Simultaneous Multiprocessing in a Software-Defined Heterogeneous
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -

Multiprocessing and Scalability
Multiprocessing and Scalability A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Multiprocessing and Scalability Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uni- processor systems. However, due to a number of difficult problems, the potential of these machines has been difficult to realize. This is because of the: Fall 2004 2 Multiprocessing and Scalability Advances in technology ─ Rate of increase in performance of uni-processor, Complexity of multiprocessor system design ─ This drastically effected the cost and implementation cycle. Programmability of multiprocessor system ─ Design complexity of parallel algorithms and parallel programs. Fall 2004 3 Multiprocessing and Scalability Programming a parallel machine is more difficult than a sequential one. In addition, it takes much effort to port an existing sequential program to a parallel machine than to a newly developed sequential machine. Lack of good parallel programming environments and standard parallel languages also has further aggravated this issue. Fall 2004 4 Multiprocessing and Scalability As a result, absolute performance of many early concurrent machines was not significantly better than available or soon- to-be available uni-processors. Fall 2004 5 Multiprocessing and Scalability Recently, there has been an increased interest in large-scale or massively parallel processing systems. This interest stems from many factors, including: Advances in integrated technology. Very -

Design of a Message Passing Interface for Multiprocessing with Atmel Microcontrollers
DESIGN OF A MESSAGE PASSING INTERFACE FOR MULTIPROCESSING WITH ATMEL MICROCONTROLLERS A Design Project Report Presented to the Engineering Division of the Graduate School of Cornell University in Partial Fulfillment of the Requirements of the Degree of Master of Engineering (Electrical) by Kalim Moghul Project Advisor: Dr. Bruce R. Land Degree Date: May 2006 Abstract Master of Electrical Engineering Program Cornell University Design Project Report Project Title: Design of a Message Passing Interface for Multiprocessing with Atmel Microcontrollers Author: Kalim Moghul Abstract: Microcontrollers are versatile integrated circuits typically incorporating a microprocessor, memory, and I/O ports on a single chip. These self-contained units are central to embedded systems design where low-cost, dedicated processors are often preferred over general-purpose processors. Embedded designs may require several microcontrollers, each with a specific task. Efficient communication is central to such systems. The focus of this project is the design of a communication layer and application programming interface for exchanging messages among microcontrollers. In order to demonstrate the library, a small- scale cluster computer is constructed using Atmel ATmega32 microcontrollers as processing nodes and an Atmega16 microcontroller for message routing. The communication library is integrated into aOS, a preemptive multitasking real-time operating system for Atmel microcontrollers. Report Approved by Project Advisor:__________________________________ Date:___________ Executive Summary Microcontrollers are versatile integrated circuits typically incorporating a microprocessor, memory, and I/O ports on a single chip. These self-contained units are central to embedded systems design where low-cost, dedicated processors are often preferred over general-purpose processors. Some embedded designs may incorporate several microcontrollers, each with a specific task. -

Piotr Warczak Quarter: Fall 2011 Student ID: 99XXXXX Credit: 2 Grading: Decimal
CSS 600: Independent Study Contract Final Report Student: Piotr Warczak Quarter: Fall 2011 Student ID: 99XXXXX Credit: 2 Grading: Decimal Independent Study Title The GPU version of the MASS library. Focus and Goals The current version of the MASS library is written in java programming language and combines the power of every computing node on the network by utilizing both multithreading and multiprocessing. The new version will be implemented in C and C++. It will also support multithreading and multiprocessing and finally CUDA parallel computing architecture utilizing both single and multiple devices. This version will harness the power of the GPU a general purpose parallel processor. My specific goals of the past quarter were: • To create a baseline in C language using Wave2D application as an example. • To implement single thread Wave2D • To implement multithreading Wave2D • To implement CUDA enabled Wave2D Work Completed During this quarter I have created Wave2D application in C language using a single thread, multithreaded and CUDA enabled application. The reason for this is that CUDA is an extension of C and thus we need to create baseline against which other versions of the program can be measured. This baseline illustrates how much faster the CUDA enabled program is versus single thread and multithreaded versions. Furthermore, once the GPU version of the MASS library is implemented, we can compare the results to identify if there is any difference in program’s total execution time due to the potential MASS library overhead. And if any major delays in execution are found, the problem ares will be identified and corrected. -

