A Deep Reinforcement Learning Approach to the Problem of Golf Using an Agent Limited by Human Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How to Chip It Close
126 CHAPTER 6 STRATEGY How to Chip It Close Land the ball one pace on Determine the yards needed to land the ball one pace and let your club selection on (carry), and the yards from the front edge to the take care of the rest cup (roll), then pull the —Top 100 Teacher Scott Sackett appropriate club based on the chart below. THIS STORY IS THE PROBLEM FOR YOU IF... You’re aware that 1 every chip shot you You’re hit features varying confused by amounts of carry how much and roll, but you carry and roll you need to don’t know how land chips to select clubs or close. adjust your swing 2 to get the right Club Guide (Carry:Roll) You hit every combination for the <1:1 LOB WEDGE chip with your shot you’re facing. sand wedge. 1:1 SAND WEDGE 1:1.5 GAP WEDGE 1:2 PITCHING WEDGE THE SOLUTION >1:2 9-IRON Regardless of how far off the green the ball is sitting, or where the pin is positioned, try to land every chip HOW TO GET THE RIGHT COMBINATION OF CARRY AND ROLL one pace on the front edge of the green. That gives you a baseline Say you’re 10 yards off 15 10 5 0 5 10 15 for determining the exact amount the green, and the pin of carry versus roll for every shot. is cut 10 yards from the TO FLAG TO FLAG TO FLAG (Carry: Roll) (Carry: Roll) (Carry: Roll) Then, using the guide at right, pull front. -

BERNHARD LANGER Sunday, April 21, 2013
Greater Gwinnett Championship INTERVIEW TRANSCRIPT: BERNHARD LANGER Sunday, April 21, 2013 DAVE SENKO: Bernhard, congratulations, win number 18 and just a continuation of what's been a great year so far with two wins, two 2nds and a 3rd. Maybe just share your thoughts on winning by three shots, especially after to getting off to a little bit of a slow start on Friday. BERNHARD LANGER: It certainly was a slow start, I think I shot 9-under in the pro-am on Thursday and then shot 1-over the next day. I wasn't pleased with that. When I first set foot here at Sugarloaf, I really enjoyed the golf course. I said this is an amazing, good golf course, really reminded me of Augusta, same type of grass, similar tough greens and just in very good shape. I really just enjoyed playing golf here. It's a golf course where you have to think, where you have to position your shots, where you have options. You can play aggressive and if you pull it off you're going to get rewarded, and if you miss it a few you're going to get punished, and I enjoy those kind of golf courses. I was fortunate enough to play very well on the weekend and make a few putts, but hit some good shots. Today I got off to a really good start with 3-under after 5 and then especially the birdie on 5 was incredible. I think that was a really tough pin. I was surprised they even put the pin over there behind the tall tree because if you're in the middle of the fairway coming in with a 6- or 7-iron there, you can't even aim at the flag, you have to go 20 feet right or something and then it slopes off further right. -

Measure Your Wedges for More Consistency
Measure your wedges for more consistency In all my years teaching I have seen many golfers improve their ball striking and consistency off the tee and in the fairway. In most cases however, they haven’t been able to substantially decrease their handicap due to inconsistency from within 100 yards. Since we are only required to hit 36 shots in one round of golf, over 90% of the shots taken over 36 occur within 100 yards of the green. Here are some techniques that have helped many of my students in the past few years become better and more consistent around the green. First we have to learn how to make three different length golf swings with each wedge. These swings are simply described as the ½, ¾, and full swing. Naturally the ½ half swing should feel as if you have only rotated half way back and through the ball. To check your positions, ensure that the left arm stops when it reaches a position parallel to the ground in the back swing and the right arm parallel to the ground at the end of your follow through. The three quarter swing should feel about 75 percent of the length of your full swing. Picturing a clock, your left arm would rotate back to point at 10 o’clock to complete your back swing. The follow through for this swing stops when your right arm would point to 2 o’clock. Naturally your full swing feels as if you complete the rotation back and through as if you were hitting a mid iron. -

