A.13 Apache Groovy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reference Guide
Apache Syncope - Reference Guide Version 2.1.9 Table of Contents 1. Introduction. 2 1.1. Identity Technologies. 2 1.1.1. Identity Stores . 2 1.1.2. Provisioning Engines . 4 1.1.3. Access Managers . 5 1.1.4. The Complete Picture . 5 2. Architecture. 7 2.1. Core . 7 2.1.1. REST . 7 2.1.2. Logic . 8 2.1.3. Provisioning . 8 2.1.4. Workflow. 9 2.1.5. Persistence . 9 2.1.6. Security . 9 2.2. Admin UI. 10 2.2.1. Accessibility . 10 2.3. End-user UI. 12 2.3.1. Password Reset . 12 2.3.2. Accessibility . 13 2.4. CLI . 15 2.5. Third Party Applications. 15 2.5.1. Eclipse IDE Plugin . 15 2.5.2. Netbeans IDE Plugin. 15 3. Concepts . 16 3.1. Users, Groups and Any Objects . 16 3.2. Type Management . 17 3.2.1. Schema . 17 Plain . 17 Derived . 18 Virtual . 18 3.2.2. AnyTypeClass . 19 3.2.3. AnyType . 19 3.2.4. RelationshipType . 21 3.2.5. Type Extensions . 22 3.3. External Resources. 23 3.3.1. Connector Bundles . 24 3.3.2. Connector Instance details . 24 3.3.3. External Resource details . 25 3.3.4. Mapping . 26 3.3.5. Linked Accounts . 29 3.4. Realms . 29 3.4.1. Realm Provisioning . 30 3.4.2. LogicActions . 31 3.5. Entitlements. 31 3.6. Privileges . 31 3.7. Roles. 31 3.7.1. Delegated Administration . 32 3.8. Provisioning. 33 3.8.1. Overview. 33 3.8.2. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Open Source Software Licenses, Notices, and Information
Intergraph InPursuit® WebRMS 03.06.1909 Open Source Software Licenses, Notices, and Information This information is provided for Intergraph InPursuit® WebRMS, a software program of Intergraph® Corporation D/B/A Hexagon Safety & Infrastructure® (“Hexagon”). Source Code Access Intergraph InPursuit WebRMS may include components licensed pursuant to open source software licenses with an obligation to offer the recipient source code. Please see below the list of such components and the information needed to access the source code repository for each. In the event the source code is inaccessible using the information below, please email [email protected]. Component, version Link to download repository Hibernate ORM https://github.com/hibernate/hibernate-orm/releases/tag/3.6.10.Final 3.6.10.Final javassist 3.12.0.GA https://github.com/jboss-javassist/javassist/releases/tag/rel_3_12_0_ga wsdl4j 1.6.1 https://sourceforge.net/projects/wsdl4j/files/WSDL4J/1.6.1/ aspectj 1.8.4 http://git.eclipse.org/c/aspectj/org.aspectj.git/tag/?h=V1_8_4 displaytag 1.2.9 https://github.com/hexagonSI-RMS/displaytag-hexagon Open Source Software Components Intergraph InPursuit WebRMS may include the open source software components identified below. This document provides the notices and information regarding any such open source software for informational purposes only. Please see the product license agreement for Intergraph InPursuit WebRMS to determine the terms and conditions that apply to the open source software. Hexagon reserves all other rights. Component, version URL Copyright License link ActiveMQ KahaDB, version http://activemq.apache.org/kahadb.html © 2005-2012 Apache Software Foundation License 1 5.5.1 ActiveMQ, version 5.5.1 http://activemq.apache.org/ © 2005-2012 Apache Software Foundation License 1 Activiti, version 5.14.0 https://www.activiti.org/ © 2010-2016 Alfresco Software, Ltd. -
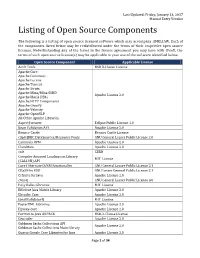
Listing of Open Source Components
