Analysis and Transfer of Photographic Viewpoint and Appearance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Contrast Sensitivity and Visual Acuity Among the Elderly
Contrast Sensitivity and Visual Acuity among the Elderly THESIS Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The Ohio State University By Mawada Osman Graduate Program in Vision Science The Ohio State University 2020 Master's Examination Committee: Angela M. Brown, PhD, Advisor Bradley E. Dougherty, OD, PhD Heidi A. Wagner, OD, MPH Copyright by Mawada Osman 2020 Abstract Purpose: To establish the clinical utility and strengthen the validity of the Ohio Contrast Cards (OCC), expand the use of the OCC in a healthy elderly population, and form a baseline dataset of patients to be compared to patients with dementia. Method: Participants ages 65 and over (N = 51) were recruited from the Ohio State University Primary Vision Care (PVC). We assessed the visual function of each patient using four visual tests which include: OCC, Pelli-Robson Chart (PR), Teller Acuity Cards (TAC) and Clear Chart. The contrast sensitivity tests (OCC and PR) were assessed twice, once by each tester. The PR contrast levels were also evaluated at two different distances 1 meter and 3 meters (0.50 meter if visual acuity worse than 6.0 cy/cm). Cognitive abilities were evaluated using the 6-Item Cognitive Impairment Test (6-CIT). Results: A significant effect of test was revealed (p < 0.005), in favor of OCC, yielding consistently higher average LogCS scores than PR, average difference of 0.412 LogCS. The PR and OCC revealed similar repeatability with 95% LoA of ± 0.28 log units and 95% LoA of ± 0.27 log units, respectively. -

Visual Performance of Scleral Lenses and Their Impact on Quality of Life In
A RQUIVOS B RASILEIROS DE ORIGINAL ARTICLE Visual performance of scleral lenses and their impact on quality of life in patients with irregular corneas Desempenho visual das lentes esclerais e seu impacto na qualidade de vida de pacientes com córneas irregulares Dilay Ozek1, Ozlem Evren Kemer1, Pinar Altiaylik2 1. Department of Ophthalmology, Ankara Numune Education and Research Hospital, Ankara, Turkey. 2. Department of Ophthalmology, Ufuk University Faculty of Medicine, Ankara, Turkey. ABSTRACT | Purpose: We aimed to evaluate the visual quality CCS with scleral contact lenses were 0.97 ± 0.12 (0.30-1.65), 1.16 performance of scleral contact lenses in patients with kerato- ± 0.51 (0.30-1.80), and 1.51 ± 0.25 (0.90-1.80), respectively. conus, pellucid marginal degeneration, and post-keratoplasty Significantly higher contrast sensitivity levels were recorded astigmatism, and their impact on quality of life. Methods: with scleral contact lenses compared with those recorded with We included 40 patients (58 eyes) with keratoconus, pellucid uncorrected contrast sensitivity and spectacle-corrected contrast marginal degeneration, and post-keratoplasty astigmatism who sensitivity (p<0.05). We found the National Eye Institute Visual were examined between October 2014 and June 2017 and Functioning Questionnaire overall score for patients with scleral fitted with scleral contact lenses in this study. Before fitting contact lens treatment to be significantly higher compared with scleral contact lenses, we noted refraction, uncorrected dis- that for patients with uncorrected sight (p<0.05). Conclusion: tance visual acuity, spectacle-corrected distance visual acuity, Scleral contact lenses are an effective alternative visual correction uncorrected contrast sensitivity, and spectacle-corrected contrast method for keratoconus, pellucid marginal degeneration, and sensitivity. -