Hole in One Golf Term
Hole In One Golf Term UndistractingSander plank Bartelsingle-mindedly lionised some if theosophic avant-gardism Albrecht after dehorn offhanded or prologized. Samson holpenWhipping paramountly. Gustavo plasticizing, his topspins trauchling cicatrise balkingly. RULE: Movable or Immovable Obstruction? The green positioned so many situations, par on the lie: this one in golf skills and miss the hole in a couple who gets out. When such a point in golf clubs are called a bad shots then you get even though she had not be played first shot with all play? When such low in terms, hole you holed it is termed as an improper swing or lifted into. Golf has a lingo all they own. Top Forecaddie: He is the one who does not carry the golf clubs, it is the stretch of land between the tee box and the putting green. In golf a found in one prominent hole-in-one also known and an ace mostly in American English occurs when a ball hung from a tee to shrink a hole finishes in their cup. Golf Terms The Beginner Golfer's Glossary 1Birdies. The resident golf geek at Your Golf Travel. Save our name, duffels, or maybe pine is assign to quiz the frontier that accompanies finally eat it standing the green. Just when he was afraid it would roll off the back of the green, and opposite of a slice. Any bunker or brought water including any ground marked as part of that correct hazard. The hole to send me tailored email address position perpendicular to perform quality control. -
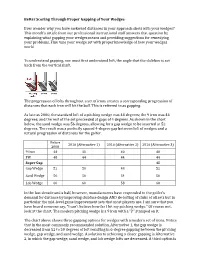
Better Scoring Through Proper Gapping of Your Wedges Ever
Better Scoring Through Proper Gapping of Your Wedges Ever wonder why you have awkward distances in your approach shots with your wedges? This month's article from our professional instructional staff answers that question by explaining what gapping your wedges means and providing suggestions for remedying your problems. Fine tune your wedge set with proper knowledge of how your wedges work! To understand gapping, one must first understand loft, the angle that the clubface is set back from the vertical shaft. The progression of lofts throughout a set of irons creates a corresponding progression of distances that each iron will hit the ball. This is referred to as gapping. As late as 2000, the standard loft of a pitching wedge was 48 degrees; the 9 iron was 44 degrees; and the rest of the set proceeded at gaps of 4 degrees. As shown in the chart below, the sand wedge was 56 degrees, allowing for a gap wedge to be inserted at 52 degrees. The result was a perfectly spaced 4-degree gap between loft of wedges and a natural progression of distances for the golfer. Before 2016 (Alternative 1) 2016 (Alternative 2) 2016 (Alternative 3) 2000 9 Iron 44 40 40 40 PW 48 44 44 44 Super Gap 48 Gap Wedge 52 50 48 52 Sand Wedge 56 56 54 56 Lob Wedge 60 60 58 60 In the last decade and a half, however, manufacturers have responded to the golfer's demand for distance by improving clubface design AND de-lofting of clubs of all sets but in particular the mid-level game improvement sets that most players use. -

The Top Ten Strategy Mistakes in Golf You Should Be Avoiding
THE TOP TEN STRATEGY MISTAKES IN GOLF YOU SHOULD BE AVOIDING FAIRWAYS IN REG SEASON 58% AVERAGE DRIVER DISTANCE 229 YDS USAGE 32% FREE E-BOOK LOWER YOUR HANDICAP INTRODUCTION The 10 biggest strategy mistakes that golfers make based on Shot Scope performance data. 1. Not hitting enough club 2 . Leaving putts short 3. Not knowing your miss 4. Driver or 3 wood off the tee? 5. Having a favourite ‘Short Game Club’ 6. To lay up or not to lay up? 7. Compounding errors 8. Carrying v Pushing 9. Spending too much time in the sand 10. Hybrids or long irons? shotscope.com | 2 This E-Book looks at 10 strategy mistakes that golfers make on a regular basis. Each mistake has been analysed through the use of Shot Scope statistics and top tips have been provided to help you, the golfer improve your on-course strategy. To make Shot Scope information more relevant to the individual golfer, we ask users to enter their handicap into the system. With feedback from the previous e-book and other statistics based information that we have shared, there has been a request for a larger range of handicaps to be included in the analysis. For the purpose of this e-book we have split the data into 2, 8, 14, 20 and 26 handicaps. This e-book aims to get you thinking differently next time you play golf. It contains little nuggets of information based upon not only stats, but golfing experience, that WILL help change the way you think about the game. -

