Processing Near Or in Memory for Deep Learning Lide Duan (段立德) Computing Technology Lab Alibaba DAMO Academy 阿里巴巴达摩院计算技术实验室 Alibaba Businesses
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

What Is Cloud-Based Backup and Recovery?
White paper Cover Image Pick an image that is accurate and relevant to the content, in a glance, the image should be able to tell the story of the asset 550x450 What is cloud-based backup and recovery? Q120-20057 Executive Summary Companies struggle with the challenges of effective backup and recovery. Small businesses lack dedicated IT resources to achieve and manage a comprehensive data protection platform, and enterprise firms often lack the budget and resources for implementing truly comprehensive data protection. Cloud-based backup and recovery lets companies lower their Cloud-based backup and recovery lets data protection cost or expand their capabilities without raising costs or administrative overhead. Firms of all sizes can companies lower their data protection benefit from cloud-based backup and recovery by eliminating cost or expand their capabilities without on-premises hardware and software infrastructure for data raising costs or administrative overhead.” protection, and simplifying their backup administration, making it something every company should consider. Partial or total cloud backup is a good fit for most companies given not only its cost-effectiveness, but also its utility. Many cloud- based backup vendors offer continuous snapshots of virtual machines, applications, and changed data. Some offer recovery capabilities for business-critical applications such as Microsoft Office 365. Others also offer data management features such as analytics, eDiscovery and regulatory compliance. This report describes the history of cloud-based backup and recovery, its features and capabilities, and recommendations for companies considering a cloud-based data protection solution. What does “backup and recovery” mean? There’s a difference between “backup and recovery” and “disaster recovery.” Backup and recovery refers to automated, regular file storage that enables data recovery and restoration following a loss. -

PROTECTING DATA from RANSOMWARE and OTHER DATA LOSS EVENTS a Guide for Managed Service Providers to Conduct, Maintain and Test Backup Files
PROTECTING DATA FROM RANSOMWARE AND OTHER DATA LOSS EVENTS A Guide for Managed Service Providers to Conduct, Maintain and Test Backup Files OVERVIEW The National Cybersecurity Center of Excellence (NCCoE) at the National Institute of Standards and Technology (NIST) developed this publication to help managed service providers (MSPs) improve their cybersecurity and the cybersecurity of their customers. MSPs have become an attractive target for cyber criminals. When an MSP is vulnerable its customers are vulnerable as well. Often, attacks take the form of ransomware. Data loss incidents—whether a ransomware attack, hardware failure, or accidental or intentional data destruction—can have catastrophic effects on MSPs and their customers. This document provides recommend- ations to help MSPs conduct, maintain, and test backup files in order to reduce the impact of these data loss incidents. A backup file is a copy of files and programs made to facilitate recovery. The recommendations support practical, effective, and efficient back-up plans that address the NIST Cybersecurity Framework Subcategory PR.IP-4: Backups of information are conducted, maintained, and tested. An organization does not need to adopt all of the recommendations, only those applicable to its unique needs. This document provides a broad set of recommendations to help an MSP determine: • items to consider when planning backups and buying a backup service/product • issues to consider to maximize the chance that the backup files are useful and available when needed • issues to consider regarding business disaster recovery CHALLENGE APPROACH Backup systems implemented and not tested or NIST Interagency Report 7621 Rev. 1, Small Business planned increase operational risk for MSPs. -

Backup Reminders Once You Have Created Your Backup, Take a Moment 1
External Hard Drives—There are a number of easily accessible, but if your laptop was stolen you’d external hard drives that can be connected to your be without a machine and without your backup! computer through the Firewire or USB port. Many Treat your backups with extreme care! of these hard drives can be configured to automati- cally synchronize folders on your desktop with the Destroy your old backups. As you conduct your folders on the external drive. Although this some- backups more frequently, you’ll end up with a pile what automates the backup process, these drives can of old backup media. Be sure to dispose of old also be easily stolen! media properly. CD and DVDs can be destroyed simply by using a pair of scissors and scratching the How to Backup back of the CD several times. There are also media Backing up your data can be as easy as copying and shredders which work just like a paper shredder pasting the files to the backup drive or you can use leaving your backups in hundred of pieces. Just be specialized programs to help create your backup. sure that the data is no longer readable before you Most ITS Windows computers have Roxio Easy CD toss the backups in the trash. Creator installed. Instructions for using Roxio are located on our website at smu.edu/help/resources/ Keep a copy of your backup off site. You may wish backup/backup.asp. For Macs, simply drag the files to store a backup copy at home in the event of theft to the CDRW drive and click Burn. -

