Buffer Pool Performance Improvements in the Innodb Storage Engine of Mariadb Server
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

View Company Overview
Real Business Relies on MariaDB™ About MariaDB Milestones MariaDB frees companies from the costs, constraints and complexity of proprietary databases, enabling them to reinvest in what matters most – rapidly developing innovative, Oct 2014 MariaDB customer-facing applications. MariaDB uses pluggable, purpose-built storage engines to Corporation formed support workloads that previously required a variety of specialized databases. With complexity and constraints eliminated, enterprises can now depend on a single complete database for all their needs, whether on commodity hardware or their cloud of choice. Deployed in minutes for transactional or analytical use cases, MariaDB delivers unmatched operational agility without Jan 2015 MariaDB MaxScale 1.0 sacrificing key enterprise features including real ACID compliance and full SQL. Trusted by organizations such as Deutsche Bank, DBS Bank, Nasdaq, Red Hat, The Home Depot, ServiceNow and Verizon – MariaDB meets the same core requirements as proprietary databases Oct 2015 MariaDB at a fraction of the cost. No wonder it’s the fastest growing open source database. Server 10.1 MariaDB at a Glance Dec 2016 MariaDB ColumnStore 1.0 Tens of millions of users worldwide Amount saved by Fastest growing Growing partner $ M 70+ ecosystem 9 migrating from April 2017 1st user 1 database Oracle conference: M|17 Customers May 2017 MariaDB TX 2.0 MariaDB Solutions MariaDB Services MariaDB TX Remote DBA Migration Services MariaDB AX Enterprise Architect Consulting Nov 2017 MariaDB AX Technical Support Training -

Mariadb / Mysql for Web Developers
www.fromdual.com MariaDB / MySQL for Web Developers Web Developer Congress 2020, remote Oli Sennhauser Senior MariaDB & MySQL Consultant at FromDual GmbH https://www.fromdual.com/presentations 1 / 27 About FromDual GmbH www.fromdual.com Support Consulting remote-DBA Training 2 / 27 Contents www.fromdual.com MariaDB / MySQL for Web Developers ➢ Databases ➢ Connecting to the database ➢ Basic database queries (SELECT) ➢ Changing Data (DML) ➢ Transactions ➢ Error Handling and Debugging ➢ Joining Tables ➢ Indexing 3 / 27 What are databases for? www.fromdual.com ● Primarily: Relational DBMS (RDBMS) ● Storing Business Information: ● CRM, ERP, Accounting, Shop, Booking, etc. ● What are they NOT for (non optimal)? ● Logs → Files, Logstash ● Images, PDFs, huge texts → Filer, Solr ● Trash → Waste bin 4 / 27 Different types of databases www.fromdual.com ● Flat files, CSV, ISAM ● Hierarchical database ● Relational databases (RDBMS) ● Network databases ● Object Oriented databases (OODBMS) ● Object Relational DBMS (ORDBMS) ● Graph databases ● Column Stores (MariaDB CS) ● "Document" Stores (JSON, MongoDB) ● Wide Column Stores (Cassandra, HBase) 5 / 27 Common Relational DBMS www.fromdual.com ● MariaDB ● more in the Web-Client-Server field (LAMP) ● MySQL ● more in the Web-Client-Server field (LAMP) ● PostgreSQL ● more in the fat-Client-Server Business Software field ● SQLite ● Not a real "Client-Server-DBMS" → Library ● Embedded DBMS (Industry, Firefox, etc.) 6 / 27 Connection to the DBMS www.fromdual.com ● GUI (MySQL Workbench, HeidiSQL) ● CLI (mariadb, -

