APRESS ROADMAP Your Enterprise Java Application Stack and More
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Enrico Rubboli
Enrico Rubboli Contact Information Mobile UK: +44 741 4734233 Mobile IT: +39 349 8083244 E-mail: [email protected] Website: http://rubbo.li Personal Citizenship: Italian Information Gender: Male Date of Birth: 1976 October 27th Profile I'm a Senior Software Engineer with experience in several fields of web development. Switched to Ruby few years ago I can now boast several successful projects delivered. I'm currently searching for a new interesting opportunity in the fintech field. • 6 years of experience in Ruby and Rails • 14 years of overall experience as Web Developer • 14 years of experience in UNIX/networking/security • worked for the last 7 years with english speaking companies Technical Skills OS: GNU Linux (debian/arch), FreeBSD, OSX Programming: Ruby, Java, PHP, Perl, Bash/Zsh, C, Go lang Web & frameworks: Ruby on Rails, Sinatra, Symfony (PHP), JBoss (Java) and Torquebox (Jruby) TDD: JUnit, Rspec, Cucumber, Test:Unit Agile: Scrum, Pair Programming, XP Admins: Managing availability, scalability and efficiency of distributed systems, docker Networking: Firewalls (iptables/ipfw), IPsec, SSL, HTTP etc. Professional Experience Bitfinex - iFinex INC, Feb 2016 - present Role: Senior Software Engineer { Working in a very small team. { Different architectures and languages, in particular GoLang - Ruby and NodeJS. { Built the development environment on docker Company info: http://bitfinex.com - Hong Kong Burnside Digital Inc, Nov 2013 - Feb 2016 Role: Senior Software Engineer { Building apps using ruby on rails, nodeJS, AngularJS and Faye. { Assisting the sales team during the estimation process. { Leader of the web team Company info: http://burnsidedigital.com - Portland, OR, USA 1 of 2 Digital Science, Oct 2012 - Nov 2013 Role: Senior Software Engineer { Member of the central team. -

Next Generation Web Scanning Presentation
Next generation web scanning New Zealand: A case study First presented at KIWICON III 2009 By Andrew Horton aka urbanadventurer NZ Web Recon Goal: To scan all of New Zealand's web-space to see what's there. Requirements: – Targets – Scanning – Analysis Sounds easy, right? urbanadventurer (Andrew Horton) www.morningstarsecurity.com Targets urbanadventurer (Andrew Horton) www.morningstarsecurity.com Targets What does 'NZ web-space' mean? It could mean: •Geographically within NZ regardless of the TLD •The .nz TLD hosted anywhere •All of the above For this scan it means, IPs geographically within NZ urbanadventurer (Andrew Horton) www.morningstarsecurity.com Finding Targets We need creative methods to find targets urbanadventurer (Andrew Horton) www.morningstarsecurity.com DNS Zone Transfer urbanadventurer (Andrew Horton) www.morningstarsecurity.com Find IP addresses on IRC and by resolving lots of NZ websites 58.*.*.* 60.*.*.* 65.*.*.* 91.*.*.* 110.*.*.* 111.*.*.* 113.*.*.* 114.*.*.* 115.*.*.* 116.*.*.* 117.*.*.* 118.*.*.* 119.*.*.* 120.*.*.* 121.*.*.* 122.*.*.* 123.*.*.* 124.*.*.* 125.*.*.* 130.*.*.* 131.*.*.* 132.*.*.* 138.*.*.* 139.*.*.* 143.*.*.* 144.*.*.* 146.*.*.* 150.*.*.* 153.*.*.* 156.*.*.* 161.*.*.* 162.*.*.* 163.*.*.* 165.*.*.* 166.*.*.* 167.*.*.* 192.*.*.* 198.*.*.* 202.*.*.* 203.*.*.* 210.*.*.* 218.*.*.* 219.*.*.* 222.*.*.* 729,580,500 IPs. More than we want to try. urbanadventurer (Andrew Horton) www.morningstarsecurity.com IP address blocks in the IANA IPv4 Address Space Registry Prefix Designation Date Whois Status [1] ----- -

