Percona Tokudb Documentation Release 7.5.7
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Data Platforms Map from 451 Research
1 2 3 4 5 6 Azure AgilData Cloudera Distribu2on HDInsight Metascale of Apache Kaa MapR Streams MapR Hortonworks Towards Teradata Listener Doopex Apache Spark Strao enterprise search Apache Solr Google Cloud Confluent/Apache Kaa Al2scale Qubole AWS IBM Azure DataTorrent/Apache Apex PipelineDB Dataproc BigInsights Apache Lucene Apache Samza EMR Data Lake IBM Analy2cs for Apache Spark Oracle Stream Explorer Teradata Cloud Databricks A Towards SRCH2 So\ware AG for Hadoop Oracle Big Data Cloud A E-discovery TIBCO StreamBase Cloudera Elas2csearch SQLStream Data Elas2c Found Apache S4 Apache Storm Rackspace Non-relaonal Oracle Big Data Appliance ObjectRocket for IBM InfoSphere Streams xPlenty Apache Hadoop HP IDOL Elas2csearch Google Azure Stream Analy2cs Data Ar2sans Apache Flink Azure Cloud EsgnDB/ zone Platforms Oracle Dataflow Endeca Server Search AWS Apache Apache IBM Ac2an Treasure Avio Kinesis LeanXcale Trafodion Splice Machine MammothDB Drill Presto Big SQL Vortex Data SciDB HPCC AsterixDB IBM InfoSphere Towards LucidWorks Starcounter SQLite Apache Teradata Map Data Explorer Firebird Apache Apache JethroData Pivotal HD/ Apache Cazena CitusDB SIEM Big Data Tajo Hive Impala Apache HAWQ Kudu Aster Loggly Ac2an Ingres Sumo Cloudera SAP Sybase ASE IBM PureData January 2016 Logic Search for Analy2cs/dashDB Logentries SAP Sybase SQL Anywhere Key: B TIBCO Splunk Maana Rela%onal zone B LogLogic EnterpriseDB SQream General purpose Postgres-XL Microso\ Ry\ X15 So\ware Oracle IBM SAP SQL Server Oracle Teradata Specialist analy2c PostgreSQL Exadata -

In Mysql/Mariadb?
T h e O W A S P F o u n d a t i o n h t t p : / / w w w . o w a s p . o r g O W A S P E U T o u r B u c h a Do you r e s“GRANT ALL PRIVILEGES” t ... in MySQL/MariaDB? 2 0 1 DevOps Engineer 3 Gabriel PREDA [email protected] @eRadical Co pyr igh t © Th e O W AS P Fo un dat ion Per mi ssi on is gr ant ed to co py, dis tri bu te an d/ or mo dif y thi s do cu me nt un de r the ter ms of the O W AS P Lic en se. 2 DevOps = new BORG DevOps Engineer ??? ● Development – Web Applications (“Certified MySQL Associate”, “Zend Certified Engineer”) – Real Time Analytics ● Operations – MySQL DBA (15+ instances) – Sysadmin (<25 virtual & physical servers) 3 My MySQL● Over 15 MariaDB / TokuDBMariaDB(s) instances ● Statistics in MariaDB – < 1TB from Oct 2012 – < 12G raw data daily – < 12,000,000 events processed daily – < 90,000,000 rows added daily BigData? NO!!! ● I can copy all of that to my laptop ● “Working data set” - less than 1G & less than 7,500,000 rows 4 MySQL History ● 1983 – first version of MySQL created by Monty Wideniuns ● 1994 – MySQL is released OpenSource ● 2004 Oct – MySQL 4.1 GA ● 2005 Oct – InnoDB (Innobase) is bought by Oracle – Black Friday ● 2008 Ian – MySQL AB is bought by Sun (1bn $) ● 2008 Nov – MySQL 5.1 GA ● 2009 Apr – Sun is bought by Oracle (7,4 bn $) ● 2010 Dec – MySQL 5.5 GA ● 2012 Apr – MariaDB 5.5 GA ● 2013 Feb – MySQL 5.6 – first version made by Oracle ● 2013 Feb – MySQL will be replaced by MariaDB in Fedora & OpenSuSE * Max Mether – SkySQL “MySQL and MariaDB: Past, Present and Future” 5 Where are we NOW()? Drizzle MySQL TokuDB (Oracle) (Tokutek) Percona Server (Percona) MariaDB (Monty Program, Brighthouse MariaDB Foundation) (Infobright) Replication: ● Asynchronous InfiniDB ● Semi-synchronous (Calpont) ● Galera Synchronous (Codership) ● Tungsten Replication (Continuent) 6 Elementary.. -

