Game Physics Pearls
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Agx Multiphysics Download
Agx multiphysics download click here to download A patch release of AgX Dynamics is now available for download for all of our licensed customers. This version include some minor. AGX Dynamics is a professional multi-purpose physics engine for simulators, Virtual parallel high performance hybrid equation solvers and novel multi- physics models. Why choose AGX Dynamics? Download AGX product brochure. This video shows a simulation of a wheel loader interacting with a dynamic tree model. High fidelity. AGX Multiphysics is a proprietary real-time physics engine developed by Algoryx Simulation AB Create a book · Download as PDF · Printable version. AgX Multiphysics Toolkit · Age Of Empires III The Asian Dynasties Expansion. Convert trail version Free Download, product key, keygen, Activator com extended. free full download agx multiphysics toolkit from AYS search www.doorway.ru have many downloads related to agx multiphysics toolkit which are hosted on sites like. With AGXUnity, it is possible to incorporate a real physics engine into a well Download from the prebuilt-packages sub-directory in the repository www.doorway.rug: multiphysics. A www.doorway.ru app that runs a physics engine and lets clients download physics data in real Clone or download AgX Multiphysics compiled with Lua support. Agx multiphysics toolkit. Developed physics the was made dynamics multiphysics simulation. Runtime library for AgX MultiPhysics Library. How to repair file. Original file to replace broken file www.doorway.ru Download. Current version: Some short videos that may help starting with AGX-III. Example 1: Finding a possible Pareto front for the Balaban Index in the Missing: multiphysics. -
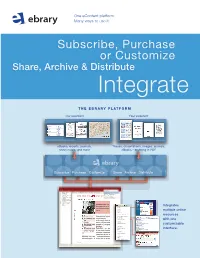
The EBRARY Platform
One eContent platform. Many ways to use it. Subscribe, Purchase or Customize Share, Archive & Distribute Integrate THE EBRARY PLatFORM Our eContent Your eContent eBooks, reports, journals, Theses, dissertations, images, journals, sheet music, and more eBooks – anything in PDF Subscribe Purchase Customize Share Archive Distribute SULAIR Select Collections SUL EBRARY COLLECTIONS Select Collections TABLE OF CONTENTS Infotools All ebrary Collections CONTRIBUTORS Byron Hoyt Sheet Music (Browse) INTRODUCTION Immigration Commision Reports (Dillingham) Contents BUSINESS: A USER’S GUIDE Women and Child Wage Earners in the U.S. CSLI Linguistics and Philosophy BEST PRACTICE SUL Books in the Public Domain MANAGEMENT CHECKLISTS Medieval and Modern Thought Text Project ACTIONLISTS MANAGEMENT LIBRARY BUSINESS THINKERS AND MANA DICTIONARY WORLD BUSINESS ALMANAC Highlights Notes BUSINESS INFORMATION SOURC INDEX CREDITS InfoTools Integrates Define Explain Locate multiple online Translate Search Document... resources Search All Documents... Search Web Search Catalog with one Highlight Add to Bookshelf customizable Copy Text... Copy Bookmark interface. Print... Print Again Toggle Automenu Preferences... Help About ebrary Reader... EASY TO USE. Subscribe, Purchase AFFORDABLE. or Customize your ALW ay S AVAILABLE. eBook selection NO CHECK-OUTS. Un I Q U E S U B SC R I B E T O G R OWI ng E B O O K D ataba S E S W I T H SIMULtanEOUS, MULTI-USER ACCESS. RESEARCH TOOLS. ACADEMIC DATABASES Academic Complete includes all academic databases listed below. FREE MARCS. # of # of Subject Titles* Subject Titles* Business & Economics 6,300 Language, Literature 3,400 & Linguistics “ebrary’s content is Computers & IT 2,800 Law, International Relations 3,800 multidisciplinary and Education 2,300 & Public Policy Engineering & Technology 3,700 supports our expanding Life Sciences 2,000 (includes Biotechnolgy, History & Political Science 4,800 Agriculture, and (also includes a bonus selection faculty and curriculum. -