Message Passing Fundamentals
1. Message Passing Fundamentals Message Passing Fundamentals As a programmer, you may find that you need to solve ever larger, more memory intensive problems, or simply solve problems with greater speed than is possible on a serial computer. You can turn to parallel programming and parallel computers to satisfy these needs. Using parallel programming methods on parallel computers gives you access to greater memory and Central Processing Unit (CPU) resources not available on serial computers. Hence, you are able to solve large problems that may not have been possible otherwise, as well as solve problems more quickly. One of the basic methods of programming for parallel computing is the use of message passing libraries. These libraries manage transfer of data between instances of a parallel program running (usually) on multiple processors in a parallel computing architecture. The topics to be discussed in this chapter are The basics of parallel computer architectures. The difference between domain and functional decomposition. The difference between data parallel and message passing models. A brief survey of important parallel programming issues. 1.1. Parallel Architectures Parallel Architectures Parallel computers have two basic architectures: distributed memory and shared memory. Distributed memory parallel computers are essentially a collection of serial computers (nodes) working together to solve a problem. Each node has rapid access to its own local memory and access to the memory of other nodes via some sort of communications network, usually a proprietary high-speed communications network. Data are exchanged between nodes as messages over the network. In a shared memory computer, multiple processor units share access to a global memory space via a high-speed memory bus. -

Composable Multi-Threading and Multi-Processing for Numeric Libraries
18 PROC. OF THE 17th PYTHON IN SCIENCE CONF. (SCIPY 2018) Composable Multi-Threading and Multi-Processing for Numeric Libraries Anton Malakhov‡∗, David Liu‡, Anton Gorshkov‡†, Terry Wilmarth‡ https://youtu.be/HKjM3peINtw F Abstract—Python is popular among scientific communities that value its sim- Scaling parallel programs is challenging. There are two fun- plicity and power, especially as it comes along with numeric libraries such as damental laws which mathematically describe and predict scala- [NumPy], [SciPy], [Dask], and [Numba]. As CPU core counts keep increasing, bility of a program: Amdahl’s Law and Gustafson-Barsis’ Law these modules can make use of many cores via multi-threading for efficient [AGlaws]. According to Amdahl’s Law, speedup is limited by multi-core parallelism. However, threads can interfere with each other leading the serial portion of the work, which effectively puts a limit on to overhead and inefficiency if used together in a single application on machines scalability of parallel processing for a fixed-size job. Python is with a large number of cores. This performance loss can be prevented if all multi-threaded modules are coordinated. This paper continues the work started especially vulnerable to this because it makes the serial part of in [AMala16] by introducing more approaches to coordination for both multi- the same code much slower compared to implementations in other threading and multi-processing cases. In particular, we investigate the use of languages due to its deeply dynamic and interpretative nature. In static settings, limiting the number of simultaneously active [OpenMP] parallel addition, the GIL serializes operations that could be potentially regions, and optional parallelism with Intel® Threading Building Blocks (Intel® executed in parallel, further adding to the serial portion of a [TBB]). -

14. Parallel Computing 14.1 Introduction 14.2 Independent
14. Parallel Computing 14.1 Introduction This chapter describes approaches to problems to which multiple computing agents are applied simultaneously. By "parallel computing", we mean using several computing agents concurrently to achieve a common result. Another term used for this meaning is "concurrency". We will use the terms parallelism and concurrency synonymously in this book, although some authors differentiate them. Some of the issues to be addressed are: What is the role of parallelism in providing clear decomposition of problems into sub-problems? How is parallelism specified in computation? How is parallelism effected in computation? Is parallel processing worth the extra effort? 14.2 Independent Parallelism Undoubtedly the simplest form of parallelism entails computing with totally independent tasks, i.e. there is no need for these tasks to communicate. Imagine that there is a large field to be plowed. It takes a certain amount of time to plow the field with one tractor. If two equal tractors are available, along with equally capable personnel to man them, then the field can be plowed in about half the time. The field can be divided in half initially and each tractor given half the field to plow. One tractor doesn't get into another's way if they are plowing disjoint halves of the field. Thus they don't need to communicate. Note however that there is some initial overhead that was not present with the one-tractor model, namely the need to divide the field. This takes some measurements and might not be that trivial. In fact, if the field is relatively small, the time to do the divisions might be more than the time saved by the second tractor. -