Mariadb Enterprise \& Mariadb Enterprise Cluster
MariaDB Enterprise & MariaDB Enterprise Cluster MariaDB Enterprise Cluster in Azure - Test Drive Contents About the Test Drive 2 What is MariaDB? 2 About MariaDB Enterprise Cluster in Azure 2 Architecture ................................................... 2 Objective .................................................... 2 Getting Started 3 Configure WordPress .............................................. 3 Administering MariaDB Enterprise Cluster ................................... 3 Connecting to MaxScale ......................................... 3 Scenario 1: Taking one MaxScale node offline .............................. 4 Scenario 2: Taking one MariaDB Cluster data node offline ....................... 5 1 MariaDB Enterprise Cluster in Azure - Test Drive 2 About the Test Drive Welcome to the MariaDB Enterprise Cluster + MariaDB MaxScale test drive in Microsoft Azure! In this 2 hour test drive, we will dive in and see what MariaDB Enterprise Cluster and MariaDB MaxScale can do. This guide walks you through the steps on how the High Availability (HA) properties of the MariaDB Enterprise Cluster + MariaDB MaxScale solution work in practice. What is MariaDB? MariaDB is the fastest growing Open Source database with more than 12 million users worldwide. It is the database of choice to power applications at companies like booking.com, HP,Virgin Mobile and Wikipedia. MariaDB is secure at the enterprise-level, highly reliable and trusted by the world’s leading brands. Its extensible, modern architecture at every layer in the database allows for flexible configuration that supports both traditional and emerging enterprise use cases. About MariaDB Enterprise Cluster in Azure MariaDB Enterprise Cluster extends MariaDB, the widely adopted, MySQL-compatible open source database with Galera clustering technology. MariaDB MaxScale offers connection- and statement-based load balancing. The MariaDB Enterprise Cluster + MariaDB MaxScale solution for Azure consists of a 3-node MariaDB Enterprise Cluster and dual MariaDB MaxScale nodes in a Highly Available (HA) configuration. -

Mariadb Presentation
THE VALUE OF OPEN SOURCE MICHAEL ”MONTY” WIDENIUS Entrepreneur, MariaDB Hacker, MariaDB CTO MariaDB Corporation AB 2019-09-25 Seoul 11 Reasons Open Source is Better than Closed Source ● Using open standards (no lock in into proprietary standards) ● Resource friendly; OSS software tend to work on old hardware ● Lower cost; Usually 1/10 of closed source software ● No cost for testing the full software ● Better documentation and more troubleshooting resources ● Better support, in many cases directly from the developers ● Better security, auditability (no trap doors and more eye balls) ● Better quality; Developed together with users ● Better customizability; You can also participate in development ● No vendor lock in; More than one vendor can give support ● When using open source, you take charge of your own future Note that using open source does not mean that you have to become a software producer! OPEN SOURCE, THE GOOD AND THE BAD ● Open source is a better way to develop software ● More developers ● More spread ● Better code (in many cases) ● Works good for projects that can freely used by a lot of companies in their production or products. ● It's very hard to create a profitable company developing an open source project. ● Not enough money to pay developers. ● Hard to get money and investors for most projects (except for infrastructure projects like libraries or daemon services). OPEN SOURCE IS NATURAL OR WHY OPEN SOURCE WORKS ● You use open source because it's less expensive (and re-usable) ● You solve your own problems and get free help and development efforts from others while doing it. -

Before We Start…
Before we start… This is the Introduction to Databases Design and Implementation workshop • Download material: dartgo.org/db-design • Poll / Interactive questions: dartgo.org/poll • Optional software: https://dev.mysql.com/downloads/workbench/ • More info: rc.dartmouth.edu Introduction to Database Design and Implementation Christian Darabos, Ph.D. [email protected] Slides download: dartgo.org/db-design Overview • introduction to Databases and this workshop • development/production environments • tools (admin, browse, query, etc.) • DB design, UML and case study (http://www.datanamic.com/support/lt-dez005-introduction-db-model ing.html) • port model into MySQL Workbench Right-click > Open link in new window To keep open slides and poll dartgo.org/poll Research Computing Introduction • Research Computing service offering • Definition of a Relational Database • Overview of this workshop Right-click > Open link in new window To keep open slides and poll dartgo.org/poll Definition of a Relational Database (SQL) • a database type structured to recognize relations among stored items of information • designed to store text, dates/times, integers, floating-point number • implemented as a series of tables Mental Model • Think of a database as a set of spreadsheets • Each spreadsheet (or table) represents a type of entity (person, object, concept, etc.) • Better than Excel because it also models the relationship between the entities Why use a Relational Database • concurrent (simultaneous) read and write • powerful selecting, filtering and sorting cross-referencing tables • large quantity of structured storage and standardized distribution • minimize post-processing (simple analytics tools pre-implemented) • automate using any scripting and programming languages (R, Matlab, Python, C++, Java, PHP) • web-proof SQL vs. -

