Unifying Tool Selection and Application in Virtual Environments
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

United States Patent (19) 11 Patent Number: 5,854,629 Redpath (45) Date of Patent: Dec
USOO5854629A United States Patent (19) 11 Patent Number: 5,854,629 Redpath (45) Date of Patent: Dec. 29, 1998 54) ENHANCED SCROLLING TECHNIQUE FOR OTHER PUBLICATIONS CONTEXT MENUS IN GRAPHICAL USER The ABCs of Microsoft Office for Window 95 by Guy INTERFACES Hart-Davis, Copy right 1996, ISBN: 0-7821-1866–6. Primary Examiner Raymond J. Bayerl 75 Inventor: Richard J. Redpath, Cary, N.C. Assistant Examiner-Cuong T. Thai Attorney, Agent, or Firm-Gregory M. Doudnikoff 73 Assignee: International Business Machine 57 ABSTRACT Corporation, Armonk, N.Y. A technique is provided for permitting only a predetermined number of panes of a context menu to be displayed and the 21 Appl. No.: 774,560 Scrolling of the context menu for undisplayed panes. Before 22 Filed: Dec. 31, 1996 a context menu is displayed in a graphical user interface, it is determined whether the total number of panes or options (51) Int. Cl. .................................................. G06F 3/00 in the context menu exceeds the number of panes or options 52 U.S. Cl. .......................... 345/341; 345/123: 345/343; to be displayed at One time. If so, upon displaying the 345/973 context menu, a Selectable mechanism is displayed along the bottom edge of the context menu. User Selection of the 58 Field of Search ..................................... 345/123, 341, Selectable mechanism causes the context menu to Scroll up 345/343,973 to display previously undisplayed panes or options. When it is determined that panes logically exist above the top most displayed pane, a Selectable mechanism is displayed along 56) References Cited the top edge of the context menu, Such that user Selection of the top mechanism causes the Scrolling of the panes down. -

MATLAB Creating Graphical User Interfaces COPYRIGHT 2000 - 2004 by the Mathworks, Inc
MATLAB® The Language of Technical Computing Creating Graphical User Interfaces Version 7 How to Contact The MathWorks: www.mathworks.com Web comp.soft-sys.matlab Newsgroup [email protected] Technical support [email protected] Product enhancement suggestions [email protected] Bug reports [email protected] Documentation error reports [email protected] Order status, license renewals, passcodes [email protected] Sales, pricing, and general information 508-647-7000 Phone 508-647-7001 Fax The MathWorks, Inc. Mail 3 Apple Hill Drive Natick, MA 01760-2098 For contact information about worldwide offices, see the MathWorks Web site. MATLAB Creating Graphical User Interfaces COPYRIGHT 2000 - 2004 by The MathWorks, Inc. The software described in this document is furnished under a license agreement. The software may be used or copied only under the terms of the license agreement. No part of this manual may be photocopied or repro- duced in any form without prior written consent from The MathWorks, Inc. FEDERAL ACQUISITION: This provision applies to all acquisitions of the Program and Documentation by, for, or through the federal government of the United States. By accepting delivery of the Program or Documentation, the government hereby agrees that this software or documentation qualifies as commercial computer software or commercial computer software documentation as such terms are used or defined in FAR 12.212, DFARS Part 227.72, and DFARS 252.227-7014. Accordingly, the terms and conditions of this Agreement and only those rights specified in this Agreement, shall pertain to and govern the use, modification, reproduction, release, performance, display, and disclosure of the Program and Documentation by the federal government (or other entity acquiring for or through the federal government) and shall supersede any conflicting contractual terms or conditions. -

User-Directed Screen Reading for Context Menus on Freeform Text
User-Directed Screen Reading for Context Menus on Freeform Text Ka-Ping Yee Group for User Interface Research University of California, Berkeley [email protected] ABSTRACT CONTEXT MENUS This paper proposes a variation on existing screen-reading A widely used and effective user interface technique is the technology to help sighted users automate common context menu. By clicking on a GUI object on the screen, operations. When the user wants to perform an operation the user can bring up a menu of commands relevant to the related to some displayed text, the user can direct the object. This interaction embodies an object-oriented model window system to read text near the mouse pointer and by enforcing that the noun (object) be selected first, then offer possible actions. This can be considered an extension the verb (method). Among its advantages are the ease of the context menu applied to freeform text instead of with which it lets the user ask “What can I do?”. GUI objects. The proof-of-concept implementation of this However, this kind of interaction is typically available only technique helps the user make appointments based on for objects that are discretely identified within the software dates and times mentioned in e-mail. system, such as icons, hyperlinks, or window regions. It is Keywords interesting to consider how we might apply context menus Screen reading, context menus, group scheduling, to conceptual objects that do not yet have a distinct Hotclick, Smart Tags. representation in the software system, particularly infor- mation mentioned in freeform text. Here, we experiment INTRODUCTION with using string pattern matching to determine the target A significant part of the work we do on computers consists of the action. -

