Developing an Autonomous Driving Model Based on Raspberry Pi
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

User Manual - S.USV Solutions Compatible with Raspberry Pi, up Board and Tinker Board Revision 2.2 | Date 07.06.2018
User Manual - S.USV solutions Compatible with Raspberry Pi, UP Board and Tinker Board Revision 2.2 | Date 07.06.2018 User Manual - S.USV solutions / Revision 2.0 Table of Contents 1 Functions .............................................................................................................................................. 3 2 Technical Specification ........................................................................................................................ 4 2.1 Overview ....................................................................................................................................... 5 2.2 Performance .................................................................................................................................. 6 2.3 Lighting Indicators ......................................................................................................................... 6 3 Installation Guide................................................................................................................................. 7 3.1 Hardware ...................................................................................................................................... 7 3.1.1 Commissioning S.USV ............................................................................................................ 7 3.1.2 Connecting the battery .......................................................................................................... 8 3.1.3 Connecting the external power supply ................................................................................. -

Building a Distribution: Openharmony and Openmandriva
Two different approaches to building a distribution: OpenHarmony and OpenMandriva Bernhard "bero" Rosenkränzer <[email protected]> FOSDEM 2021 -- February 6, 2021 1 MY CONTACT: [email protected], [email protected] Way more important than that, he also feeds LINKEDIN: dogs. https://www.linkedin.com/in/berolinux/ Bernhard "bero" Rosenkränzer I don't usually do "About Me", but since it may be relevant to the topic: Principal Technologist at Open Source Technology Center since November 2020 President of the OpenMandriva Association, Contributor since 2012 - also a contributor to Mandrake back in 1998/1999 2 What is OpenHarmony? ● More than an operating system: Can use multiple different kernels (Linux, Zephyr, ...) ● Key goal: autonomous, cooperative devices -- multiple devices form a distributed virtual bus and can share resources ● Initial target devices: Avenger 96 (32-bit ARMv7 Cortex-A7+-M4), Nitrogen 96 (Cortex-M4) ● Built with OpenEmbedded/Yocto - one command builds the entire OS ● Fully open, developed as an Open Source project instead of an inhouse product from the start. ● For more information, visit Stefan Schmidt's talk in the Embedded devroom, 17.30 and/or talk to us at the Huawei OSTC stand. 3 What is OpenMandriva? ● A more traditional Linux distribution - controlled by the community, continuing where Mandriva left off after the company behind it went out of business in 2012. Its roots go back to the first Mandrake Linux release in 1998. ● Originally targeting only x86 PCs - Support for additional architectures (aarch64, armv7hnl, RISC-V) added later ● Repositiories contain 17618 packages, built and updated individually, assembled into an installable product with omdv-build-iso or os-image-builder. -

A Low-Cost Deep Neural Network-Based Autonomous Car
DeepPicar: A Low-cost Deep Neural Network-based Autonomous Car Michael G. Bechtely, Elise McEllhineyy, Minje Kim?, Heechul Yuny y University of Kansas, USA. fmbechtel, elisemmc, [email protected] ? Indiana University, USA. [email protected] Abstract—We present DeepPicar, a low-cost deep neural net- task may be directly linked to the safety of the vehicle. This work based autonomous car platform. DeepPicar is a small scale requires a high computing capacity as well as the means to replication of a real self-driving car called DAVE-2 by NVIDIA. guaranteeing the timings. On the other hand, the computing DAVE-2 uses a deep convolutional neural network (CNN), which takes images from a front-facing camera as input and produces hardware platform must also satisfy cost, size, weight, and car steering angles as output. DeepPicar uses the same net- power constraints, which require a highly efficient computing work architecture—9 layers, 27 million connections and 250K platform. These two conflicting requirements complicate the parameters—and can drive itself in real-time using a web camera platform selection process as observed in [25]. and a Raspberry Pi 3 quad-core platform. Using DeepPicar, we To understand what kind of computing hardware is needed analyze the Pi 3’s computing capabilities to support end-to-end deep learning based real-time control of autonomous vehicles. for AI workloads, we need a testbed and realistic workloads. We also systematically compare other contemporary embedded While using a real car-based testbed would be most ideal, it computing platforms using the DeepPicar’s CNN-based real-time is not only highly expensive, but also poses serious safety control workload. -

