Penalized Splines - Estimation with Longitudinal Unemployment Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Testing the Significance of Calendar Effects
A Service of Leibniz-Informationszentrum econstor Wirtschaft Leibniz Information Centre Make Your Publications Visible. zbw for Economics Hansen, Peter Reinhard; Lunde, Asger; Nason, James M. Working Paper Testing the significance of calendar effects Working Paper, No. 2005-02 Provided in Cooperation with: Federal Reserve Bank of Atlanta Suggested Citation: Hansen, Peter Reinhard; Lunde, Asger; Nason, James M. (2005) : Testing the significance of calendar effects, Working Paper, No. 2005-02, Federal Reserve Bank of Atlanta, Atlanta, GA This Version is available at: http://hdl.handle.net/10419/100920 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Documents in EconStor may be saved and copied for your Zwecken und zum Privatgebrauch gespeichert und kopiert werden. personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle You are not to copy documents for public or commercial Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich purposes, to exhibit the documents publicly, to make them machen, vertreiben oder anderweitig nutzen. publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur Verfügung gestellt haben sollten, If the documents have been made available under an Open gelten abweichend von diesen Nutzungsbedingungen die in der dort Content Licence (especially Creative Commons Licences), you genannten Lizenz gewährten Nutzungsrechte. may exercise further usage rights as specified in the indicated licence. www.econstor.eu ATLANTA Testing the Significance of Calendar Effects f o Peter Reinhard Hansen, Asger Lunde, and James M. Nason Working Paper 2005-2 January 2005 FEDERAL RESERVE BANK WORKING PAPER SERIES FEDERAL RESERVE BANK of ATLANTA WORKING PAPER SERIES Testing the Significance of Calendar Effects Peter Reinhard Hansen, Asger Lunde, and James M. -

Adaptive Estimation of Daily Demands with Complex Calendar Effects For
Transportation Research Part B 34 (2000) 451±469 www.elsevier.com/locate/trb Adaptive estimation of daily demands with complex calendar eects for freight transportation Gregory A. Godfrey *, Warren B. Powell Department of Financial Engineering and Operations Research, School of Engineering/Appl. Science, Princeton University, Princeton, NJ 08544, USA Received 4 September 1997; received in revised form 7 May 1999; accepted 18 May 1999 Abstract We address the problem of forecasting spatial activities on a daily basis that are subject to the types of multiple, complex calendar eects that arise in many applications. Our problem is motivated by applica- tions where we generally need to produce thousands, and frequently tens of thousands, of models, as arises in the prediction of daily origin±destination freight ¯ows. Exponential smoothing-based models are the simplest to implement, but standard methods can handle only simple seasonal patterns. We propose a class of exponential smoothing-based methods that handle multiple calendar eects. These methods are much easier to implement and apply than more sophisticated ARIMA-based methods. We show that our tech- niques actually outperform ARIMA-based methods in terms of forecast error, indicating that our sim- plicity does not involve any loss in accuracy. Ó 2000 Elsevier Science Ltd. All rights reserved. Keywords: Forecasting; Time series; Freight demand; Exponential smoothing 1. Introduction We address the problem of forecasting daily demands that arise in large freight transportation applications at a fairly high level of detail. Our most speci®c issue is the need for daily forecasts of freight demand, generally extended for one or two weeks into the future. -