Mariadb Viable Mysql Replacement Scale12x.Pdf
MariaDB: Viable MySQL replacement Colin Charles, Team MariaDB, SkySQL Ab [email protected] | [email protected] http://mariadb.org/ http://bytebot.net/blog/ | @bytebot on Twitter SCALE12x, Los Angeles, California, USA 22 February 2014 Sunday, 23 February 14 whoami • Work on MariaDB at SkySQL Ab • Merged with Monty Program Ab, makers of MariaDB • Formerly MySQL AB (exit: Sun Microsystems) • Past lives include Fedora Project (FESCO), OpenOffice.org • MHA experience • since November 2011 (MHA 0.52, 0.53) • NRE work to make it run in a Solaris 10 environment... with no Internet access! • Continued deployment advice + work for data centre use • Much thanks to SkySQL for the experience Sunday, 23 February 14 MySQL? Percona Server? MariaDB? Sunday, 23 February 14 Agenda • 4 years: major server releases (5.1, 5.2, 5.3, 5.5, 5.5+TokuDB, Galera Cluster) and 10.0 series • Delving into history of previous releases • MariaDB 10.0 • Client libraries, Galera Cluster • Roadmap Sunday, 23 February 14 What isn’t covered • MariaDB Enterprise • Galera Cluster + GUI + API • mariadb.com • SkySQL • trademarks... Sunday, 23 February 14 What is MariaDB? • Community developed branch of MySQL • Feature enhanced • Fully compatible & feature complete with MySQL Sunday, 23 February 14 Backed by MariaDB Foundation • Driver of the MariaDB project • Foundation not controlled by single entity/ person; has a Board • Ensure MariaDB is compatible with MySQL, maintain mariadb.org, keep community voice • Major sponsors: SkySQL, Parallels, Booking.com, Automattic, OpenQuery, Percona, -

Data Management Organization Charter
Large Synoptic Survey Telescope (LSST) Database Design Jacek Becla, Daniel Wang, Serge Monkewitz, K-T Lim, Douglas Smith, Bill Chickering LDM-135 08/02/2013 LSST Database Design LDM-135 08/02/13 Change Record Version Date Description Revision Author 1.0 6/15/2009 Initial version Jacek Becla 2.0 7/12/2011 Most sections rewritten, added scalability test Jacek Becla section 2.1 8/12/2011 Refreshed future-plans and schedule of testing Jacek Becla, sections, added section about fault tolerance Daniel Wang 3.0 8/2/2013 Synchronized with latest changes to the Jacek Becla, requirements (LSE-163). Rewrote most of the Daniel Wang, “Implementation” chapter. Documented new Serge Monkewitz, tests, refreshed all other chapters. Kian-Tat Lim, Douglas Smith, Bill Chickering 2 LSST Database Design LDM-135 08/02/13 Table of Contents 1. Executive Summary.....................................................................................................................8 2. Introduction..................................................................................................................................9 3. Baseline Architecture.................................................................................................................10 3.1 Alert Production and Up-to-date Catalog..........................................................................10 3.2 Data Release Production....................................................................................................13 3.3 User Query Access.............................................................................................................13 -
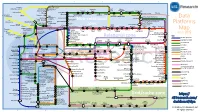
Data Platforms
1 2 3 4 5 6 Towards Apache Storm SQLStream enterprise search Treasure AWS Azure Apache S4 HDInsight DataTorrent Qubole Data EMR Hortonworks Metascale Lucene/Solr Feedzai Infochimps Strao Doopex Teradata Cloud T-Systems MapR Apache Spark A Towards So`ware AG ZeUaset IBM Azure Databricks A SRCH2 IBM for Hadoop E-discovery Al/scale BigInsights Data Lake Oracle Big Data Cloud Guavus InfoSphere CenturyLink Data Streams Cloudera Elas/c Lokad Rackspace HP Found Non-relaonal Oracle Big Data Appliance Autonomy Elas/csearch TIBCO IBM So`layer Google Cloud StreamBase Joyent Apache Hadoop Platforms Oracle Azure Dataflow Data Ar/sans Apache Flink Endeca Server Search AWS xPlenty zone IBM Avio Kinesis Trafodion Splice Machine MammothDB Presto Big SQL CitusDB Hadapt SciDB HPCC AsterixDB IBM InfoSphere Starcounter Towards NGDATA SQLite Apache Teradata Map Data Explorer Firebird Apache Apache Crate Cloudera JethroData Pivotal SIEM Tajo Hive Drill Impala HD/HAWQ Aster Loggly Sumo LucidWorks Ac/an Ingres Big Data SAP Sybase ASE IBM PureData June 2015 Logic for Analy/cs/dashDB Logentries SAP Sybase SQL Anywhere Key: B TIBCO EnterpriseDB B LogLogic Rela%onal zone SQream General purpose Postgres-XL Microso` vFabric Postgres Oracle IBM SAP SQL Server Oracle Teradata Specialist analy/c Splunk PostgreSQL Exadata PureData HANA PDW Exaly/cs -as-a-Service Percona Server MySQL MarkLogic CortexDB ArangoDB Ac/an PSQL XtremeData BigTables OrientDB MariaDB Enterprise MariaDB Oracle IBM Informix SQL HP NonStop SQL Metamarkets Druid Orchestrate Sqrrl Database DB2 Server -

