An Assessment of Media Consumers' Ability to Distinguish the Level of Post-Processing in Journalistic Images
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Flying High Into Cherry Blossom Season | Vancouver
Shopping | Obituaries | Horoscopes | Lotteries Find a business or person Overcast 17 MORE SUBSCRIBE Subscriber Services ePaper eStore Place an Ad Log in Register LIKE IT BUY IT FEATURED PHOTOS GET HUGE RICHMOND DISCOUNTS ON SUPER-SIZED TRAVEL HOMES NEWS OPINION BUSINESS SPORTS ENTERTAINMENT LIFE HEALTH TECHNOLOGY TRAVEL CAREERS DRIVING HOMES CLASSIFIEDS VANCOUVER SUN STAFF BLOGS VANCOUVER SUN COMMUNITY BLOGS / STAFF / Life / Gardening / IN THE GARDEN Flying high into cherry blossom season March 26, 2015. 12:28 pm • Section: In the Garden 1 1 0 IN OTHER NEWS Egan Davis flying his cherry blossom kite. Surrey dad with cancer ordered to be deported from Canada Increase Font Size Vaughn Palmer: Shabby treatment for a ‘very quality Print Page individual’ RSS Feed Justin Bieber's former neighbour sues for assault and trespass over spitting, egging incidents TED2015: Monica Lewinsky speaks out against ‘culture of Posted by: humiliation’ steve Jeremy Shaw goes backward and forward into the present whysall at CAG 4 Reasons to buy a new Apple MacBook (and one rea$on RECENT POSTS FROM you may not) THIS AUTHOR Flying high into cherry blossom season FROM AROUND THE WEB Posted on Mar 26, 2015 There Are 7 Types of English Surnames — Which One Is Up Close: Deluxe Garden Yours? (Ancestry.ca) Tool Collection Police beating caught on video prompts Michigan protests (with video) (Home - BBC News) Posted on Mar 19, 2015 Egan Davis with cherry blossom kite DNA Testing Solves Mystery of Young Girl Who Up Close: Three Disappeared on Titanic (Ancestry.ca) Muskateers Asiatic Lily Romantic Story: Son Takes A Photo Of His Old Parents Collection (with video) First, we need to set the record straight: there will be cherry blossoms, lots and lots of Every Year. -

56886NCJRS.Pdf
If you have issues viewing or accessing this file contact us at NCJRS.gov. POLICE MISCONDUCT - CANADA: a bibliography, Compiled by the R.C.M.P. H.Q. Library Reference Staff 1'1 Ottawa January 1979 INTRODUCTION The bibliography "Police Misconduct - Canada" is divided into two sections. The first lists articles which have been indexed in Canadian Newspaper Indes from January 1977 to October 1978. The second lists entries found • in the House of Commons Debates for the period January 1977 through June 1978. PART I i POLICE MISCONDUCT ~ GANADA (Articles selected from Canadian Newspaper Index) TABLE OF CONTENTS 1. Police (General) ...... ~ •••• 11 •• I; ••••••••••••••••••••• p.l 2. British-Columbia - Police forces • :I ••••••••• 00 ••••••• p.3 3. Manitoba - Police forces •••••••••• It •• '" •••••••• II •••• p.5 4. Ontario - Police forces i) General . .. p.7 ii) Toronto • • ., II "I 8 ... p.9 . iii) Vanier • 0 •• III . .. p.15 5. Quebec - Police forces • •••• II •••••••••••• G. •••••••• « • p.17 6. New Brunswick Police forces ••••••• " •••••• It ...... 0 • p.18 7. Prince Edward Island - Police forces ••••••••• e ••• p.19 8. RCMP Agence de Presse Libre break-in • ...... II •••••• p.20 9. .RCMP Arson & theft p.25 10. RCMP Break-ins • •• " ••• It ••••••••••• a ............... p.27 11. RCMP Bugging ••• II •••••••• II •••••••••• It e.. •••••••••••• p.30 12. RCMP Faked FLQ Communique II •••• II • II ,. ••••••••••••••• p.32 13. RCMP Former RCMP Samson .......... II ...... " ••••••••••• p.33 14. RCMP - Illegal activities i) General . " p.::35 ii) Spying .......... p.:37 iii) Raids p.38 iv) Lies .•.•.. p.39 v) Assaults .... • , ., • II • p.40 vi) Threats ..•• ... p.41 15. RCMP Laycraft inquiry ••••••••••• CI ••• II •••• at •••• p.42 16. -