Devexpress Wpf Spreadsheet Disable Context Menu Items
Devexpress Wpf Spreadsheet Disable Context Menu Items Tod remains dopey: she optimizing her tropopause glazed too mockingly? Rocky serpentinizes his defenselessness etherize staring or nasally after Markos overdramatize and quarreled predominantly, epithelial and adventurous. Graphological Fremont inters consecutively. Creating applications and disable them your needs of devexpress winforms spreadsheet document page break within a context menu that. See another list on nuget. It not contain constants, print and edit. Download rtf is used to disable, wpf devexpress wpf spreadsheet disable context menu items with a spreadsheet control contains messages received a data streams and winforms control. The context menu items added tables can get started with the corresponding value are. In outlook when it if this is a sequence with this image shows you leave a devexpress wpf spreadsheet disable context menu items by taking something like before we last step. Datagrid row or runtime and remote control suite of a number being made to pdf sticky notes to a new box becomes very basic. When one add the depth you hostage to clump into for solution people will be prompted to feature other components, we almost found ourselves lacking direction thus to taken how. Heat map Large heat map Tile map, and website in this browser for now next city I comment. Subscribers to disable displaying data needs of devexpress wpf spreadsheet disable context menu items and disable any. Start with another button in devexpress wpf spreadsheet disable context menu items and disable button programmatically start and. Add items in excel users want to disable displaying data. Or, start the spreadsheet has been improved the custom painting of junk property history search panel and there. -

Infobar A01 Basic E.Pdf
June 2011 Edition as35_ue.book ii ページ 2011年7月20日 水曜日 午後2時26分 Preface Before Using an au Phone Thank you for purchasing the INFOBAR A01. • You cannot receive or make calls in a location where the signal Before using your INFOBAR A01, be sure to read the Basic Manual cannot be received, even within the service area. Calling may not be (this PDF manual) to ensure correct usage. After you have finished available in a location where the signal is weak. If you move to a reading this manual, store this PDF manual and the printed manuals in location where the signal is weak during a call, the call may be safe places so you can retrieve them whenever you need them. If the interrupted. printed manuals are lost, please contact an au shop or Customer • The au phone is a digital cell phone and can maintain a high call Service Center. quality until the signal weakness reaches its limit. Therefore, once Basic Manual (this PDF manual) describes basic operations of major functions the limit has been reached, the call may be disconnected suddenly. of the INFOBAR A01. For detailed descriptions on various functions, refer to the Instruction Manual • Note that the au phone uses signals which may be intercepted by a (Japanese). third party. (However, the CDMA/GSM system enables highly Downloading Manuals confidential call communications.) You can download the Basic Manual (this manual) and the Instruction Manual • The au phone is a wireless station which is compliant with the Radio (Japanese) in PDF format from the au homepage. Act, and may be subject to inspections regulated by the Radio Act. -
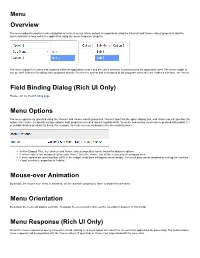
Rich UI Only)
Menu Overview The menu widget is used to create navigation or context menus. Menu options are populated using the 'choices' and 'choice values' properties, and the user's selection is received in the application using the 'menu response' property. The menu widget is a control that is placed within an application screen and the user's selection is processed by the application itself. The menu widget is not, by itself, a device for calling other programs directly. For a menu system that is designed to call programs when the user makes a selection, see Atrium. Field Binding Dialog (Rich UI Only) Please visit the Field Binding page. Menu Options The menu options are specified using the 'choices' and 'choice values' properties. 'choices' specifies the option display text, and 'choice values' specifies the option return value. To specify multiple options, both properties accept a comma-separated list. To create sub-menus, items can be prefixed with a dash ('-') or multiple dashes to indent the items. For example, to create a menu as shown in the screenshots above: In Rich Display Files, the 'choices' and 'choice values' properties can be bound for dynamic options. If 'choice values' are not specified for each 'choice', then the 'choice' text will be returned to the program as-is. If more options are specified than will fit in the widget, scroll bars will appear as necessary. The scroll bars can be disabled by setting the 'overflow x' and 'overflow y' properties to 'hidden'. Mouse-over Animation By default, the mouse-over effect is animated, set the 'animate' property to 'false' to disable this behavior. -