Alibaba Cloud Apsaradb for Mysql
Alibaba Cloud ApsaraDB for MySQL User Guide Issue: 20190909 ApsaraDB for MySQL User Guide / Legal disclaimer Legal disclaimer Alibaba Cloud reminds you to carefully read and fully understand the terms and conditions of this legal disclaimer before you read or use this document. If you have read or used this document, it shall be deemed as your total acceptance of this legal disclaimer. 1. You shall download and obtain this document from the Alibaba Cloud website or other Alibaba Cloud-authorized channels, and use this document for your own legal business activities only. The content of this document is considered confidential information of Alibaba Cloud. You shall strictly abide by the confidentiality obligations. No part of this document shall be disclosed or provided to any third party for use without the prior written consent of Alibaba Cloud. 2. No part of this document shall be excerpted, translated, reproduced, transmitted, or disseminated by any organization, company, or individual in any form or by any means without the prior written consent of Alibaba Cloud. 3. The content of this document may be changed due to product version upgrades , adjustments, or other reasons. Alibaba Cloud reserves the right to modify the content of this document without notice and the updated versions of this document will be occasionally released through Alibaba Cloud-authorized channels. You shall pay attention to the version changes of this document as they occur and download and obtain the most up-to-date version of this document from Alibaba Cloud-authorized channels. 4. This document serves only as a reference guide for your use of Alibaba Cloud products and services. -