D I E B Ü C H S E D E R P a N D O R a Seite 1
D i e B ü c h s e d e r P a n d o r a Infos zur griechischen Mythologie siehe: http://de.wikipedia.org/wiki/B%C3%BCchse_der_Pandora ______________________________________________________________________________________________________________________________________________________ „Das Öffnen der Büchse ist absolute Pflicht, um die Hoffnung in die Welt zu lassen!“ Nachdruck und/oder Vervielfältigungen, dieser Dokumentation ist ausdrücklich gestattet. Quellenangabe: Der Tux mit dem Notebook stammt von der Webseite: http://www.openclipart.org/detail/60343 1. Auflage , © 9-2012 by Dieter Broichhagen | Humboldtstraße 106 | 51145 Köln. e-Mail: [email protected] | Web: http://www.broichhagen.de | http://www.illugen-collasionen.com Satz, Layout, Abbildungen (wenn nichts anderes angegeben ist): Dieter Broichhagen Alle Rechte dieser Beschreibung liegen beim Autor Gesamtherstellung: Dieter Broichhagen Irrtum und Änderungen vorbehalten! Seite 1 - 12 D i e B ü c h s e d e r P a n d o r a Infos zur griechischen Mythologie siehe: http://de.wikipedia.org/wiki/B%C3%BCchse_der_Pandora ______________________________________________________________________________________________________________________________________________________ Hinweis: Weitere Abbildungen von meiner „Büchse der Pandora“ finden Sie unter http://broichhagen.bplaced.net/ilco3/images/Pandora-X1.pdf Bezeichnungen • SheevaPlug ist kein Katzenfutter und kein Ausschlag • DreamPlug ist kein Auslöser für Alpträume • Raspberry Pi ist kein Himbeer-Kuchen • Pandaboard ist kein Servbrett für Pandabären • Die „Büchse der Pandora“ ist keine Legende Was haben SheevaPlug, DreamPlug, Raspberry Pi und Pandaboard gemeinsam? Sie haben einen ARM und sind allesamt Minicomputer. Wer einen ARM hat, ist nicht arm dran. Spaß bei Seite oder vielmehr, jetzt geht der Spaß erst richtig los. Am Anfang war der ... SheevaPlug Das Interesse wurde durch Matthias Fröhlich geweckt, der einen SheevaPlug- Minicomputer vor 2 Jahren im Linux- Workshop vorstellte. -

End-To-End Learning for Autonomous Driving Robots
End-to-End Learning for Autonomous Driving Robots Anthony Ryan 21713293 Supervisor: Professor Thomas Bräunl GENG5511/GENG5512 Engineering Research Project Submitted: 25th May 2020 Word Count: 8078 Faculty of Engineering and Mathematical Sciences School of Electrical, Electronic and Computer Engineering 1 Abstract This thesis presents the development of a high-speed, low cost, end-to-end deep learning based autonomous robot driving system called ModelCar-2. This project builds on a previous project undertaken at the University of Western Australia called ModelCar, where a robotics driving system was first developed with a single LIDAR scanner as its only sensory input as a baseline for future research into autonomous vehicle capabilities with lower cost sensors. ModelCar-2 is comprised of a Traxxas Stampede RC Car, Wide-Angle Camera, Raspberry Pi 4 running UWA’s RoBIOS software and a Hokuyo URG-04LX LIDAR Scanner. ModelCar-2 aims to demonstrate how the cost of producing autonomous driving robots can be reduced by replacing expensive sensors such as LIDAR with digital cameras and combining them with end-to-end deep learning methods and Convolutional Neural Networks to achieve the same level of autonomy and performance. ModelCar-2 is a small-scale application of PilotNet, developed by NVIDIA and used in the DAVE-2 system. ModelCar-2 uses TensorFlow and Keras to recreate the same neural network architecture as PilotNet which features 9 layers, 27,000,000 connections and 252,230 parameters. The Convolutional Neural Network was trained to map the raw pixels from images taken with a single inexpensive front-facing camera to predict the speed and steering angle commands to control the servo and drive the robot. -