Adjusting for a Calendar Effect in Employment Time Series
ADJUSTING FOR A CALENDAR EFFECT IN EMPLOYMENT TIME SERIES Stephanie Cano, Patricia Getz, Jurgen Kropf, Stuart Scott and George Stamas, Bureau of Labor Statistics George Stamas, BLS, 2 Massachusetts Ave. NE, Room 4985, Washington, DC 20212 Key Words: Regression, Seasonal Adjustment gain for the current month often exceeded the expectation, thus exaggerating the strength of job growth. In the second case, again for a month in 1. INTRODUCTION which seasonal growth typically occurs, the seasonal expectation was too high and the resultant employment The Current Employment Statistics (CES) program series risked presenting a weaker employment picture is a survey of nearly 400,000 business establishments than genuinely existed. A recent example of this latter nationwide, which provides monthly estimates of situation occurred with April 1995: There were 4 nonfarm payroll jobs and the hours and earnings of weeks between the March and April surveys in 1995, workers. The month-to-month movements in these while each of the three preceding years had 5-week series are closely followed by policy makers and intervals. When the April 1995 survey registered a forecasters as timely indicators of the overall strength very weak employment gain, concerns were raised as to and direction of the nation's economy. Over-the-month whether this calendar effect had significantly changes in CES series are nearly always analyzed on a dampened the published over-the-month change. seasonally adjusted basis, but historically a calendar- Recent availability of X-12-ARIMA seasonal related limitation in the CES seasonal adjustment adjustment software developed by the Bureau of the process complicated the interpretation of month-to- Census enabled the Bureau of Labor Statistics (BLS) to month movements in the series. -

Calendar Anomalies: an Empirical Study on the Day of the Week Effect in Indian Banking Sector
International Journal of Business and Management Invention ISSN (Online): 2319 – 8028, ISSN (Print): 2319 – 801X www.ijbmi.org || Volume 6 Issue 7 || July. 2017 || PP—49-59 Calendar Anomalies: an empirical study on the Day of the Week Effect in Indian Banking Sector Harman Arora1, Dr.Parminder Bajaj 2 1Student-CFA Institute 2Associate Professor, JIMS, Rohini (Sec-5) Abstract: Calendar Anomalies have long been part of market folklore. ‘Studies of the day-of-the-week, holiday and January effects first began to appear in the 1930. And although academics have only recently begun seriously to examine these return patterns, they have found them to withstand close scrutiny. Calendar regularities generally occur at cusps in time—the turn of the year, the month, the week, the day. They often have significant economic impact. For instance, the "Blue 12 Monday” effect was so strong during the Great Depression that the entire market crash took place over weekends, from Saturday's close to Monday's close. The stock market actually rose on average every other day of the week. Calendar anomalies are often related to other return effects. For instance, some calendar anomalies are more potent for small than for large capitalization stocks. While analysis of cross-sectional effects requires fundamental databases—a relatively recent innovation—the study of calendar anomalies requires only time-dated records of market indexes. Hence calendar anomalies can be tracked historically for much longer periods than effects requiring fundamental data. The availability of a century of data brings enormous statistical power for testing calendar effects, but it also increases the likelihood of data-mining. -

WORKING PAPER 168/2018 Calendar Anomaly and the Degree
MSE Working Papers Recent Issues WORKING PAPER 168/2018 * Working Paper 159/2017 Export Performance, Innovation, And Productivity In Indian Manufacturing Firms Santosh K. Sahu, Sunder Ramaswamy and Abishek Choutagunta * Working Paper 160/2017 An Alternative Argument of Green Solow Model in Developing Economy Context Santosh K. Sahu and Arjun Shatrunjay Calendar Anomaly and the Degree of * Working Paper 161/2017 Market Inefficiency of Bitcoin Technical Efficiency of Agricultural Production in India: Evidence from REDS Survey Santosh K. Sahu and Arjun Shatrunjay * Working Paper 162/2017 Does Weather Sensitivity of Rice Yield Vary Across Regions? Evidence from Eastern and Southern India Anubhab Pattanayak and K. S. Kavi Kumar * Working Paper 163/2017 Cost of Land Degradation in India S. Raja Sethu Durai P. Dayakar Sunil Paul * Working Paper 164/2017 Microfinance and Women Empowerment- Empirical Evidence from the Indian States Saravanan and Devi Prasad DASH * Working Paper 165/2017 Financial Inclusion, Information and Communication Technology Diffusion and Economic Growth: A Panel Data Analysis Amrita Chatterjee and Nitigya Anand * Working Paper 166/2017 Task Force on Improving Employment Data - A Critique T.N. Srinivasan * Working Paper 167/2017 Predictors of Age-Specific Childhood Mortality in India G. Naline, Brinda Viswanathan MADRAS SCHOOL OF ECONOMICS * Working papers are downloadable from MSE website http://www.mse.ac.in Gandhi Mandapam Road $ Restricted circulation Chennai 600 025 India April 2018 Calendar Anomaly and the Degree of Market Inefficiency of Bitcoin S. Raja Sethu Durai Associate Professor School of Economics, University of Hyderabad, Hyderabad-500046, India [email protected] and Sunil Paul Assistant Professor, Madras School of Economics [email protected] i WORKING PAPER 168/2018 MADRAS SCHOOL OF ECONOMICS Gandhi Mandapam Road Chennai 600 025 India April 2018 Phone: 2230 0304/2230 0307/2235 2157 Fax : 2235 4847/2235 2155 Email : [email protected] Price : Rs. -