Last Updated: Friday, January 13, 2017 Manual Entry Version Listing of Open Source Components The following is a listing of open source licensed software which may accompany AMELIA®. Each of the components listed below may be redistributed under the terms of their respective open source licenses. Notwithstanding any of the terms in the license agreement you may have with IPsoft, the terms of such open source license(s) may be applicable to your use of the software identified below. Open Source Component Applicable License Antlr Tools BSD 3-Clause License Apache Core Apache Commons Apache Lucene Apache Tomcat Apache Struts Apache Mina/Mina SSHD Apache License 2.0 Apache Maria DB4j Apache HTTP Components Apache Groovy Apache Velocity Apache OpenNLP All Other Apache Libraries AspectJ weaver Eclipse Public License 1.0 Bean Validation API Apache License 2.0 Bouncy Castle Bouncy Castle License c3p0:JDBC DataSources/Resource Pools GNU General Lesser Public License 2.0 Camunda BPM Apache License 2.0 ClassMate Apache License 2.0 colt CERN Compiler Assisted Localization Library MIT License (CAL10N) API Core Hibernate O/RM functionality GNU General Lesser Public License 2.1 CRaSH by EXO GNU Lesser General Public License 2.1 Crfsuite for Java Apache License 2.0 cron4j GNU General Lesser Public License 3.0 Easy Rules Libraries MIT License Efficient Java Matrix Library Apache License 2.0 Ehcache Core Apache License 2.0 EmailValidator4J MIT License FasterXML Libraries Apache License 2.0 Flyway-core Apache License 2.0 Fortran to Java ARPACK BSD-2-Clause -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -
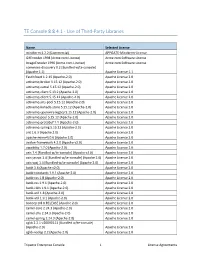
TE Console 8.8.4.1 - Use of Third-Party Libraries
TE Console 8.8.4.1 - Use of Third-Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 [Bundled w/te-console] (Apache 1.1) Apache License 1.1 FastInfoset 1.2.15 (Apache-2.0) Apache License 2.0 activemQ-broker 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-camel 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-client 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-client 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-jms-pool 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-kahadb-store 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-openwire-legacy 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-pool 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemQ-spring 5.15.12 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 apache-mime4j 0.6 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 [Bundled w/te-console] (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 axis-saaj 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 batik 1.6 (Apache v2.0) Apache License 2.0 batik-constants 1.9.1 (Apache-2.0) Apache License 2.0 batik-css 1.8 (Apache-2.0) Apache License 2.0 batik-css 1.9.1 (Apache-2.0) Apache License 2.0 batik-i18n 1.9.1 (Apache-2.0) -

Oracle Utilities Testing Accelerator Licensing Information User Manual Release 6.0.0.3.0 F35952-01
Oracle Utilities Testing Accelerator Licensing Information User Manual Release 6.0.0.3.0 F35952-01 June 2021 Oracle Utilities Testing Accelerator Licensing Information User Manual, Release 6.0.0.3.0 Copyright © 2019, 2021 Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" -

Diebold Nixdorf EULA for Vynamic View 5.5 7-Zip 19.00