A Closer Look at Mysql Cluster an Architectural Overview - Mariadb White Paper - 08-26-13-001.Docx Page 1
w: www.mariadb.com e: [email protected] MySQL Cluster Internal Architecture Max Mether MariaDB Keywords: MySQL Cluster, MySQL, High Availability, HA, Clustering, Architecture 1 Introduction MySQL Cluster is tightly linked to the MySQL server, yet it is a separate product. Due to its distributed nature, MySQL Cluster has a far more complicated architecture than a standard MySQL database. This presentation and white paper will describe the internal architecture of the MySQL Cluster product and the different mechanisms and process that exists to insure the availability of the cluster. We will also take a close look at the data and message flow that takes place between the nodes in the cluster during different types of operations. 2 MySQL Cluster Features MySQL Cluster can be distinguished from many other clustering products in that it offers five nines availability with a shared-nothing architecture. Most clustering products use a shared-disk architecture. Using a shared- nothing architecture allows the cluster to run on commodity hardware, thus greatly reducing costs compared to shared-disk architecture. Having a shared-nothing architecture does, however, come with a different cost, namely, a more complex way of ensuring high availability and synchronization of the nodes which is mainly seen as increased network traffic. MySQL Cluster also provides ACID transactions with row level locking using the READ-COMMITTED isolation level. MySQL Cluster is, in general, an in-memory database, however non-indexed data can be stored on disk and the disks are also used for checkpointing to ensure durability through system shutdown. MySQL cluster provides unique hash indexes as well as ordered T-tree indexes. -

In Mysql/Mariadb?
T h e O W A S P F o u n d a t i o n h t t p : / / w w w . o w a s p . o r g O W A S P E U T o u r B u c h a Do you r e s“GRANT ALL PRIVILEGES” t ... in MySQL/MariaDB? 2 0 1 DevOps Engineer 3 Gabriel PREDA [email protected] @eRadical Co pyr igh t © Th e O W AS P Fo un dat ion Per mi ssi on is gr ant ed to co py, dis tri bu te an d/ or mo dif y thi s do cu me nt un de r the ter ms of the O W AS P Lic en se. 2 DevOps = new BORG DevOps Engineer ??? ● Development – Web Applications (“Certified MySQL Associate”, “Zend Certified Engineer”) – Real Time Analytics ● Operations – MySQL DBA (15+ instances) – Sysadmin (<25 virtual & physical servers) 3 My MySQL● Over 15 MariaDB / TokuDBMariaDB(s) instances ● Statistics in MariaDB – < 1TB from Oct 2012 – < 12G raw data daily – < 12,000,000 events processed daily – < 90,000,000 rows added daily BigData? NO!!! ● I can copy all of that to my laptop ● “Working data set” - less than 1G & less than 7,500,000 rows 4 MySQL History ● 1983 – first version of MySQL created by Monty Wideniuns ● 1994 – MySQL is released OpenSource ● 2004 Oct – MySQL 4.1 GA ● 2005 Oct – InnoDB (Innobase) is bought by Oracle – Black Friday ● 2008 Ian – MySQL AB is bought by Sun (1bn $) ● 2008 Nov – MySQL 5.1 GA ● 2009 Apr – Sun is bought by Oracle (7,4 bn $) ● 2010 Dec – MySQL 5.5 GA ● 2012 Apr – MariaDB 5.5 GA ● 2013 Feb – MySQL 5.6 – first version made by Oracle ● 2013 Feb – MySQL will be replaced by MariaDB in Fedora & OpenSuSE * Max Mether – SkySQL “MySQL and MariaDB: Past, Present and Future” 5 Where are we NOW()? Drizzle MySQL TokuDB (Oracle) (Tokutek) Percona Server (Percona) MariaDB (Monty Program, Brighthouse MariaDB Foundation) (Infobright) Replication: ● Asynchronous InfiniDB ● Semi-synchronous (Calpont) ● Galera Synchronous (Codership) ● Tungsten Replication (Continuent) 6 Elementary.. -