Nixie Clock Type 'Nixie QTC Plus'
Assembly Instructions And User Guide Nixie Clock Type ‘Nixie QTC Plus’ For Parts Bag Serial Numbers from 1000 onwards Nixie Tube Clock ‘Nixie QTC+’ - 1 - Issue 3 (13 June 2019) www.pvelectronics.co.uk REVISION HISTORY Issue Date Reason for Issue Number 3 13 June 2019 Added support for Dekatron Sync Pulse 2 01 October 2018 C5 changed to 15pF Draft 1 29 August 2018 New document Nixie Tube Clock ‘Nixie QTC+’ - 2 - Issue 3 (13 June 2019) www.pvelectronics.co.uk 1. INTRODUCTION 1.1 Nixie QTC Plus - Features Hours, Minutes and Seconds display Drives a wide range of medium sized solder-in tubes Uses a Quartz Crystal Oscillator as the timebase 12 or 24 hour modes Programmable leading zero blanking Date display in either DD.MM.YY or MM.DD.YY or YY.MM.DD format Programmable date display each minute Scrolling display of date or standard display Alarm, with programmable snooze period Optional GPS / WiFi / XTERNA synchronisation with status indicator LED Dedicated DST button to switch between DST and standard time Supercapacitor backup. Keeps time during short power outages Simple time setting using two buttons Configurable for leading zero blanking Double dot colon neon lamps 11 colon neon modes including AM / PM indication (top / bottom or left / right), railroad (slow or fast) etc. Seconds can be reset to zero to precisely the set time Programmable night mode - blanked or dimmed display to save tubes or prevent sleep disturbance Rear Indicator LEDs dim at night to prevent sleep disturbance Weekday aware ‘Master Blank’ function to turn off tubes and LEDs on weekends or during working hours Separate modes for colon neons during night mode Standard, fading, or crossfading with scrollback display modes ‘Slot Machine’ Cathode poisoning prevention routine Programmable RGB tube lighting – select your favourite colour palette 729 colours possible. -

Cloudberry Backup
CloudBerry Backup Installation and Configuration Guide CloudBerry Backup Installation and Configuration Guide Getting Started with CloudBerry Backup CloudBerry Backup (CBB) solution was designed to facilitate PC and server data backup operations to multiple remote locations. It is integrated with top Cloud storage providers, allowing you to access each of your storage or start a sign up to a Cloud platform directly from CBB. It also works fine with network destinations like NAS (Network Attached Storage) or directly connected drives. This document is the complete guide to the CloudBerry Backup deployment, configuration, and usage. Product Editions & Licensing The CBB can be downloaded directly from CloudBerry website with several editions. ● Windows Desktop (including FREE Edition) / Server. ● Microsoft SQL Server. ● Microsoft Exchange Server. ● Oracle Database. ● Ultimate (former Enterprise). ● CloudBerry Backup for NAS (QNAP and Synology). They differ in functionality, storage limits and individual solutions availability. We accomplished a chart with basic editions to give a clear perspective. CBB Edition Desktop Desktop Server MS SQL MS Ultimate Free Pro Exchange File-level + + + + + + Backup Image - - + + + + CloudBerry Backup Installation and Configuration Guide Based Backup MS SQL - - - + - + Server Backup MS - - - - + + Exchange Server Backup Encryption - - + + + + and Compressio n Storage 200GB 1TB 1TB 1TB 1TB Unlimited Limits (for one account) Network 1 1 5 5 5 Unlimited Shares for Backup Support Superuser.c Email, 48 Email, 48 Email, 48 Email, 48 Email, 48 Type om forum hours hours hours hours hours Only response response response response response On the download page, there are also links for Mac and Linux Editions. For Windows, CBB is distributed within Universal Installer so that you can choose the desired edition after the download. -