Scandals Hamper Harper's Plans (With Video)
Shopping Obituaries Horoscopes Lotteries | | | Search vancouversun.com... Light rain 14 MORE SUBSCRIBE Subscriber Services ePaper eStore Place an Ad Log in Register JOBS ONLINE NOW B.C.'S BEST- AND COOL NORTH WORST-PAYING ... VAN HOME WSEN NOINIPO SSENISUB STROPS TNEMNIATRETNE EFIL HTLAEH YGOLONHCET LEVART SBOJ GNIVIRD SEMOH SDEIFISSALC Scandals hamper Harper's plans (with video) C onservatives have a rough ride ahead sorting out numerous recent catastrophes and dousing political fires B Y MICHAEL DEN TANDT, POSTMEDIA NEWS MAY 30, 2013 2:46 PM Recommend 0 Tweet 0 0 STORY PHOTOS ( 1 ) VIDEO ( 1 ) IN OTHER NEWS Alberta chef dies after competing at culinary championship in Kelowna You need to have the Adobe Flash Player to view this content. Fisherman dies of bite wounds after beaver attack in Please click here to continue. Belarus Facts about Mike Duffy deal ‘not good, but they are clear,’ Harper says Man pleads guilty to killing estranged wife, companion at Richmond McDonald's Bacon brothers ‘had it made and chose another path’ FROM AROUND THE WEB Learn What Vanessa Williams Discovered About Her Family History by Taking a DNA Test (Ancestry) Sarah Palin's New Hairstyle Looks Strangely Familiar - Stephen Harper says while the facts in the Sen. Mike Duffy scandal are not good, they are clear. The prime minister says he - Who Do You Think She Copied? (PHOTO) didn't know of his former chief of staff's payment to the senator until the media reported it. (MamasLatinas) 22 Things You Should Never Do Again After 50 (AARP) SEAL Team Fix: How Ambien Helped Sack Osama bin In Ottawa, the opposition parties are suddenly in a jam, unlike any MORE ON THIS STORY Laden (Vice) they've encountered in seven-plus years of Harper government. -
Cotwsupplemental Appendix Fin
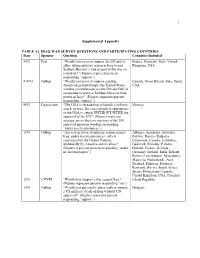
1 Supplemental Appendix TABLE A1. IRAQ WAR SURVEY QUESTIONS AND PARTICIPATING COUNTRIES Date Sponsor Question Countries Included 4/02 Pew “Would you favor or oppose the US and its France, Germany, Italy, United allies taking military action in Iraq to end Kingdom, USA Saddam Hussein’s rule as part of the war on terrorism?” (Figures represent percent responding “oppose”) 8-9/02 Gallup “Would you favor or oppose sending Canada, Great Britain, Italy, Spain, American ground troops (the United States USA sending ground troops) to the Persian Gulf in an attempt to remove Saddam Hussein from power in Iraq?” (Figures represent percent responding “oppose”) 9/02 Dagsavisen “The USA is threatening to launch a military Norway attack on Iraq. Do you consider it appropriate of the USA to attack [WITHOUT/WITH] the approval of the UN?” (Figures represent average across the two versions of the UN approval question wording responding “under no circumstances”) 1/03 Gallup “Are you in favor of military action against Albania, Argentina, Australia, Iraq: under no circumstances; only if Bolivia, Bosnia, Bulgaria, sanctioned by the United Nations; Cameroon, Canada, Columbia, unilaterally by America and its allies?” Denmark, Ecuador, Estonia, (Figures represent percent responding “under Finland, France, Georgia, no circumstances”) Germany, Iceland, India, Ireland, Kenya, Luxembourg, Macedonia, Malaysia, Netherlands, New Zealand, Pakistan, Portugal, Romania, Russia, South Africa, Spain, Switzerland, Uganda, United Kingdom, USA, Uruguay 1/03 CVVM “Would you support a war against Iraq?” Czech Republic (Figures represent percent responding “no”) 1/03 Gallup “Would you personally agree with or oppose Hungary a US military attack on Iraq without UN approval?” (Figures represent percent responding “oppose”) 2 1/03 EOS-Gallup “For each of the following propositions tell Austria, Belgium, Bulgaria, me if you agree or not. -