Dspace 1.8 Documentation
DSpace 1.8 Documentation DSpace 1.8 Documentation Author: The DSpace Developer Team Date: 03 November 2011 URL: https://wiki.duraspace.org/display/DSDOC18 Page 1 of 621 DSpace 1.8 Documentation Table of Contents 1 Preface _____________________________________________________________________________ 13 1.1 Release Notes ____________________________________________________________________ 13 2 Introduction __________________________________________________________________________ 15 3 Functional Overview ___________________________________________________________________ 17 3.1 Data Model ______________________________________________________________________ 17 3.2 Plugin Manager ___________________________________________________________________ 19 3.3 Metadata ________________________________________________________________________ 19 3.4 Packager Plugins _________________________________________________________________ 20 3.5 Crosswalk Plugins _________________________________________________________________ 21 3.6 E-People and Groups ______________________________________________________________ 21 3.6.1 E-Person __________________________________________________________________ 21 3.6.2 Groups ____________________________________________________________________ 22 3.7 Authentication ____________________________________________________________________ 22 3.8 Authorization _____________________________________________________________________ 22 3.9 Ingest Process and Workflow ________________________________________________________ 24 -

Building Multiplayer Games with Web Sockets #GHC19 About Us
Leveling Up: Building Multiplayer Games with Web Sockets #GHC19 About Us: #GHC19 Agenda 0. Introduction 1. Simple Chat Application 2. Multiplayer Game 3. Further Applications #GHC19 www.kahoot.com #GHC19 #GHC19 #GHC19 #GHC19 Diagram source: BMC Blog #GHC19 Diagram source: BMC Blog TCP and UDP are the transport level protocols TCP UDP Reliable Unreliable Connection-oriented Connectionless Segment sequencing No sequencing Acknowledge No acknowledgement segments #GHC19 Source: Pluralsight #GHC19 Diagram source: BMC Blog #GHC19 Diagram source: BMC Blog HTTP is used to share information on the application layer #GHC19 Graphic Source: Webnots Alternatives to WebSockets ● Browser Plug-Ins ● Polling ● Long Polling ● Server-Sent Events (SSE) #GHC19 The WebSocket protocol is used for real-time communication RFC-6455 #GHC19 Source: IETF RFC-6455 Some benefits of WebSockets Event driven Reduces network overhead - no need to send full HTTP requests HTTP compatible Co-exists on same port as your web server TLS/SSL compatible Same security as HTTPS #GHC19 WebSocket connection overview #GHC19 Diagram source: PubNub Staff Opening Handshake Client Handshake Server Handshake #GHC19 Source: IETF RFC-6455 Opening Handshake Client Handshake Server Handshake #GHC19 Source: IETF RFC-6455 Opening Handshake Client Handshake Server Handshake #GHC19 Source: IETF RFC-6455 Opening Handshake Client Handshake Server Handshake #GHC19 Source: IETF RFC-6455 Opening Handshake Client Handshake Server Handshake #GHC19 Source: IETF RFC-6455 Data Transfer Base Framing Protocol -

A Post-Apocalyptic Sun.Misc.Unsafe World
A Post-Apocalyptic sun.misc.Unsafe World http://www.superbwallpapers.com/fantasy/post-apocalyptic-tower-bridge-london-26546/ Chris Engelbert Twitter: @noctarius2k Jatumba! 2014, 2015, 2016, … Disclaimer This talk is not going to be negative! Disclaimer But certain things are highly speculative and APIs or ideas might change by tomorrow! sun.misc.Scissors http://www.underwhelmedcomic.com/wp-content/uploads/2012/03/runningdude.jpg sun.misc.Unsafe - What you (don’t) know sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) • Used inside the JVM / JRE sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) • Used inside the JVM / JRE // Unsafe mechanics private static final sun.misc.Unsafe U; private static final long QBASE; private static final long QLOCK; private static final int ABASE; private static final int ASHIFT; static { try { U = sun.misc.Unsafe.getUnsafe(); Class<?> k = WorkQueue.class; Class<?> ak = ForkJoinTask[].class; example: QBASE = U.objectFieldOffset (k.getDeclaredField("base")); java.util.concurrent.ForkJoinPool QLOCK = U.objectFieldOffset (k.getDeclaredField("qlock")); ABASE = U.arrayBaseOffset(ak); int scale = U.arrayIndexScale(ak); if ((scale & (scale - 1)) != 0) throw new Error("data type scale not a power of two"); ASHIFT = 31 - Integer.numberOfLeadingZeros(scale); } catch (Exception e) { throw new Error(e); } } } sun.misc.Unsafe -

