Package 'Stylo'
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

{DOWNLOAD} One False Move
ONE FALSE MOVE Author: Harlan Coben Number of Pages: 383 pages Published Date: 25 Aug 2009 Publisher: Random House USA Inc Publication Country: New York, United States Language: English ISBN: 9780440246091 DOWNLOAD: ONE FALSE MOVE One False Move PDF Book Well, finally there s a professional out there who s not too embarrassed to answer bone-fide veterinarian, critical-care specialist, and dog lover Dr. They have been supremely successful homeschoolers themselves. Women have more options than step aerobics or running on a treadmill to shed pounds: they can weight-train in a very specific manner designed to make the most of a woman's unique physiology. He is one of the most prominent nutrition and anti- aging-specialists in Germany. This workbook is based in cognitive behavioral therapy, a powerful approach that has been proven to be more effective over the long run than sleeping pills. To this end, the Institute has brought together insiders and peers from allover the world to discuss basic principles and latest results and to help correlate future research effort. Anne Spencer is the author of Alone at Sea: The Adventures of Joshua Slocum and three books of sea stories and folklore for young adults. com This book is a reproduction of an important historical work. Style and approach Learn about Spark's infrastructure with this practical tutorial. While tracking down the U-boat veterans, Wiggins came across photographs and secret diaries and gained access to personnel records. When Romeo Montague meets and falls instantly in love with Juliet Capulet, it can only lead to a tragic end. -
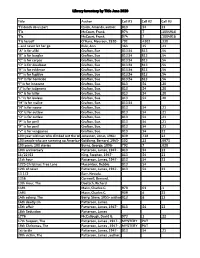
Library Inventory by Title June 2020 Title Author Call
Library Inventory by Title June 2020 Title Author Call #1 Call #2 Call #3 'Til death do us part Quick, Amanda, author. 813 .54 23 'Tis McCourt, Frank. 974 .7 .1004916 'Tis McCourt, Frank. 974 .7 .1004916 'Tis herself O'Hara, Maureen, 1920- 791 .4302 .330 --and never let her go Rule, Ann. 364 .15 .23 "A" is for alibi Grafton, Sue 813.54 813 .54 "B" is for burglar Grafton, Sue 813.54 813 .54 "C" is for corpse Grafton, Sue 813.54 813 .54 "D" is for deadbeat Grafton, Sue 813.54 813 .54 "E" is for evidence Grafton, Sue 813.54 813 .54 "F" is for fugitive Grafton, Sue 813.54 813 .54 "H" is for homicide Grafton, Sue 813.54 813 .54 "I" is for innocent Grafton, Sue. 813 .54 .20 "J" is for judgment Grafton, Sue. 813 .54 .20 "K" is for killer Grafton, Sue. 813 .54 .20 "L" is for lawless Grafton, Sue. 813 .54 .20 "M" is for malice Grafton, Sue. 813.54 "N" is for noose Grafton, Sue. 813 .54 .21 "O" is for outlaw Grafton, Sue. 813 .54 .21 "O" is for outlaw Grafton, Sue. 813 .54 .21 "P" is for peril Grafton, Sue. 813 .54 .21 "P" is for peril Grafton, Sue. 813 .54 .21 "V" is for vengeance Grafton, Sue. 813 .54 22 100-year-old man who climbed out the windowJonasson, and disappeared, Jonas, 1961- The 839 .738 23 100 people who are screwing up America--andGoldberg, Al Franken Bernard, is #3 1945- 302 .23 .0973 100 years, 100 stories Burns, George, 1896- 792 .7 .028 10th anniversary Patterson, James, 1947- 813 .54 22 11/22/63 King, Stephen, 1947- 813 .54 23 11th hour Patterson, James, 1947- 813 .54 23 1225 Christmas Tree Lane Macomber, Debbie 813 .54 12th of never Patterson, James, 1947- 813 .54 23 13 1/2 Barr, Nevada. -

