Statistical Analysis of a Class: Monte Carlo and Multiple Imputation Spreadsheet Methods for Estimation and Extrapolation Laurel J
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Savvy Survey #16: Data Analysis and Survey Results1 Milton G
AEC409 The Savvy Survey #16: Data Analysis and Survey Results1 Milton G. Newberry, III, Jessica L. O’Leary, and Glenn D. Israel2 Introduction In order to evaluate the effectiveness of a program, an agent or specialist may opt to survey the knowledge or Continuing the Savvy Survey Series, this fact sheet is one of attitudes of the clients attending the program. To capture three focused on working with survey data. In its most raw what participants know or feel at the end of a program, he form, the data collected from surveys do not tell much of a or she could implement a posttest questionnaire. However, story except who completed the survey, partially completed if one is curious about how much information their clients it, or did not respond at all. To truly interpret the data, it learned or how their attitudes changed after participation must be analyzed. Where does one begin the data analysis in a program, then either a pretest/posttest questionnaire process? What computer program(s) can be used to analyze or a pretest/follow-up questionnaire would need to be data? How should the data be analyzed? This publication implemented. It is important to consider realistic expecta- serves to answer these questions. tions when evaluating a program. Participants should not be expected to make a drastic change in behavior within the Extension faculty members often use surveys to explore duration of a program. Therefore, an agent should consider relevant situations when conducting needs and asset implementing a posttest/follow up questionnaire in several assessments, when planning for programs, or when waves in a specific timeframe after the program (e.g., six assessing customer satisfaction. -

Evolution of the Infographic
EVOLUTION OF THE INFOGRAPHIC: Then, now, and future-now. EVOLUTION People have been using images and data to tell stories for ages—long before the days of the Internet, smartphones, and Excel. In fact, the history of infographics pre-dates the web by more than 30,000 years with the earliest forms of these visuals being cave paintings that helped early humans find food, resources, and shelter. But as technology has advanced, so has our ability to tell meaningful stories. Here’s a look into the evolution of modern infographics—where they’ve been, how they’ve evolved, and where they’re headed. Then: Printed, static infographics The 20th Century introduced the infographic—a staple for how we communicate, visualize, and share information today. Early on, these print graphics married illustration and data to communicate information in a revolutionary way. ADVANTAGE Design elements enable people to quickly absorb information previously confined to long paragraphs of text. LIMITATION Static infographics didn’t allow for deeper dives into the data to explore granularities. Hoping to drill down for more detail or context? Tough luck—what you see is what you get. Source: http://www.wired.co.uk/news/archive/2012-01/16/painting- by-numbers-at-london-transport-museum INFOGRAPHICS THROUGH THE AGES DOMO 03 Now: Web-based, interactive infographics While the first wave of modern infographics made complex data more consumable, web-based, interactive infographics made data more explorable. These are everywhere today. ADVANTAGE Everyone looking to make data an asset, from executives to graphic designers, are now building interactive data stories that deliver additional context and value. -
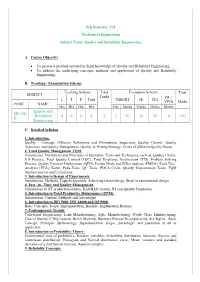
D Quality and Reliability Engineering 4 0 0 4 4 3 70 30 20 0
B.E Semester: VII Mechanical Engineering Subject Name: Quality and Reliability Engineering A. Course Objective To present a problem oriented in depth knowledge of Quality and Reliability Engineering. To address the underlying concepts, methods and application of Quality and Reliability Engineering. B. Teaching / Examination Scheme Teaching Scheme Total Evaluation Scheme Total SUBJECT Credit PR. / L T P Total THEORY IE CIA VIVO Marks CODE NAME Hrs Hrs Hrs Hrs Hrs Marks Marks Marks Marks Quality and ME706- Reliability 4 0 0 4 4 3 70 30 20 0 120 D Engineering C. Detailed Syllabus 1. Introduction: Quality – Concept, Different Definitions and Dimensions, Inspection, Quality Control, Quality Assurance and Quality Management, Quality as Wining Strategy, Views of different Quality Gurus. 2. Total Quality Management TQM: Introduction, Definitions and Principles of Operation, Tools and Techniques, such as, Quality Circles, 5 S Practice, Total Quality Control (TQC), Total Employee Involvement (TEI), Problem Solving Process, Quality Function Deployment (QFD), Failure Mode and Effect analysis (FMEA), Fault Tree Analysis (FTA), Kizen, Poka-Yoke, QC Tools, PDCA Cycle, Quality Improvement Tools, TQM Implementation and Limitations. 3. Introduction to Design of Experiments: Introduction, Methods, Taguchi approach, Achieving robust design, Steps in experimental design 4. Just –in –Time and Quality Management: Introduction to JIT production system, KANBAN system, JIT and Quality Production. 5. Introduction to Total Productive Maintenance (TPM): Introduction, Content, Methods and Advantages 6. Introduction to ISO 9000, ISO 14000 and QS 9000: Basic Concepts, Scope, Implementation, Benefits, Implantation Barriers 7. Contemporary Trends: Concurrent Engineering, Lean Manufacturing, Agile Manufacturing, World Class Manufacturing, Cost of Quality (COQ) system, Bench Marking, Business Process Re-engineering, Six Sigma - Basic Concept, Principle, Methodology, Implementation, Scope, Advantages and Limitation of all as applicable. -