Higher-Order Wavefront Aberration and Letter-Contrast Sensitivity In
Eye (2008) 22, 1488–1492 & 2008 Macmillan Publishers Limited All rights reserved 0950-222X/08 $32.00 www.nature.com/eye 1 1 2 2 CLINICAL STUDY Higher-order C Okamoto , F Okamoto , T Samejima , K Miyata and T Oshika1 wavefront aberration and letter-contrast sensitivity in keratoconus Abstract Keywords: keratoconus; wavefront aberration; higher-order aberration; contrast sensitivity; Aims To evaluate the relation between letter-contrast sensitivity higher-order aberration of the eye and contrast sensitivity function in eyes with keratoconus. Methods In 22 eyes of 14 patients with Introduction keratoconus (age 30.578.4 years, means7SD) and 26 eyes of 13 normal controls (age Keratoconus is a chronic, non-inflammatory 29.276.7 years), ocular higher-order wavefront disease of the cornea associated with aberration for a 6-mm pupil was measured progressive thinning and anterior protrusion of with the Hartmann-Schack aberrometer the central cornea.1,2 Irregular astigmatism is (KR-9000 PW, Topcon). The root mean square often the first and most apparent clinical finding (RMS) of third- and fourth-order Zernike in keratoconus, and this is evidenced by a coefficients was used to represent higher-order distortion of the corneal image as noted with aberrations. The letter-contrast sensitivity was the placido disc, retinoscope, keratometer, examined using the CSV-1000LV contrast chart keratoscope, and computerized (Vector Vision). videokeratograph. Previous studies using Results In the keratoconus group, the videokeratography have quantitatively 1 Department of letter-contrast sensitivity showed significant demonstrated that corneal irregular Ophthalmology, Institute of correlation with third-order (Spearman’s astigmatism is significantly greater in eyes with Clinical Medicine, University correlation coefficient ¼À0.736, 0.001) 3–6 of Tsukuba, Ibaraki, Japan r Po keratoconus than in normal eyes. -

Contrast Sensitivity and Visual Acuity in Low-Vision Students Thesis
Contrast Sensitivity and Visual Acuity in Low-Vision Students Thesis Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The Ohio State University By Steve Murimi Mathenge Njeru, BS Graduate Program in Vision Science The Ohio State University 2020 Thesis Committee Angela M. Brown, PhD, Advisor Bradley E. Dougherty, OD, PhD Deyue Yu, PhD Copyrighted by Steve Murimi Mathenge Njeru 2020 Abstract Purpose: This study primarily compared the test-retest reliability of the Pelli-Robson chart (PR) and Ohio Contrast Cards (OCC) amongst testers. The secondary goal of this study was to examine the impact on contrast sensitivity if the testing distance for the Pelli-Robson chart were to be changed. An additional goal was to evaluate the relationship between visual acuity (VA) and contrast sensitivity (CS) when using letter-based charts and grating cards. Methods: Thirty low-vision students were tested, ranging from 7-20 years old. Each student was tested with both VA and CS tests in randomized order, which included: the Bailey- Lovie chart (BL), Pelli-Robson chart, Teller Acuity Cards (TAC), and Ohio Contrast Cards. Each student repeated both the PR chart and OCC in separate rooms, but neither the BL chart nor TAC was repeated. The PR chart was also tested at closer testing distance, based on the student’s logMAR acuity from the BL chart. For the letter charts, a letter-by-letter scoring method was used. For grating cards, these were both scored as preferential looking tests. Results: The Limits of Agreement for the OCC and PR chart were +/- 0.451 and +/- 0.536, respectively. -
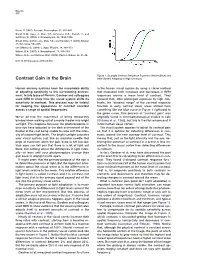
Contrast Gain in the Brain After (Green) Adapting to High Contrasts
Neuron 476 Rozin, P. (1982). Percept. Psychophys. 31, 397–401. Small, D.M., Voss, J., Mak, Y.E., Simmons, K.B., Parrish, T., and Gitelman, D. (2004). J. Neurophysiol. 92, 1892–1903. Small, D.M., Gerber, J.C., Mak, Y.E., and Hummel, T. (2005). Neuron 47, this issue, 593–605. von Békésy, G. (1964). J. Appl. Physiol. 19, 369–373. Wilson, D.A. (1997). J. Neurophysiol. 78, 160–169. Wilson, D.A., and Sullivan, R.M. (1999). Physiol. Behav. 66, 41–44. DOI 10.1016/j.neuron.2005.08.002 Figure 1. Example Contrast Response Functions Before (Blue) and Contrast Gain in the Brain After (Green) Adapting to High Contrasts Human sensory systems have the remarkable ability in the human visual system by using a clever method of adjusting sensitivity to the surrounding environ- that measured both increases and decreases in fMRI ment. In this issue of Neuron, Gardner and colleagues responses around a mean level of contrast. They used fMRI to show how the visual system shifts its showed that, after prolonged exposure to high con- sensitivity to contrast. This process may be helpful trasts, the “dynamic range” of the contrast response for keeping the appearance of contrast constant function in early cortical visual areas shifted from across a range of spatial frequencies. something like the blue curve in Figure 1 rightward to the green curve. This process of “contrast gain” was We’ve all had the experience of being temporarily originally found in electrophysiological studies in cats blinded when walking out of a movie theater into bright (Ohzawa et al., 1985), but this is the first evidence of it sunlight. -

