nelly (Medley) It's Now Or Never Elvis Presley Pharrell Ft Kanye West (Medley) One Night Elvis Presley Skye Sweetnam (Medley) Rock & Roll Mike Denver Skye Sweetnam Christmas Tinchy Stryder Ft N Dubz (Medley) Such A Night Elvis Presley #1 Crush Garbage (Medley) Surrender Elvis Presley #1 Enemy Chipmunks Ft Daisy Dares (Medley) Suspicion Elvis Presley You (Medley) Teddy Bear Elvis Presley Daisy Dares You & (Olivia) Lost And Turned Whispers Chipmunk Out #1 Spot (TH) Ludacris (You Gotta) Fight For Your Richard Cheese #9 Dream John Lennon Right (To Party) & All That Jazz Catherine Zeta Jones +1 (Workout Mix) Martin Solveig & Sam White & Get Away Esquires 007 (Shanty Town) Desmond Dekker & I Ciara 03 Bonnie & Clyde Jay Z Ft Beyonce & I Am Telling You Im Not Jennifer Hudson Going 1 3 Dog Night & I Love Her Beatles Backstreet Boys & I Love You So Elvis Presley Chorus Line Hirley Bassey Creed Perry Como Faith Hill & If I Had Teddy Pendergrass HearSay & It Stoned Me Van Morrison Mary J Blige Ft U2 & Our Feelings Babyface Metallica & She Said Lucas Prata Tammy Wynette Ft George Jones & She Was Talking Heads Tyrese & So It Goes Billy Joel U2 & Still Reba McEntire U2 Ft Mary J Blige & The Angels Sing Barry Manilow 1 & 1 Robert Miles & The Beat Goes On Whispers 1 000 Times A Day Patty Loveless & The Cradle Will Rock Van Halen 1 2 I Love You Clay Walker & The Crowd Goes Wild Mark Wills 1 2 Step Ciara Ft Missy Elliott & The Grass Wont Pay -

Downbeat.Com April 2011 U.K. £3.50
£3.50 £3.50 U.K. PRIL 2011 DOWNBEAT.COM A D OW N B E AT MARSALIS FAMILY // WOMEN IN JAZZ // KURT ELLING // BENNY GREEN // BRASS SCHOOL APRIL 2011 APRIL 2011 VOLume 78 – NumbeR 4 President Kevin Maher Publisher Frank Alkyer Editor Ed Enright Associate Editor Aaron Cohen Art Director Ara Tirado Production Associate Andy Williams Bookkeeper Margaret Stevens Circulation Manager Sue Mahal Circulation Associate Maureen Flaherty ADVERTISING SALES Record Companies & Schools Jennifer Ruban-Gentile 630-941-2030 [email protected] Musical Instruments & East Coast Schools Ritche Deraney 201-445-6260 [email protected] Classified Advertising Sales Sue Mahal 630-941-2030 [email protected] OFFICES 102 N. Haven Road Elmhurst, IL 60126–2970 630-941-2030 Fax: 630-941-3210 http://downbeat.com [email protected] CUSTOMER SERVICE 877-904-5299 [email protected] CONTRIBUTORS Senior Contributors: Michael Bourne, John McDonough, Howard Mandel Atlanta: Jon Ross; Austin: Michael Point, Kevin Whitehead; Boston: Fred Bouchard, Frank-John Hadley; Chicago: John Corbett, Alain Drouot, Michael Jackson, Peter Margasak, Bill Meyer, Mitch Myers, Paul Natkin, Howard Reich; Denver: Norman Provizer; Indiana: Mark Sheldon; Iowa: Will Smith; Los Angeles: Earl Gibson, Todd Jenkins, Kirk Silsbee, Chris Walker, Joe Woodard; Michigan: John Ephland; Minneapolis: Robin James; Nashville: Robert Doerschuk; New Orleans: Erika Goldring, David Kunian, Jennifer Odell; New York: Alan Bergman, Herb Boyd, Bill Douthart, Ira Gitler, Eugene Gologursky, Norm Harris, D.D. Jackson, Jimmy Katz, -

Modeling Musical Influence Through Data
Modeling Musical Influence Through Data The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:38811527 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Modeling Musical Influence Through Data Abstract Musical influence is a topic of interest and debate among critics, historians, and general listeners alike, yet to date there has been limited work done to tackle the subject in a quantitative way. In this thesis, we address the problem of modeling musical influence using a dataset of 143,625 audio files and a ground truth expert-curated network graph of artist-to-artist influence consisting of 16,704 artists scraped from AllMusic.com. We explore two audio content-based approaches to modeling influence: first, we take a topic modeling approach, specifically using the Document Influence Model (DIM) to infer artist-level influence on the evolution of musical topics. We find the artist influence measure derived from this model to correlate with the ground truth graph of artist influence. Second, we propose an approach for classifying artist-to-artist influence using siamese convolutional neural networks trained on mel-spectrogram representations of song audio. We find that this approach is promising, achieving an accuracy of 0.7 on a validation set, and we propose an algorithm using our trained siamese network model to rank influences. -

The Influence of Rap/Hip-Hop Music: a Mixed-Method Analysis by Gretchen Cundiff — 71
The Influence of Rap/Hip-Hop Music: A Mixed-Method Analysis by Gretchen Cundiff — 71 The Influence of Rap/Hip-Hop Music: A Mixed-Method Analysis on Audience Perceptions of Misogynistic Lyrics and the Issue of Domestic Violence Gretchen Cundiff* Strategic Communications Elon University Abstract Using a qualitative content analysis and online survey, this research examined how college students perceive and respond to the portrayal of women when exposed to misogynistic lyrics. Based on cultivation theory, this study analyzed the lyrical content of popular rap and hip-hop songs (n=20) on Billboard’s “Hot 100” chart between 2000 and 2010. Song lyrics were classified into one or more of the following coding categories: demeaning language, rape/sexual assault, sexual conquest and physical violence. Themes of power over, objectification of and violence against women were identified as prevalent throughout the content analysis sample. Survey results indicated a positive correlation between misogynous thinking and rap/hip-hop consumption. I. Introduction This study examined the culture of rap/hip-hop music and how misogynistic lyrical messages influ- enced listeners’ attitudes toward intimate partner violence. Adams and Fuller (2006) define misogyny as the “hatred or disdain of women” and “an ideology that reduces women to objects for men’s ownership, use, or abuse” (p. 939). Popular American hip-hop and rap artists, such as Eminem, Ludacris and Ja Rule, have increasingly depicted women as objects of violence or male domination by communicating that “submission is a desirable trait in a woman” (Stankiewicz & Rosselli, 2008, p. 581). These songs condone male hegemony in which “men find the domination and exploitation of women and other men to be not only expected, but actu- ally demanded” (Prushank, 2007, p.