Characteristics of Dynamic JVM Languages
Characteristics of Dynamic JVM Languages Aibek Sarimbekov Andrej Podzimek Lubomir Bulej University of Lugano Charles University in Prague University of Lugano fi[email protected] [email protected]ff.cuni.cz fi[email protected] Yudi Zheng Nathan Ricci Walter Binder University of Lugano Tufts University University of Lugano fi[email protected] [email protected] fi[email protected] Abstract However, since the JVM was originally conceived for The Java Virtual Machine (JVM) has become an execution a statically-typed language, the performance of the JVM platform targeted by many programming languages. How- and its JIT compiler with dynamically-typed languages is ever, unlike with Java, a statically-typed language, the per- often lacking, lagging behind purpose-built language-specific formance of the JVM and its Just-In-Time (JIT) compiler JIT compilers. Making the JVM perform well with various with dynamically-typed languages lags behind purpose-built statically- and dynamically-typed languages clearly requires language-specific JIT compilers. In this paper, we aim to significant effort, not only in optimizing the JVM itself, but contribute to the understanding of the workloads imposed on also, more importantly, in optimizing the bytecode-emitting the JVM by dynamic languages. We use various metrics to language compiler, instead of just relying on the original JIT characterize the dynamic behavior of a variety of programs to gain performance [8]. This in turn requires that developers written in three dynamic languages (Clojure, Python, and of both the language compilers and the JVM understand the Ruby) executing on the JVM. We identify the differences characteristics of the JVM workloads produced by various with respect to Java, and briefly discuss their implications. -

Ola Bini Computational Metalinguist [email protected] 698E 2885 C1DE 74E3 2CD5 03AD 295C 7469 84AF 7F0C
JRuby For The Win Ola Bini computational metalinguist [email protected] http://olabini.com/blog 698E 2885 C1DE 74E3 2CD5 03AD 295C 7469 84AF 7F0C onsdag 12 juni 13 Logistics and Demographics onsdag 12 juni 13 LAST MINUTE DEMO onsdag 12 juni 13 JRuby Implementation of the Ruby language Java 1.6+ 1.8.7 and 1.9.3 compatible (experimental 2.0 support) Open Source Created 2001 Embraces testing Current version: 1.7.4 Support from EngineYard, RedHat & ThoughtWorks onsdag 12 juni 13 Why JRuby? Threading Unicode Performance Memory Explicit extension API and OO internals Libraries and legacy systems Politics onsdag 12 juni 13 InvokeDynamic onsdag 12 juni 13 JRuby Differences Most compatible alternative implementation Native threads vs Green threads No C extensions (well, some) No continuations No fork ObjectSpace disabled by default onsdag 12 juni 13 Simple JRuby onsdag 12 juni 13 Java integration Java types == Ruby types Call methods, construct instances Static generation of classes camelCase or snake_case .getFoo(), setFoo(v) becomes .foo and .foo = v Interfaces can be implemented Classes can be inherited from Implicit closure conversion Extra added features to Rubyfy Java onsdag 12 juni 13 Ant+Rake onsdag 12 juni 13 Clojure STM onsdag 12 juni 13 Web onsdag 12 juni 13 Rails onsdag 12 juni 13 Sinatra onsdag 12 juni 13 Trinidad onsdag 12 juni 13 Swing Swing API == large and complex Ruby magic simplifies most of the tricky bits Java is a very verbose language Ruby makes Swing fun (more fun at least) No consistent cross-platform GUI library for Ruby -
Android Geeknight Presentation 2011-03
Android Geek Night 3.0 Per Nymann Jørgensen [email protected] Niels Sthen Hansen [email protected] Android Geek Night 3.0 Android at a glance New features in Gingerbread & Honeycomb Demos & Code Android 101 Operating system targeting mobile devices/Tables devices Linux based - with additions Open source under the Apache License Allows development in Java Share of worldwide 2010 Q4 smartphone sales to end users by Or Scala, JRuby, Groovy .. operating system, according toCanalys.[35] Two new versions just came out.. Android 101 - Dalvik VM Virtual machine developed by Google for mobile devices Uses the Dalvik Executable (.dex) format Designed for limited processing power and memory Register-based architecture as opposed to stack machine Java VMs Class library based on Apache Harmony No AWT, Swing No Java ME Android 101 - SDK Android libraries The SDK and AVD manager, for maintaining the SDK components and creating virtual devices LogCat to capture logs from running device DDMS – Dalvik Debug Monitor Tools to convert Java .class files to Dalvik bytecode and create installable .apk files Plugin for Eclipse - Android Development Tools (ADT) Android 101 - Components Activity GUI Service non-GUI Broadcast Receiver Events Content Provider Exposing data/content across applications An Android application can be seen as a collection of components. Android API 10 New stuff New Sensors / New Sensor APIs Gyroscope Rotation vector Acceleration Linear acceleration (acceleration without gravity) Gravity (gravity without acceleration) Barometer (air pressure) Android API 10 New stuff NFC Short range wireless communication. Do not require discovery or pairing Supported mode as of 2.3.3 (reader/writer/P2P limited) Enable application like Mobile ticketing (dare we say rejsekort), Smart poster, etc. -