Calendar Effects in the Portuguese Mutual Funds Market
Calendar Effects In The Portuguese Mutual Funds Market Márcio Daniel Pereira Barros [email protected] Dissertation Master in Finance Supervisor: Prof. Doutor Júlio Fernando Seara Sequeira da Mota Lobão September 2015 BIOGRAPHIC NOTE Márcio Daniel Pereira Barros, born on the 20th of December 1992, in Valença, Viana do Castelo. In 2010, he enrolled in a Bachelor in Economics in FEP – School of Economics and Management, from which he graduated in 2013. During the same year, he entered in the Master in Finance in the same institution, having concluded the curricular year with an average grade of 15. In the course of his academic years, Márcio was also member and part of the Executive Board of AIESEC in FEP. In 2015, Márcio joined IBM International Services Centre, in Slovakia, where he currently has the position of Financial Analyst. i ACKNOWLEDGEMENTS Firstly and most importantly, I want to thank Professor Julio Lobão, for his support since the beginning; this work would not be possible without him. I am deeply grateful for his patience, guidance, share of knowledge and constructive feedback. I also thank all my family for their total support and concern, especially from my parents. Last but not least, I would like to highlight all the motivation and help provided by my closest friends, who directly or indirectly have contributed to the accomplishment of this goal. ii ABSTRACT: There is a wide range of studies regarding the calendar effects, however very few of those studies are applied to the mutual funds’ performance. This study aims to search the existence of calendar effects (also known as calendar anomalies) in the Portuguese Mutual Funds Market. -

Calendar Effects: Empirical Evidence from the Vietnam Stock Markets
International Journal of Advanced and Applied Sciences, 7(12) 2020, Pages: 48-55 Contents lists available at Science-Gate International Journal of Advanced and Applied Sciences Journal homepage: http://www.science-gate.com/IJAAS.html Calendar effects: Empirical evidence from the Vietnam stock markets Bui Huy Nhuong 1, Pham Dan Khanh 2, *, Pham Thanh Dat 3 1Personnel Department, National Economics University, Hanoi, Vietnam 2School of Advanced Education Program, National Economics University, Hanoi, Vietnam 3School of Banking and Finance, National Economics University, Hanoi, Vietnam ARTICLE INFO ABSTRACT Article history: The Efficient Market Hypothesis (EMH) deals with informational efficiency Received 7 May 2020 and strongly based on the idea that the stock market prices or returns are Received in revised form unpredictable and do not follows any regular pattern, so it is impossible to 21 July 2020 “beat the market.” According to the EMH theory, security prices immediately Accepted 29 July 2020 and fully reflect all available relevant information. EMH also establishes a foundation of modern investment theory that essentially advocates the Keywords: futility of information in the generation of abnormal returns in capital Calendar effects markets over a period. However, the existence of anomalies challenges the EMH notion of efficiency in stock markets. Calendar effects break the weak form of Dummy variable regression efficiency, highlighting the role of past patterns and seasonality in estimating Day-of-the-week effect future prices. The present research aims to study the efficiency in Vietnam Month-of-the-year effect stock markets. Using daily and monthly returns of VnIndex data from its inception in March 2002 to December 2018, we employ dummy variable multiple linear regression techniques to assess the existence of calendar effects in Vietnam stock markets. -