Software Design for Pluggable Real Time Physics Middleware
2005:270 CIV MASTER'S THESIS AgentPhysics Software Design for Pluggable Real Time Physics Middleware Johan Göransson Luleå University of Technology MSc Programmes in Engineering Department of Computer Science and Electrical Engineering Division of Computer Science 2005:270 CIV - ISSN: 1402-1617 - ISRN: LTU-EX--05/270--SE AgentPhysics Software Design for Pluggable Real Time Physics Middleware Johan GÄoransson Department of Computer Science and Electrical Engineering, LuleºaUniversity of Technology, [email protected] October 27, 2005 Abstract This master's thesis proposes a software design for a real time physics appli- cation programming interface with support for pluggable physics middleware. Pluggable means that the actual implementation of the simulation is indepen- dent and interchangeable, separated from the user interface of the API. This is done by dividing the API in three layers: wrapper, peer, and implementation. An evaluation of Open Dynamics Engine as a viable middleware for simulating rigid body physics is also given based on a number of test applications. The method used in this thesis consists of an iterative software design based on a literature study of rigid body physics, simulation and software design, as well as reviewing related work. The conclusion is that although the goals set for the design were ful¯lled, it is unlikely that AgentPhysics will be used other than as a higher level API on top of ODE, and only ODE. This is due to a number of reasons such as middleware speci¯c tools and code containers are di±cult to support, clash- ing programming paradigms produces an error prone implementation layer and middleware developers are reluctant to port their engines to Java. -

Physics Simulation Game Engine Benchmark Student: Marek Papinčák Supervisor: Doc
ASSIGNMENT OF BACHELOR’S THESIS Title: Physics Simulation Game Engine Benchmark Student: Marek Papinčák Supervisor: doc. Ing. Jiří Bittner, Ph.D. Study Programme: Informatics Study Branch: Web and Software Engineering Department: Department of Software Engineering Validity: Until the end of summer semester 2018/19 Instructions Review the existing tools and methods used for physics simulation in contemporary game engines. In the review, cover also the existing benchmarks created for evaluation of physics simulation performance. Identify parts of physics simulation with the highest computational overhead. Design at least three test scenarios that will allow to evaluate the dependence of the simulation on carefully selected parameters (e.g. number of colliding objects, number of simulated projectiles). Implement the designed simulation scenarios within Unity game engine and conduct a series of measurements that will analyze the behavior of the physics simulation. Finally, create a simple game that will make use of the tested scenarios. References [1] Jason Gregory. Game Engine Architecture, 2nd edition. CRC Press, 2014. [2] Ian Millington. Game Physics Engine Development, 2nd edition. CRC Press, 2010. [3] Unity User Manual. Unity Technologies, 2017. Available at https://docs.unity3d.com/Manual/index.html [4] Antonín Šmíd. Comparison of the Unity and Unreal Engines. Bachelor Thesis, CTU FEE, 2017. Ing. Michal Valenta, Ph.D. doc. RNDr. Ing. Marcel Jiřina, Ph.D. Head of Department Dean Prague February 8, 2018 Bachelor’s thesis Physics Simulation Game Engine Benchmark Marek Papinˇc´ak Department of Software Engineering Supervisor: doc. Ing. Jiˇr´ıBittner, Ph.D. May 15, 2018 Acknowledgements I am thankful to Jiri Bittner, an associate professor at the Department of Computer Graphics and Interaction, for sharing his expertise and helping me with this thesis. -

Locotest: Deploying and Evaluating Physics-Based Locomotion on Multiple Simulation Platforms
LocoTest: Deploying and Evaluating Physics-based Locomotion on Multiple Simulation Platforms Stevie Giovanni and KangKang Yin National University of Singapore fstevie,[email protected] Abstract. In the pursuit of pushing active character control into games, we have deployed a generalized physics-based locomotion control scheme to multiple simulation platforms, including ODE, PhysX, Bullet, and Vortex. We first overview the main characteristics of these physics engines. Then we illustrate the major steps of integrating active character controllers with physics SDKs, together with necessary implementation details. We also evaluate and compare the performance of the locomotion control on different simulation platforms. Note that our work only represents an initial attempt at doing such evaluation, and additional refine- ment of the methodology and results can still be expected. We release our code online to encourage more follow-up works, as well as more interactions between the research community and the game development community. Keywords: physics-based animation, simulation, locomotion, motion control 1 Introduction Developing biped locomotion controllers has been a long-time research interest in the Robotics community [3]. In the Computer Animation community, Hodgins and her col- leagues [12, 7] started the many efforts on locomotion control of simulated characters. Among these efforts, the simplest class of locomotion control methods employs re- altime feedback laws for robust balance recovery [12, 7, 14, 9, 4]. Optimization-based control methods, on the other hand, are more mathematically involved, but can incor- porate more motion objectives automatically [10, 8]. Recently, data-driven approaches have become quite common, where motion capture trajectories are referenced to further improve the naturalness of simulated motions [14, 10, 9]. -