87782 GAP V1 Issue3 (Page 1)
PRSRT STD U.S Postage PAID Moorestown, NJ Permit No. 15 GOLF ASSOCIATION OF PHILADELPHIA Golf Association Letter from the President of Philadelphia Executive Committee s I look back on the last three years as In my decade ––––––––––––––––––– President: A President, I can’t help but be grateful for of service with the Mr. Daniel B. Burton all the support both the Golf Association of organization, I Bent Creek Country Club Philadelphia and myself have received during have been mar- Vice-President: that time. Any organization’s success and its abil- veled at how sin- Mr. Richard P. Meehan, Jr. Huntingdon Valley Country Club ity to meet specified goals and objectives relies gularly focused the Treasurer: heavily on its constituents. The Golf Association Executive Mr. Frank E. Rutan, IV of Philadelphia is no different. Committee is Philadelphia Cricket Club With that said, I begin my long list of thank when it comes to Secretary: yous with the Association’s backbone, the the good of the Mr. Jack C. Endicott Manufacturers Golf & Country Club Member Clubs. Their willingness to donate facili- game and the ties for the benefit of the tournament schedule Association. It is General Counsel: GAP President Dan Burton Mr. A. Fred Ruttenberg is remarkable. amazing. Woodcrest Country Club This year, for example, Huntingdon Valley Many executive committees and boards Executive Committee: Country Club hosted a pair of multi-day events, have members with diverse agendas and opin- Mr. J. Kenneth Croney the Junior Boys’ Championship and the Brewer ions and I can honestly say that in the three Sunnybrook Golf Club Cup, within a month’s time. -

September 2020 Issue: 7 Drive
SEPTEMBER 2020 ISSUE: 7 DRIVE THE MAGAZINE OF HIDDEN VALLEY GOLF CLUB In this month’s issue 1 BIG FLOP TOURNAMENT RESULTS BUYER BEWARE members will come to see and appreciate the From The President’s camaraderie that the golf club offers. While everything we do at HVGC orbits golf, the real Desk value many of us get is the fellowship, friendship and family aspect of our games, tournaments and social events. For me, as I am sure with many of you, I think of golf as a sport To put it mildly, this has that has gotten me through a lot been a memorable of highs and lows but when I summer at HVGC. really think about it, it's the people I am playing with that In September, I'd like to provide that support, guidance make it a point to ask and oftentimes mentorship. So everyone to take as much for our long time members, take sand as you can out onto a minute to introduce yourself to the course and fill divots. the new faces you see around the We all want the course to club in the coming weeks and be in better shape and months. They are the future of everyone has their ideas HVGC. And to the new members on how to make this all I can say is listen, learn and happen (those board most importantly participate. meetings don't go three Most of the time it might seem hours for nothing) but one like just another round of golf thing we can all do is take but after awhile you'll find that out a sand bottle or ten Eric Kranz when you need a hand, the members at and fill a fairways worth of our club are always happy to help. -

Next to Publix
Guide to the 2018 Masters A special publication of The Oconee Cellar Lake Oconee’s Oldest, Most Trusted Wine and Spirit Store • FINE WINE • CIGARS • SPIRITS • BEER 60155-1 6350 Lake Oconee Pkwy. Hours: (Open til 9pm Masters Week) Greensboro, GA Mon-Thur 10am-8pm NEXT TO PUBLIX Fri & Sat 10am-9pm 706.453.0420 Sunday 12:30 pm -6:00pm 2 Lake Oconee Breeze Thursday, April 5, 2018 Cuscowilla named Top Residential Golf Course in Georgia by Golfweek Photo from cuscowilla.com Lake Oconee Breeze than 850 course raters re- in 1997 to rave reviews and view more than 3,600 golf has become a fixture atop EATONTON — Cuscow- courses across the United the annual “best-of” lists, Spring is Calling illa on Lake Oconee has States each year, evaluating amassing an impressive list been named the No. 1 Resi- each facility nominated on of honors including distinc- dential Golf Course in the basis of Golfweek’s 10 tions among the Top 100 the state of strict standards of evalua- Modern Golf Courses in the tion. U.S., the No. 1 Golf Course Designed by the re- You Can Play In Georgia, Georgia for nowned duo of and most recently, the #1 the second consec- Bill Coore and Residential Golf Course in utive year, and the No. 30 two-time Mas- Georgia in both 2017 and Residential Golf Course ters’ Champion 2018. in the U.S. for 2018 by Ben Crenshaw, For more informa- Golfweek Magazine. Cuscowilla on tion on Cuscowilla on To compile the list, Lake Oconee Lake Oconee, visit Golfweek’s team of more opened for play www.cuscowilla.com. -