Using Survey Data Author: Jen Buckley and Sarah King-Hele Updated: August 2015 Version: 1
ukdataservice.ac.uk Using survey data Author: Jen Buckley and Sarah King-Hele Updated: August 2015 Version: 1 Acknowledgement/Citation These pages are based on the following workbook, funded by the Economic and Social Research Council (ESRC). Williamson, Lee, Mark Brown, Jo Wathan, Vanessa Higgins (2013) Secondary Analysis for Social Scientists; Analysing the fear of crime using the British Crime Survey. Updated version by Sarah King-Hele. Centre for Census and Survey Research We are happy for our materials to be used and copied but request that users should: • link to our original materials instead of re-mounting our materials on your website • cite this as an original source as follows: Buckley, Jen and Sarah King-Hele (2015). Using survey data. UK Data Service, University of Essex and University of Manchester. UK Data Service – Using survey data Contents 1. Introduction 3 2. Before you start 4 2.1. Research topic and questions 4 2.2. Survey data and secondary analysis 5 2.3. Concepts and measurement 6 2.4. Change over time 8 2.5. Worksheets 9 3. Find data 10 3.1. Survey microdata 10 3.2. UK Data Service 12 3.3. Other ways to find data 14 3.4. Evaluating data 15 3.5. Tables and reports 17 3.6. Worksheets 18 4. Get started with survey data 19 4.1. Registration and access conditions 19 4.2. Download 20 4.3. Statistics packages 21 4.4. Survey weights 22 4.5. Worksheets 24 5. Data analysis 25 5.1. Types of variables 25 5.2. Variable distributions 27 5.3. -

Monte Carlo Likelihood Inference for Missing Data Models
MONTE CARLO LIKELIHOOD INFERENCE FOR MISSING DATA MODELS By Yun Ju Sung and Charles J. Geyer University of Washington and University of Minnesota Abbreviated title: Monte Carlo Likelihood Asymptotics We describe a Monte Carlo method to approximate the maximum likeli- hood estimate (MLE), when there are missing data and the observed data likelihood is not available in closed form. This method uses simulated missing data that are independent and identically distributed and independent of the observed data. Our Monte Carlo approximation to the MLE is a consistent and asymptotically normal estimate of the minimizer ¤ of the Kullback- Leibler information, as both a Monte Carlo sample size and an observed data sample size go to in¯nity simultaneously. Plug-in estimates of the asymptotic variance are provided for constructing con¯dence regions for ¤. We give Logit-Normal generalized linear mixed model examples, calculated using an R package that we wrote. AMS 2000 subject classi¯cations. Primary 62F12; secondary 65C05. Key words and phrases. Asymptotic theory, Monte Carlo, maximum likelihood, generalized linear mixed model, empirical process, model misspeci¯cation 1 1. Introduction. Missing data (Little and Rubin, 2002) either arise naturally|data that might have been observed are missing|or are intentionally chosen|a model includes random variables that are not observable (called latent variables or random e®ects). A mixture of normals or a generalized linear mixed model (GLMM) is an example of the latter. In either case, a model is speci¯ed for the complete data (x; y), where x is missing and y is observed, by their joint den- sity f(x; y), also called the complete data likelihood (when considered as a function of ). -

Quality Assurance: Best Practices in Clinical SAS® Programming
NESUG 2012 Management, Administration and Support Quality Assurance: Best Practices in Clinical SAS® Programming Parag Shiralkar eClinical Solutions, a Division of Eliassen Group Abstract SAS® programmers working on clinical reporting projects are often under constant pressure of meeting tight timelines, producing best quality SAS® code and of meeting needs of customers. As per regulatory guidelines, a typical clinical report or dataset generation using SAS® software is considered as software development. Moreover, since statistical reporting and clinical programming is a part of clinical trial processes, such processes are required to follow strict quality assurance guidelines. While SAS® programmers completely focus on getting best quality deliverable out in a timely manner, quality assurance needs often get lesser priorities or may get unclearly understood by clinical SAS® programming staff. Most of the quality assurance practices are often focused on ‘process adherence’. Statistical programmers using SAS® software and working on clinical reporting tasks need to maintain adequate documentation for the processes they follow. Quality control strategy should be planned prevalently before starting any programming work. Adherence to standard operating procedures, maintenance of necessary audit trails, and necessary and sufficient documentation are key aspects of quality. This paper elaborates on best quality assurance practices which statistical programmers working in pharmaceutical industry are recommended to follow. These quality practices -