Percona Xtrabackup 2.4 Documentation Release 2.4.20
Percona XtraBackup 2.4 Documentation Release 2.4.20 Percona LLC and/or its affiliates Apr 14, 2020 CONTENTS I Introduction2 II Installation8 III Prerequisites 16 IV Backup Scenarios 20 V User’s Manual 33 VI Advanced Features 91 VII Tutorials, Recipes, How-tos 100 VIII References 122 IX Indices and tables 149 i Percona XtraBackup 2.4 Documentation, Release 2.4.20 Percona XtraBackup is an open-source hot backup utility for MySQL - based servers that doesn’t lock your database during the backup. It can back up data from InnoDB, XtraDB, and MyISAM tables on MySQL 5.11, 5.5, 5.6 and 5.7 servers, as well as Percona Server for MySQL with XtraDB. For a high-level overview of many of its advanced features, including a feature comparison, please see About Percona XtraBackup. Whether it is a 24x7 highly loaded server or a low-transaction-volume environment, Percona XtraBackup is designed to make backups a seamless procedure without disrupting the performance of the server in a production environment. Commercial support contracts are available. Important: Percona XtraBackup 2.4 does not support making backups of databases created in MySQL 8.0, Percona Server for MySQL 8.0 or Percona XtraDB Cluster 8.0. 1 Support for InnoDB 5.1 builtin has been removed in Percona XtraBackup 2.1 CONTENTS 1 Part I Introduction 2 CHAPTER ONE ABOUT PERCONA XTRABACKUP Percona XtraBackup is the world’s only open-source, free MySQL hot backup software that performs non-blocking backups for InnoDB and XtraDB databases. With Percona XtraBackup, you can achieve the following benefits: • Backups that complete quickly and reliably • Uninterrupted transaction processing during backups • Savings on disk space and network bandwidth • Automatic backup verification • Higher uptime due to faster restore time Percona XtraBackup makes MySQL hot backups for all versions of Percona Server for MySQL, MySQL, and MariaDB. -

LSM-Tree Database Storage Engine Serving Facebook's Social Graph
MyRocks: LSM-Tree Database Storage Engine Serving Facebook's Social Graph Yoshinori Matsunobu Siying Dong Herman Lee Facebook Facebook Facebook [email protected] [email protected] [email protected] ABSTRACT Facebook uses MySQL to manage tens of petabytes of data in its 1. INTRODUCTION main database named the User Database (UDB). UDB serves social The Facebook UDB serves the most important social graph activities such as likes, comments, and shares. In the past, Facebook workloads [3]. The initial Facebook deployments used the InnoDB storage engine using MySQL as the backend. InnoDB was a robust, used InnoDB, a B+Tree based storage engine as the backend. The challenge was to find an index structure using less space and write widely used database and it performed well. Meanwhile, hardware amplification [1]. LSM-tree [2] has the potential to greatly improve trends shifted from slow but affordable magnetic drives to fast but these two bottlenecks. RocksDB, an LSM tree-based key/value more expensive flash storage. Transitioning to flash storage in UDB store was already widely used in variety of applications but had a shifted the bottleneck from Input/Output Operations Per Second very low-level key-value interface. To overcome these limitations, (IOPS) to storage capacity. From a space perspective, InnoDB had MyRocks, a new MySQL storage engine, was built on top of three big challenges that were hard to overcome, index RocksDB by adding relational capabilities. With MyRocks, using fragmentation, compression inefficiencies, and space overhead per the RocksDB API, significant efficiency gains were achieved while row (13 bytes) for handling transactions. -

Mysql Storage Engine Comparison Guide June 2009
MySQL Storage Engine Comparison Guide June 2009 Copyright 2009, Sun Microsystems Page: 1 Table of Contents Introduction...................................................................................................................................... 3 Key Storage Engine Differentiation Points ...................................................................................... 3 MySQL/Sun Developed Engines.....................................................................................................4 Archive ......................................................................................................................................... 4 Blackhole...................................................................................................................................... 5 CSV.............................................................................................................................................. 6 Falcon .......................................................................................................................................... 7 Federated..................................................................................................................................... 8 Memory ........................................................................................................................................ 9 Merge ......................................................................................................................................... 10 MyISAM..................................................................................................................................... -

The Mysql-Mariadb Story
Michael Widenius, Entrepreneur The MySQL-MariaDB story Haaga-Helia, September 4, 2013 Michael “Monty” Widenius Entrepreneur, MariaDB hacker [email protected] http://mariadb.org/ Notice: MySQL is a registered trademark of Sun Microsystems, Inc. Questions addressed in talk 1) Brief MySQL & MariaDB history 2) What challenges did you face in the beginning and how did you overcome them? Eg Convincing early employees to join you, raising seed & venture capital etc. 3) How did you handle the growth of your venture? 4) Liquidity event. 5) End of story (or is it?) 6)Where is MariaDB today 7)Features of the different MariaDB releases 8)Challenges faced while creating MariaDB 9)Reasons for the success Notice: MySQL is a registered trademark of Sun Microsystems, Inc. The origin of My (SQL) At start: Lots of traveling and meeting interesting people Notice: MySQL is a registered trademark of Sun Microsystems, Inc. The origin of My (SQL) Combined with working from home Notice: MySQL is a registered trademark of Sun Microsystems, Inc. The origin of My (SQL) Things were good Notice: MySQL is a registered trademark of Sun Microsystems, Inc. The origin of Max (DB) We also made a MaxDB (based on SAP DB) and MySQL-max Notice: MySQL is a registered trademark of Sun Microsystems, Inc. The origin of My (SQL) Even if there were some growing pains Notice: MySQL is a registered trademark of Sun Microsystems, Inc. The origin of My (SQL) Then we came into strange company Notice: MySQL is a registered trademark of Sun Microsystems, Inc. The origin of My (SQL) Which scared some of us a bit.. -