Physics Engine Design and Implementation Physics Engine • a Component of the Game Engine
Physics engine design and implementation Physics Engine • A component of the game engine. • Separates reusable features and specific game logic. • basically software components (physics, graphics, input, network, etc.) • Handles the simulation of the world • physical behavior, collisions, terrain changes, ragdoll and active characters, explosions, object breaking and destruction, liquids and soft bodies, ... Game Physics 2 Physics engine • Example SDKs: – Open Source • Bullet, Open Dynamics Engine (ODE), Tokamak, Newton Game Dynamics, PhysBam, Box2D – Closed source • Havok Physics • Nvidia PhysX PhysX (Mafia II) ODE (Call of Juarez) Havok (Diablo 3) Game Physics 3 Case study: Bullet • Bullet Physics Library is an open source game physics engine. • http://bulletphysics.org • open source under ZLib license. • Provides collision detection, soft body and rigid body solvers. • Used by many movie and game companies in AAA titles on PC, consoles and mobile devices. • A modular extendible C++ design. • Used for the practical assignment. • User manual and numerous demos (e.g. CCD Physics, Collision and SoftBody Demo). Game Physics 4 Features • Bullet Collision Detection can be used on its own as a separate SDK without Bullet Dynamics • Discrete and continuous collision detection. • Swept collision queries. • Generic convex support (using GJK), capsule, cylinder, cone, sphere, box and non-convex triangle meshes. • Support for dynamic deformation of nonconvex triangle meshes. • Multi-physics Library includes: • Rigid-body dynamics including constraint solvers. • Support for constraint limits and motors. • Soft-body support including cloth and rope. Game Physics 5 Design • The main components are organized as follows Soft Body Dynamics Bullet Multi Threaded Extras: Maya Plugin, Rigid Body Dynamics etc. Collision Detection Linear Math, Memory, Containers Game Physics 6 Overview • High level simulation manager: btDiscreteDynamicsWorld or btSoftRigidDynamicsWorld. -

Physics Application Programming Interface
PHI: Physics Application Programming Interface Bing Tang, Zhigeng Pan, ZuoYan Lin, Le Zheng State Key Lab of CAD&CG, Zhejiang University, Hang Zhou, China, 310027 {btang, zgpan, linzouyan, zhengle}@cad.zju.edu.cn Abstract. In this paper, we propose to design an easy to use physics applica- tion programming interface (PHI) with support for pluggable physics library. The goal is to create physically realistic 3D graphics environments and inte- grate real-time physics simulation into games seamlessly with advanced fea- tures, such as interactive character simulation and vehicle dynamics. The actual implementation of the simulation was designed to be independent, interchange- able and separated from the user interface of the API. We demonstrate the util- ity of the middleware by simulating versatile vehicle dynamics and generating quality reactive human motions. 1 Introduction Each year games become more realistic visually. Current generation graphics cards can produce amazing high-quality visual effects. But visual realism is only half the battle. Physical realism is another half [1]. The impressive capabilities of the latest generation of video game hardware have raised our expectations of not only how digital characters look, but also they behavior [2]. As the speed of the video game hardware increases and the algorithms get refined, physics is expected to play a more prominent role in video games. The long-awaited Half-life 2 impressed the players deeply for the amazing Havok physics engine[3]. The incredible physics engine of the game makes the whole game world believable and natural. Items thrown across a room will hit other objects, which will then react in a very convincing way. -