Interactive Statistical Graphics/ When Charts Come to Life
Titel Event, Date Author Affiliation Interactive Statistical Graphics When Charts come to Life [email protected] www.theusRus.de Telefónica Germany Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 2 www.theusRus.de What I do not talk about … Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 3 www.theusRus.de … still not what I mean. Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 4 www.theusRus.de Interactive Graphics ≠ Dynamic Graphics • Interactive Graphics … uses various interactions with the plots to change selections and parameters quickly. Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 4 www.theusRus.de Interactive Graphics ≠ Dynamic Graphics • Interactive Graphics … uses various interactions with the plots to change selections and parameters quickly. • Dynamic Graphics … uses animated / rotating plots to visualize high dimensional (continuous) data. Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 4 www.theusRus.de Interactive Graphics ≠ Dynamic Graphics • Interactive Graphics … uses various interactions with the plots to change selections and parameters quickly. • Dynamic Graphics … uses animated / rotating plots to visualize high dimensional (continuous) data. 1973 PRIM-9 Tukey et al. Interactive Statistical Graphics – When Charts come to Life PSI Graphics One Day Meeting Martin Theus 4 www.theusRus.de Interactive Graphics ≠ Dynamic Graphics • Interactive Graphics … uses various interactions with the plots to change selections and parameters quickly. • Dynamic Graphics … uses animated / rotating plots to visualize high dimensional (continuous) data. -

Data Quality Monitoring and Surveillance System Evaluation
TECHNICAL DOCUMENT Data quality monitoring and surveillance system evaluation A handbook of methods and applications www.ecdc.europa.eu ECDC TECHNICAL DOCUMENT Data quality monitoring and surveillance system evaluation A handbook of methods and applications This publication of the European Centre for Disease Prevention and Control (ECDC) was coordinated by Isabelle Devaux (senior expert, Epidemiological Methods, ECDC). Contributing authors John Brazil (Health Protection Surveillance Centre, Ireland; Section 2.4), Bruno Ciancio (ECDC; Chapter 1, Section 2.1), Isabelle Devaux (ECDC; Chapter 1, Sections 3.1 and 3.2), James Freed (Public Health England, United Kingdom; Sections 2.1 and 3.2), Magid Herida (Institut for Public Health Surveillance, France; Section 3.8 ), Jana Kerlik (Public Health Authority of the Slovak Republic; Section 2.1), Scott McNabb (Emory University, United States of America; Sections 2.1 and 3.8), Kassiani Mellou (Hellenic Centre for Disease Control and Prevention, Greece; Sections 2.2, 2.3, 3.3, 3.4 and 3.5), Gerardo Priotto (World Health Organization; Section 3.6), Simone van der Plas (National Institute of Public Health and the Environment, the Netherlands; Chapter 4), Bart van der Zanden (Public Health Agency of Sweden; Chapter 4), Edward Valesco (Robert Koch Institute, Germany; Sections 3.1 and 3.2). Project working group members: Maria Avdicova (Public Health Authority of the Slovak Republic), Sandro Bonfigli (National Institute of Health, Italy), Mike Catchpole (Public Health England, United Kingdom), Agnes -

Quality Control and Reliability Engineering 1152Au128 3 0 0 3
L T P C QUALITY CONTROL AND RELIABILITY ENGINEERING 1152AU128 3 0 0 3 1. Preamble This course provides the essentiality of SQC, sampling and reliability engineering. Study on various types of control charts, six sigma and process capability to help the students understand various quality control techniques. Reliability engineering focuses on the dependability, failure mode analysis, reliability prediction and management of a system 2. Pre-requisite NIL 3. Course Outcomes Upon the successful completion of the course, learners will be able to Level of learning CO Course Outcomes domain (Based on Nos. C01 Explain the basic concepts in Statistical Process Control K2 Apply statistical sampling to determine whether to accept or C02 K2 reject a production lot Predict lifecycle management of a product by applying C03 K2 reliability engineering techniques. C04 Analyze data to determine the cause of a failure K2 Estimate the reliability of a component by applying RDB, C05 K2 FMEA and Fault tree analysis. 4. Correlation with Programme Outcomes Cos PO1 PO2 PO3 PO4 PO5 PO6 PO7 PO8 PO9 PO10 PO11 PO12 PSO1 PSO2 CO1 H H H M L H M L CO2 H H H M L H H M CO3 H H H M L H L H CO4 H H H M L H M M CO5 H H H M L H L H H- High; M-Medium; L-Low 5. Course content UNIT I STATISTICAL QUALITY CONTROL L-9 Methods and Philosophy of Statistical Process Control - Control Charts for Variables and Attributes Cumulative Sum and Exponentially Weighted Moving Average Control Charts - Other SPC Techniques Process - Capability Analysis - Six Sigma Concept. -