The Myron Bolitar Series by Harlan Coben
The Myron Bolitar series by Harlan Coben Deal Breaker [1995] Fade Away [1996] Sports agent and sometime Myron Bolitar once had a investigator Myron Bolitar is promising career as a sportsman, poised on the edge of the big until an accident forced him to time. So is Christian Steele, a quit. After a spell in the FBI he rookie quarterback and Myron's now runs his own business. Then prized client. But when Christian Myron is approached to find Greg gets a phone call from a former Downing. He knows Greg from girlfriend, a woman who everyone, including the old - they were once rivals, not just in sport, but for police, believes is dead, the deal starts to go sour. a woman they both loved. Now Greg has vanished, Suddenly Myron is plunged into a baffling mystery and the team boss wants Myron to find him, before of sex and blackmail. Trying to unravel the truth news of his disappearance is leaked to the press. In about a family's tragedy, a woman's secret and a Greg's house Myron finds blood in the basement - man's lies, Myron is up against the dark side of his lots of it. And when he discovers the body of a business - where image and talent make you rich, woman, he begins to unravel the strange, violent but the truth can get you killed. world of a national hero gone wrong, as he comes face to face with a past he can't re live, and a Drop Shot [1996] present he may not survive. -

HBG Adult Winter 2021 - Page 1
GRAND CENTRAL PUBLISHING What's Mine and Yours Naima Coster Summary From the author of Halsey Street, a sweeping novel of legacy, identity, the American family-and the ways that race affects even our most intimate relationships. A community in the Piedmont of North Carolina rises in outrage as a county initiative draws students from the largely Black east side of town into predominantly white high schools on the west. For two students, Gee and Noelle, the integration sets off a chain of events that will tie their two families together in unexpected ways over the span of the next twenty years. On one side of the integration debate is Jade, Gee's steely, ambitious mother. In the aftermath of a harrowing loss, she is determined to give her son the tools he'll need to survive in America as a sensitive, anxious, Grand Central Publishing young Black man. On the other side is Noelle's headstrong mother, Lacey May, a white woman who refuses to 9781538702345 Pub Date: 3/2/21 see her half-Latina daughters as anything but white. She strives to protect them as she couldn't protect On Sale Date: 3/2/21 herself from the influence of their charming but unreliable father, Robbie. $28.00 USD/$35.00 CAD Hardcover When Gee and Noelle join the school play meant to bridge the divi... 352 Pages Carton Qty: 20 Contributor Bio Print Run: 25K Naima Coster is the author of HALSEY STREET, and a finalist for the 2018 Kirkus Prize for Fiction. Naima's Fiction / Family Life FIC045000 stories and essays have appeared in the New York Times, Kweli, The Paris Review Daily, Catapult, The Rumpus, and elsewhere. -

BOOKNEWS from ISSN 1056–5655, © the Poisoned Pen, Ltd
BOOKNEWS from ISSN 1056–5655, © The Poisoned Pen, Ltd. 4014 N. Goldwater Blvd. Volume 31, Number 4 Scottsdale, AZ 85251 March Booknews 2019 480-947-2974 [email protected] tel (888)560-9919 http://poisonedpen.com MARCH MADNESS AND MYSTERY AUTHORS ARE SIGNING… Some Events will be webcast on Facebook Live Check out our new YouTube Channel MONDAY MARCH 4 7:00 PM TUESDAY MARCH 19 7:00 PM Phillip Margolin signs The Perfect Alibi (St Martins $27.99) Greg Iles signs Cemetery Road (Harper $28.99) Our March Surprise Me! Book of the Month WEDNESDAY MARCH 20 7:00 PM Harriet Tyce signs Blood Orange (Grand Central $26) The Janet Cussler Car Collection March First Mystery Book of the Month 16055 North Dial Boulevard, Suite 16, Scottsdale 85260 WEDNESDAY MARCH 6 7:00 PM Clive and Dirk Cussler sign Celtic Empire (Putnam $29) Steve Berry signs The Malta Exchange (St Martins $28.99 Dirk Pitt #25 Cotton Malone #14 THURSDAY MARCH 21 7:00 PM Our copies come with a collectible created and signed by Berry Joe R. Lansdale signs The Elephant of Surprise FRIDAY MARCH 8 (LittleBrown $26) Isabella Maldonado signs Death Blow (Midnight Ink $15.99) Hap & Leonard Veranda Cruz police procedural #3 FRIDAY MARCH 22 7:00 PM MONDAY MARCH 11 7:00 PM Lisa See signs The Island of Sea Women (Scribner $27) Kerr Cultural Center 6110 N Scottsdale Rd 85253 (enter via Rose TUESDAY MARCH 26 7:00 PM Lane, take first left to the Kerr) Jacqueline Winspear signs The American Agent CJ Box signs Wolf Pack (Putnam $27 (Harper $27.99) Joe Pickett #19 And What Would Maisie Do? ($17.99) An illustrated companion Our copies come with art that CJ Box describes as “having a nice to the Maisie Dobbs mysteries creepy feel to it and has always been one of my favorites” WEDNESDAY MARCH `3 7:00 PM WEDNESDAY MARCH 27 7:00 PM Deanna Raybourn signs A Dangerous Collaboration Linda Fairstein signs. -