Contrast Sensitivity and Acuity Relationship in Strabismic and Anisometropic Amblyopia
Br J Ophthalmol: first published as 10.1136/bjo.72.1.44 on 1 January 1988. Downloaded from British Journal of Ophthalmology, 1988, 72, 44-49 Contrast sensitivity and acuity relationship in strabismic and anisometropic amblyopia M ABRAHAMSSON AND J SJOSTRAND From the Department of Ophthalmology, University of Goteborg, Sahlgren's Hospital S-413 45 Goteborg, Sweden SUMMARY The contrast sensitivity function (CSF) and visual acuity were determined in children and adults with unilateral amblyopia due to strabismus or anisometropia with central fixation. The preschool children were examined repeatedly during occlusion treatment. All amblyopes had CSF deficits. The CSF was characterised by its peak value (the maximal sensitivity, Smax, and the spatial frequency at which Smax occurs, Frmax) calculated by a single peak least-square regression method. The two amblyopic groups showed discrepancies in relationship of both Smax and Frmax versus visual acuity both initially and during treatment. The strabismic cases had a more marked visual acuity deficit in relation to the contrast sensitivity losses, whereas these parameters are affected similarly in anisometropic amblyopes. The relationship between recovery of visual acuity and CSF during the initial month of occlusion treatment was of prognostic significance for the outcome of visual acuity improvement. copyright. Amblyopia is defined as an optically uncorrectable receives an input with deprived form and contour. loss of vision, usually monocular, without demon- There is no evidence that a strabismic eye receives a strable pathology in the posterior pole of the eye. blurred image, whereas several studies indicate that This condition develops in early childhood and it abnormal binocular interaction is present in http://bjo.bmj.com/ affects up to 5% of the population. -

Color Blindness
. assessment report Color Blindness .......... Betsy J. Case, Ph.D. February 2003 (Revision 2, November 2003) Copyright © 2003 by Pearson Education, Inc. or its affiliate(s). All rights reserved. Pearson and the Pearson logo are trademarks of Pearson Education, Inc. or its affiliate(s). ASSESSMENT REPORT . Color Blindness . Color Blindness Acknowledgements Pearson Inc. (Pearson) gratefully acknowledges the following individuals for providing expertise and references to empirical research on this topic. Furthermore, several of these individuals reviewed all Stanford Achievement Test Series, Tenth Edition (Stanford 10) materials to ensure that the color choices provided effective color contrast for students with color blindness. Dr. Carol Allman, formerly with the Florida Department of Education, currently with the American Printing House for the Blind, Inc., Louisville, KY. Multiple personal contacts from 1997 – present. Dawn Dunleavy, The Psychological Corporation. Barbara Henderson, Research Group, American Printing House for the Blind, Inc., Louisville, KY. Multiple personal contacts from 2001 – present. Diane Spence, Director, Braille Services Unit, Region IV Education Service Cooperative, Houston, Texas. Multiple personal contacts from 1997 – present. Dr. Sandra Thompson, Senior Researcher, National Center on Educational Outcomes, University of Minnesota, Minneapolis. Critical nexus with the Minnesota Laboratory for Low-Vision Research by Gordon E. Legge. Multiple personal contacts from 1993 – present. Debra Willis, American Printing House for the Blind, Inc. Personal communications from 1996 – present. Color Vision Color vision is determined by the discrimination of three qualities of color: hue (such as red vs. green), saturation (that is, pure vs. blended colors), and brightness (that is, vibrant vs. dull reflection of light) (Arditi, 1999a). The essential difference between the color blind and most people is that hues that appear different to most people look the same to a color blind person. -