Reading the Runes for Java Runtimes the Latest IBM Java Sdks
Java Technology Centre Reading the runes for Java runtimes The latest IBM Java SDKs ... and beyond Tim Ellison [email protected] © 2009 IBM Corporation Java Technology Centre Goals . IBM and Java . Explore the changing landscape of hardware and software influences . Discuss the impact to Java runtime technology due to these changes . Show how IBM is leading the way with these changes 2 Mar 9, 2009 © 2009 IBM Corporation Java Technology Centre IBM and Java . Java is critically important to IBM – Provides fundamental infrastructure to IBM software portfolio – Delivers standard development environment – Enables cost effective multi platform support – Delivered to Independent Software Vendors supporting IBM server platforms . IBM is investing strategically in virtual machine technology – Since Java 5.0, a single Java platform technology supports ME, SE and EE – Technology base on which to delivery improved performance, reliability and serviceability • Some IBM owned code (Virtual machine, JIT compiler, ...) • Some open source code (Apache XML parser, Apache Core libraries, Zlib, ...) • Some Sun licensed code (class libraries, tools, ...) . Looking to engender accelerated and open innovation in runtime technologies – Support for Eclipse, Apache (Harmony, XML, Derby, Geronimo, Tuscany) – Broad participation of relevant standards bodies such as JCP and OSGi 3 Mar 9, 2009 © 2009 IBM Corporation Java Technology Centre IBM Java – 2009 key initiatives . Consumability – Deliver value without complexity. – Ensure that problems with our products can be addressed quickly, allowing customers to keep focus on their own business issues. – Deliver a consistent model for solving customer problems. “Scaling Up” - Emerging hardware and applications – Provide a Java implementation that can scale to the most demanding application needs. -
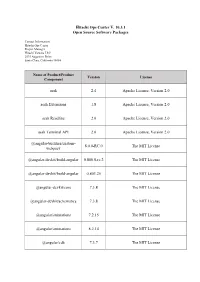
Open Source Software Packages
Hitachi Ops Center V. 10.3.1 Open Source Software Packages Contact Information: Hitachi Ops Center Project Manager Hitachi Vantara LLC 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component aesh 2.4 Apache License, Version 2.0 aesh Extensions 1.8 Apache License, Version 2.0 aesh Readline 2.0 Apache License, Version 2.0 aesh Terminal API 2.0 Apache License, Version 2.0 @angular-builders/custom- 8.0.0-RC.0 The MIT License webpack @angular-devkit/build-angular 0.800.0-rc.2 The MIT License @angular-devkit/build-angular 0.803.25 The MIT License @angular-devkit/core 7.3.8 The MIT License @angular-devkit/schematics 7.3.8 The MIT License @angular/animations 7.2.15 The MIT License @angular/animations 8.2.14 The MIT License @angular/cdk 7.3.7 The MIT License Name of Product/Product Version License Component @angular/cli 8.0.0 The MIT License @angular/cli 8.3.25 The MIT License @angular/common 7.2.15 The MIT License @angular/common 8.2.14 The MIT License @angular/compiler 7.2.15 The MIT License @angular/compiler 8.2.14 The MIT License @angular/compiler-cli 8.2.14 The MIT License @angular/core 7.2.15 The MIT License @angular/forms 7.2.13 The MIT License @angular/forms 7.2.15 The MIT License @angular/forms 8.2.14 The MIT License @angular/forms 8.2.7 The MIT License @angular/language-service 8.2.14 The MIT License @angular/platform-browser 7.2.15 The MIT License @angular/platform-browser 8.2.14 The MIT License Name of Product/Product Version License Component @angular/platform-browser- 7.2.15 The MIT License -