Data Backup Options Paul Ruggiero and Matthew A
Data Backup Options Paul Ruggiero and Matthew A. Heckathorn All computer users, from home users to professional information security officers, should back up the critical data they have on their desktops, laptops, servers, and even mobile devices to protect it from loss or corruption. Saving just one backup file may not be enough to safeguard your information. To increase your chances of recovering lost or corrupted data, follow the 3-2-1 rule:1 3 – Keep 3 copies of any important file: 1 primary and 2 backups. 2 – Keep the files on 2 different media types to protect against different types of hazards. 1 – Store 1 copy offsite (e.g., outside your home or business facility). This paper summarizes the pros, cons, and security considerations of backup options for critical personal and business data. Remote Backup – Cloud Storage Recent expansions of broadband internet service have made cloud storage available to a wide range of computer users. Cloud service customers use the internet to access a shared pool of computing resources (e.g., networks, servers, storage, applications, and services) owned by a 2 cloud service provider. 3 Pros Remote backup services can help protect your data against some of the worst-case scenarios, such as natural disasters or critical failures of local devices due to malware. Additionally, cloud services give you anytime access to data and applications anywhere you have an internet connection, with no need for you to invest in networks, servers, and other hardware. You can purchase more or less cloud service as needed, and the service provider transparently manages 1 Krogh, Peter. -
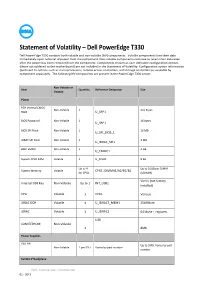
Statement of Volatility – Dell Poweredge T330 Dell Poweredge T330 Contains Both Volatile and Non-Volatile (NV) Components
Statement of Volatility – Dell PowerEdge T330 Dell PowerEdge T330 contains both volatile and non-volatile (NV) components. Volatile components lose their data immediately upon removal of power from the component. Non-volatile components continue to retain their data even after the power has been removed from the component. Components chosen as user-definable configuration options (those not soldered to the motherboard) are not included in the Statement of Volatility. Configuration option information (pertinent to options such as microprocessors, remote access controllers, and storage controllers) is available by component separately. The following NV components are present in the PowerEdge T330 server. Non-Volatile or Item Quantity Reference Designator Size Volatile Planer PCH Internal CMOS Non-Volatile 1 256 Bytes RAM U_SRP1 BIOS Password Non-Volatile 1 16 bytes U_SRP1 BIOS SPI Flash Non-Volatile 1 16 MB U_SPI_BIOS_1 iDRAC SPI Flash Non-Volatile 1 4 MB U_IDRAC_SPI1 BMC EMMC Non-Volatile 1 4 GB U_EMMC1 System CPLD RAM Volatile 1 U_CPLD1 8 KB Up to 4 Up to 16GB per DIMM System Memory Volatile CPU1: DIMMA1/A2/B1/B2 for CPU1 (UDIMM) Varies (not factory Internal USB Key Non-Volatile Up to 1 INT_USB1 installed) CPU Volatile 1 CPU1 Various iDRAC DDR Volatile 1 U_IDRAC7_MEM1 256MByte iDRAC Volatile 1 U_IDRAC1 64 kbyte + registers U30 LOM EEPROM Non-Volatile 1 8Mb Power Supplies PSU FW Up to 2MB. Varies by part Non-Volatile 1 per PSU Varies by part number number 5U 8x3.5”Backplane Dell - Internal Use - Confidential 02 - 2013 Non-Volatile or Item -