Wavelets: a Primer
Wavelets A Primer Wavelets A Primer Christian Blatter Departement Mathematik ETH Zentrum Zurich, Switzerland Boca Raton London New York CRC Press is an imprint of the Taylor & Francis Group, an informa business AN A K PETERS BOOK First published 1998 by Ak Peters, Ltd. Published 2018 by CRC Press Taylor & Francis Group 6000 Broken Sound Parkway NW, Suite 300 Boca Raton, FL 33487-2742 © 1998 by Taylor & Francis Group, LLC CRC Press is an imprint of Taylor & Francis Group, an Informa business No claim to original U.S. Government works ISBN 13: 978-1-56881-195-6 (pbk) ISBN 13: 978-1-56881-095-9 (hbk) This book contains information obtained from authentic and highly regarded sources. Reasonable efforts have been made to publish reliable data and information, but the author and publisher cannot assume responsibility for the validity of all materials or the consequences of their use. The authors and publishers have attempted to trace the copyright holders of all material reproduced in this publication and apologize to copyright holders ifpermission to publish in this form has not been obtained. If any copyright material has not been acknowledged please write and let us know so we may rectify in any future reprint. Except as permitted under U.S. Copyright Law, no part of this book may be reprinted, reproduced, transmitted, or utilized in any form by any electronic, mechanical, or other means, now known or hereafter invented, including photocopying, microfilming, and recording, or in any information storage or retrieval system, without written permission from the publishers. For permission to photocopy or use material electronically from this work, please access www. -

Taylor & Francis
Taylor & Francis E-Book-Erwerbungsoptionen auf einen Blick Stand: Mai 2021 Plattform Taylor & Francis eBooks Imprints: AOCS Publishing - A K Peters/CRC Press - Apple Academic Press - Auerbach Publications - Blackwell - Burleigh Dodds Science Publishing - Birkbeck Law Press - Chapman and Hall - CRC Press - David Fulton Pulblishers - EPFL Press - Hakulyt Society - Informa Law from Routledge - Jennifer Stanford Publishing - Productivity Press - Psychology Press - RFF Press - RIBA Publishing - Routledge - Routledge India - Routledge-Cavendish - Spon Press- Taylor & Francis - Tecton NewMedia - UCL Press - Willan - W.W. Norton & Company Former Imprints: Ashgate -Focal Press - Elsevier - Landes Bioscience - Radcliff - Informa Healthcare - Pearson HE List/ Pearson (US) - Pearson - Nickel - Pyrczak - Speechmark - Earthscan - Acumen Publishing - Left Coast Press - Pickering & Chatto - Hodder Education - Longman - Garland - Routhledge Falmer - Brunner/Mazel - ME Sharp - Paradigm - Planners Press - Theatre Arts - Kegan Paul - Eye on Education - Transaction Publishing - St Jerome - Architectural Press - Harrington Park Press - GSER - Baywood - Bibliomotion - Westview Press - Karnac Books - Noordhof - Frank Cass - Accelerated Development - Brunner Routledge - James & James - Routledge Curca Flexible Angebotsformen für Ihre Bibliothek Einzeltitel Keine Mindestbestellmenge mehr. Pick & Choose Größere Bestellungen werden jedoch von den Verlagen bevorzugt. DRM-free-E-Books Wie gewohnt bietet Taylor & Francis weiterhin DRM-freie E-Books mit unlimitierten -

CRC Press Catalogue 2020 July - December New and Forthcoming Titles
TAYLOR & FRANCIS CRC Press Catalogue 2020 July - December New and Forthcoming Titles www.routledge.com Welcome THE EASY WAY TO ORDER Book orders should be addressed to the Welcome to the July - December 2020 CRC Press catalogue. Taylor & Francis Customer Services Department at Bookpoint, or the appropriate In this catalogue you will find new and forthcoming CRC Press titles overseas offices. publishing across all subject areas including Life Sciences, Engineering, Food and Nutrition, Environmental Sciences, Mathematics and Statistics, Physics and Material Sciences, Computer Science, Agriculture, Biomedicine and Forensics Science and Homeland Security. Contacts UK and Rest of World: Bookpoint Ltd We welcome your feedback on our publishing programme, so please do Tel: +44 (0) 1235 400524 not hesitate to get in touch – whether you want to read, write, review, Email: [email protected] adapt or buy, we want to hear from you, so please visit our website below USA: or please contact your local sales representative for more information. Taylor & Francis Tel: 800-634-7064 Email: [email protected] www.crcpress.com Asia: Taylor & Francis Asia Pacific Tel: +65 6508 2888 Email: [email protected] China: Taylor & Francis China Tel: +86 10 58452881 Prices are correct at time of going to press and may be subject to change without Email: [email protected] notice. Some titles within this catalogue may not be available in your region. India: Taylor & Francis India Tel: +91 (0) 11 43155100 Email: [email protected] eBooks Partnership Opportunities at We have over 50,000 eBooks available across the Routledge Humanities, Social Sciences, Behavioural Sciences, At Routledge we always look for innovative ways to Built Environment, STM and Law, from leading support and collaborate with our readers and the Imprints, including Routledge, Focal Press and organizations they represent. -