CURRENT CONTENTS BULLETIN State Bank of Pakistan, Library VOLUME NO: 09 ISSUE NO: 02
CURRENT CONTENTS BULLETIN State Bank of Pakistan, Library VOLUME NO: 09 ISSUE NO: 02 February 2019 CONTENTS Foreign Journals/Magazines American Economic Journal Applied Economics------------------------------ Print + Online 1 American Economic Journal Macroeconomic--------------------------------- Print + Online 2 American Economic Review ------------------------------------------------------- Print + Online 3 American Statistician---------------------------------------------------------------- Print + Online 4 Asian Banker Journal---------------------------------------------------------------- Print + Online 5 Cambridge Journal of Economics------------------------------------------------- Print Only 6 Canadian Journal of Economics--------------------------------------------------- Print + Online 7 Cyber Security A Peer - Reviewed Journal------------------------------------- Print Only 8 Developing Economies-------------------------------------------------------------- Print + Online 9 Economic and Political Weekly---------------------------------------------------- Print Only 10 European Journal of Management and Business Economics-------------- Online Only 11 Human Resource Development International--------------------------------- Online Only 12 I.M.F Finance and Development-------------------------------------------------- Print Only 13 International journal of Middle East Studies---------------------------------- Print + Online 14 Journal of Banking & Finance------------------------------------------------------ Online Only 15 Journal -

Efficient Market Hypothesis and Calendar Effects: Evidence from the Oslo Stock Exchange
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by NORA - Norwegian Open Research Archives Efficient Market Hypothesis and Calendar Effects: Evidence from the Oslo Stock Exchange Evgenia Yavrumyan Master of Philosophy in Economics Department of Economics University of Oslo May 2015 II Efficient Market Hypothesis and Calendar Effects: Evidence from the Oslo Stock Exchange III © Evgenia Yavrumyan 2015 Efficient Market Hypothesis and Calendar Effects: Evidence from the Oslo Stock Exchange Evgenia Yavrumyan http://www.duo.uio.no/ Trykk: Reprosentralen, Universitetet i Oslo IV Summary Stock market efficiency is an essential property of the market. It implies that rational, profit-maximazing investors are not able to consistently outperform the market since prices of stocks in the market are fair, that is, there are no undervalued stocks in the market. Market efficiency is divided into three forms: weak, semi-strong and strong. Weak form of market efficiency implies that technical analysis, utilizing historical data, cannot be used to predict future price movements, since all the historical information is impounded into the stock prices and price changes are random. Semi-strong form of market efficiency states that fundamental analysis does not create opportunity to earn abnormal returns, since all publicly available information is reflected in the stock prices. In market efficiency in its strong form, the price on stock reflects all the relevant information and knowledge of insider information will not create opportunity to earn abnormal returns. In practice, to have a perfectly efficient market is almost impossible. Investors do not always behave rationally, stocks can be priced «wrongly» due to presence of anomaly in price formation process or there can emerge a predictable pattern in stock price changes. -

Department of Economics Issn 1441-5429 Discussion
DEPARTMENT OF ECONOMICS ISSN 1441-5429 DISCUSSION PAPER 16/05 REVISITING CALENDAR ANOMALIES IN ASIAN STOCK MARKETS USING A STOCHASTIC DOMINANCE APPROACH * † ‡ Lean Hooi Hooi , Wong Wing Keung and Russell Smyth ABSTRACT Extensive evidence on the prevalence of calendar effects suggests that there exists abnormal returns, but some recent studies have concluded that calendar effects have largely disappeared. In spite of the non-normal nature of stock returns, most previous studies have employed the mean- variance criterion or CAPM statistics, which rely on the normality assumption and depend only on the first two moments, to test for calendar effects. A limitation of these approaches is that they miss much important information contained in the data such as higher moments. In this paper, we use the Davidson and Duclos (2000) test, which is a powerful non-parametric stochastic dominance (SD) test, to test for the existence of day-of-the-week and January effects for several Asian markets using daily data for the period from 1988 to 2002. Our empirical results support the existence of weekday and monthly seasonality effects in some Asian markets but suggest that first order SD for the January effect has largely disappeared. KEYWORDS: Stochastic dominance, Calendar anomalies, Asian markets. JEL CODES: C14, G12, G15 * Department of Economics, Monash University. † Department of Economics, National University of Singapore. ‡ Department of Economics, Monash University. 1 REVISITING CALENDAR ANOMALIES IN ASIAN STOCK MARKETS USING A STOCHASTIC DOMINANCE APPROACH I. INTRODUCTION Extensive evidence of the day-of-the-week and January effects has been found for both the United States (US) and international stock markets (see Pettengill, 2003 for a review of the day-of-the- week effect literature). -