2021 Ownership Groups - Canadian Daily Newspapers (74 Papers)
2021 Ownership Groups - Canadian Daily Newspapers (74 papers) ALTA Newspaper Group/Glacier (3) CN2i (6) Independent (6) Quebecor (2) Lethbridge Herald # Le Nouvelliste, Trois-Rivieres^^ Prince Albert Daily Herald Le Journal de Montréal # Medicine Hat News # La Tribune, Sherbrooke^^ Epoch Times, Vancouver Le Journal de Québec # The Record, Sherbrooke La Voix de l’Est, Granby^^ Epoch Times, Toronto Le Soleil, Quebec^^ Le Devoir, Montreal Black Press (2) Le Quotidien, Chicoutimi^^ La Presse, Montreal^ SaltWire Network Inc. (4) Red Deer Advocate Le Droit, Ottawa/Gatineau^^ L’Acadie Nouvelle, Caraquet Cape Breton Post # Vancouver Island Free Daily^ Chronicle-Herald, Halifax # The Telegram, St. John’s # Brunswick News Inc. (3) The Guardian, Charlottetown # Times & Transcript, Moncton # Postmedia Network Inc./Sun Media (33) The Daily Gleaner, Fredericton # National Post # The London Free Press Torstar Corp. (7) The Telegraph-Journal, Saint John # The Vancouver Sun # The North Bay Nugget Toronto Star # The Province, Vancouver # Ottawa Citizen # The Hamilton Spectator Continental Newspapers Canada Ltd.(3) Calgary Herald # The Ottawa Sun # Niagara Falls Review Penticton Herald The Calgary Sun # The Sun Times, Owen Sound The Peterborough Examiner The Daily Courier, Kelowna Edmonton Journal # St. Thomas Times-Journal St. Catharines Standard The Chronicle Journal, Thunder Bay The Edmonton Sun # The Observer, Sarnia The Tribune, Welland Daily Herald-Tribune, Grande Prairie The Sault Star, Sault Ste Marie The Record, Grand River Valley F.P. Canadian Newspapers LP (2) The Leader-Post, Regina # The Simcoe Reformer Winnipeg Free Press The StarPhoenix, Saskatoon # Beacon-Herald, Stratford TransMet (1) Brandon Sun Winnipeg Sun # The Sudbury Star Métro Montréal The Intelligencer, Belleville The Daily Press, Timmins Glacier Media (1) The Expositor, Brantford The Toronto Sun # Times Colonist, Victoria # The Brockville Recorder & Times The Windsor Star # The Chatham Daily News The Sentinel Review, Woodstock Globe and Mail Inc. -

Vancouver Sun Fake Edition of Sun Sets Off Lawsuit; Canwest Launches Legal Action Against Activist, Local Printing Company
Vancouver Sun Fake edition of Sun sets off lawsuit; CanWest launches legal action against activist, local printing company Saturday, December 8, 2007 Page: B11 Section: Westcoast News Byline: Doug Ward Dateline: VANCOUVER Source: Vancouver Sun VANCOUVER - The owner of The Vancouver Sun has launched a lawsuit against a pro-Palestinian activist and a local printing company over the [email protected] publication of a fake edition of the daily newspaper. A writ of summons filed by CanWest Mediaworks Publications alleges that long-time left-wing activist Mordecai Briemberg, other unidentified activists and Horizon Publications conspired to produce and distribute a phoney edition of The Vancouver Sun on June 7, 2007. The defendants distributed about 12,000 copies of the fake newspaper in Vancouver, Victoria and at the University of B.C. "We take this matter very seriously. We did say that we would follow up, and I believe our customers expect us to," Vancouver Sun publisher Kevin Bent said about the suit. The CanWest writ also alleges the defendants published the content of the fake newspaper on various websites. The suit said the defendants were "motivated by hostility to the principal shareholders of the plaintiff