Raspberry Pi Market Research
Raspberry Pi Market Research Contents MARKET ................................................................................................................................................... 3 CONSUMERS ............................................................................................................................................ 8 COMPETITORS ....................................................................................................................................... 12 Element14 ......................................................................................................................................... 12 Gumstix- Geppetto Design ............................................................................................................... 14 Display Module .................................................................................................................................. 17 CoMo Booster For Raspberry Pi Compute Module (Geekroo Technologies ) ................................... 18 2 MARKET When the first Raspberry PI (Pi) was released in February 2012 it made a big impact that extended well beyond the education world for which it was touted. The Pi became a staple amongst the hobbyist and professional maker communities and was used for building everything from media centers, home automation systems, remote sensing devices and forming the brains of home made robots. It has recently been announced that over 5m Raspberry Pi’s have been sold since its inception, making it the best selling -

Gumstix Edge AI Series for NVIDIA Jetson Nano
Gumstix Edge AI Series for NVIDIA Jetson Nano TensorFlow pre-integration for machine learning and neural networking development. ® Fremont, CA. March 31, 2020— Gumstix , Inc., a leader in computing hardware for intelligent embedded applications, announced the release of four Edge AI devices designed to meet the demands of machine-learning applications moving massive data from the networks edge. Powered by the NVIDIA Jetson Nano running a Quad-core ARM A57, the Gumstix AI development boards feature built in TensorFlow support to make edge AI prototyping more accessible for software engineers and provide a rapid turnkey solution for deployment. Gumstix AI devices streamline the software-hardware integration and provide users the following benefits: ● Easy to customize modular designs available in the Geppetto app. ● GPU enabled TensorFlow support. ● Customizable OS (Yocto) for rapid and simple deployment. “Ever since launching our first products in 2003- running a full Linux implementation in the size of a stick of gum - we have sought to make the world of tiny devices more and more powerful.” says W.Gordon Kruberg, M.D., Head of Modular Hardware, Altium, Inc., “This new AI series of expansion boards, featuring the SnapShot, and our support of the NVIDIA Nano, grows from our belief in the power and primacy of neural-network algorithms.” The Gumstix Snapshot with up to 16 video streams along with the 3 other new boards, are now available for purchase at www.gumstix.com. In addition, users are able to also easily customize the form, fit and function of these modular designs online and receive a customized board in 15 days. -