A Review on the Evolution of Calendar Anomalies
Studies in Business and Economics no. 12(1)/2017 DOI 10.1515/sbe-2017-0008 A REVIEW ON THE EVOLUTION OF CALENDAR ANOMALIES KUMAR Satish IBS Hyderabad (ICFAI Foundation for Higher Education), India Abstract: In this article, we provide a detailed review on the behavior of calendar anomalies (day– of–the–week, January and turn–of–month in particular) to understand their evolution over time. The research in the area of stock market indicates negative returns on Monday and positive returns on Friday; however, in the currency markets, results are opposite, that is, the returns on Monday are positive and higher than the returns on Friday which show negative returns. For the January (TOM) effect, the literature suggest that the returns during January (TOM trading days) are higher (lower) than the returns during rest of the year (non–TOM trading days). Further, these calendar anomalies were stronger during the 1980s and 1990s and have gradually diminished in the recent times which indicate that the markets have achieved a higher degree of efficiency. Key words: Calendar anomalies; Day–of–the–week; January; Turn–of–month 1. Introduction Several studies have documented the presence of various calendar anomalies which violates the well–known theories of asset–pricing models. For example, holiday effect (Ariel, 1990; Liano and White, 1994; Vergin and McGinnis, 1999), monthly or January effect (Kim and Park, 1994; Haug and Hirschey, 2006; Rendon and Ziemba, 2007; and Agnani and Aray, 2011; Kumar, 2016a,b), week–end effect (Lakonishok and Levi, 1982; Jaffe and Westerfield, 1985; Kohli and Kohers, 1992), turn–of–month effect (Ogden, 1990; Compton, Johnson and Kunkel, 2006; Kumar, 2015), day–of–the– week effect (Chang and Kim, 1988; Dubois and Louvet, 1996; Tonchev and Kim, 2004; Keef and Roush, 2005; Ariss, Rezvanian and Mehdian, 2011; Berument and Dogan, 2012; Kumar and Pathak, 2016), and week–of–the–year effect (Levy and Yagil, 2012). -
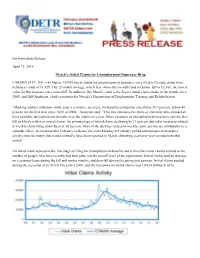
For Immediate Release April 12, 2016 March's Initial Claims For
For Immediate Release April 12, 2016 March’s Initial Claims for Unemployment Insurance Drop CARSON CITY, NV —In March, 10,924 initial claims for unemployment insurance were filed in Nevada, down from February’s total of 11,429. The 12-month average, which best shows the overall trend in claims, fell to 12,343, the lowest value for this measure since mid-2007. In addition, this March’s total is the fewest initial claims made in the month since 2005, said Bill Anderson, chief economist for Nevada’s Department of Employment, Training and Rehabilitation. “Marking another milestone in the state’s economic recovery, the benefits exhaustion rate slid to 39.7 percent, below 40 percent for the first time since April of 2008,” Anderson said. “This rate estimates the share of claimants who exhaust all their available unemployment benefits over the course of a year. Other measures of unemployment insurance activity also fell in March with new initial claims, the primary type of initial claim, declining by 11 percent and other measures related to weekly claim filing down by over 20 percent. Most of the declines related to weekly claim activity are attributable to a calendar effect. As mentioned in February’s release, the extra Monday in February pulled unemployment insurance activity into the month that would normally have been reported in March, distorting year-over-year comparisons this month.” An initial claim represents the first stage of filing for unemployment benefits and is therefore most closely related to the number of people who have recently lost their jobs, not the overall level of unemployment.