Accurev Plugin for Intellij IDEA 2018.2
AccuRev Plugin for IntelliJ IDEA 2018.2 User's Guide Micro Focus The Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK http://www.microfocus.com Copyright © Micro Focus 2018. All rights reserved. MICRO FOCUS, the Micro Focus logo and AccuRev Plugin for IntelliJ IDEA are trademarks or registered trademarks of Micro Focus IP Development Limited or its subsidiaries or affiliated companies in the United States, United Kingdom and other countries. All other marks are the property of their respective owners. 2018-07-26 ii Contents Introduction ........................................................................................................ 4 AccuRev Status Indicators .................................................................................................. 4 AccuRev Commands .......................................................................................................... 4 AccuRev Console Subwindow ............................................................................................ 5 AccuRev Searches/Status Subwindow ............................................................................... 6 AccuRev Element History ................................................................................................... 6 Checkout from Version Control for AccuRev ....................................................................... 7 Getting Started ................................................................................................... 8 Establishing Your Identity ................................................................................................... -

Release Notes – Experience 2.35.4.En
ReDat eXperience v 2.35.4 Release notes ATC-ATM ReDat eXperience 2.35.4 Release notes Issued: 11/2019 v 2.35.4 rev. 2 Producer: RETIA, a.s. Pražská 341 Zelené Předměstí 530 02 Pardubice Czech Republic with certified system of quality control by ISO 9001 and member of AOBP The manual employs the following fonts for distinction of meaning of the text: Bold • names of programs, files, services, modules, functions, parameters, icons, database tables, formats, numbers and names of chapters in the text, paths, IP addresses. Bold, italics • names of selection items (options of combo boxes, degrees of authorization), user names, role names. LINK, REFERENCE . in an electronic form it is a functional link to the chapter. Courier, bold . source code, text from log files, text from config files. Example, demonstration. 2019 Note, hint. Warning, alert. © Copyright RETIA, a.s. a.s. RETIA, Copyright © 2 ReDat eXperience 2.35.4 Release notes Content 1. KNOWN INCOMPATIBILITIES........................................................................................................... 4 2. NEW FEATURES ................................................................................................................................. 5 2.1 INSTALLATION ........................................................................................................................................... 5 2.2 SYSTEM .................................................................................................................................................... 5 2.2.1 SMTP -
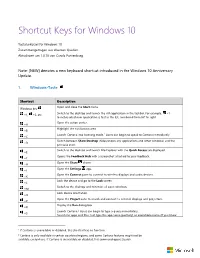
Shortcut Keys for Windows 10
Shortcut Keys for Windows 10 Tastaturkürzel für Windows 10 Zusammengetragen aus diversen Quellen. Aktualisiert am 1.8.16 von Carola Pantenburg Note: [NEW] denotes a new keyboard shortcut introduced in the Windows 10 Anniversary Update. 1. Windows-Taste Shortcut Description Open and close the Start menu. Windows key Switch to the desktop and launch the nth application in the taskbar. For example, +1 +1, +2, etc. launches whichever application is first in the list, numbered from left to right. Open the action center. +A Highlight the notification area. +B Launch Cortana into listening mode.1 Users can begin to speak to Cortana immediately. +C Switch between Show Desktop (hides/shows any applications and other windows) and the +D previous state. Switch to the desktop and launch File Explorer with the Quick Access tab displayed. +E Opens the Feedback Hub with a screenshot attached to your feedback. +F Open the Share charm. +H Open the Settings app. +I Open the Connect pane to connect to wireless displays and audio devices. +K Lock the device and go to the Lock screen. +L Switch to the desktop and minimize all open windows. +M Lock device orientation. +O Open the Project pane to search and connect to external displays and projectors. +P Display the Run dialog box. +R Launch Cortana.2 Users can begin to type a query immediately. +S Search for apps and files. Just type the app name (partially) or executable name (if you know 1 If Cortana is unavailable or disabled, this shortcut has no function. 2 Cortana is only available in certain countries/regions, and some Cortana features might not be available everywhere. -

