Building Advanced, Offline Web Applications with HTML 5
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Programming in HTML5 with Javascript and CSS3 Ebook
spine = 1.28” Programming in HTML5 with JavaScript and CSS3 and CSS3 JavaScript in HTML5 with Programming Designed to help enterprise administrators develop real-world, About You job-role-specific skills—this Training Guide focuses on deploying This Training Guide will be most useful and managing core infrastructure services in Windows Server 2012. to IT professionals who have at least Programming Build hands-on expertise through a series of lessons, exercises, three years of experience administering and suggested practices—and help maximize your performance previous versions of Windows Server in midsize to large environments. on the job. About the Author This Microsoft Training Guide: Mitch Tulloch is a widely recognized in HTML5 with • Provides in-depth, hands-on training you take at your own pace expert on Windows administration and has been awarded Microsoft® MVP • Focuses on job-role-specific expertise for deploying and status for his contributions supporting managing Windows Server 2012 core services those who deploy and use Microsoft • Creates a foundation of skills which, along with on-the-job platforms, products, and solutions. He experience, can be measured by Microsoft Certification exams is the author of Introducing Windows JavaScript and such as 70-410 Server 2012 and the upcoming Windows Server 2012 Virtualization Inside Out. Sharpen your skills. Increase your expertise. • Plan a migration to Windows Server 2012 About the Practices CSS3 • Deploy servers and domain controllers For most practices, we recommend using a Hyper-V virtualized • Administer Active Directory® and enable advanced features environment. Some practices will • Ensure DHCP availability and implement DNSSEC require physical servers. -

Standard Query Language (SQL) Hamid Zarrabi-Zadeh Web Programming – Fall 2013 2 Outline
Standard Query Language (SQL) Hamid Zarrabi-Zadeh Web Programming – Fall 2013 2 Outline • Introduction • Local Storage Options Cookies Web Storage • Standard Query Language (SQL) Database Commands Queries • Summary 3 Introduction • Any (web) application needs persistence storage • There are three general storage strategies: server-side storage client-side storage a hybrid strategy 4 Client-Side Storage • Client-side data is stored locally within the user's browser • A web page can only access data stored by itself • For a long time, cookies were the only option to store data locally • HTML5 introduced several new web storage options 5 Server-Side Storage • Server-side data is usually stored within a file or a database system • For large data, database systems are preferable over plain files • Database Management Systems (DBMSs) provide an efficient way to store and retrieve data Cookies 7 Cookies • A cookie is a piece of information stored on a user's browser • Each time the browser requests a page, it also sends the related cookies to the server • The most common use of cookies is to identify a particular user amongst a set of users 8 Cookies Structure • Each cookie has: • a name • a value (a 4000 character string) • expiration date (optional) • path and domain (optional) • if no expiration date is specified, the cookie is considered as a session cookie • Session cookies are deleted when the browser session ends (the browser is closed by the user) 9 Set/Get Cookies • In JavaScript, cookies can be accessed via the document.cookie -

Amazon Silk Developer Guide Amazon Silk Developer Guide
Amazon Silk Developer Guide Amazon Silk Developer Guide Amazon Silk: Developer Guide Copyright © 2015 Amazon Web Services, Inc. and/or its affiliates. All rights reserved. The following are trademarks of Amazon Web Services, Inc.: Amazon, Amazon Web Services Design, AWS, Amazon CloudFront, AWS CloudTrail, AWS CodeDeploy, Amazon Cognito, Amazon DevPay, DynamoDB, ElastiCache, Amazon EC2, Amazon Elastic Compute Cloud, Amazon Glacier, Amazon Kinesis, Kindle, Kindle Fire, AWS Marketplace Design, Mechanical Turk, Amazon Redshift, Amazon Route 53, Amazon S3, Amazon VPC, and Amazon WorkDocs. In addition, Amazon.com graphics, logos, page headers, button icons, scripts, and service names are trademarks, or trade dress of Amazon in the U.S. and/or other countries. Amazon©s trademarks and trade dress may not be used in connection with any product or service that is not Amazon©s, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. AWS documentation posted on the Alpha server is for internal testing and review purposes only. It is not intended for external customers. Amazon Silk Developer Guide Table of Contents What Is Amazon Silk? .................................................................................................................... 1 Split Browser Architecture ...................................................................................................... -