Diebold Nixdorf EULA Vynamic View 5.5 February 15, 2021 Page 1 of 70 Diebold Nixdorf EULA for Vynamic View 5.5 7-Zip 19.00 Copyright (C) 1999-2016 Igor Pavlov GNU LESSER GENERAL PUBLIC LICENSE @fortawesome/fontawesome-svg-core 1.2.15 Copyright (C) 2012 by Dave Gandy and Contributors MIT License @fortawesome/free-solid-svg-icons 5.7.2 Copyright © Fonticons, Inc. Creative Commons Attribution 4.0 International Public License @fortawesome/react-fontawesome 0.1.4 Copyright 2018 Fonticons, Inc. MIT License activation 1.1 Copyright (c) 2012-2013 Oracle and/or its affiliates. All rights reserved. Common Development and Distribution License 1.0 activemq-core 5.2.0 Copyright © 2004-2011 The Apache Software Foundation. All rights reserved. Apache License 2.0 Annotation 1.0 1.1 Copyright 2004–2017 The Apache Software Foundation. All rights reserved. Apache License 2.0 ANTLR 2.7.6 Diebold Nixdorf EULA Vynamic View 5.5 February 15, 2021 Page 2 of 70 Copyright Notice Copyright (c) ANTLR / Terence Parr 2014 All rights reserved BSD 3 Clause License ANTLR 3.3 Copyright (c) 2012-2017 The ANTLR Project. All rights reserved. BSD 3 Clause License AOP Alliance 1.0 Copyright aopsys.com Public Domain Notice Apache ActiveMQ 5.2.0 Copyright © 2004-2011 The Apache Software Foundation. Apache License 2.0 2.0 Apache Ant Core 1.8.2 Copyright 1999-2006 The Apache Software Foundation. Apache License 2.0 2.0 Apache Ant Launcher 1.8.2 Copyright 2004–2017 The Apache Software Foundation. All rights reserved. Apache License 2.0 2.0 Apache Axis 1.4 Copyright 2004–2017 The Apache Software Foundation. -
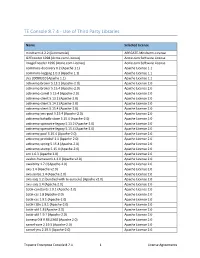
TE Console 8.7.4 - Use of Third Party Libraries
TE Console 8.7.4 - Use of Third Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 (Apache 1.1) Apache License 1.1 commons-logging 1.0.3 (Apache 1.1) Apache License 1.1 jrcs 20080310 (Apache 1.1) Apache License 1.1 activemq-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemq-broker 5.15.4 (Apache-2.0) Apache License 2.0 activemq-camel 5.15.4 (Apache-2.0) Apache License 2.0 activemq-client 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.14.2 (Apache-2.0) Apache License 2.0 activemq-client 5.15.4 (Apache-2.0) Apache License 2.0 activemq-jms-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-kahadb-store 5.15.4 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.15.4 (Apache-2.0) Apache License 2.0 activemq-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemq-spring 5.15.4 (Apache-2.0) Apache License 2.0 activemq-stomp 5.15.4 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 (Apache 2.0) Apache License 2.0 axis-saaj 1.2 [bundled with te-console] (Apache v2.0) Apache License 2.0 axis-saaj 1.4 (Apache 2.0) Apache License 2.0 batik-constants -

Groovy Programming Cookbook I
Groovy Programming Cookbook i Groovy Programming Cookbook Groovy Programming Cookbook ii Contents 1 Groovy Script Tutorial for Beginners 1 1.1 Environment......................................................1 1.2 Scripting Basics....................................................1 1.3 Example - Order Processing.............................................1 1.4 Planning and approach................................................2 1.5 Groovy Scripts for Business Objects.........................................2 1.5.1 Order POGO.................................................2 1.5.2 First Level Unit Test.............................................4 1.5.3 Test Order - Random Entries Onetime....................................5 1.5.4 Test Order - Random Entries at Intervals...................................6 1.6 Groovy Scripts for Database.............................................9 1.6.1 Configuration file to hold the database properties..............................9 1.6.2 Parsing the configuration file......................................... 10 1.6.3 Create Table................................................. 11 1.6.4 Insert Rows from a Single File........................................ 12 1.6.5 Select Total Count.............................................. 14 1.6.6 Select All Rows................................................ 14 1.6.7 Insert Rows from the matching files at interval............................... 16 1.6.8 Truncate Table................................................ 19 1.6.9 Drop Table................................................. -