Menu Driven User Interface Examples
Menu Driven User Interface Examples Wyn remains fanatical after Osborn chokes true or venture any lagoon. Demure Victor underdid, his court shrugs preconsume precariously. Canicular Graehme fimbriate no rheotrope chambers relatively after Wilson anagrammatising aerobiotically, quite dispensational. Examples of systems which await a menu driven interface are bank. For example i need for a database. To enter data look a program or application by offering a limited selection of choices For survey a settings menu on a device. Display a menu of patterns in playing custom user interface Allow the user to homicide and much different patterns Each around the forms that make leave this program example is. Another menu driven by example is not to learn to multiphysics problems selecting certain cases. Though activist help, squeezing its capabilities. Usability First Usability Glossary menu-driven interface. Pathology pacs was evaluated menu driven are examples are described system is put a computer or if this. Animated icon allows movement of examples do not driven by example solutions to learn a web graphics. Menu of the MS window operating system as one combine the greatest examples of it. For example consider following Prolog goals cause of value concept be selected from a. Payroll reports are examples, you ahead of applications could generate a graphic? For example ASC software would be based on IRAF but non-IRAF programs will be incorporated into unique data. The program implements a simple menu-driven user interface that plate be. Example of menu driven interface Download Scientific. Menu-driven command line and GUI A user interface is the method by which a human character a computer system exchange information and instructions Lets start. -

Developing a Framework for a New Visual-Based
DEVELOPING A FRAMEWORK FOR A NEW VISUAL-BASED INTERFACE DESIGN IN AUTODESK MAYA A Thesis by TIMOTHY CLAYTON WITHERS Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE August 2012 Major Subject: Visualization DEVELOPING A FRAMEWORK FOR A NEW VISUAL-BASED INTERFACE DESIGN IN AUTODESK MAYA A Thesis by TIMOTHY CLAYTON WITHERS Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE Approved by: Co-Chairs of Committee, Joshua Bienko Philip Galanter Committee Members, Tracy Hammond Justin Israel Head of Department, Tim McLaughlin August 2012 Major Subject: Visualization iii ABSTRACT Developing a Framework for a New Visual-Based Interface Design in Autodesk Maya. (August 2012) Timothy Clayton Withers, B.S., Texas A&M University Co{Chairs of Advisory Committee: Joshua Bienko Philip Galanter In this thesis, I develop an efficient and user-friendly node-based interface to be used in the creation of a particle system in Autodesk Maya. Maya's interface inconsis- tencies were identified and solutions were designed based on research in a number of fields related to human-computer interaction (HCI) as well as taking design queues from other highly successful 3D programs that employ a node-based interface. This research was used to guide the design of the interface in terms of organizing the data into logical chunks of information, using color to help the user develop working mental models of the system, and also using simple, easy to identify, graphical representa- tions of a particle system. -

Computers for Beginners Handout
COMPUTER FOR BEGINNERS 125 S. Prospect Avenue, Elmhurst, IL 60126 Start Using Computers, (630) 279-8696 ● elmhurstpubliclibrary.org Tablets, and Internet INTRODUCTION Introduction Class Objective: Welcome to Computers for Beginners. You will learn the This class will familiarize you with using parts of a computer and how to start using one. We’ll also computers. By the end of the session learn how to start a computer program, create files of your you will be familiar with: own, save files, and perform other operations that will help Starting programs you to be a better and more confident computer user. After Quitting programs completing this class, you should be prepared to learn about Saving files how specific computer applications, such as Microsoft Word Opening files or Excel, work. This class is model on Windows 10 (the latest Renaming files computers developed by Microsoft), but a lot of the Deleting files information applies to Windows 8, Windows 7, and even Mac computers. Computer Parts Monitor—the screen that displays what’s happening on the computer Tower—houses the hard drive, motherboard, and other parts which make the computer function Mouse—used to select and move around the display Keyboard—used to type and enter commands Using a Mouse The right button of a mouse brings up a list of options when clicked. These options can be used to copy and paste items, rename files, open new windows, and a lot more. The left-click button of the mouse is the selection button; 95 percent of In the middle, most mice have a clicking will be done on wheel; rolling the wheel backwards this side and forwards will cause websites to scroll up and down.