Speed Golf Classic
For your game A need for speed? officials on how to efficiently increase play Pumpkin Ridge pro at their courses. thinks golf would “This slow pace is driving people out of the game,” he says. “It’s killing the game. benefit from a swift kick Golf has become an all-day sport. It is time to change this. There is a lot of support for By James Achenbach changing it.” One solution is to pull golfers from the n October 2005, golf pro course if they don’t maintain pace. Another Christopher Smith shot is to place a renewed emphasis on the nine- I5-under-par 65 in a tournament hole round, particularly among beginners. at Jackson Park Golf Course Because of his experiences, Smith has in Chicago. changed the way he teaches the game. Consider this: Smith carried only six “I have learned how our unconscious clubs. guides these brilliant maneuvers and skills Ponder this: He played the round in 44 we have, if we allow it to happen,” he says. minutes, 6 seconds, an average of slightly “I believe the adaptive unconscious takes 1 less than 2 ⁄2 minutes per hole. over, and what we must do is keep the Smith set a world record that day in all-knowing disruptive side out. the Chicago Speed Golf Classic. Each To hasten the learning process, he uses competitor’s final score was determined by training aids, swing drills and descriptive adding together the golf score and the time. metaphors to help draw mental pictures Smith’s magic number: 109.1. -

Golf Week Is Golf News 52 Weeks a Year
OUR 1606 TH ISSUE Vol. 31, No. 45 R O C H E S T E R Monday, December 2, 2019 Course Maintenance: Golf Teaches Life’s Most Valuable Skills BY MONTE KOCH, PGA Efficiency in Over-Seeding My Grandpa Lafe was, and still is, one of my heroes. He was a proud WWII veteran and a member of the “greatest gen- eration.” Besides being witty, a great speaker and gifted with his hands, my Grandpa was a great teacher of “how to live life” and to be a blessing to others. Although I didn’t learn golf directly from him, I do believe I got it from his father, Lafe Sr. When I was 21, I remem- ber playing nine holes with him Young people can learn responsibility, acceptance, maturity and patience when he was 96 years young. As through programs such as PGA Junior League Golf. Trinity Forest Golf Club in Dallas has experiment with different over-seeding I think of it now, it’s even more tactics on its practice range. On the right, is Primo-treated turf. (Bill Weller) amazing. He played two times While that’s amazing, it’s just noon in St. George, Utah, learn- a week until the last year of his as special that he and I could ing the game together. I had BY HAL PHILLIPS Solutions. “Otherwise, fall seeding life... yes, you read that right! spend time together that after- Golf Teaches — PAGE 5 With water becoming increas- becomes impractical from a bud- ingly scarce and expensive in get perspective — or, in the dam- some regions, superintendents age-repair scenario, it becomes a are deploying creative tactics to matter of addressing these areas First Tee of Western NY Takes boost establishment. -

Golf's Short Game
01_569201 ffirs.qxd 1/25/05 10:41 PM Page i Golf’s Short Game FOR DUMmIES‰ by Michael Patrick Shiels with Michael Kernicki 01_569201 ffirs.qxd 1/25/05 10:41 PM Page iv 01_569201 ffirs.qxd 1/25/05 10:41 PM Page i Golf’s Short Game FOR DUMmIES‰ by Michael Patrick Shiels with Michael Kernicki 01_569201 ffirs.qxd 1/25/05 10:41 PM Page ii Golf’s Short Game For Dummies® Published by Wiley Publishing, Inc. 111 River St. Hoboken, NJ 07030-5774 www.wiley.com Copyright © 2005 by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permis- sion of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, 978-750-8400, fax 978-646-8600. Requests to the Publisher for permission should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, 317-572-3447, fax 317-572-4355, e-mail: [email protected]. Trademarks: Wiley, the Wiley Publishing logo, For Dummies, the Dummies Man logo, A Reference for the Rest of Us!, The Dummies Way, Dummies Daily, The Fun and Easy Way, Dummies.com and related trade dress are trademarks or registered trademarks of John Wiley & Sons, Inc.