Sports Mysteries
Sports Mysteries Bernhardt, William (Golf): Cruel Justice; Final Round Borthwick, J.S. (Golf): Murder in the Rough Boyle, Alistair (Boating): Ship Shapely Briody, Thomas (Boating): Rogue’s Regatta Christie, Agatha (Golf): Murder on the Links; Why Didn’t They Ask Evans? Coben, Harlan (Sports Agents and Various Sports): Deal Breaker; The Final Detail; Drop Shot; Darkest Fear; Back Spin; Fade Away; The Final Detail; Live Wire; One False Move; Play Dead; Promise Me Cornwell, Bernard (Cricket): Gallow’s Thief Corrigan, J.R. (Golf): Snap Hook; Center Cut; Bad Lie Craig, Philip (Golf): Dead in Vineyard Sand Crane, Hamilton (Cricket): Miss Seeton Goes to Bat Daly, Conor (Golf): Outside Agency Dexter, Pete (Golf): Train Ehman, Kit (Kentucky Derby): Triple Cross Eidson, Bill (Boating): The Repo Elkins, Charlotte (Golf): Rotten Lies; Nasty Breaks; On the Fringe Evers, Crabbe (Baseball): Fear in Fenway Feinstein, John (Basketball): Winter Games Francis, Dick (Horse Racing): 10lb Penalty; Blood Sport; Bolt; Break In; Come to Grief; Comeback; Crossfire; Dead Cert; Dead Heat; Decider; Dick Francis’s Gamble; Driving Force; The Edge; Enquiry; Even Money; Field of Thirteen; For Kicks; Forfeit; Hot Money; Knockdown; Longshot; Nerve; Odds Against; Proof; Rat Race; Risk; Shattered; Silks; Straight; To the Hilt; Trial Run; Twice Shy; Under Orders; Whip Hand; Wild Horses; Win, Place, or Show Gordon, Alison (Baseball): The Dead Pull Hitter Gray, Malcolm (Golf): An Unwelcome Presence Green, Tim (Football): Double Reverse; Ruffians Grissom, Ken (Boating): Drop-Off -
Indian Shores Library Items by Title.Xlsx
Title Author 2nd Author 'Til death do us part Quick, Amanda, author. 'Tis McCourt, Frank. 'Tis McCourt, Frank. 'Tis herself O'Hara, Maureen, 1920-Nicoletti, John, 1962- --and never let her go Rule, Ann. "A" is for alibi Grafton, Sue Grafton, Sue. "B" is for burglar Grafton, Sue Grafton, Sue. "C" is for corpse Grafton, Sue Grafton, Sue. "D" is for deadbeat Grafton, Sue Grafton, Sue. "E" is for evidence Grafton, Sue Grafton, Sue. "F" is for fugitive Grafton, Sue Grafton, Sue. "H" is for homicide Grafton, Sue Grafton, Sue. "I" is for innocent Grafton, Sue. "J" is for judgment Grafton, Sue. "K" is for killer Grafton, Sue. "L" is for lawless Grafton, Sue. "M" is for malice Grafton, Sue. "N" is for noose Grafton, Sue. "O" is for outlaw Grafton, Sue. "O" is for outlaw Grafton, Sue. "P" is for peril Grafton, Sue. "P" is for peril Grafton, Sue. "V" is for vengeance Grafton, Sue. <New Title> <New Title> <New Title> <New Title> <New Title> <New Title> <New Title> <New Title> <New Title> 100-year-old man who climbed out theJonasson, window Jonas, and disappeared, 1961- Bradbury, The Rod. 100 people who are screwing up America--andGoldberg, AlBernard, Franken 1945- is #3 100 years, 100 stories Burns, George, 1896- 10th anniversary Patterson, James, 1947-Paetro, Maxine. 11/22/63 King, Stephen, 1947- 11th hour Patterson, James, 1947-Paetro, Maxine. 1225 Christmas Tree Lane Macomber, Debbie 12th of never Patterson, James, 1947-Paetro, Maxine. 13 1/2 Barr, Nevada. 1356 Cornwell, Bernard. 13th Hour, The Doetsch, Richard 1491 Mann, Charles C. -