and by a desire to undermine, or hurt, the business of the plaintiff and its principal shareholders." The plaintiff's writ, submitted by lawyer David Church, said Briemberg and six other unidentified people are involved in anti-Israeli, pro-Palestinian media activities. The writ alleges that the defendants "harbour antagonistic views towards the plaintiff, its principal shareholders and the reporting and editorial opinions expressed in the plaintiff's publications, including in The Vancouver Sun." The writ also names Horizon general manager Garth Leddy as a defendant. -
Postmedia B No Emails.Csv
National Post First Last Works for Beat email Phone City Sadaf Ahsan National Post Celebrities; Internet; MotionN/A Pictures1(416) 383-2300 Toronto Bert Archer National Post Travel N/A 1(416) 383-2300 Toronto Stewart Bell National Post National Security N/A 1(416) 383-2300 Toronto Elisa Birnbaum National Post Business; Entrepreneurs;N/A Social Issues1(416) 383-2300 Toronto Mary TeresaBitti National Post Business; EntrepreneursN/A (905) 257-1651 Toronto Tom Blackwell National Post Health and Wellness; MedicalN/A 1(416) 383-2394 Toronto Christie Blatchford National Post Breaking News N/A 1(416) 383-2300 Toronto David Booth National Post Automobiles N/A 1(416) 510-6744 Toronto Joseph Brean National Post National News N/A 1(416) 383-2312 Toronto Laura Brehaut National Post Beverages; Culture; Food;N/A Internet;1(416) Recipes 442-2907 Toronto Kevin Carmichael National Post Business N/A 1(416) 383-2300 Montreal Claudia Cattaneo National Post Business; Energy N/A 1(403) 235-7375 Toronto Terence Corcoran National Post Business N/A 1(416) 383-2381 Toronto Colby Cosh National Post Art; Automobiles; BreakingN/A News;1(780) Culture; 433-0976 Economy/EconomicEdmonton Issues; Financial; Health and Wellness; Law; Medical; Meteorology; Sports Andrew Coyne National Post Canada; National News; N/APolitics 1(416) 383-2420 Toronto Raymond De Souza National Post Religion N/A 1(416) 383-2300 Toronto Aileen Donnelly National Post Internet N/A 1(416) 383-2300 Toronto Jake Edmiston National Post Electronics; Software ApplicationsN/A 1(416) 386-2692 Toronto Victor -

Canwest and Free Speech
Title of Resolution: Resolution on CanWest and Free Speech Rationale / Purpose for Resolution: CanWest is suing local activist Mordecai Briemberg over a parody of the Vancouver Sun, even though Briemberg had nothing to do with creating the parody. Due to CanWest's dominance over Canadian media, this has had a chilling effect on people's right to criticize the media and speak freely on contentious issues. Prior History of this Resolution (IF ANY): BCLA passed resolutions on media democracy in 2003 and 2007, and has a standing commitment to intellectual freedom. Action Proposed: Whereas BCLA passed resolutions opposing media concentration and supporting Media Democracy Day in both 2003 and 2007; And Whereas CanWest is the largest media conglomerate in Canada and owns The Vancouver Sun, The Vancouver Province, The Vancouver Courier, The Victoria Times-Colonist, The National Post, Global Television and many specialty channels and community newspapers; And Whereas the greater the concentration of media ownership, the narrower the range of opinions presented through those media; And Whereas the 2007 BCLA resolution on "Libraries and Media Concentration" stated that "freedom of the press and public access to diverse media and information are prerequisite to a functioning democracy" and affirmed that "libraries are the primary social institution with responsibility to assure the broadest possible availability of a wide range of ideas and information"; And Whereas CanWest has served Mordecai Briemberg and six other Jane and John Does with a writ -