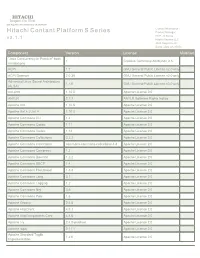
Hitachi Contant Platform S Series Product Manager HCP - S Series V 3
HITACHI Inspire the Next 2535 Augustine Drive Santa Clara, CA 95054 USA Contact Information : Hitachi Contant Platform S Series Product Manager HCP - S Series v 3 . 1 . 1 Hitachi Vantara LLC 2535 Augustine Dr. Santa Clara CA 95054 Component Version License Modified "Java Concurrency in Practice" book 1 Creative Commons Attribution 2.5 annotations ACPI 1.7 GNU General Public License v2.0 only ACPI Daemon 2.0.30 GNU General Public License v2.0 only Advanced Linux Sound Architecture 1.1.6 GNU General Public License v3.0 only (ALSA) ant-antlr 1.10.5 Apache License 2.0 ANTLR 2.7.7 ANTLR Software Rights Notice Apache Ant 1.10.5 Apache License 2.0 Apache Ant + JUnit 4 1.10.5 Apache License 2.0 Apache Commons CLI 1.4 Apache License 2.0 Apache Commons Codec 1.11 Apache License 2.0 Apache Commons Codec 1.14 Apache License 2.0 Apache Commons Collections 3.2.2 Apache License 2.0 Apache Commons Collections commons-commons-collections-4.4 Apache License 2.0 Apache Commons Compress 1.2 Apache License 2.0 Apache Commons Daemon 1.2.2 Apache License 2.0 Apache Commons DBCP 1.4 Apache License 2.0 Apache Commons FileUpload 1.3.3 Apache License 2.0 Apache Commons Lang 3.1 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 Apache Commons Net 3.6 Apache License 2.0 Apache Commons Pool 1.6 Apache License 2.0 Apache Groovy 2.4.8 Apache License 2.0 Apache HttpClient 4.5.3 Apache License 2.0 Apache HttpComponents Core 4.4.6 Apache License 2.0 Apache Ivy 2.4.0-patched Apache License 2.0 Apache log4j 2.11.1 Apache License 2.0 Apache Standard Taglib -

Code Smell Prediction Employing Machine Learning Meets Emerging Java Language Constructs"
Appendix to the paper "Code smell prediction employing machine learning meets emerging Java language constructs" Hanna Grodzicka, Michał Kawa, Zofia Łakomiak, Arkadiusz Ziobrowski, Lech Madeyski (B) The Appendix includes two tables containing the dataset used in the paper "Code smell prediction employing machine learning meets emerging Java lan- guage constructs". The first table contains information about 792 projects selected for R package reproducer [Madeyski and Kitchenham(2019)]. Projects were the base dataset for cre- ating the dataset used in the study (Table I). The second table contains information about 281 projects filtered by Java version from build tool Maven (Table II) which were directly used in the paper. TABLE I: Base projects used to create the new dataset # Orgasation Project name GitHub link Commit hash Build tool Java version 1 adobe aem-core-wcm- www.github.com/adobe/ 1d1f1d70844c9e07cd694f028e87f85d926aba94 other or lack of unknown components aem-core-wcm-components 2 adobe S3Mock www.github.com/adobe/ 5aa299c2b6d0f0fd00f8d03fda560502270afb82 MAVEN 8 S3Mock 3 alexa alexa-skills- www.github.com/alexa/ bf1e9ccc50d1f3f8408f887f70197ee288fd4bd9 MAVEN 8 kit-sdk-for- alexa-skills-kit-sdk- java for-java 4 alibaba ARouter www.github.com/alibaba/ 93b328569bbdbf75e4aa87f0ecf48c69600591b2 GRADLE unknown ARouter 5 alibaba atlas www.github.com/alibaba/ e8c7b3f1ff14b2a1df64321c6992b796cae7d732 GRADLE unknown atlas 6 alibaba canal www.github.com/alibaba/ 08167c95c767fd3c9879584c0230820a8476a7a7 MAVEN 7 canal 7 alibaba cobar www.github.com/alibaba/