Efficient Parallel Approaches to Financial Derivatives and Rapid Stochastic Convergence
Utah State University DigitalCommons@USU All Graduate Plan B and other Reports Graduate Studies 5-2015 Efficient Parallel Approaches to Financial Derivatives and Rapid Stochastic Convergence Mario Harper Utah State University Follow this and additional works at: https://digitalcommons.usu.edu/gradreports Part of the Business Commons Recommended Citation Harper, Mario, "Efficient Parallel Approaches to Financial Derivatives and Rapid Stochastic Convergence" (2015). All Graduate Plan B and other Reports. 519. https://digitalcommons.usu.edu/gradreports/519 This Thesis is brought to you for free and open access by the Graduate Studies at DigitalCommons@USU. It has been accepted for inclusion in All Graduate Plan B and other Reports by an authorized administrator of DigitalCommons@USU. For more information, please contact [email protected]. EFFICIENT PARALLEL APPROACHES TO FINANCIAL DERIVATIVES AND RAPID STOCHASTIC CONVERGENCE by Mario Y. Harper A thesis submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in Financial Economics Approved: Dr. Tyler Brough Dr. Jason Smith Major Professor Committee Member Dr. Jared DeLisle Dr. Richard Inouye Committee Member Associate Dean of the School of Gradu- ate Studies UTAH STATE UNIVERSITY Logan, Utah 2015 ii Copyright c Mario Y. Harper 2015 All Rights Reserved iii Abstract Efficient Parallel Approaches to Financial Derivatives and Rapid Stochastic Convergence by Mario Y. Harper, Master of Science Utah State University, 2015 Major Professor: Dr. Tyler Brough Department: Economics and Finance This Thesis explores the use of different programming paradigms, platforms and lan- guages to maximize the speed of convergence in Financial Derivatives Models. The study focuses on the strengths and drawbacks of various libraries and their associated languages as well as the difficulty of porting code into massively parallel processes. -

Parallel Processing with Eight-Node Raspberry Pi Cluster
INTRODUCTION TO PARALLEL PROCESSING WITH EIGHT NODE RASPBERRY PI CLUSTER Greg Dorr, Drew Hagen, Bob Laskowski, Dr. Erik Steinmetz and Don Vo Department of Computer Science Augsburg College 707 21st Ave S, Minneapolis, MN 55454 [email protected], [email protected], [email protected], [email protected], [email protected] Abstract We built an eight node Raspberry Pi cluster computer which uses a distributed memory architecture. The primary goal of this paper is to demonstrate Raspberry Pis have the potential to be a cost effective educational tool to teach students about parallel processing. With the cluster we built, we ran experiments using the Message Passing Interface (MPI) standard as well as multiprocessing implemented in Python. Our experiments revolve around how efficiency in computing increases or decreases with different parallel processing techniques. We tested this by implementing a Monte Carlo calculation of Pi. We ran the experiments with eight nodes and one through four processes per node. For a comparison, we also ran the computations on a desktop computer. Our primary goal is to demonstrate how Raspberry Pis are an effective, yet comparatively cheap solution for learning about parallel processing. 1. Introduction We became interested in parallel processing when our Association of Computing Machinery chapter toured the Minnesota Supercomputing Institute at the University of Minnesota. Walking through the rows of server racks filled with massive computing power and hearing about how the computers were working on problems such as predicting weather patterns and fluid mechanics fascinated us. This led us to exploring ways we could learn about parallel processing on a smaller and cheaper scale. -