Setting up and Using an External USB Flash Drive (Thumb Drive) on Your Mac
Setting up and using an external USB Flash Drive (Thumb Drive) on your Mac IMPORTANT! Backup your flash drive data! 1. Plug in the external flash drive into a USB port with enough power. This is usually found on the CPU or monitor. DO NOT plug the USB flash drive into the keyboard. The keyboard does not have enough power to run the USB flash drive. a). On the iMac G5, look on the back right side, find the USB 2.0 ports. b). On the iMac Intel, look on the back, bottom for the USB 2.0 ports. c). On the iMac G4, look on the back left side and find the USB ports. d). On the G5’s or G4’s, locate the 17” Studio Display. This monitor has two USB ports built into it. These ports are located on the back right side. e). You can also plug the USB flash drive directly into the front of the G5. f). On the G4’s, locate the USB ports on the back of the G4’s. 2. Once the USB flash drive is plugged into a good USB port, the first time it is connected, it should appear on your desktop as a NO NAME drive icon. 3. Open the Disk Utility program found in the Utilities folder located in the Applications folder. 4. The Disk Utility program opens to show the various drives available to work with. 5. Click on the SanDisk Cruz… disk as seen above to start working with it. 6. Let’s take a look at the variety of formats we have to chose from for the USB flash drive. -

Battery Backup of Self-Refreshing Dynamic Random Access Memory Prepared By: Paul A
Order this document MOTOROLA by AN1202/D SEMICONDUCTOR TECHNICAL DATA AN1202 Battery Backup of Self-Refreshing Dynamic Random Access Memory Prepared by: Paul A. Oats, 4M DRAM Products, Motorola Microprocessor and Memory Technologies Group John P. Hansen, M68000 Products, Motorola Microprocessor and Memory Technologies Group Paul J. Polansky, formerly of Motorola High-End Microprocessor Division, currently in Motorola Austin Intellectual Property Department INTRODUCTION In addition to the usual methods of DRAM refresh (any read or write cycle, a RAS-only refresh, a CAS before RAS In today’s information-dependent society, the need for refresh, or a hidden refresh), the MCM5V4800A also incor- maintaining the integrity of data and program status during a porates a self-refresh operation, previously found only on power outage is becoming increasingly important. Even pseudo-static RAMs (PSRAMs). This self-refresh feature though data files may be stored frequently during a session, removes the need to have the DRAM control circuitry on the in the event of a power failure, any changes since the last battery backup node, and is expected to be a standard fea- save would be lost, and the program would have to initialize ture on future generations of DRAMs. and reload the required data. In applications where data loss The self-refresh operation is entered just as a normal CAS would be costly in terms of dollars and time spent re-entering before RAS refresh, but CAS and RAS are held low for a data, the use of battery backup circuits in conjunction with period greater than tRASS min (>100 µs), as shown in Fig- robust software can ensure that a power failure would be at ure 1. -

Improving Energy-Efficiency in Dynamic Memories Through Retention Failure Detection
Received January 22, 2019, accepted February 22, 2019, date of publication February 27, 2019, date of current version March 13, 2019. Digital Object Identifier 10.1109/ACCESS.2019.2901738 Improving Energy-Efficiency in Dynamic Memories Through Retention Failure Detection ROBERT GITERMAN 1, ROMAN GOLMAN2, AND ADAM TEMAN 2 1Telecommunications Circuits Laboratory, Institute of Electrical Engineering, EPFL, 1015 Lausanne, Switzerland 2Emerging Nanoscale Integrated Circuits and Systems Laboratories, Faculty of Engineering, Bar-Ilan University, Ramat Gan 5290002, Israel Corresponding author: Robert Giterman (robert.giterman@epfl.ch) This work was supported by the Israel Science Foundation under Grant 996/18 and Grant 2181/18. ABSTRACT A gain-cell embedded DRAM (GC-eDRAM) is an attractive logic-compatible alternative to the conventional static random access memory (SRAM) for the implementation of embedded memories, as it offers higher density, lower leakage, and two-ported operation. However, it requires periodic refresh cycles to maintain its data which deteriorates due to leakage. The refresh-rate, which is traditionally set according to the worst cell in the array under extreme operating conditions, leads to a significant refresh power consumption and decreased memory availability. In this paper, we propose to reduce the cost of GC-eDRAM refresh by employing failure detection to lower the refresh-rate. A 4T dynamic complementary dual-modular redundancy bitcell is proposed to offer per-bit error detection, resulting in a substantial decrease in the refresh-rate and over 60% power reduction compared with the SRAM. The proposed approach is also compared with the conventional SRAM and GCeDRAM implementations with integrated error correction codes, demonstrating significant area and latency reductions. -