Deploying with Jruby Is the Definitive Text on Getting Jruby Applications up and Running
Early Praise for Deploying JRuby Deploying with JRuby is the definitive text on getting JRuby applications up and running. Joe has pulled together a great collection of deployment knowledge, and the JRuby story is much stronger as a result. ➤ Charles Oliver Nutter JRuby Core team member and coauthor, Using JRuby Deploying with JRuby answers all of the most frequently asked questions regarding real-world use of JRuby that I have seen, including many we were not able to answer in Using JRuby. Whether you’re coming to JRuby from Ruby or Java, Joe fills in all the gaps you’ll need to deploy JRuby with confidence. ➤ Nick Sieger JRuby Core team member and coauthor, Using JRuby This book is an excellent guide to navigating the various JRuby deployment op- tions. Joe is fair in his assessment of these technologies and describes a clear path for getting your Ruby application up and running on the JVM. ➤ Bob McWhirter TorqueBox team lead at Red Hat Essential reading to learn not only how to deploy web applications on JRuby but also why. ➤ David Calavera Creator of Trinidad Deploying with JRuby is a must-read for anyone interested in production JRuby deployments. The book walks through the major deployment strategies by providing easy-to-follow examples that help the reader take full advantage of the JRuby servers while avoiding the common pitfalls of migrating an application to JRuby. ➤ Ben Browning TorqueBox developer at Red Hat Deploying with JRuby is an invaluable resource for anyone planning on using JRuby for web-based development. For those who have never used JRuby, Joe clearly presents its many advantages and few disadvantages in comparison to MRI. -

J2EETM Deployment: the Jonas Case Study
J2EETM Deployment: The JOnAS Case Study François Exertier Bull, 1, rue de Provence BP 208 38432 Echirolles Cedex [email protected] RÉSUMÉ. La spécification J2EE (Java 2 platform Enterprise Edition) définit une architecture de serveur d'application Java. Jusqu'à J2EE 1.3, seuls les aspects de déploiement concernant le développeur d'applications étaient adressés. Avec J2EE 1.4, les interfaces et les étapes de déploiement ont été plus précisément spécifiées dans la spécification "J2EE Deployment". JOnAS (Java Open Application Server) est une plate-forme J2EE développée au sein du consortium ObjectWeb. Les aspects déploiement sont en cours de développement. Cet article décrit les concepts liés au déploiement dans J2EE, ainsi que les problématiques levées lors de leur mise en œuvre pour JOnAS. Il n'a pas pour but de présenter un travail abouti, mais illustre le déploiement par un cas concret et ébauche une liste de besoins non encore satisfaits dans le domaine. ABSTRACT. The J2EE (Java 2 platform Enterprise Edition) specification defines an architecture for Java Application Servers. Until J2EE 1.3, the deployment aspect was addressed from the developer point of view only. Since J2EE 1.4, deployment APIs and steps have been more precisely specified within the "J2EE Deployment Specification". JOnAS (Java Open Application Server) is a J2EE platform implementation by ObjectWeb. The deployment aspects are under development. This article describes the J2EE Deployment concepts, and the issues raised when implementing deployment features within JOnAS. It does not provide a complete solution, but illustrates deployment through a concrete example and initiates a list of non fulfilled requirements.