Download Slides
A Snapshot of the Mobile HTML5 Revolution @ jamespearce The Pledge Single device Multi device Sedentary user Mobile* user Declarative Imperative Thin client Thick client Documents Applications * or supine, or sedentary, or passive, or... A badge for all these ways the web is changing HTML5 is a new version of HTML4, XHTML1, and DOM Level 2 HTML addressing many of the issues of those specifications while at the same time enhancing (X)HTML to more adequately address Web applications. - WHATWG Wiki WHATWG What is an Application? Consumption vs Creation? Linkable? User Experience? Architecture? Web Site sites Web apps Native apps App Nativeness MS RIM Google Apple Top US Smartphone Platforms August 2011, comScore MobiLens C# J2ME/Air Java/C++ Obj-C Native programming languages you’ll need August 2011 IE WebKit WebKit WebKit Browser platforms to target August 2011 There is no WebKit on Mobile - @ppk But at least we are using one language, one markup, one style system One Stack Camera WebFont Video Audio Graphics HTTP Location CSS Styling & Layout AJAX Contacts Events SMS JavaScript Sockets Orientation Semantic HTML SSL Gyro File Systems Workers & Cross-App Databases Parallel Messaging App Caches Processing The Turn IE Chrome Safari Firefox iOS BBX Android @font-face Canvas HTML5 Audio & Video rgba(), hsla() border-image: border-radius: box-shadow: text-shadow: opacity: Multiple backgrounds Flexible Box Model CSS Animations CSS Columns CSS Gradients CSS Reflections CSS 2D Transforms CSS 3D Transforms CSS Transitions Geolocation API local/sessionStorage -

Exposing Native Device Apis to Web Apps
Exposing Native Device APIs to Web Apps Arno Puder Nikolai Tillmann Michał Moskal San Francisco State University Microsoft Research Microsoft Research Computer Science One Microsoft Way One Microsoft Way Department Redmond, WA 98052 Redmond, WA 98052 1600 Holloway Avenue [email protected] [email protected] San Francisco, CA 94132 [email protected] ABSTRACT language of the respective platform, HTML5 technologies A recent survey among developers revealed that half plan to gain traction for the development of mobile apps [12, 4]. use HTML5 for mobile apps in the future. An earlier survey A recent survey among developers revealed that more than showed that access to native device APIs is the biggest short- half (52%) are using HTML5 technologies for developing mo- coming of HTML5 compared to native apps. Several dif- bile apps [22]. HTML5 technologies enable the reuse of the ferent approaches exist to overcome this limitation, among presentation layer and high-level logic across multiple plat- them cross-compilation and packaging the HTML5 as a na- forms. However, an earlier survey [21] on cross-platform tive app. In this paper we propose a novel approach by using developer tools revealed that access to native device APIs a device-local service that runs on the smartphone and that is the biggest shortcoming of HTML5 compared to native acts as a gateway to the native layer for HTML5-based apps apps. Several different approaches exist to overcome this running inside the standard browser. WebSockets are used limitation. Besides the development of native apps for spe- for bi-directional communication between the web apps and cific platforms, popular approaches include cross-platform the device-local service. -

Security Considerations Around the Usage of Client-Side Storage Apis
Security considerations around the usage of client-side storage APIs Stefano Belloro (BBC) Alexios Mylonas (Bournemouth University) Technical Report No. BUCSR-2018-01 January 12 2018 ABSTRACT Web Storage, Indexed Database API and Web SQL Database are primitives that allow web browsers to store information in the client in a much more advanced way compared to other techniques such as HTTP Cookies. They were originally introduced with the goal of enhancing the capabilities of websites, however, they are often exploited as a way of tracking users across multiple sessions and websites. This work is divided in two parts. First, it quantifies the usage of these three primitives in the context of user tracking. This is done by performing a large-scale analysis on the usage of these techniques in the wild. The results highlight that code snippets belonging to those primitives can be found in tracking scripts at a surprising high rate, suggesting that user tracking is a major use case of these technologies. The second part reviews of the effectiveness of the removal of client-side storage data in modern browsers. A web application, built for specifically for this study, is used to highlight that it is often extremely hard, if not impossible, for users to remove personal data stored using the three primitives considered. This finding has significant implications, because those techniques are often uses as vector for cookie resurrection. CONTENTS Abstract ........................................................................................................................ -