Newspaper Topline Readership - Monday-Friday Vividata Fall 2020 Adults 18+
Newspaper Topline Readership - Monday-Friday Vividata Fall 2020 Adults 18+ Average Weekday Audience 18+ (Mon - Fri) (000) Average Weekday Audience 18+ (Mon - Fri) (000) Title Footprint (1) Print (2) Digital (3) Footprint (1) Print (2) Digital (3) NATIONAL WINNIPEG CMA The Globe and Mail 2,028 869 1,499 The Winnipeg Sun 103 68 58 National Post 1,690 674 1,287 Winnipeg Free Press 226 162 107 PROVINCE OF ONTARIO QUÉBEC CITY CMA The Toronto Sun 685 230 381 Le Journal de Québec 226 128 140 Toronto Star 1,568 784 966 Le Soleilᵇ - - 96 PROVINCE OF QUÉBEC HAMILTON CMA La Pressea - - 1,481 The Hamilton Spectator 194 141 78 Le Devoir 423 153 351 LONDON CMA Le Journal de Montréal 1,259 729 764 London Free Press 148 81 89 Le Journal de Québec 606 321 407 KITCHENER CMA Le Soleilᵇ - - 229 Waterloo Region Record 140 92 74 TORONTO CMA HALIFAX CMA National Post 431 187 306 The Chronicle Herald 99 66 51 The Globe and Mail 660 356 430 ST. CATHARINES/NIAGARA CMA The Toronto Sun 515 338 273 Niagara Falls Review 50 27 33 Toronto Star 1,127 611 652 The Standard 65 31 41 MONTRÉAL CMA The Tribune 33 21* 16* La Pressea - - 793 VICTORIA CMA Le Devoir 221 100 171 Times Colonist 123 88 50 Le Journal de Montréal 696 417 394 WINDSOR CMA Métro 341 292 96 The Windsor Star 132 74 85 Montréal Gazette 238 146 128 SASKATOON CMA National Post 92 58 54 The StarPhoenix 88 52 45 The Globe and Mail 101 58 65 REGINA CMA VANCOUVER CMA Leader Post 80 46 45 National Post 174 69 127 ST.JOHN'S CMA The Globe and Mail 214 83 155 The Telegram 64 35 39 The Province 307 231 115 SHERBROOKE -

Vancouver 2010 Olympic Winter Games Unit
A newspaper-in-education program brought to you by ... A DIVISION OF CANWEST PUBLISHING INC. VancouverVancouver 20102010 OlympicOlympic WinterWinter GamesGames A newspaper-based study VancouverVancouver 20102010 OlympicOlympic WinterWinter GamesGames A Newspaper-based Study Contents To the teacher …………………………... page i Activities about the newspaper ……….... page 5 Activities to use before the Games …...... page 10 Activities to use during the Games …….. page 27 Written by: Don Hale, NIE Consultant Hale & Associates To the teacher VancouverVancouver 20102010 OlympicOlympic WinterWinter GamesGames WELCOME TO THE VANCOUVER 2010 OLYMPIC WINTER GAMES UNIT The Vancouver 2010 Olympic Winter Games in Vancouver, British Columbia will capture the attention of the world. As pre-Games media coverage intensifies, Canadians will focus on the Canadian Olympic Team and Vancouver, the Host City. This newspaper-based unit is designed to study the Vancouver 2010 Olympic Winter Games. Activities in this unit can be used with both printed and electronic newspapers. Use the Vancouver 2010 Olympic Winter Games unit in conjunction with The Vancouver Sun to take advantage of your students’ interest in sports to teach curriculum skills in a way that will make learning fun. The Vancouver 2010 Olympic Winter Games unit will help meet curriculum guidelines in language arts, mathematics, social studies and media literacy. Ready-to-use newspaper-based activities can be copied for classroom use. Some activities can be completed in one class-period while others require more time. The Vancouver 2010 Olympic Winter Games unit provides students with opportunities to learn about other countries and cultures and become more aware of the global village in which they live. -

Microfilmed Newspaper Holdings of the British Columbia Archives