Introduction to Multithreading, Superthreading and Hyperthreading Introduction
Introduction to Multithreading, Superthreading and Hyperthreading Introduction Back in the dual-Celeron days, when symmetric multiprocessing (SMP) first became cheap enough to come within reach of the average PC user, many hardware enthusiasts eager to get in on the SMP craze were asking what exactly (besides winning them the admiration and envy of their peers) a dual-processing rig could do for them. It was in this context that the PC crowd started seriously talking about the advantages of multithreading. Years later when Apple brought dual-processing to its PowerMac line, SMP was officially mainstream, and with it multithreading became a concern for the mainstream user as the ensuing round of benchmarks brought out the fact you really needed multithreaded applications to get the full benefits of two processors. Even though the PC enthusiast SMP craze has long since died down and, in an odd twist of fate, Mac users are now many times more likely to be sporting an SMP rig than their x86- using peers, multithreading is once again about to increase in importance for PC users. Intel's next major IA-32 processor release, codenamed Prescott, will include a feature called simultaneous multithreading (SMT), also known as hyper-threading . To take full advantage of SMT, applications will need to be multithreaded; and just like with SMP, the higher the degree of multithreading the more performance an application can wring out of Prescott's hardware. Intel actually already uses SMT in a shipping design: the Pentium 4 Xeon. Near the end of this article we'll take a look at the way the Xeon implements hyper-threading; this analysis should give us a pretty good idea of what's in store for Prescott. -
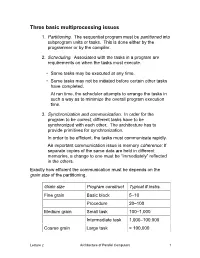
Three Basic Multiprocessing Issues
Three basic multiprocessing issues 1. Partitioning. The sequential program must be partitioned into subprogram units or tasks. This is done either by the programmer or by the compiler. 2. Scheduling. Associated with the tasks in a program are requirements on when the tasks must execute. • Some tasks may be executed at any time. • Some tasks may not be initiated before certain other tasks have completed. At run time, the scheduler attempts to arrange the tasks in such a way as to minimize the overall program execution time. 3. Synchronization and communication. In order for the program to be correct, different tasks have to be synchronized with each other. The architecture has to provide primitives for synchronization. In order to be efficient, the tasks must communicate rapidly. An important communication issue is memory coherence: If separate copies of the same data are held in different memories, a change to one must be “immediately” reflected in the others. Exactly how efficient the communication must be depends on the grain size of the partitioning. Grain size Program construct Typical # instrs. Fine grain Basic block 5–10 Procedure 20–100 Medium grain Small task 100–1,000 Intermediate task 1,000–100,000 Coarse grain Large task > 100,000 Lecture 2 Architecture of Parallel Computers 1 A parallel program runs most efficiently if the grain size is neither too large nor too small. What are some disadvantages of having a too-large grain size? • • What would be some disadvantages of making the grain size too small? • • The highest speedup is achieved with grain size somewhere in between. -

Helios: Heterogeneous Multiprocessing with Satellite Kernels
Helios: Heterogeneous Multiprocessing with Satellite Kernels † Edmund B. Nightingale Orion Hodson Ross McIlroy Microsoft Research Microsoft Research University of Glasgow, UK Chris Hawblitzel Galen Hunt Microsoft Research Microsoft Research ABSTRACT 1. INTRODUCTION Helios is an operating system designed to simplify the task of writ- Operating systems are designed for homogeneous hardware ar- ing, deploying, and tuning applications for heterogeneous platforms. chitectures. Within a machine, CPUs are treated as interchange- Helios introduces satellite kernels, which export a single, uniform able parts. Each CPU is assumed to provide equivalent functional- set of OS abstractions across CPUs of disparate architectures and ity, instruction throughput, and cache-coherent access to memory. performance characteristics. Access to I/O services such as file At most, an operating system must contend with a cache-coherent systems are made transparent via remote message passing, which non-uniform memory architecture (NUMA), which results in vary- extends a standard microkernel message-passing abstraction to a ing access times to different portions of main memory. satellite kernel infrastructure. Helios retargets applications to avail- However, computing environments are no longer homogeneous. able ISAs by compiling from an intermediate language. To simplify Programmable devices, such as GPUs and NICs, fragment the tra- deploying and tuning application performance, Helios exposes an ditional model of computing by introducing “islands of computa- affinity metric to developers. Affinity provides a hint to the operat- tion” where developers can run arbitrary code to take advantage of ing system about whether a process would benefit from executing device-specific features. For example, GPUs often provide high- on the same platform as a service it depends upon.