HTML5 Storage HTML5 Forms Geolocation Event Listeners Canvas Element Video and Audio Element HTML5 Storage 1
HTML5 storage HTML5 Forms Geolocation Event listeners canvas element video and audio element HTML5 Storage 1 • A way for web pages to store named key/value pairs locally, within the client web browser – You can store up to about 5 MB of data – Everything is stored as strings • Like cookies, this data persists even after you navigate away from the web site • Unlike cookies, this data is never transmitted to the remote web server • Properties and methods belong to the window object • sessionStorage work as localStorage but for the session localStorage[key] = value; // set localStorage.setItem(key, value); // alternative local-session- var text = localStorage[key]; // get var text = localStorage.getItem(key); // alternative storage.html console.log(localStorage.key(0)); // get key name localStorage.removeItem(key); // remove localStorage.clear(key); // clears the entire storage HTML5 Storage 2 • Web SQL Database (formerly known as “WebDB”) provides a thin wrapper around a SQL database, allowing you to do things like this from JavaScript function testWebSQLDatabase() { openDatabase('documents', '1.0', 'Local document storage', 5*1024*1024, function (db) { db.changeVersion('', '1.0', function (t) { t.executeSql('CREATE TABLE docids (id, name)'); //t.executeSql('drop docids'); localstorage.html }, error); }); } Not working - check: http://html5demos.com/ for working sample • As you can see, most of the action resides in the string you pass to the executeSql method. This string can be any supported SQL statement, including SELECT, UPDATE, INSERT, and DELETE statements. It’s just like backend database programming, except you’re doing it from JavaScript! • A competing Web DB standard is IndexedDB which uses a non- SQL API to something called object store - demos are only available this far HTML5 Forms • There are basically five areas of improvements when it comes to form features in HTML5 • New input types as email, url, number, search, date etc. -

CS2550 Dr. Brian Durney SOURCES
CS2550 Dr. Brian Durney SOURCES JavaScript: The Definitive Guide, by David Flanagan Dive into HTML5, by Mark Pilgrim http://diveintohtml5.info/storage.html WEB STORAGE BEFORE HTML5 Cookies – sent to server possibly unencrypted, only 4K data Internet Explorer – userData Flash – Local Shared Objects Dojo Toolkit – dojox.storage Google Gears Except for cookies, all of these rely on third- party plugins or are only available in one browser. (Cookies have their own issues.) WEB STORAGE Provides persistent storage for web applications "playerName": "George" tictactoe.com "won": "3" "lost": "10" Tic Tac Toe George Won: 3 Maps string keys to string Lost: 10 values Can store “large (but not huge) amounts of data” David Flanagan, JavaScript: The Definitive Guide p. 587 PERSISTENT STORAGE Web app saves data User quits browser User returns to site in in local storage same browser tictactoe.com tictactoe.com tictactoe.com Tic Tac Toe Tic Tac Toe Tic Tac Toe George George George Won: 3 Won: 3 Won: 3 Lost: 10 Lost: 10 Lost: 10 "playerName": "George" "playerName": "George" "won": "3" "won": "3" "lost": "10" "lost": "10" BROWSER Web storage is supported by (virtually) all current browsers SUPPORT and a lot of older browsers. caniuse.com screencapture from 20OCT15 http://caniuse.com/#search=localStorage USING LOCAL STORAGE LIKE AN OBJECT localStorage.playerName = "George"; localStorage['won'] = 3; WRITE localStorage.lost = 10; "playerName": "George" "won": "3" "lost": "10" var name = localStorage.playerName; alert(name); // ALERTS George READ -