Spjaldtölvur Í Norðlingaskóla Smáforrit Í Nóvember 2012 – Upplýsingar Um Forritin Skúlína Hlíf Kjartansdóttir – 31.8.2014
Spjaldtölvur í Norðlingaskóla Smáforrit í nóvember 2012 – upplýsingar um forritin Skúlína Hlíf Kjartansdóttir – 31.8.2014 Lýsingar eru úr iTunes Preview eða af vefsíðum fyrirtækja framleiðnda forritanna. ! Not found on itunes http://ruckygames.com/ 30/30 – Productivity By Binary Hammer https://itunes.apple.com/is/app/30-30/id505863977?mt=8 You have never experienced a task manager like this! Simple. Attractive. Useful. 30/30 helps you get stuff done! 3D Brain – Education / 1 Cold Spring Harbor Lab http://www.g2conline.org/ https://itunes.apple.com/is/app/3d-brain/id331399332?mt=8 Use your touch screen to rotate and zoom around 29 interactive structures. Discover how each brain region functions, what happens when it is injured, and how it is involved in mental illness. Each detailed structure comes with information on functions, disorders, brain damage, case studies, and links to modern research. 3DGlobe2X – Education By Sreeprakash Neelakantan http://schogini.com/ View More by This Developer https://itunes.apple.com/us/app/3d-globe-2x/id430309485?mt=8 2 An amazing way to twirl the world! This 3D globe can be rotated with a swipe of your finger. Spin it to the right or left, and if you want it closer zoom in, or else zoom out. Watch the world revolve at your fingertips! An interesting feature of this 3D globe is that you can type in the name of a place in the given space and it is shown on the 3D globe by affixing a flag to show you the exact location. Also, when you click on the flag, you will get the details about the place on your screen. -

A Position Based Approach to Ragdoll Simulation
LINKÖPING UNIVERSITY Department of Electrical Engineering Master Thesis A Position Based Approach to Ragdoll Simulation Fiammetta Pascucci LITH-ISY-EX- -07/3966- -SE June 2007 LINKÖPING UNIVERSITY Department of Electrical Engineering Master Thesis A position Based Approach to Ragdoll Simulation Fiammetta Pascucci LITH-ISY-EX- -07/3966- -SE June 2007 Supervisor: Ingemar Ragnemalm Examinator: Ingemar Ragnemalm Abstract Create the realistic motion of a character is a very complicated work. This thesis aims to create interactive animation for characters in three dimen- sions using position based approach. Our character is pictured from ragdoll, which is a structure of system particles where all particles are linked by equidistance con- straints. The goal of this thesis is observed the fall in the space of our ragdoll after creating all constraints, as structure, contact and environment constraints. The structure constraint represents all joint constraints which have one, two or three Degree of Freedom (DOF). The contact constraints are represented by collisions between our ragdoll and other objects in the space. Finally, the environment constraints are represented by means of the wall con- straint. The achieved results allow to have a realist fall of our ragdoll in the space. Keywords: Particle System, Verlet’s Integration, Skeleton Animation, Joint Con- straint, Environment Constraint, Skinning, Collision Detection. Acknowledgments I would to thanks all peoples who aid on making my master thesis work. In particular, thanks a lot to the person that most of all has believed in me. This person has always encouraged to go forward, has always given a lot love and help me in difficult movement.