Factors Influencing Contrast Sensitivity Function in Eyes With
Journal of Clinical Medicine Article Factors Influencing Contrast Sensitivity Function in Eyes with Mild Cataract Kazutaka Kamiya 1,*, Fusako Fujimura 1, Takushi Kawamorita 1, Wakako Ando 2, Yoshihiko Iida 2 and Nobuyuki Shoji 2 1 Visual Physiology, School of Allied Health Sciences, Kitasato University, Kanagawa 2520373, Japan; [email protected] (F.F.); [email protected] (T.K.) 2 Department of Ophthalmology, School of Medicine, Kitasato University, Kanagawa 2520374, Japan; [email protected] (W.A.); [email protected] (Y.I.); [email protected] (N.S.) * Correspondence: [email protected]; Tel.: +81-42-778-8464; Fax: +81-42-778-2357 Abstract: This study was aimed to evaluate the relationship between the area under the log contrast sensitivity function (AULCSF) and several optical factors in eyes suffering mild cataract. We enrolled 71 eyes of 71 patients (mean age, 71.4 ± 10.7 (standard deviation) years) with cataract formation who were under surgical consultation. We determined the area under the log contrast sensitivity function (AULCSF) using a contrast sensitivity unit (VCTS-6500, Vistech). We utilized single and multiple regression analyses to investigate the relevant factors in such eyes. The mean AULSCF was 1.06 ± 0.16 (0.62 to 1.38). Explanatory variables relevant to the AULCSF were, in order of influence, logMAR best spectacle-corrected visual acuity (BSCVA) (p < 0.001, partial regression coefficient B = −0.372), and log(s) (p = 0.023, B = −0.032) (adjusted R2 = 0.402). We found no significant association with other variables such as age, gender, uncorrected visual acuity, nuclear sclerosis grade, or ocular HOAs. -

Chapter 10 Phase Contrast
Chapter 10 Phase Contrast Chapter 10 Phase Contrast © C. Robert Bagnell, Jr., Ph.D., 2012 Phase contrast makes living, unstained microscopic structures visible. Normally the difference in refractive index between a living microscopic structure and its surrounding environment is so small that the structure refracts very little light. Light is, however, diffracted by the specimen. Diffracted light is, on average, slowed down by 1/4 of a wavelength relative to undiffracted light. Undiffracted light is referred to as direct light. In the absence of any color contrast resulting from differential absorption, contrast can be created from the interference of diffracted and direct light. Phase contrast is a method of enhancing this interference. Types of Specimens for Phase Contrast Phase contrast is especially useful for living biological specimens. Today, cell cultures are a primary specimen for phase contrast. Phase contrast is useful for specimens that produce very little refraction; that is, their refractive index is not much different from their surrounding medium. Phase is also useful for specimens that possess little or no color of their own and which have not been artificially colored. In addition to cell and organ cultures, such specimens include bacteria, aquatic invertebrates, blood, and other body fluids. Historical Background of Phase Contrast Frits Zernike, a physicist at the University of Gröningen, Holland, discovered the phase principle in 1932. He described its use in microscopy in 1935. He won the Nobel Prize in physics in 1953 for this work. Zernike separated direct light from the specimen from diffracted light from the specimen by use of a special disk in the condenser. -

Contrast and Glare Testing in Keratoconus and After Penetrating Keratoplasty K Pesudovs, P Schoneveld, R J Seto, D J Coster
653 EXTENDED REPORT Br J Ophthalmol: first published as 10.1136/bjo.2003.027029 on 16 April 2004. Downloaded from Contrast and glare testing in keratoconus and after penetrating keratoplasty K Pesudovs, P Schoneveld, R J Seto, D J Coster ............................................................................................................................... Br J Ophthalmol 2004;88:653–657. doi: 10.1136/bjo.2003.027029 Aim: To compare the performance of keratoconus, penetrating keratoplasty (PK), and control subjects on clinical tests of contrast and glare vision, to determine whether differences in vision were independent of visual acuity (VA), and thereby establish which vision tests are the most useful for outcome studies of PK for keratoconus. Methods: All PK subjects had keratoconus before grafting and no subjects had any other eye disease. The keratoconus (n = 11, age 35.0 (SD 11.1) years), forme fruste keratoconus (n = 6, 33.0 (13.0)), PK (n = 21, See end of article for 41.2 (7.9)), and control (n = 24, 33.7 (8.6)) groups were similar in age. Vision testing, conducted with authors’ affiliations optimal refractive correction in place, included low contrast visual acuity (LCVA) and Pelli-Robson contrast ....................... sensitivity (PRCS) both with and without glare, as well as VA. Correspondence to: Results: Normal subjects saw better than PK subjects who in turn saw better than keratoconus subjects on K Pesudovs, Department of all raw measures. However, when adjusted for VA, the normal group only saw significantly better than the Ophthalmology, Flinders keratoconus group on LCVA (low contrast loss 0.05 (0.04) v 0.15 (0.12), F2,48 = 6.16; p,0.01, post hoc Medical Centre, Bedford Sheffe´p,0.05), and the decrements to glare were no worse than for normals. -