Alibaba Cloud Apsara Stack Agility SE
Alibaba Cloud Apsara Stack Agility SE Technical Whitepaper Version: 1912, Internal: V3.1.0 Issue: 20200311 Technical Whitepaper / Legal disclaimer Legal disclaimer Alibaba Cloud reminds you to carefully read and fully understand the terms and conditions of this legal disclaimer before you read or use this document. If you have read or used this document, it shall be deemed as your total acceptance of this legal disclaimer. 1. You shall download and obtain this document from the Alibaba Cloud website or other Alibaba Cloud-authorized channels, and use this document for your own legal business activities only. The content of this document is considered confidential information of Alibaba Cloud. You shall strictly abide by the confidentiality obligations. No part of this document shall be disclosed or provided to any third party for use without the prior written consent of Alibaba Cloud. 2. No part of this document shall be excerpted, translated, reproduced, transmitted , or disseminated by any organization, company, or individual in any form or by any means without the prior written consent of Alibaba Cloud. 3. The content of this document may be changed due to product version upgrades , adjustments, or other reasons. Alibaba Cloud reserves the right to modify the content of this document without notice and the updated versions of this document will be occasionally released through Alibaba Cloud-authorized channels. You shall pay attention to the version changes of this document as they occur and download and obtain the most up-to-date version of this document from Alibaba Cloud-authorized channels. 4. This document serves only as a reference guide for your use of Alibaba Cloud products and services. -

The Mysql Diaspora Scale10x.Pdf
The MySQL Diaspora Colin Charles, Monty Program Ab [email protected] http://montyprogram.com / http://mariadb.org/ http://bytebot.net/blog / @bytebot on Twitter SCALE10x, Los Angeles, CA, USA 21 January 2012 Friday, 27 January 12 whoami • Chief Evangelist, MariaDB • Formerly of MySQL AB/Sun Microsystems • Past lives included FESCO (Fedora Project), OpenOffice.org Friday, 27 January 12 Agenda • The MySQL-based servers • Patches for new features • MySQL tools • MySQL Cluster • Support Friday, 27 January 12 MySQL release policy • Alpha • Beta • GA - generally available • Labs • Developer Milestone Releases (DMR) Friday, 27 January 12 MySQL through the years MySQL MySQL Sun Oracle Sun Oracle AB AB 3.23 5.1 5.5 5.1 5.2 5.4 4.0 5.2 5.4 6.0 4.1 6.0 6.0 5.6 5.0 GA Plans & Cancellations Friday, 27 January 12 Where do you get MySQL from? • mysql.com • Over 55%-60% of 70,000 daily downloads are Microsoft Windows based • your distribution of choice • Linux, BSD, Mac • packaged w/o many engines built-in Friday, 27 January 12 The commercial ecosystem • Storage engines had an API since 5.1... being pluggable, there were also commercial engines available • InfoBright, TokuDB, ScaleDB, Calpont, Nitro, SolidDB, RitmarkFS, etc. • Hardware vendors too: Kickfire, Virident, Schooner, etc. Friday, 27 January 12 Let’s define: • Fork • Branch Friday, 27 January 12 Forks Friday, 27 January 12 Drizzle • 64-bit only, *nix only • Micro-kernel architecture • Stripped out MySQL 6.0 to focus on everything as a plugin • All C++ now • Focus on the cloud (small plug-in