The Use of Write-Once Read-Many Optical Disks for Temporary and Archival Storage
THE USE OF WRITE-ONCE READ-MANY OPTICAL DISKS FOR TEMPORARY AND ARCHIVAL STORAGE By Brenda L. Groskinsky U.S. GEOLOGICAL SURVEY Open-File Report 92-36 Portland, Oregon 1992 U. S. DEPARTMENT OF THE INTERIOR MANUEL LUJAN, JR., Secretary U.S. GEOLOGICAL SURVEY Dallas L. Peck, Director ,,... ,. , .. Copies of this report can For additional information , r , , , r .^ ^ be purchased from: wnte to: r T-V j. -^ /-u- c U.S. Geological Survey District Chief D . ° ., ^ . c .. TT _^ . , c ,Arnr^ Books and Open-File Reports Section U.S. Geological Survey, WRD c , , ^ . r oc^oc -inxn-rc^u Di T^. Federal Center, Box 25425 10615 S.E. Cherry Blossom Drive T-. , ' on~~r. n .. , ,. n^-i^ Denver, Colorado 80225 Portland, Oregon 97216 n CONTENTS Abstract..........................................................................................................................................................................1 Introduction .................................................................................................................................................................1 Purpose and scope.........................................................................................................................................3 Approach .......................................................................:..............................................................................................3 Results and discussion ................................................................................................................................................3 -

Application Note 63 Using Nonvolatile Static Rams
APPLICATION NOTE 63 Application Note 63 Using Nonvolatile Static RAMs Vast resources have been expended by the semicon- ability, higher density, low cost, and the ability to be used ductor industry trying to build a nonvolatile random ac- in any semiconductor memory application. cess read/write memory. The effort has been undertak- en because nonvolatile RAM offers several advantages While the various memory components designed to over other memory devices – DRAM, Static RAM, date do not meet the ideal memory scenario, each ex- Shadow RAM, EEPROM, EPROM and ROM – which cels in meeting one or more of the sought after attributes were developed to meet specific applications needs. (Figure 1). Characteristics of the ideal nonvolatile RAM are: low power consumption, higher performance, greater reli- MEMORY ATTRIBUTES Figure 1 EASE OF DATA COST INTERFACE NONVOLATILE DENSITY PERFORMANCE READ/WRITE RETENTION DRAM +++ +++ ++ +++ STATIC RAM +++ + +++ +++ NV SRAM +++ ++ + +++ +++ ++ PARTITIONABLE +++ ++ + +++ +++ ++ NV SRAM PSEUDO STATIC + + ++ + +++ FLASH ++ ++ ++ + ++ + ++ EEPROM + ++ + + + + EPROM ++ ++ ++ ++ + ++ OTP EPROM +++ +++ +++ +++ + +++ ROM +++ +++ +++ +++ + +++ + = Degree of excellence TYPES OF MEMORY ing much more current then an SRAM to maintain the Many types of memories have been devised to meet va- stored data. The net memory cell size is smaller for the rying application needs. However, nonvolatile read/ DRAM than for the SRAM, so the total cost per bit of write random access memories can be substituted for memory is less. The DRAM’s capacitors must be con- all memory types independent of application, if cost is stantly refreshed so that they retain their charge, and re- not a primary consideration. quire more sophisticated interface circuitry. DRAM: Dynamic Random Access Memory.