2014-Kein Titel-Gerrit Grunwald
SENSOR NETWORKS JAVA RASPBERRYEMBEDDED PI ABOUTME. CANOOENGINEERING Gerrit Grunwald | Developer Leader of JUG Münster JavaFX & IoT community Co-Lead Java Champion, JavaOne RockStar JAVA ONE 2013 canoo canoo canoo canoo MONITORING canoo IDEAS canoo ๏ Measure multiple locations ๏ Store data for analysis ๏ Access it from everywhere ๏ Use Java where possible ๏ Visualize the data on Pi canoo ๏ Create mobile clients ๏ Display current weather condition ๏ Measure local environmental data ๏ Use only embedded devices canoo QUESTIONS ???canoo ๏ How to do the measurement ? ๏ Where to store the data ? ๏ Which technologies to use ? ๏ What is affordable ? ๏ Which hardware to use ? canoo TODO canoo 1 2 MONITOR STORE DATA 9 ROOMS 3 4 VISUALIZE ON OTHER RASPBERRY PI CLIENTS canoo MONITOR 9 ROOMS canoo BUT HOW canoo SENSOR NETWORK canoo SENSOR NETWORK ๏ Built of sensor nodes ๏ Star or mesh topology ๏ Pass data to coordinator ๏ Sensor nodes running on batteries canoo POSSIBLE SENSOR NODES canoo RASPBERRY PI canoo RASPBERRY PI ๏ Cheaper ๏ Power supply ๏ Support ๏ Size ๏ Flexible ๏ Overkill ๏ Connectivity ๏ limited I/O's canoo ARDUINO YUN canoo ARDUINO YUN ๏ Cheaper ๏ Power supply ๏ Support ๏ Oversized ๏ Flexible ๏ I/O's ๏ No Java ๏ Connectivity canoo ARDUINO + XBEE canoo ARDUINO + XBEE ๏ Cheap ๏ Power supply ๏ Support ๏ Oversized ๏ Flexible ๏ I/O's ๏ No Java ๏ Connectivity canoo XBEE canoo XBEE ๏ Cheap ๏ No Java ๏ Support ๏ Flexible canoo XBEE canoo XBEE ๏ 2.4 GHz at 2mW ๏ Indoor range up to 40m ๏ Outdoor range up to 120m ๏ 2.8 - 3.6 Volt ๏ -40 - 85°C operat. -
Raspberry Pi 4 Laptop | Element14 | Raspberry Pi
Raspberry Pi 4 Laptop | element14 | Raspberry Pi https://www.element14.com/community/communit... Welcome, Guest Log in Register Activity Search Translate Content Participate Learn Discuss Build Find Products Store Raspberry Pi Raspberry Pi 4 Laptop Posted by stevesmythe in Raspberry Pi on Nov 23, 2019 4:17:58 PM [Updated 03 January 2020 - see addendum at bottom of the page] I was lucky enough to win one of the 20 Raspberry Pi 4s in the element14 "Happy 10th Birthday!" giveaway. My suggestion was to use the Pi 4 to run Pi-Hole on my network to block unwanted adverts that slow down my browsing (and not just me - everybody in the household). This worked really well and I'll blog about it shortly. I've been reading reports of people using the Pi 4 as a low-cost desktop computer and tried that out myself by adding a screen and one of the new Raspberry Pi Keyboard/ Mouse combos. Not forgetting an official Raspberry Pi 4 power supply. I was pleasantly surprised at how usable it was. However, I'm running low on desk space to hold another monitor/keyboard so I haven't really made much use of it. I recently noticed that element14's sister site CPC Farnell in the UK was selling off the original Pi-Top (Raspberry Pi laptop kit) for £80 plus VAT. It originally cost around £200. For £80 you get an (almost) empty laptop shell, with a large capacity (43-watt-hour) Li-ion battery, keyboard (with trackpad), a 1366x768 resolution TFT LCD screen and 3A power supply. -

Using Pareto Optimum to Choose Module's Computing
29TH DAAAM INTERNATIONAL SYMPOSIUM ON INTELLIGENT MANUFACTURING AND AUTOMATION DOI: 10.2507/29th.daaam.proceedings.081 USING PARETO OPTIMUM TO CHOOSE MODULE’S COMPUTING PLATFORMS OF MOBILE ROBOT WITH MODULAR ARCHITECTURE Victor Andreev, Valerii Kim & Pavel Pletenev This Publication has to be referred as: Andreev, V[iktor]; Kim, V[alerii] & Pletenev, P[avel] (2018). Using Pareto Optimum to Choose Module’s Computing Platforms of Mobile Robot with Modular Architecture, Proceedings of the 29th DAAAM International Symposium, pp.0559-0565, B. Katalinic (Ed.), Published by DAAAM International, ISBN 978-3-902734-20-4, ISSN 1726-9679, Vienna, Austria DOI: 10.2507/29th.daaam.proceedings.081 Abstract This paper tries to address a sufficiently complex task – choice of module’s computing platform for implementation of information-measuring and control system (IMCS) of full-functional modules of mobile robot with modular architecture. The full functionality of a mechatronic device is the ability to perform its goal function using only its own facilities for executing instructions from an external control system. This condition sets for robot’s IMCS some specific requirements on selection of corresponding computational platform, which one could separate into objective, subjective and computative-objective criteria. This paper proposes use of discrete optimization with Pareto-optimum to select viable alternatives from computing platforms which can be both off-the-shelf and perspective products. One of the main criteria – such embedded computing platforms must have suitable computational power, low weight and sizes. The paper provides descriptions of different computing platforms, as well as the rationale for main quality criteria of them. An example of Pareto optimization for a specific IMCS solution for some types of mobile robot modules with modular architecture is provided. -