The S3 Storage Engine in Mariadb 10.5 FOSDEM 2020
The S3 storage engine in MariaDB 10.5 FOSDEM 2020 Michael Widenius CTO @ MariaDB What is Amazon S3 ● Storage of files in the cloud ● Works through http requests (think get/put) ● Supports basic functions like list files, copy to/from and delete. ● Move is implemented as copy + delete of the whole file (not fast) ● Quite slow for small files. Optimal file size for retrial is said to be around 4M. ● Many vendors support storage of files according to the ‘S3 interface’ ● Not really usable for databases who needs to update blocks withing a file. S3 storage ● All files are stored in one of several ‘buckets’ ● Files are stored as objects in a bucket accessed with a key. ● The key may contain ‘/’ and commands like ‘aws ls’ make S3 storage to feel like a file structure, even it it really isn’t. S3 storage engine in MariaDB 10.5 ● Read only tables (perfect for inexpensive archiving of old data). ● For some organizations S3 storage is cheaper than local storage ● Data and index can optionally be compressed on S3, which can make storage even cheaper. ● S3 works with partitioning for flexible handling of multiple tables ● Very fast, thanks to reading of blocks in big chunks (4M by default) ● Supports all key formats and optimizations that Aria supports ● Data can be accessed by multiple MariaDB servers. Tables are automatically discovered when needed. ● S3 has it’s own page cache ● S3 is also backported to 10.3 and 10.4 MariaDB enterprise server Converting a table to S3 Converting a table to S3: ALTER TABLE old_table ENGINE=S3 And converting back to local: ALTER TABLE table_on_s3 ENGINE=InnoDB Internally the data is first copied to a local Aria table with ROW_FORMAT=PAGE TRANSACTIONAL=0 and then moved to S3. -

Webscalesql : Basic Details and Installation
The Customize Windows Technology Blog http://thecustomizewindows.com WebScaleSQL : Basic Details and Installation Author : Abhishek WebScaleSQL is a modified MySQL Database developed by Engineers at Facebook, Google, LinkedIn, and Twitter for making kind of scalable SQL. Everyone knows about MySQL Database. Those who do not know what is MySQL, they can read our previously published article - What is MySQL, Why We Need MySQL. At the time of publishing this article; WebScaleSQL is on everyone's lips. MySQL is great, but it is not intended to be Scalable when it was written, that is the basic reason why we try to make Scalable MySQL Database for CMS like WordPress in a kind of legacy mode. WebScaleSQL is kind of fork of MySQL. WebScaleSQL : Basics Need for the Approach Flexibility and Scalability are the Key Benefits of Cloud Computing. Again, Scalability and Service Continuity are Not equivalent. There is another a MySQL Improved Extension - MySQLi. There are reasons why NoSQL Movement was started. 1 / 4 The Customize Windows Technology Blog http://thecustomizewindows.com Official website of WebScaleSQL is : http://webscalesql.org/ But, we do not need the official website, but the Github repository : https://github.com/webscalesql/webscalesql-5.6/tree/webscalesql-5.6.16 2 / 4 The Customize Windows Technology Blog http://thecustomizewindows.com Do you know that, PostgreSQL; one of the most popular noSQL database actually can be used instead of MySQL for WordPress? MariaDB is constantly merged with MySQL community edition. Instead of writing vague collected data on WebScaleSQL, let us install WebScaleSQL. WebScaleSQL : Installation In order to test WebScaleSQL, we will need the following dependencies : + cmake + gcc + libaio-dev + libncurses5-dev + libreadline- dev + bison + git + perl I believe, WebScaleSQL is not intended for use on a VirtualBox as a Virtual Appliance. -
Mariadb Company Overview
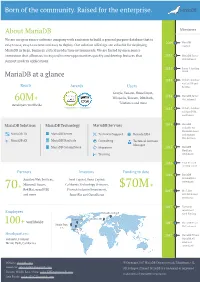
Born of the community. Raised for the enterprise. About MariaDB Milestones We are an open source software company with a mission to build a general purpose database that is 2009 MariaDB easy to use, easy to extend and easy to deploy. Our solution offerings are valuable for deploying created MariaDB in large, business-critical production environments. We are fueled by open source innovation that allows us to respond to new opportunities quickly and develop features that 2012 MariaDB Server 10.0 released support modern applications. 2012 Series A funding round MariaDB at a glance 2013 Default database on CentOS and Reach Awards Users Red Hat Google, Verizon, Home Depot, 2014 MariaDB Server Wikipedia, Tencent, DBS Bank, 60M+ 10.1 released Telefónica and more Developers Worldwide 2015 Default database on OpenSUSE and Fedora MariaDB Solutions MariaDB Technology MariaDB Services 2015 MariaDB available on Microsoft Azure MariaDB TX MariaDB Server Technical Support Remote DBA and Amazon Web Services MariaDB AX MariaDB MaxScale Consulting Technical Account Manager MariaDB ColumnStore Migration 2015 MariaDB MaxScale Training introduced 2016 Final Series B funding round Partners Investors Funding to date 2016 MariaDB Amazon Web Services, Intel Capital, Runa Capital, ColumnStore introduced Microsoft Azure, California Technology Ventures, $70M + 70+ Red Hat, openSUSE Finnish Industry Investment, 2017 M|17, first and more SmartFin and OpenOcean worldwide user conference 2017 European Employees Investment Helsinki, Finland Bank funding Denver, CO London, UK 100+ worldwide 2017 MariaDB Server Menlo Park, 10.2 released CA Austin, TX Headquarters: REACH 2017 MariaDB TX and Helsinki, Finland MariaDB AX Menlo Park, California solutions introduced Website: mariadb.com © Copyright 2017 MariaDB Corporation Ab, Tekniikantie 12, Americas: [email protected] 02150 Espoo, Finland. -