Books by Mail Large Print Catalog
NEW MEXICO STATE LIBRARY Books By Mail Rural Services Large Print Catalog (Updated 5/2008) NEW MEXICO STATE LIBRARY BOOKS BY MAIL RURAL SERVICES We are now offering our Books By Mail patrons Gale Group InfoTrac Resources ! In an effort to bring electronic information resources to as many New Mexicans as possible, the New Mexico State Library is providing databases of magazines and journals to libraries and patrons via the Internet. The New Mexico State Library has chosen InfoTrac, a highly regarded resource of content-rich authoritative information through the Internet. The InfoTrac databases contain over 4,277 magazines and journals, 2,969 of them with full-text and full-image with the remainder offering abstracts to the articles. InfoTrac is a product of Gale Group, a major vendor of library magazine and journal subscriptions to libraries. Access to the databases is controlled through specific usernames and passwords which are established for constituent libraries and patrons throughout New Mexico. Each library is authorized to provide these usernames and passwords to its clients, students or patrons, thus giving access to any New Mexico citizen with Internet access. The Gale logon screen for NMSL Direct and Rural Services patrons is http://infotrac.galegroup.com/itweb/nmlibdrsb (The password is: cactus) Copyright requirements are covered by the arrangements that the Gale Group makes with the journals and magazines it includes in the databases. *We ask that you mention you are a Books By Mail patron when contacting the following numbers. For information or help contact either: Mark Adams 1-800-477-4401 or Teresa Martinez (505) 476-9781 or 1-800-395-9144 For information on how to use the database contact: Reference 1-800-876-2203 For information from the New Mexico State Library visit the web site at http://www.nmstatelibrary.org . -

Package 'Stylo'
Package ‘stylo’ November 4, 2019 Type Package Title Stylometric Multivariate Analyses Version 0.7.1 Date 2019-11-4 Author Maciej Eder, Jan Rybicki, Mike Kestemont, Steffen Pielstroem Maintainer Maciej Eder <[email protected]> URL https://github.com/computationalstylistics/stylo Depends R (>= 2.14) Imports tcltk, tcltk2, ape, pamr, e1071, class, lattice, tsne Suggests stringi, networkD3, readr Description Supervised and unsupervised multivariate methods, supplemented by GUI and some visu- alizations, to perform various analyses in the field of computational stylistics, authorship attribu- tion, etc. For further reference, see Eder et al. (2016), <https://journal.r- project.org/archive/2016/RJ-2016-007/index.html>. You are also encouraged to visit the Compu- tational Stylistics Group's website <https://computationalstylistics.github.io/>, where a reason- able amount of information about the package and related projects are provided. License GPL (>= 3) NeedsCompilation no Repository CRAN Date/Publication 2019-11-04 17:40:02 UTC R topics documented: assign.plot.colors . .3 change.encoding . .4 check.encoding . .5 classify . .6 crossv . .9 define.plot.area . 12 delete.markup . 13 delete.stop.words . 14 1 2 R topics documented: dist.cosine . 15 dist.delta . 17 dist.entropy . 18 dist.minmax . 19 dist.simple . 20 dist.wurzburg . 21 galbraith . 23 gui.classify . 24 gui.oppose . 25 gui.stylo . 26 imposters . 27 imposters.optimize . 29 lee.............................................. 31 load.corpus . 32 load.corpus.and.parse . 33 make.frequency.list . 35 make.ngrams . 36 make.samples . 38 make.table.of.frequencies . 40 novels............................................ 41 oppose . 42 parse.corpus . 44 parse.pos.tags . 46 perform.culling . 47 perform.delta . -