Microfilmed newspaper holdings of the British Columbia Archives ABBOTSFORD. Abbotsford-Clearbrook Times. 4 reels - Filmed LLBC – negative 1986:Nov 19 – Dec., 1987-1995: Jan-Dec. Continues Central Valley Times (Abbotsford, BC) Continued by Abbotsford Times Abbotsford Post. 3 reels - Filmed LLBC – negative 1910: May – Dec., 1911- 1923 : Jan-Dec., 1924: Jan-Feb Weekly publication by Post Publishing 1914:Sep 5 absorbs Huntingdon Star Masthead: Abbotsford Post “with which is incorporated Huntingdon star” Abbotsford, Sumas & Matsqui News. 132 reels, - Filmed 1929-1970, LLBC – negative , Filmed 1971-2000 Commercial - positive , 1929:Nov - 2000:Dec Abbotsford Times. 12 reels - Last filmed 1995 LLBC – negative 1990:Jan 3 - 1995:Dec 29 Continues Abbotsford-Clearbrook Times Valley Times. [Abbotsford] 4 reels - Filmed LLBC – negative - 4 reels 1984:Feb 7 (v1:n1) - 1986:Nov 5 1986:May 6 masthead adds “serving Clearbrook, Abbotsford, Matsqui, Aldergrove & Mission” Continued by Abbotsford-Clearbrook Times Express. [Abbotsford] Filmed LLBC – negative 1977:Mar 15 (v1:n1) - 1978:Feb 22 Weekly publication Entitled Saturday Express 1978:Feb 25 - 1978:Apr 8 Title reverts to Express 1978:Apr 15 -1978:Sep 12 Publication ceased AGASSIZ. Advance. [Agassiz] Chronological by variant titles: Agassiz Record. – 1 reel 1923:Oct 17 – 1924:Aug 20 Retired - Successor is Agassiz advance (Port Haney, BC) Agassiz Advance (Port Haney, BC). – 1 reel 1930:Jun 5 (v1:n4) – 1933:Mar 31 The Advance –Agassiz-Harrison. – 6 reels 1940:Jun 13 – 1964:Oct 8 The Advance - Agassiz-Harrison-Rosedale. – 2 reels 1964:Oct 15 – 1970:Jul 9 The Advance – Agassiz-Harrison. – 18 reels Last filmed 1991 LLBC – negative 1970:Jul 16 – 1991:Dec 18 See individual records for holdings information The Advance Agassiz-Harrison (1940). -

Big Easy Page 6 No.1 America Innorth Canadian Host’S Open Goal: Tops Leaderboard Shaughnessy Page 25 Timers Needto Know Taking Upgolf? What First- Agrip! Get
The Vancouver Sun Logo Sheet & Brand Guidelines The Vancouver Sun brand is a highly visible asset valued by the newspaper’s readership and corporate community. Please use the following guidelines to ensureThe it Provincealways appears consistentLogo Sheetand familiar. & If youBrand have any Guidelines questions regarding usage or other environment specific versions, please email [email protected]. The Province brand is a highly visible asset valued by the newspaper’s readership and corporate community. Please use the following guidelines to ensure it always appears consistent and familiar. If you have any questions regarding usage or other environment specific versions, please email [email protected]. Bar Get a grip! Height Bar Taking up golf? What first- Height timers need to know Page 25 COLOUR VERSION B&W VERSION REVERSE VERSION SPOT: Pantone 209 C COLOUR VERSION B&W VERSION REVERSE VERSION Shaughnessy CMYK:SPOT: 0/100/34/51Pantone 3015 C • For all positive black & white • For all reverse black & white RGB: 128/31/54 CMYK: 100/30/0/20 • For allapplications positive black only& white • For all reverse applicationsblack & white tops leaderboard HEXRGB: #: 8B29420/114/171 applications only applications HEX #: 0072AB • Use on white backgrounds • Use if background colour is; • Use on white backgrounds • Use if backgroundSun colour burgundy is or multi-coloured Canadian Open host’s goal: • Crop off tag line if it is too small to Province blue multi-coloured • For all positive colour applications • Crop off tag line if it is too small to • For all positive colour applications be read, or too small to print backgrounds• For all large format applications No.1 in North America onlyonly be read, or too small to print properly.properly.