Statistical Quality Control Methods in Infection Control and Hospital Epidemiology, Part I: Introduction and Basic Theory Author(S): James C
Statistical Quality Control Methods in Infection Control and Hospital Epidemiology, Part I: Introduction and Basic Theory Author(s): James C. Benneyan Source: Infection Control and Hospital Epidemiology, Vol. 19, No. 3 (Mar., 1998), pp. 194-214 Published by: The University of Chicago Press Stable URL: http://www.jstor.org/stable/30143442 Accessed: 25/06/2010 18:26 Your use of the JSTOR archive indicates your acceptance of JSTOR's Terms and Conditions of Use, available at http://www.jstor.org/page/info/about/policies/terms.jsp. JSTOR's Terms and Conditions of Use provides, in part, that unless you have obtained prior permission, you may not download an entire issue of a journal or multiple copies of articles, and you may use content in the JSTOR archive only for your personal, non-commercial use. Please contact the publisher regarding any further use of this work. Publisher contact information may be obtained at http://www.jstor.org/action/showPublisher?publisherCode=ucpress. Each copy of any part of a JSTOR transmission must contain the same copyright notice that appears on the screen or printed page of such transmission. JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. The University of Chicago Press is collaborating with JSTOR to digitize, preserve and extend access to Infection Control and Hospital Epidemiology. -

Questionnaire Analysis Using SPSS
Questionnaire design and analysing the data using SPSS page 1 Questionnaire design. For each decision you make when designing a questionnaire there is likely to be a list of points for and against just as there is for deciding on a questionnaire as the data gathering vehicle in the first place. Before designing the questionnaire the initial driver for its design has to be the research question, what are you trying to find out. After that is established you can address the issues of how best to do it. An early decision will be to choose the method that your survey will be administered by, i.e. how it will you inflict it on your subjects. There are typically two underlying methods for conducting your survey; self-administered and interviewer administered. A self-administered survey is more adaptable in some respects, it can be written e.g. a paper questionnaire or sent by mail, email, or conducted electronically on the internet. Surveys administered by an interviewer can be done in person or over the phone, with the interviewer recording results on paper or directly onto a PC. Deciding on which is the best for you will depend upon your question and the target population. For example, if questions are personal then self-administered surveys can be a good choice. Self-administered surveys reduce the chance of bias sneaking in via the interviewer but at the expense of having the interviewer available to explain the questions. The hints and tips below about questionnaire design draw heavily on two excellent resources. SPSS Survey Tips, SPSS Inc (2008) and Guide to the Design of Questionnaires, The University of Leeds (1996). -

Methodological Challenges Associated with Meta-Analyses in Health Care and Behavioral Health Research
o title: Methodological Challenges Associated with Meta Analyses in Health Care and Behavioral Health Research o date: May 14, 2012 Methodologicalo author: Challenges Associated with Judith A. Shinogle, PhD, MSc. Meta-AnalysesSenior Research Scientist in Health , Maryland InstituteCare for and Policy Analysis Behavioraland Research Health Research University of Maryland, Baltimore County 1000 Hilltop Circle Baltimore, Maryland 21250 http://www.umbc.edu/mipar/shinogle.php Judith A. Shinogle, PhD, MSc Senior Research Scientist Maryland Institute for Policy Analysis and Research University of Maryland, Baltimore County 1000 Hilltop Circle Baltimore, Maryland 21250 http://www.umbc.edu/mipar/shinogle.php Please see http://www.umbc.edu/mipar/shinogle.php for information about the Judith A. Shinogle Memorial Fund, Baltimore, MD, and the AKC Canine Health Foundation (www.akcchf.org), Raleigh, NC. Inquiries may also be directed to Sara Radcliffe, Executive Vice President for Health, Biotechnology Industry Organization, www.bio.org, 202-962-9200. May 14, 2012 Methodological Challenges Associated with Meta-Analyses in Health Care and Behavioral Health Research Judith A. Shinogle, PhD, MSc I. Executive Summary Meta-analysis is used to inform a wide array of questions ranging from pharmaceutical safety to the relative effectiveness of different medical interventions. Meta-analysis also can be used to generate new hypotheses and reflect on the nature and possible causes of heterogeneity between studies. The wide range of applications has led to an increase in use of meta-analysis. When skillfully conducted, meta-analysis is one way researchers can combine and evaluate different bodies of research to determine the answers to research questions. However, as use of meta-analysis grows, it is imperative that the proper methods are used in order to draw meaningful conclusions from these analyses.