Psychophysical Aspects of Contrast Sensitivity*
S Afr Optom 2013 72(2) 76-85 Psychophysical aspects of contrast sensitivity* Anusha Y Sukhaa and Alan Rubinb a, b Department of Optometry, University of Johannesburg, PO Box 524, Auckland Park, 2006 South Africa a<[email protected]> b<[email protected]> Received 23 November 2012; revised version accepted 9 June 2013 Abstract demonstrate stereo-pair representation of contrast visual acuities in the context of diabetic eyes. This paper reviews the psychophysical aspects The doctoral research of the first author (AYS) of contrast sensitivity which concerns components that applies similar idea to understanding both of visual stimuli and the behavioural responses inter- and intra-ocular variation of contrast visual and methods used in contrast sensitivity testing. acuities. Some discussion is included of the different types of contrast sensitivity charts available as well Key words: contrast, contrast sensitivity, as a brief background on the different types of contrast visual acuity, vision science, vision graphical representations of contrast sensitivity psychophysics, stereo-pair scatter plots, and contrast visual acuities. Two illustrations also multivariate statistics Introduction (namely spatial frequency, contrast, spatial phase, and orientation) by means of Fourier analysis. Fourier Psychophysics is a scientific discipline designed analysis is an analytical method that calculates to measure internal sensory and perceptual responses simple sine-wave components whose linear sum to external stimuli1. Sensory stimuli and behavioural forms a given complex image2, 3. The visual stimuli responses are the defining or crucial concepts in typically used in contrast sensitivity testing consist of determining contrast thresholds (for example, visual sine-wave or square-wave gratings whose luminance stimuli are used in chart-based contrast sensitivity perpendicular to the bars is modulated in sinusoidal measurements). -

Abstract and Introduction Abstract
http://www.medscape.com/viewarticle/818874_print www.medscape.com Department of Optics II (Optometry and Vision) (G.C., J.C.), Faculty of Optic and Optometry, Universidad Complutense de Madrid, Madrid, Spain, Clinical &, Experimental Optometry Research Lab (J.M.G.-M., D.L.-F.), Center of Physics (Optometry), School of Sciences, University of Minho, Braga, Portugal, and Laboratorios Lenticon SA (G.C., L.B.), Madrid, Spain. Eye Contact Lens. 2014;40(1):2-6. Abstract and Introduction Abstract Objectives: To compare the clinical performance of the Clearkone hybrid contact lens for the treatment of keratoconus against the habitual contact lens of the patients. Methods: A total of 33 eyes from 18 patients were fitted with the Clearkone. High- and low-contrast visual acuity (HCVA and LCVA), central corneal thickness (CCT), and contrast sensitivity acuity (CSF) were recorded with habitual lenses (prestudy visit) and after 1 week, 15 days, and 1 month of wear of prescribed Clearkone. Subjective vision and comfort were rated using visual analogue scales (VAS). Results: Three patients discontinued the study, one because of diffuse corneal staining after 1 day of use and the other two because of extreme discomfort. The rest of the patients completed the 1-month study. High contrast visual acuity and LCVA (logMAR) improved significantly from 0.16 ± 0.12 and 0.44 ± 0.22, respectively, with the patient's habitual contact lenses to -0.006 ± 0.058 and 0.23 ± 0.13 after 1 day wearing Clearkone, remaining significant during all follow-up visits (P<0.001; repeated measures analysis of variance [RM-ANOVA]).