Download This PDF File
Paper—An Investigation of User Privacy and Data Protection on User-Side Storages An Investigation of User Privacy and Data Protection on User-Side Storages https://doi.org/10.3991/ijoe.v15i09.10669 Thamer Al-Rousan Isra University, Amman, Jordan, [email protected] Abstract—Along with the introduction of HTML5, a new user storage tech- nologies; particularly, Web SQL Database, Web Storage, and Indexed Database API have emerged. The common goal of these storage technologies is to over- come the limitations of legacy of user-side storage mechanisms. All these tech- nologies have many privacy and security concerns, and the main threat is user tracking. In this context, this study investigates the usage of these technologies and to find out which one of these technologies is primarily used by user track- ers, and to calculate their frequency in context of 3rd-party tracking code. The result exposes that the adoption of Web Storage most commonly used amongst the three storage technologies. Motivated by the investigation results, this study examines the degree of protection which the popular web browsers supply to prevent privacy violations. The result reveals that the protection mechanisms that are provided by web browsers are almost the same, and in many occasions privacy violations do exist. Keywords—User-side storages, User tracking, Cookies, Security and privacy 1 Introduction Using the internet and the services that it provides has continuously increased as it has become the main source of information for thousands of millions of people, at work, at school, and at home. People spend over 60 hours a week browsing the inter- net, using personal computers or portable devices. -

Introducing HTML5 Second Edition
HTMLINTRODUCING SECOND 5EDITION BRUCE LAWSON REMY SHARP Introducing HTML5, Second Edition Bruce Lawson and Remy Sharp New Riders 1249 Eighth Street Berkeley, CA 94710 510/524-2178 510/524-2221 (fax) Find us on the Web at: www.newriders.com To report errors, please send a note to [email protected] New Riders is an imprint of Peachpit, a division of Pearson Education Copyright © 2012 by Remy Sharp and Bruce Lawson Project Editor: Michael J. Nolan Development Editor: Margaret S. Anderson/Stellarvisions Technical Editors: Patrick H. Lauke (www.splintered.co.uk), Robert Nyman (www.robertnyman.com) Production Editor: Cory Borman Copyeditor: Gretchen Dykstra Proofreader: Jan Seymour Indexer: Joy Dean Lee Compositor: Danielle Foster Cover Designer: Aren Howell Straiger Cover photo: Patrick H. Lauke (splintered.co.uk) Notice of Rights All rights reserved. No part of this book may be reproduced or transmitted in any form by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the publisher. For informa- tion on getting permission for reprints and excerpts, contact permissions@ peachpit.com. Notice of Liability The information in this book is distributed on an “As Is” basis without war- ranty. While every precaution has been taken in the preparation of the book, neither the authors nor Peachpit shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the instructions contained in this book or by the com- puter software and hardware products described in it. Trademarks Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. -