Mystery Series 1
Mystery Series 1 Adler-Olsen, Jussi 6. Aunt Dimity Beats the 13. Hard Truth Departement Q Devil 14. Winter Study 1. Keeper of Lost Causes 7. Aunt Dimity Detective 15. Borderline 2. The Absent One 8. Aunt Dimity Takes a 16. Burn 3. A Conspiracy of Faith Holiday 17. The Rope 4. The Purity of Vengeance 9. Aunt Dimity Snowbound 18. Destroyer Angel 5. The Marco Effect 10. Aunt Dimity and the Next 19. Boar Island 6. The Hanging Girl of Kin Beaton, M.C. 7. The Scarred Woman 11. Aunt Dimity and the Deep Agatha Raisin Andrews, Donna Blue Sea 1. Quiche of Death Meg Langslow 12. Aunt Dimity Goes West 2. Vicious Vet 1. Murder With Peacocks 13. Aunt Dimity, Vampire 3. Potted Gardener 2. Murder With Puffins Hunter 4. Walkers of Dembley 3. Revenge of the Wrought- 14. Aunt Dimity Slays the 5. Murderous Marriage Iron Flamingos Dragon 6. Terrible Tourist 4. Crouching Buzzard, 15. Aunt Dimity Down Under 7. Wellspring of Death Leaping Loon 16. Aunt Dimity and the 8. Wizard of Evesham 5. We’ll Always Have Parrots Family Tree 9. Witch of Wyckhadden 6. Owls Well That Ends Well 17. Aunt Dimity and the 10. Fairies of Fryfam 7. No Nest for the Wicket Village Witch 11. Love from Hell 8. The Penguin Who New 18. Aunt Dimity and the Lost 12. Day the Floods Came Too Much Prince 13. Case of the Curious 9. Cockatiels at Seven 19. Aunt Dimity and the Curate 10. Six Geese a-Slaying Wishing Well 14. The Haunted House 11. -
ONE FALSE MOVE... a Study of Children's Independent Mobility
ONE FALSE MOVE... A Study of Children's Independent Mobility Mayer Hillman, John Adams and John Whitelegg PUBLISHING The publishing imprint of the independent POLICY STUDIES INSTITUTE 100 Park Village East, London NW13SR Telephone: 071-387 2171; Fax: 071-388 0914 © Policy Studies Institute 1990 All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted, in any form or by any means, electronic or otherwise, without the prior permission of the Policy Studies Institute. ISBN 085374 494 7 A CIP catalogue record of this book is available from the British Library. 123456789 How to obtain PSI publications All book shop and individual orders should be sent to PSI's distributors: BEBCLtd 9 Albion Close, Parkstone, Bournemouth BH12 2LL. Books will normally be despatched in 24 hours. Cheques should be made payable to BEBCLtd. Credit card and telephone/fax orders may be placed on the following freephone numbers: FREEPHONE: 0800 262260 FREEFAX: 0800 262266 Booktrade Representation (UK & Eire) Book Representation Ltd P O Box 17, Canvey Island, Essex SS8 8HZ PSI Subscriptions PSI Publications are available on subscription. Further information from PSI's subscription agent: Carfax Publishing Company Ltd Abingdon Science Park, P O Box 25, Abingdon OX10 SUE Laserset by Policy Studies Institute Printed in Great Britain by Billing & Sons Ltd, Worcester Preface This report is based on a research study focused on junior schoolchildren aged 7 to 11, and senior schoolchildren aged 11 to 15. It explores their travel patterns and levels of personal autonomy, and the links that these have with their parents' perception of the danger to which their children are exposed when travelling on their own. -

January – June 2019 Contents
penguin random house highlights catalogue JANUARY – JUNE 2019 CONTENTS STAR DEBUTS 4 AFRIKAANSE FIKSIE 25 COMMERCIAL FICTION 9 NON-FICTION 29 CRIME & THRILLERS 14 BIOGRAPHIES 40 LITERARY FICTION 19 NATURE & TRAVEL 43 LOCAL FICTION 22 COOKERY 48 January – June 2019 STAR DEBUTS STAR DEBUTS Daisy Jones & The Six Taylor Jenkins Reid In 1979, Daisy Jones and The Six split up. Together, they had redefined the 70’s music scene, creating an iconic sound that rocked the world. Apart, they baffled a world that had hung on their every verse. This book is an attempt to piece together a clear portrait of the band’s rise to fame and their abrupt and infamous split. The following oral history is a compilation of interviews, emails, transcripts, and lyrics, all pertaining My Name is Anna She Lies in Wait Freefall to the personal and professional lives of the members of Lizzy Barber Gytha Lodge Jessica Barry the band The Six and singer Daisy Jones. All of which is to say that while this is the first and only Anna has been taught that virtue On a hot July night in 1983, six Surviving the plane crash is only the authorised account from all represented perspectives, is the path to God. But on her school friends go camping in the beginning for Allison. it should be noted that, in matters both big and small, eighteenth birthday she defies her forest. Bright and brilliant, they are The life that she’s built for herself reasonable people disagree. Mamma’s rules and visits Florida’s destined for great things, and young – her perfect fiancé, their world of The truth often lies, unclaimed, in the middle.