Raspberry Pi User Shows Home-Automation Feats Using Iphone 8 February 2013, by Nancy Owano
Raspberry Pi user shows home-automation feats using iPhone 8 February 2013, by Nancy Owano Thermostat; 5. RedEye IP2IR controllers; 6. SiriProxy running on a RPi; 7. iOS mobile apps MobiLinc HD; and eKeypad Pro for iPhone/iPad touch control (not in video). "Elvis Impersonator" said he started exploring what can be done in home automation and control in 2008, visiting the pursuit "as time and disposable income permitted." He said he worked with iOS app developers during this time, beta testing and suggesting capabilities for their apps. He had been following the development of SiriProxy since its initial appearance in late 2011. (A developer in 2011 created a proxy server third-party proxy server, designed specifically for Siri. The developer used a plug-in to control a WiFi thermostat with voice commands. Last year, DarkTherapy in a (Phys.org)—The latest hacker enthusiast who is out Raspberry Pi forum, said he had a project involving to demonstrate Raspberry Pi's potential has a SiriProxy running on the Raspberry Pi along with system that pairs SiriProxy with Raspberry Pi to wiringPi to access the Pi's GPIO pins and turn a perform numerous home automation feats, just by relay on/off. The relay was hooked up to his garage speaking commands into the iPhone. "Elvis door system. That gave him control of the door with Impersonator" has shown in a YouTube video how Siri on his iPhone.) he can change Siri from a glamorous job as Concierge to a role as domestic helper. With the Pi "Elvis Impersonator" got SiriProxy installed and running SiriProxy, his commands via iPhone result working on a Marvell SheevaPlug ARM based plug in his desired reactions based on his predefined computer. -
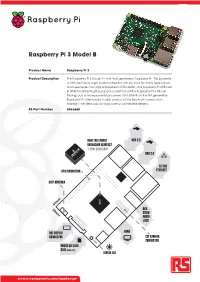
Raspberry Pi 3 Model B
Raspberry Pi 3 Model B Product Name Raspberry Pi 3 Product Description The Raspberry Pi 3 Model B is the third generation Raspberry Pi. This powerful credit-card sized single board computer can be used for many applications and supersedes the original Raspberry Pi Model B+ and Raspberry Pi 2 Model B. Whilst maintaining the popular board format the Raspberry Pi 3 Model B brings you a more powerful processer, 10x faster than the first generation Raspberry Pi. Additionally it adds wireless LAN & Bluetooth connectivity making it the ideal solution for powerful connected designs. RS Part Number 896-8660 RAM 1GB LPDDR2 USB 2.0 BROADCOM BCM2837 1.2GHz QUAD CORE USB 2.0 10/100 GPIO CONNECTOR ETHERNET CHIP ANTENNA 85mm 56mm RCA VIDEO/ AUDIO JACK DSI DISPLAY HDMI CONNECTOR CSI CAMERA CONNECTOR MICRO SD CARD SLOT (underside) STATUS LED www.rs-components.com/raspberrypi Raspberry Pi 3 Model B Specifications Processor Broadcom BCM2387 chipset. 1.2GHz Quad-Core ARM Cortex-A53 802.11 b/g/n Wireless LAN and Bluetooth 4.1 (Bluetooth Classic and LE) GPU Dual Core VideoCore IV® Multimedia Co-Processor. Provides Open GL ES 2.0, hardware-accelerated OpenVG, and 1080p30 H.264 high-profile decode. Capable of 1Gpixel/s, 1.5Gtexel/s or 24GFLOPs with texture filtering and DMA infrastructure Memory 1GB LPDDR2 Operating System Boots from Micro SD card, running a version of the Linux operating system or Windows 10 IoT Dimensions 85 x 56 x 17mm Power Micro USB socket 5V1, 2.5A Connectors: Ethernet 10/100 BaseT Ethernet socket Video Output HDMI (rev 1.3 & 1.4 Composite