NIST SP 800-28 Version 2 Guidelines on Active Content and Mobile
Special Publication 800-28 Version 2 (Draft) Guidelines on Active Content and Mobile Code Recommendations of the National Institute of Standards and Technology Wayne A. Jansen Theodore Winograd Karen Scarfone NIST Special Publication 800-28 Guidelines on Active Content and Mobile Version 2 Code (Draft) Recommendations of the National Institute of Standards and Technology Wayne A. Jansen Theodore Winograd Karen Scarfone C O M P U T E R S E C U R I T Y Computer Security Division Information Technology Laboratory National Institute of Standards and Technology Gaithersburg, MD 20899-8930 March 2008 U.S. Department of Commerce Carlos M. Gutierrez, Secretary National Institute of Standards and Technology James M. Turner, Acting Director GUIDELINES ON ACTIVE CONTENT AND MOBILE CODE Reports on Computer Systems Technology The Information Technology Laboratory (ITL) at the National Institute of Standards and Technology (NIST) promotes the U.S. economy and public welfare by providing technical leadership for the nation’s measurement and standards infrastructure. ITL develops tests, test methods, reference data, proof of concept implementations, and technical analysis to advance the development and productive use of information technology. ITL’s responsibilities include the development of technical, physical, administrative, and management standards and guidelines for the cost-effective security and privacy of sensitive unclassified information in Federal computer systems. This Special Publication 800-series reports on ITL’s research, guidance, and outreach efforts in computer security and its collaborative activities with industry, government, and academic organizations. National Institute of Standards and Technology Special Publication 800-28 Version 2 Natl. Inst. Stand. Technol. Spec. Publ. -
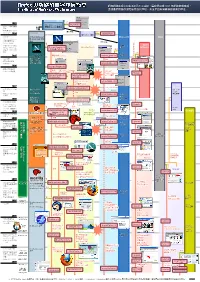
Firefox 與網路瀏覽器發展簡史 網際網路在現今的生活中已不可或缺,讓我們回溯 1993 年網路黎明時期, the History of Firefox and Web Browsers 透過最常接觸的瀏覽器其進化歷程,來逐步回顧網際網路發展的歷史。
Firefox 與網路瀏覽器發展簡史 網際網路在現今的生活中已不可或缺,讓我們回溯 1993 年網路黎明時期, The History of Firefox and Web Browsers 透過最常接觸的瀏覽器其進化歷程,來逐步回顧網際網路發展的歷史。 NCSA 發行 Marc Andreessen 等人 NCSA Mosaic 離開 ‧Mosaic 席捲瀏覽器 開發出 Mosaic 瀏覽器 市場 ‧台灣 最 初 的 WWW Server 出現 提供授權 發行 Mosaic Spyglass Spyglass Mosaic Communications 取得 Mosaic 授權 .W3C 成立 由 Marc Andreessen Microsoft Apple .Netscape Navigator 及 James Clark 共同 席捲瀏覽器市場 設立 發行 提供授權 分頁瀏覽功能的原型 .Yahoo! JP上線 .台灣首家 ISP 新絲 取得 Mosaic Opera 路成立、Hinet 成立 Netscape Navigator 1.0 Mozilla Classic 授權 Software .教育部 TWNIC 計畫 開發代號「Mozilla」 發行 開始 發行 Windows 95 開始支援 JavaScript Internet Explorer 1.0 發行 ‧Java 登場 因 NCSA 抗議 發展 ‧網路使用者遽增 而變更公司名稱 MultiTorg Opera 1.0 ‧蕃薯藤成立 日本分公司成立 Internet Explorer 2.0 Netscape Navigator 2.0 ‧瀏覽器大戰白熱化 發展 整合 Mail、Composer ‧公佈 CSS1 建議書 郵件及網頁編輯功能 部份支援 JScript、VBScript Opera 2.0 Netscape Navigator 3.0 Netscape Navigator 3.0 及 CSS 草案 Standard Edition Gold Edition 支援 CSS、DHTML Internet Explorer 3.0 加強國際化支援 KDE Netscape Communicator 4.0 CSS、DHTML Project ‧公佈 HTML4.0 建議 精誠公司代理 KDE HTML 書 Netscape Trident 發展 widget ‧精誠公司成立 Kimo 進入台灣市場 開始開發 Internet Explorer 4.0 Windows 98 奇摩站 發行 免費散佈 NC4.x 整合 IE 4.0 開發中的 NC5.0 Netscape Communicator 5.0 ‧IE 獲得壓倒性優勢 開放原始碼化 ‧CSS2、XML1.0、 繼承部份程式碼 Opera 3.0 發行 和設計概念 支援 Ruby Text DOM 1 建議書公佈 放棄 文字顯示 KHTML ‧SEEDNet、蕃薯藤公 加入 Mail 功能 公開 司化 Mozilla Application Suite Gecko Internet Explorer 5.0 Google [Milestone 3~18] 高度支援網頁 ‧台灣上網人口突 破 開發代號「Seamonkey」 標準的成像技術 四百萬 支援文字直排 由 Netscape 的 全 發展 Windows 職員工和 Netscape 2000 發行 ‧瀏覽器大戰結束 開始中文化專案台灣志願者Communications Mozilla Application Suite 0.6 Internet Explorer 5.5 Opera