Remote DBA Service for Mysql and Mariadb
Let our team of experts supplement or backfill your team with: Expert care and monitoring Remote DBA Service for MySQL and MariaDB Operationalized best Augment or outsource your database administration and leverage the industry’s practices leading team of DBAs Unique solutions for As application use grows, our expectations for those applications also grow. We want your exact applications to be always up, bug-free, easy-to-use, secure, and high-performance. requirements Applications need data, but database environments can be complicated by unoptimized queries, slow response times, unlocked security, incorrectly installed Percona provides software and improperly configured settings. These problems can lurk in the shadows, Remote DBA services for waiting to hamper queries, strangle interactions and frustrate users with slow applications. clients using: You need the right people to tackle the day-to-day database issues. Are your DBAs: Percona Server® for Crushed by daily maintenance? MySQL Overwhelmed by bad performance? MySQL® by Oracle Baffled by high availability performance? MariaDB® Fighting for backup resources? IaaS and DBaaS Unable to initiate new projects? including: Google Questions like these make planning your operations almost impossible. Cloud® SQL, AWS The Percona Remote DBA service allows your organization to outsource your MySQL® RDS®, EC2®, and DBA needs. Our experienced team of MySQL and MariaDB experts will take care of all Rackspace® Cloud of your organization’s DBA needs on a fixed budget. We hire only highly experienced MySQL professionals with deep knowledge and experience running mission-critical deployments. Your database servers will receive expert care and monitoring at a predictable price that will allow you to rest assured that your database infrastructure . -

Migrate from Oracle to Mariadb Platform
LOWER TCO WITHOUT LOWERING STANDARDS Migrate to MariaDB Platform from Oracle WHITEPAPER TABLE OF CONTENTS 4 TOTAL COST OF OWNERSHIP AND SCALING BENEFITS 4 SAVING MILLIONS WITH MARIADB 5 MARIADB PLATFORM BENEFITS 6 FEATURE PARITY 7 BUILT-IN MIGRATION COMPATIBILITY 8 INFRASTRUCTURE 9 MIGRATION METHODOLOGY 9 ASSESSMENT 10 SCHEMA MIGRATION 10 APPLICATION CODE MIGRATION 11 DATA MIGRATION AND REPLICATION 12 QUALITY ASSURANCE 12 CUTOVER 13 NEXT STEPS 14 APPENDIX A: TCO 17 APPENDIX B: DATA TYPES Lower TCO without Lowering Standards WHITEPAPER LOWER TCO WITHOUT LOWERING STANDARDS: MIGRATE TO MARIADB PLATFORM FROM ORACLE Built on 20+ years of open source engineering and production use, MariaDB Server is an enterprise open source database for transactional workloads, analytical workloads, or both – at scale. MariaDB Server is the foundation of MariaDB Platform – an integrated suite of enterprise-grade products for storing and accessing data. MariaDB Platform is the only open source database with the same enterprise features found in proprietary databases, including Oracle Database compatibility (e.g., PL/SQL compatibility), temporal tables, sharding, point-in-time rollback, and transparent data encryption. And all of this comes at a much lower total cost of ownership (TCO) than Oracle. MariaDB has displaced MySQL in leading Linux distributions, including Red Hat Enterprise Linux (RHEL) and SUSE Linux Enterprise Server (SLES). MariaDB Platform is used on premises, as well as on public and private cloud infrastructure platforms, including OpenStack. It is a trusted, proven, and reliable replacement for proprietary databases. 3 Lower TCO without Lowering Standards WHITEPAPER TOTAL COST OF OWNERSHIP & SCALING BENEFITS MariaDB Platform frees companies from the costs, constraints, and complexity of proprietary databases, enabling them to reinvest in what matters most – rapidly developing innovative, customer-facing applications.